by David L Schoen
Organizations utilize databases to streamline their operations in a number of areas. Databases may be used to keep track of sales, potential clients, phone numbers of employees, or customer comments. There are very few areas of an organization that could not be benefited by a well-organized database. This paper will examine the history of databases and the basic differences between modern databases. In addition, this paper will look at concerns with replicating databases. It is beyond the scope of this paper to incorporate an in-depth discussion of databases and replication. This paper is to give the reader a general overview of databases and replication concepts.
History Of Databases
Databases have been in use by organizations since the 1950�s. These first generation databases required data to be input via punch cards or magnetic tapes. It required batch processing and sequential access to the data. The second-generation databases began appearing around 1960. These second generation databases offered data on magnetic disks and interactive data processing. This gave users direct access to data via either multiple or parallel access. Third generation databases arrived in 1965. Third generation databases required data modeling. Two common models are hierarchical data (IBM) and network (Siemens) models. The current databases are fourth generation. The fourth generation databases came on the scene in 1975. These databases are a giant leap ahead of the third generation models. They offer data independence, non-procedural languages, and computer-independent systems. The two models of fourth generation databases are relational data (IBM and Oracle) and object-oriented (Poet) systems. (Fachhochschule Darstadt University of Applied Sciences, 1996)
Relational and Object-Oriented Databases
The relational database had its beginning at IBM. In the 1960�s and 1970�s, IBM was researching ways to automate office functions. Ted Codd published the first article on relational databases in 1970. This article used mathematical formulas to support Cobb's theory. IBM assigned a research group and identified the project as System R. During their research, the industry standard language, SQL - Structured Query Language, was created. Over time, System R evolved into IBM�s database program DB2. Even though IBM created the concept, it did not produce the first commercial relational database. Honeywell created the first relational database in June of 1976. It was the early 1980�s when the first relational database using SQL was introduced by Oracle. (Database Group, 2000).
The popularity of relational databases has grown. SearchDatabase.com defines a database as �� a collection of data that is organized so that its contents can easily be accessed, managed, and updated.� (TechTarget, 2000-2002). Further exploration of SearchDatabase.com reveals that relational databases utilize tables, also known as relations, organized in columns of unique data. Their beauty is the ability to add additional data categories without modifying existing applications. (TechTarget, 2000-2002) Steve Franklin, in his article Object-Oriented Databases Are Worth A Closer Look, makes the statement
- Despite the advantages that object-oriented databases (OODBs) can offer over relational databases (RDBs), OODBs have not been able to shake the RDB stronghold on data-driven systems. They are a newer technology that has proven popular with many DB architects, yet application developers often opt for RDBs. (Franklin, 2000-2002)
Centralized and Distributed Databases
These relational and object-oriented databases may be centralized or distributed. Slides from a lecture on Distributed Databases at Monash University shows three disadvantages of distributed databases. They are:
This leads many companies to use a centralized database system. Dr. W. Robert J. Funnell at McGill University has posted several pages under the title Basic Computer Notions. Dr. Funnell lists the following advantages are obtained when using a large centralized database.
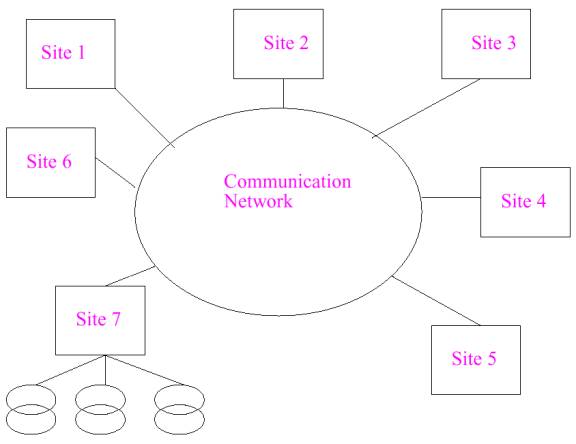
Centralized database system diagram (Bouguettaya, slide 11)
There are problems with using one centralized database. When a portion of the network is down, the database may not be accessible. Files cannot be updated. Information stored in the database cannot be mined (searched). If the database is damaged, stored information may be lost. To overcome these problems, organizations turn to distributed databases. Slides from a lecture on Distributed Databases at Monash University also show the benefits of distributed databases. Five benefits distributed databases have over centralized databases are:
Slides from Athman Bouguettaya�s lecture at Virginia Tech titled CS6604: Distributed Databases further states these benefits lead to:
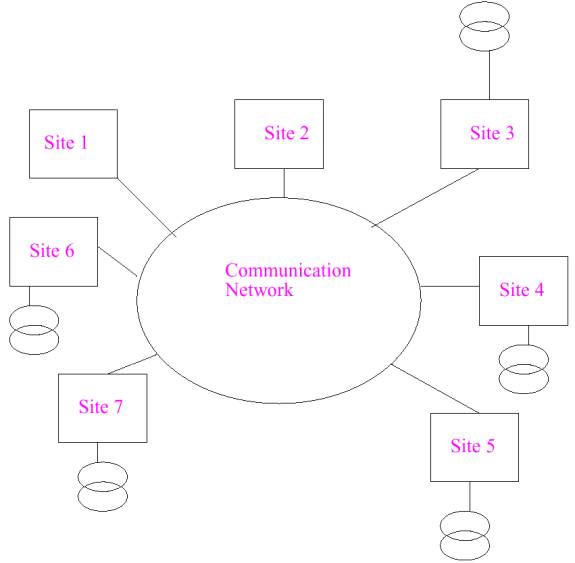
Distributed database system diagram (Bouguettaya, slide 14)
Replication
Distributed databases create new problems. How does one ensure the data contained in all copies of the database are correct? How are mobile applications affected? These problems are resolved through replication. In Chapter 31 of a manual published by Oracle Corporation titled Oracle8 Concepts, replication is defined as �� the process of copying and maintaining database objects in multiple databases that make up a distributed database system.� (Oracle, 1997) Charles Thompson in his article Database Replication gives the following warning � Managing a distributed database is vastly more difficult than managing a centralized database � It is also important to have a through understanding of the mechanism that your database uses for replication.� (Thompson, 1997) Oracle8 Concepts describes two forms of replication � basic and advanced. (Oracle, 1997)
Basic and Advanced Replication
Basic replication provides for read-only access to data. A localized database replica receives information from a master database. This replica contains only the data relevant to a specified group of users. Allowing this local, specified group of users to query the replica, prevents unnecessary network traffic and allows access to the information regardless of network availability. When it is necessary to update information contained in the database, users must access the master database. (Oracle, 1997)
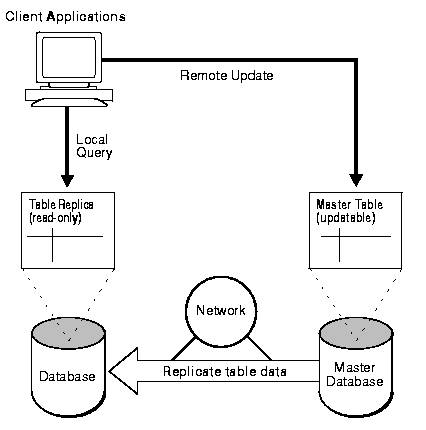
Basic read-only replication diagram (Oracle, 1997, Figure 31-1)
Advanced replication allows database replicas to provide access to read-only and update features. The applications no longer need to update the master database. The replicas automatically work to update the data in all tables to ensure global transaction consistency and data integrity. (Oracle, 1997) To avoid bottlenecks, system architects often distribute data items among sites. This means no single site is the primary, or master, database for all of the fields contained in the data tables. (Wiesmann)
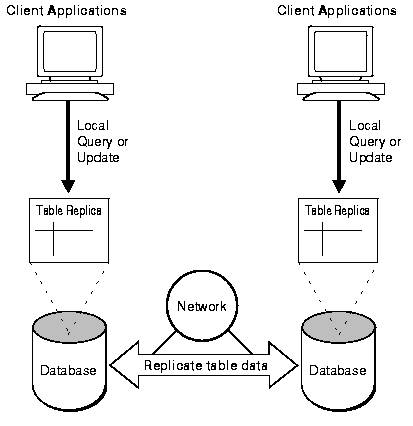
Advanced replication diagram (Oracle, 1997, Figure 31-2)
Replication Protocols
Replication uses a protocol, a set of rules, to address efficiency and reliability of the data distribution. Protocols that may be used in the replication of data include: Network News Transfer Protocol (NNTP), Internet Cache Protocol (ICP), Distributed Authoring and Versioning Protocol (WebDAV), and Network Data Management Protocol (NDMP). Each of these protocols accomplishes different tasks. Because they perform different tasks, multiple protocols may be running on each system. (Schwartz, 2001) A protocol commonly found on most systems is the HTTP Distribution and Replication Protocol (DRP). The use of the DRP protocol allows a client to receive an initial download of data, and then keep the client updated by downloading only the data that has changed since the last update. This method of updating the client is more efficient than downloading all the data during each update. (W3C, 1997)
Asynchronous and Synchronous Replication Updates
These updates may be done by either asynchronous (lazy) or synchronous (eager) replication. In deciding which method to use, one must look at the replicas. If some of the replicas will become inaccessible or offline, such as a replica on a notebook computer, lazy replication is used. The reasoning behind this choice is not all replicas may be available for an update at a set time. (Lanard and Lucas, 2001) The lazy or asynchronous replication provides for the update of the primary database. The replicas may be updated at a future time when the replica is available or when the network has less traffic. The changes are stored in a queue until the update is processed. This means the primary database and its replicas may have different stored values. (Staffordshire University) Eager or synchronous replication is used when all replicas are accessible for updates and when transactions must be synchronized. Eager replication ensures synchronization by updating all versions of the distributed database at the same time. This method is slow due to extra updates and messages required to ensure previous transactions are updated before allowing a new transaction. (Staffordshire University)
Summary
Databases are appropriate for many applications. Assuming one database will work just as well as another database for a particular application is problematic. We have seen how one must consider if a relational database is all that is needed or if the data requires an object-oriented database. After it is determined how the database is to be used, one must weigh the advantages and disadvantages of centralized and distributed databases. Should a distributed database be considered, a good understanding of how the data is to be replicated is required. This requires looking again at the data and the end user. Data that requires the synchronization of transactions must be replicated through eager replication. Eager replication will not be performed as quickly as lazy replication. Many applications can use �stale� data that can be quickly accessed and then process database updates during periods of low activity. Through careful consideration of the data and the end user, one can determine the best database and method of replication for an application.
Bouguettaya, Athman. Virginia Tech. CS6604: Distributed Databases. Retrieved February 28, 2002 from the World Wide Web: http://www.nvc.cs.vt.edu/~athman/CS6604/week1.pdf
Database Group. (2000). A Brief History of Databases. Retrieved February 18, 2002 from the World Wide Web: http://wwwinfo.cern.ch/db/aboutdbs/history/industry.html
Fachhochschule Darstadt University of Applied Sciences. (1996). History of Databases, Retrieved February 18, 2002 from the World Wide Web: http://www.fbi.fh-darmstadt.de/~databases/db03.html
Franklin, Steve. (2000-2002). Object Oriented Databases Are Worth a Closer Look. Retrieved February 7, 2002 from the World Wide Web: http://www.devx.com/dbzone/articles/sf0601/sf0601-1.asp
Funnell, W. Robert J. (2000). Basic Computer Notion/. Retrieved February 20, 2002 from the World Wide Web: http://funsan.biomed.mcgill.ca/~funnell/InforMed/Bacon/DBMS/dbms039.html
Lanard, Valerie and Lucas, Gabriel. (May 8, 2001). Media Map: a Distribution Database Scenario, Retrieved February 26, 2002 from the World Wide Web: http://www.google.com/search?q=cache:7Lf2QcQWX_YC:dream.sims.berkeley.edu/media-map/290-5/Scalability.pdf+lazy+%22database+replication+%22&hl=en
Monash University, COT2132 Database Systems, Week 12 Lecture Distributed Database. Retrieved February 22, 2002 from the World Wide Web: http://www.csse.monash.edu.au/courseware/cse2132/lec12-4up.pdf
Oracle. (1997). Oracle8 Concepts, Chapter 31 Database Replication. Retrieved February 27, 2002 from the World Wide Web: http://www-wnt.gsi.de/oragsidoc/doc_804/database.804/a58227/ch_repli.htm
Schwartz, M. (October 7, 2001) The Internet Society, The ANTACID Replication Service: Rationale and Architecture, Retrieved February 22, 2002 from the World Wide Web: http://www.codeontheroad.com/papers/draft-schwartz-antacid-service.html
Staffordshire University. Retrieved February 28, 2002 from the World Wide Web: http://gawain.soc.staffs.ac.uk/modules/level3/cm35364-3/Essays2001/Ward.doc
TechTarget, Inc. (2000-2002). searchDatabase.com. Retrieved February 5, 2002 from the World Wide Web: http://searchdatabase.techtarget.com/sDefinition/0,,sid13_gci211895,00.html
Thompson, Charles. (May 1997) DMBS, Database Replication. Retrieved February 7, 2002 from the World Wide Web: www.dbmsmag.com/9705d15.html
Wiesmann, Matthias. Database Replication Techniques: a Three Parameter Classification, Retrieved February 26, 2002 from the World Wide Web: http://lsewww.epfl.ch/Documents/html/WPS+00b.html
W3C. (August 25, 1997). The HTTP Distribution and Replication Protocol, Retrieved February 6, 2002 from the World Wide Web: http://www.w3.org/TR/NOTE-drp-19970825.html
last update: 4/26/2002