Vladimir
Alejandro Giraldo Duque
Diego Alexander
Zuleta
Departamento
de Ingenieria de Sistemas
Unviersidad de
Antioquia
Vladimir
Alejandro Giraldo Duque
Diego Alexander
Zuleta
Departamento
de Ingenieria de Sistemas
Unviersidad de
Antioquia
CONTENIDO:
CONTENIDO:
El fenómeno Internet ha venido
a alterar la forma de vida de millones de personas que hoy en día utilizan la
red en diferentes actividades de su vida cotidiana. El correo electrónico es de
las aplicaciones más utilizadas y de una gran utilidad para la comunicación
entre amigos, investigadores y colegas. Sin embargo la World Wide Web es el
servicio al que todo usuario puede acceder, buscar información en bibliotecas
virtuales, universidades, centros de investigación o en páginas desarrolladas
por personas aficionadas al tema. Existen otros servicios, como el utilizado
para la transferencia de archivos, llamado FTP (File Transfer Protocol). Este
está dirigido a quienes necesitan enviar grandes volúmenes de información a
lugares distantes y que demandan seguridad y confiabilidad. Otro servicio es el
de terminal virtual (TELNET) con el cual se pueden realizar tareas desde
terminales remotas como si físicamente se estuviera trabajando en el equipo al
cual se conecta. Existen otros servicios menos utilizados como Gopher
(información de tipo texto) y su servicio de búsqueda llamado
Veronica.
Sin
duda alguna la aparición de la Web, y la implementación de navegadores o
browsers con los cuales se podía desplazar de un sitio a otro a través de forma
gráfica (iconos) utilizando como interfaz un ratón, dio el puntapié al fenómeno
Internet.
Durante el desarrollo del
protocolo TCP/IP se incrementó notablemente el número de redes locales de
agencias gubernamentales y de universidades, dando origen así a la red de redes
más grande del mundo; las funciones militares que se pensaron en un inicio se
separaron y se permitió el acceso a la red a todo aquel que lo requiriera sin
importar de que país provenía la solicitud siempre y cuando fuera para fines
académicos o de investigación.
Después de que las funciones militares
de la red se separaron en una subred de Internet, la tarea de coordinar el
desarrollo de la red recayó en varios grupos, uno de ellos la National Science
Fundation quien promovió el uso de la red ya que se encargó de conectar cinco
centros de supercómputo en todo Estados Unidos que podían ser accedidos desde
cualquier nodo de la red. El grupo de mayor autoridad sobre el desarrollo de la
red es la Internet Society, creado en 1992 y formado por miembros voluntarios,
cuyo propósito principal es promover el intercambio de información global a
través de la tecnología Internet. Puede decirse que esta sociedad es como un
consejo que tiene la responsabilidad de la administración técnica y dirección de
Internet, aunque no es el único.
Existen otros tres grupos que tienen un
rol significativo, el Internet Architecture Board (IAB), esta organización toma
las decisiones acerca de los estándares de comunicaciones entre las diferentes
plataformas para que puedan interactuar máquinas de diferentes fabricantes sin
problemas; este grupo es responsable de cómo se deben asignar las direcciones y
otros recursos en la red, aunque no son ellos quienes se encargan de hacer estas
asignaciones, para eso existe otra organización llamada NIC (Network Information
Center), administrado por el departamento de defensa de los Estados Unidos. En
1989 se reorganiza la estructura de la IAB, un grupo subsidiario e importante de
la IAB es el Internet Engineering Task Force (IETF) Fuerza de Tarea de
Ingeniería, esta se concentra en problemas de ingeniería a corto y mediano plazo
y la IRTF Fuerza de Tarea de Investigación Internet, la cual coordina las
actividades de investigación relacionadas con los protocolos TCP/IP y con la
arquitectura de la red de redes en general.
La estandarización tecnológica
de Internet dio origen a un nuevo conjunto de protocolos llamados TCP/IP
(Transmission Control Protocol/Internet Protocol). Un sistema de comunicaciones
muy sólido y robusto bajo el cual se integran todas las redes que conforman lo
que se conoce actualmente como Internet, el cual no fue diseñado para ignorar o
evadir estándares ya existentes. Estos surgen solamente porque ninguno de los
protocolos existentes satisfacía la necesidad de un sistema de comunicación
interoperable para el enlace de redes. Los protocolos TCP/IP, cuyo nombre
proviene de sus dos protocolos principales fue desarrollado en la agencia de
proyectos Avanzados de Investigación.
TCP/IP puede utilizarse para
comunicarse a través de cualquier grupo de redes interconectadas. Muchas empresa
utilizan TCP/IP para interconectar todas las redes dentro de una corporación,
aún cuando las empresas no tengan una conexión hacia redes externas. Otros lo
utilizan para comunicarse entre sitios geográficamente alejados unos de otros.
El diseño de los protocolos TCP/IP proporciona una conexión universal entre
máquinas independientes a las redes en particular a las que están conectadas,
por este motivo TCP/IP realiza las conexiones de forma transparente al usuario
sin importar la ruta que la conexión establezca, de esta forma se oculta al
usuario la arquitectura de la red global
TCP/IP es un conjunto o suite de
protocolos diseñados con una arquitectura en capas. Las capas permiten a los
diseñadores del protocolo dividir en módulos las tareas y servicios que
realizará el mismo. El diseño también especifica la manera en que un módulo
interactua con los otros. La arquitectura en capas de los protocolos está
diseñada como una pila en la que los protocolos de más alto nivel interactuan
con los protocolos de niveles más bajos.
El modelo TCP/IP está formado por cuatro capas:
1. La capa de aplicaciones es
la capa más alta de la pila, ésta provee servicios de alto nivel a los usuarios
como transferencia de archivos, entrega de correo electrónico y acceso a
terminales remotas, entre otros. Los programas de aplicación escogen entre
diferentes protocolos de transporte dependiendo del tipo de servicio que
requieran.
2.
La principal tarea de la capa de transporte es proveer comunicación punto a
punto entre las aplicaciones. Los protocolos de transporte (TCP y UDP) usan el
servicio de entrega de paquetes que provee la capa de Internet .
3. La capa de Internet provee
el servicio de entrega de paquetes de una máquina a otra, por medio del
protocolo de Internet (IP). La integridad de los datos no se verifica en este
nivel, por lo que el mecanismo de verificación es implementado en capas
superiores (Transporte o Aplicación).
4. La capa de acceso al medio acepta
datagramas de la capa de Internet y los envía físicamente. El modulo para el
acceso al medio es con frecuencia un controlador de dispositivo (device driver)
para una pieza particular de hardware, y la capa de acceso al medio puede
consistir de múltiples módulos.
Para que la información fluya a través de las capas, esta pasa por un proceso de encapsulamiento. Los mensajes e información recibida por la capa de TCP es encapsulada con un encabezado de TCP en un paquete llamado "Segmento de TCP", este es entregado a la capa de IP, en el que se le agrega un encabezado de IP y se crea el paquete llamado "Datagrama de IP". El paso final incluye el encapsulamiento del datagrama de IP en paquetes creados para la capa de acceso al medio.
Cuando se utiliza un servicio
de Internet, se establece un proceso, en el cual entran en juego dos partes. Por
un lado, el usuario ejecuta una aplicación en la computadora local, que es el
denominado programa cliente, este programa se pone en contacto con el host
remoto para solicitar la información deseada. El host remoto a su vez,
responderá al pedido realizado por el programa cliente, a través de otro
programa de aplicación, el programa servidor.
Los términos cliente y servidor se usan
tanto para referirse a los programas que cumplen estas funciones, como a las
computadoras donde son ejecutados dichos programas.
El programa cliente cumple dos
funciones distintas, por un lado gestiona la comunicación con el servidor,
solicita un servicio y recibe los datos enviados por servidor; por otro maneja
la interfaz con el usuario, presenta los datos en el formato adecuado y brinda
las herramientas y comandos para que el usuario pueda utilizar las prestaciones
del servidor de forma sencilla.
El programa servidor, en cambio, acepta
atenciones recibidas a través de la red, realiza el servicio y regresa el
resultado al cliente, de esta forma un mismo servidor puede atender a varios
clientes al mismo tiempo, sin embargo el servidor procesa una petición a la vez,
después de aceptar una petición, el servidor forma una respuesta y la manda
antes de volver a ver si ha llegado otra petición, se asume que el sistema
operativo hace una cola de peticiones que llegan al servidor mientras este esta
ocupado, los servidores tienen dos partes importantes, un programa maestro
sencillo, el cual es responsable de aceptar nuevas peticiones, y un conjunto de
esclavos, los cuales son responsables de manejar las peticiones individuales,
como el maestro ejecuta un esclavo para cada nueva petición el procesamiento
procede de manera concurrente, de este modo las peticiones que requieren de poco
tiempo para completarse pueden terminar antes que las peticiones que llevan más
tiempo, independientemente del orden en que hayan comenzado.
Sin embargo esto que parece
sencillo es aún más complejo, ya que necesita acomodar varias peticiones
concurrentes, con esto los servidores deben de reforzar las reglas de
autorización y protección, los programas servidor suelen requerir una ejecución
de alta prioridad, pues tienen que leer archivos, mantenerse en línea y tener
acceso a los datos, cada servidor toma la responsabilidad para reforzar el
acceso al sistema y las políticas de protección.
En las aplicaciones cliente-servidor es
importante minimizar las interacciones entre un cliente y la información, es por
eso que las máquinas se valen del protocolo ARP de TCP/IP para mantener una
memoria intermedia (caché) de respuestas para mejorar la eficiencia de las
búsquedas redundantes que surjan después. El proceso de memoria intermedia
(caching) mejora el desempeño del modelo, un ejemplo real de esta aplicación se
da en el caché del browser utilizado para navegar, en donde se alojan todos los
gráficos y de más archivos de las páginas que han sido visitadas, de forma que
si en una sesión se vuelve a visitar el sitio no es necesario que el servidor
vuelva a enviar esa información pues esta se tiene en el caché y puede ser
recuperada de forma inmediata, el browser es un programa cliente.
SERVICIOS DE
INTERNET
La idea de la World Wide Web
nació en Marzo de 1989, cuando Tim Berners-Lee del Laboratorio Europeo de Física
de Partículas (conocido como CERN, un centro de investigadores de física
europeos de alta energía) propuso el proyecto para ser usado como medio para
difundir investigaciones e ideas a lo largo de la organización y a través de la
red.
Para fines
de 1990, la primera versión de la WWW se presentó sobre una máquina NeXT . Tuvo
la capacidad de inspeccionar y transmitir documentos de hipertexto. El
hipertexto se refiere al texto que contiene vínculos (Hyperlink) a otros
documentos. Dichos documentos pueden estar en la misma computadora o en
cualquier otra que se encuentre conectada a la red, sin importar su situación
geográfica.
Un
vinculo (Hyperlink) se puede definir como "Get the address asociated with this
link and go there", Obtiene la dirección asociada a este vinculo y ve a ella. La
World Wide Web se define oficialmente como una "iniciativa global de
recuperación de información hipermedia con acceso universal al inmenso conjunto
de documentos en Internet". Lo que el proyecto World Wide Web ha hecho, es
proveer a los usuarios de las redes de computadoras el acceso a la información a
través de un medio uniforme de manera simplificada. Lo anterior significa que,
después de varios intentos, en Internet surge un programa de fácil manejo que
puede obtener información de cualquier computadora conectada a la
red.
Las
primeras visiones de los sistemas como la WWW tuvieron como meta el adelanto de
la ciencia y la educación, aunque el proyecto World Wide Web tiene la
potencialidad para generar un impacto importante en el comercio, la política, y
la sociedad.
Hasta hace algunos años el uso de Internet estuvo en manos de los
expertos, dada la cantidad de conceptos y comandos que el usuario debía conocer
para poder entrar al mundo cibernético. En los últimos años, los expertos
comenzaron a desarrollar sistemas que pudieran ser usados por personas con pocos
conocimientos y experiencia en sistemas de cómputo. Estos sistemas han
incorporado el uso del ratón (mouse) y pantallas gráficas, que reducen al mínimo
el uso de comandos. De esta manera nació la World Wide Web: un sistema que
permite tener acceso a la información de las máquinas conectadas a
Internet.
El protocolo que los
servidores y clientes Web usan para comunicarse se llama Protocolo de
Transferencia de Hipertexto (HTTP, HyperText Transfer Protocol). Todos los
servidores y clientes Web deben ser capaces de entender este protocolo a fin de
enviar y recibir documentos hipermedia. Por esto, a los servidores Web se les
llama frecuentemente servidores HTTP. El lenguaje estándar que "entiende" la WWW
para crear y reconocer documentos de hipertexto es el HTML (Hypertext Markup
Language), utilizado para crear páginas de Web.
La World Wide Web utiliza los
Localizadores de Uniformes de Recursos (URL, Uniform Resource Locators) para
conectarse a otros servicios de la red.
Es posible representar cualquier
archivo o servicio en Internet con un URL, de esta manera, las ligas pueden
hacerse no solamente a otros textos y medios, sino también a otra red o
servicios. El éxito de la World Wide Web es la facilidad que se tiene para
navegar sin la necesidad de aprender comandos complicados, únicamente se
necesita conocer el manejo de un ambiente gráfico de ventanas y del ratón
.
Algunos
servidores WWW incluyen encriptación y capacidades de autenticación de cliente,
esto significa que el servidor es capaz de enviar y recibir los datos seguros,
es decir, que sólo la persona que envía los datos y el que los recibe conocen la
información transmitida. Lo anterior permite tener un control entre servidores y
clientes con el fin de mantener seguros y privados los datos que se transfieran.
Por ejemplo, si un banco desea instalar un servidor Web para que sus clientes
realicen operaciones financieras, debe asegurar que la transferencia de
información sea segura y que únicamente el usuario y el banco la
conozcan.
FTP es una aplicación que
permite transferir archivos de una computadora a otra. Es una de las más
antiguas herramientas de Internet, pero también una de las más utilizadas. Un
servidor de FTP permite a los clientes navegar por la estructura de su
directorio y transportar archivos en cualquiera de las dos direcciones. No
importa el tipo de máquina ni su sistema operativo, la conexión es
"transparente".
Existen dos formas distintas de compartir archivos, el acceso en
línea y el copiado de archivo completo, el acceso compartido en línea significa
que se permite a varios programas acceder de manera concurrente a un solo
archivo, los cambios que se realizan al archivo se efectúan inmediatamente y
están disponibles para todos los programas que accedan al archivo, el copiado de
archivo completo significa que, cada vez que un programa quiera acceder a un
archivo, este obtendrá una copia local, el copiado se utiliza para datos de solo
lectura.
Un
mecanismo de acceso remoto debe manejar nociones de propiedad, autorización y
noción de acceso para seguridad de la información. La forma de establecer una
conexión con un servidor FTP desde la línea de comandos de una sesión FTP, es
especificarla escribiendo open y el dominio correspondiente del servidor a
conectarse o la dirección IP correspondiente, al establecerse la conexión el
servidor despliega una pantalla para que el usuario pueda identificarse. El uso
más importante de FTP se conoce como FTP anónimo, y permite acceder bases de
información o de software sin tener una cuenta en la computadora
remota.
FTP
ofrece muchas facilidades que van más allá de la función de transferencia misma
como:
Acceso interactivo: La
mayor parte de las aplicaciones ofrecen al cliente una interfaz interactiva, la
cual permite interactuar fácilmente con los servidores remotos.
Especificación de formato
: El FTP permite al cliente especificar el tipo y formato de los datos
almacenados.
Control de autenticación: el FTP requiere que los clientes
se identifiquen ante el servidor con un nombre de conexión y una clave de acceso
antes de pedir la transferencia de archivos.
FTP puede utilizarse para diversos servicios como bases de datos o librerías de programas, transferencia selectiva de archivos o como un canal de información privado.
El conjunto de protocolos
TCP/IP incluye un protocolo de terminal remota sencillo, llamado TELNET, este
permite al usuario de una localidad establecer una conexión TCP con un servidor
de acceso a otro No importa si la computadora está en el mismo cuarto o al otro
lado del mundo. TELNET transfiere después las pulsaciones del teclado del
usuario a la computadora remota como si hubiesen sido hechos desde un teclado
unido a la computadora remota. TELNET transporta la salida de la computadora
remota de regreso a la pantalla del usuario en un servicio transparente y da la
impresión de que teclado y monitor están conectados físicamente a la computadora
remota. Cada pulso de teclado viaja del teclado del usuario a través del sistema
operativo hacia el programa cliente, el programa cliente regresa a través del
sistema operativo y a través de la red de redes hacia la máquina servidor.
Después de llegar a la computadora destino, los datos deben viajar a través del
sistema operativo del servidor al programa de aplicación del servidor en un
punto de entrada de pseudoterminal, finalmente el sistema operativo remoto
entrega el caracter al programa de aplicación que usuario está
corriendo.
El
software de cliente TELNET permite que el usuario especifique una computadora
remota dando su nombre de dominio o la dirección IP, esto permite que se
realicen conexiones remotas aunque el software de nombres de dominio no este
depurado.
TELNET ofrece tres servicios básicos, el primero define una
terminal virtual de red, que proporciona una interfaz estándar para los sistemas
remotos. los programas clientes no tienen que comprender los detalles de todos
los sistemas remotos, se construyen para ocuparse con la interfaz estándar, el
segundo incluye un mecanismo que permite al cliente y al servidor negociar
opciones, asimismo proporciona un mecanismo de opciones estándar (una de las
opciones controla si los datos que se transfieren se valen del conjunto de
caracteres ASCII estándar de siete bits o de un conjunto de caracteres de ocho
bits). Por último TELNET trata con ambos extremos de la conexión de manera
simétrica. En particular TELNET no fuerza la entrada de cliente para que esta
venga de un teclado ni al cliente para que muestre la salida en su pantalla. De
esta manera TELNET permite que cualquier programa se convierta en cliente,
además de que cualquier extremo puede negociar las opciones
Cuando un usuario invoca a
TELNET, un programa de aplicación en la computadora del usuario se convierte en
cliente. el cliente establece una conexión TCP con el servidor por medio de la
cual se comunicarán, una vez establecida la conexión el cliente acepta los
pulsos de teclado del usuario y los manda al servidor, al tiempo que acepta
caracteres de manera concurrente que el servidor regresa y despliega en la
pantalla del usuario. El servidor debe aceptar una conexión TCP del cliente y
después transmitir los datos entre la conexión TCP y el sistema operativo local.
En práctica el servidor es más complejo, pues debe manejar diversas conexiones
concurrentes. Normalmente un proceso de servidor maestro espera nuevas
conexiones y crea un nuevo esclavo para manejar nuevas conexiones.
E-mail es el servicio de
aplicación utilizado más ampliamente, ofrece un método rápido y conveniente de
transferencia de información privada, puede adaptarse al envío de pequeñas notas
y grandes y voluminosos documentos mediante un mecanismo sencillo, de echo hay
más usuarios que envían archivos por correo electrónico que por el protocolo de
transferencia de archivos. La entrega de correo difiere de otros usos de redes,
los protocolos de red envían paquetes directamente a sus destinos utilizando
límites de tiempo y retransmisión para los segmentos individuales si no se
devuelve un acuse de recibo. Sin embargo, en el caso del correo electrónico el
sistema debe proporcionar los medios cuando la máquina remota o las conexiones
de la red han fallado. El emisor no desea esperar a que la máquina remota este
disponible para continuar trabajando, ni el usuario quiere que se aborte la
transmisión solo por que las comunicaciones con la máquina remota no están
disponibles temporalmente.
Para manejar las entregas con retraso, el sistema de coreo utiliza
una técnica conocida como spooling. Cuando el usuario envía un mensaje de
correo, el sistema coloca una copia en su área de almacenamiento privado spool
junto con la identificación del emisor, recipiente, máquina destino y hora de
depósito. El sistema indica entonces la transferencia hacia la máquina remota
como una actividad subordinada o secundaria, permitiendo al emisor que continúe
con otras actividades computacionales.
El servicio de IRC (Internet
Relay Chat) es un lugar virtual, donde las personas pueden reunirse y
conversar. Para utilizar este servicio lo único que se debe hacer es
conectarse a un servidor IRC, entrar a un canal y conversar. Para esto existen
diferentes servidores situados alrededor del mundo que son accedidos por
personas diariamente con el único fin de conocerce y entablar maravillosas
conversaciones. Con el avance de JAVA ahora esos servidores también se
encuentran en la red. Por ejemplo, usted puede conocer gente de todas las edades
desde www.planetatierra.com y conversar directamente desde un applet
JAVA.
El URL contiene los segmentos
de información que un navegador necesita para localizar una página Web. Este
busca en un URL para encontrar una página principal. La página principal es la
página Web primaria (index.html), que sirve como punto de partida.
Existen direcciones que
incluyen la tilde (~) la cual indica que es el directorio base del
usuario.
El
index.html indica al navegador el nombre del archivo a buscar, la extensión
.html indica que es un documento de hipertexto. En muchos de los servidores Web,
index.html es el nombre del archivo predeterminado a buscar, incluso si el URL
no tiene el nombre de la página principal, este automáticamente busca y
visualiza el archivo index.html.
En sistemas Unix como en muchos otros,
no es necesario que la extensión de las páginas Web sea .html, por el número de
caracteres de la extensión, estas pueden ser extensiones .htm
Para que un navegador pueda
visualizar una página Web necesita el URL o en su defecto una dirección IP, el
URL es la forma de representar direcciones para que un usuario pueda recordar
fácilmente una dirección Internet, una dirección Internet es una dirección IP.
Ya hemos hablado de la función de los servidores DNS, que prácticamente tienen
la función de asociar direcciones URL a direcciones IP.
Sin duda alguna la
infraestructura de Internet a dado cabida a nuevos tipos de aplicaciones y
servicio a los usuarios desarrollados por empresas, organizaciones y gobiernos.
Parte fundamental de estos servicios son la implementación de bases de datos
accedidas a través de la World Wide Web. El alcance y el fácil acceso a ellas,
así como la reducción de costos y la popularidad que ha cobrado la Web, son los
principales atractivos que ofrece una aplicación de esta
naturaleza.
Este trabajo pretende dar un panorama amplio sobre el
funcionamiento e implementación de bases de datos en Internet, accediendo a sus
datos a través de la Web.
UTILIZAR BASES DE DATOS EN LA WEB
La Web es un medio para
localizar/enviar/recibir información de diversos tipos, aun con las bases de
datos. En el ámbito competitivo, es esencial ver las ventajas que esta vía
electrónica proporciona para presentar la información, reduciendo costos y el
almacenamiento de la información, y aumentando la rapidez de difusión de la
misma.
Internet
provee de un formato de presentación dinámico para ofrecer campañas y mejorar
negocios, además de que permite acceder a cada sitio alrededor del mundo, con lo
cual se incrementa el número de personas a las cuales llega la
información.
Alrededor de 14 millones de personas alrededor del mundo hacen uso
de Internet, lo cual demuestra el enorme potencial que esta red ha alcanzado,
con lo cual se puede decir que en un futuro no muy lejano, será el principal
medio de comunicación utilizado para distintos fines.
Pero, no sólo es una vía para hacer
negocios, sino también una gran fuente de información, siendo éste uno de los
principales propósitos con que fue creada.
Una gran porción de dicha información
requiere de un manejo especial, y puede ser provista por Bases de
datos.
En el
pasado, las Bases de datos sólo podían utilizarse al interior de las
instituciones o en redes locales, pero actualmente la Web permite acceder a
bases de datos desde cualquier parte del mundo. Estas ofrecen, a través de la
red, un manejo dinámico y una gran flexibilidad de los datos, como ventajas que
no podrían obtenerse a través de otro medio informativo.
Con estos propósitos, los usuarios de
Internet o Intranet pueden obtener un medio que puede adecuarse a sus
necesidades de información, con un costo, inversión de tiempo, y recursos
mínimos. Asimismo, las Bases de datos serán usadas para permitir el acceso y
manejo de la variada información que se encuentra a lo largo de la
red.
La evaluación de este punto es
uno de los más importantes en la interconexión de la Web con Bases de datos. A
nivel de una red local, se puede permitir o impedir, a diferentes usuarios el
acceso a cierta información, pero en la red mundial de Internet se necesita de
controles más efectivos en este sentido, ante posible espionaje, copia de datos,
manipulación de éstos, etc.
La identificación del usuario es una de las formas de guardar la
seguridad. Las identidades y permisos de usuarios están definidas en los
Archivos de Control de Acceso.
Pero la seguridad e integridad total de
los datos puede conservarse, permitiendo el acceso a distintos campos de una
base de datos, solamente a usuarios autorizados para ello.
En este sentido, los datos
pueden ser presentados a través de la Web de una forma segura, y con mayor
impacto en todos los usuarios de la red mundial.
Para la integración de Bases de datos
con la Web es necesario contar con una interfaz que realice las conexiones,
extraiga la información de la base de datos, le dé un formato adecuado de tal
manera que puede ser visualizada desde un browser de la Web, y permita lograr
sesiones interactivas entre ambos, dejando que el usuario haga elecciones de la
información que requiere.
Como podemos ver, en base a
temas anteriores, un servidor Web es un programa que se ejecuta en una
computadora conectada a Internet, donde su trabajo es escuchar en un puerto
TCP/IP predefinido las solicitudes de cliente y luego responder a navegadores
Web con contenido basado en esas solicitudes. Cuando se escribe una dirección
URL en el navegador, es proyectado en una dirección y puerto IP correspondiente
a un servidor Web específico, Después de haber establecido una conexión, el
cliente y el servidor se comunican con el Protocolo de transferencia de
Hipertexto (HTTP). Por lo general el servidor Web envía un bloque de texto HTML
en el navegador, mismo que analiza el HTML y puede solicitar contenido adicional
como información gráfica. El modelo trabaja bien para la información estática,
sin embargo si queremos hacer que nuestra página presente información en base a
las peticiones tecleadas por el usuario, CGI (COMMON GATEWAY INTERFACE) es la
respuesta. El servidor ejecuta un programa CGI como un proceso por separado para
satisfacer las solicitudes de los usuarios, como puede ser una consulta a una
bases de datos. Dado que un programa CGI es externo al navegador Web, puede ser
escrito casi en cualquier lenguaje, ya sea compilado o interpretado. Los
lenguajes populares de CGI son Perl, C, e incluso el shell de UNIX. Algunos
servidores Web ofrecen bibliotecas e intérpretes para JAVA y Visual Basic para
ser utilizados por programas CGI.
En la actualidad existen diferentes
tipos de herramientas para implantar una base de datos en la World Wide Web. La
capacidad y alcance del software disponible depende directamente del hardware
con que se cuente para la implantación de la base de datos, del sistema
operativo en función y del diseño de la misma. Este puede ser centralizado o
distribuido. El servidor de base de datos puede alojarse junto con el servidor
que atiende al navegador o en un servidor o servidores de bases de datos
diferentes, en la misma red o en diversas redes. Otro factor importante es el
número de usuarios esperados para consultar la base de datos y determinar un
rango de usuarios contemplado, así como un crecimiento a futuro de la misma ya
que del tamaño de las tablas dependerá también la rapidez de consulta. La
calidad de los dispositivos de comunicación y la capacidad del servidor tienen
gran relevancia para ofrecer un buen servicio a los usuarios.
Sin duda alguna el factor más
importante para un buen desempeño en el rendimiento, es el sistema operativo.
Esto determina la posible potencia de la base de datos. Los sistemas operativos
han desarrollado base sólidas para este tipo de aplicaciones. Existen en el
mercado sistemas UNIX, Windows, OS/2 con grandes capacidades y con un alto grado
de estabilidad. En los últimos años se han desarrollado sistemas operativos
experimentales con herramientas de comunicación. Un ejemplo de ellos es Linux
que se ha convertido en el sistema operativo para PC con capacidades Internet,
pues configura todos los servicios en una computadora sin exigir gran
requerimiento de hardware. Las máquinas UNIX que corren SunOS, Solaris, HP-UX o
cualquier otra variedad de UNIX son las plataformas preferidas para bases de
datos de gran tamaño. No olvidemos también la aceptación que Windows NT ha
tenido en el mercado de los sistemas operativos de red y la madurez que ha
alcanzando en los últimos Resource Kit.
Al elegir una base de datos se
debe considerar no solo el tipo de dato, si no la cantidad de datos que va a
almacenar. Si la cantidad de registros está en la escala de los cientos de
millones el espacio de almacenamiento se vuelve crucial. Para esto se deben
considerar los controladores nativos del disco duro, controladores SCSI (Small
Computer Systemes Interface) y reflejo de datos. Los controladores SCSI son la
norma en equipos Macintosh y UNIX. Estos pueden manejar hasta siete dispositivos
cada uno y es posible utilizar varios controladores simultáneamente. Los discos
duros también pueden utilizarse para reflejar datos (el reflejo es una técnica
de resguardo de información) en más de una unidad. Si el motor de la base de
datos acepta el reflejo de datos, estos pueden escribirse en dos discos
diferentes para mayor seguridad. Si un disco falla, la base de datos se cambia
automáticamente al otro, cuando la unidad original se devuelve al servicio, la
base actualizará los datos en el disco reparado, o en uno nuevo, para que
concuerde con el disco reflejado. Cuando el disco nuevo está completamente
actualizado, la base conmuta al disco original y continúa reflejando la
información en el disco alternativo.
Hoy en día existen otros métodos de
resguardo de información. La tecnología Raid 5 (Independient Disk Array) es una
de ellas. Este es un sistema de discos independiente con integración de códigos
de error mediante una paridad. Los datos y la paridad son guardados en los
mismos discos, por lo que se consigue aumentar la velocidad de demanda, ya que
cada disco puede satisfacer una demanda independientemente de los demás. En el
Raid 5 guarda la paridad del dato dentro de los discos y no hace falta un disco
para guardar dichas paridades. La paridad se genera haciendo un XOR de los datos
A0,B0,C0,D0 creando la zona de paridad PAR0. La paridad nunca se guarda en los
discos que contienen los datos que han generado dicha paridad, ya que en el caso
en que uno de ellos se estropeara como por ejemplo el dato A0, bastaría con
regenerar la banda B0, C0,DO,PAR0 para que el dato vuelva a
reestablecerse.
Un gateway es una conexión con
el sistema operativo externo, la acción de llamar un programa CGI desde un
navegador Web es muy sencilla para el usuario, lo cual es uno de los principales
atractivos del Common Gateway Interface, el tener acceso a una base de datos a
través de un programa CGI tiene una metodología propia, comúnmente el usuario
hace clic sobre un botón predeterminado o sobre un vínculo, en este momento el
navegador envía una solicitud de ejecutar el programa CGI al servidor Web, el
servidor Web revisa la configuración y los archivos de acceso para asegurarse
que se cuenta con el permiso de ejecución del programa CGI y se asegura de que
este exista , cualquier resultado producido por el programa CGI se devuelve al
navegador Web que despliega el resultado.
Los programas CGI son un gateway de
doble sentido. Los datos pueden transferirse al programa CGI para su
procesamiento, al igual los programas CGI pueden devolver información al
servidor Web. Con esto la información introducida por el usuario puede afectar
el comportamiento del programa CGI, y los resultados devueltos por el programa
son resultado directo de lo que introduce el usuario. En algunos casos los
programas CGI se ejecutan al cargar la página y los resultados se despliegan
como parte de la misma.
La interfaz proporciona un
método para interactuar con una base de datos. Los proveedores de bases de datos
pueden proporcionar una interfaz de varios niveles de complejidad dependiendo de
las necesidades. Los gateway reciben datos transferidos desde un navegador Web
mediante un servidor de HTTP y los convierten a un formato que la base de datos
pueda entender. La información convertida se transfiere a la interfaz de la base
de datos y esta la ejecuta. Los resultados se devuelven al programa de gateway,
el cual los convierte a un formato de manera que el navegador los pueda
desplegar.
Un
gateway no puede trabajar solo, requiere de un tipo de canal para hacer contacto
con la base de datos, este canal lo proporciona la interfaz de la base de datos,
el cual es un software especial que suministra el proveedor. El gateway se
comunica con la interfaz, la cual se pone en contacto con la base de
datos.
Dependiendo de las necesidades de la aplicación, el diseño de base
de datos puede o no tener capacidades de redes, esto lo determina el software
del proveedor, el método más sencillo se alcanza con una base de datos sin
capacidad de red, pues el servidor de HTTP, los programas CGI y el servidor de
la base de datos están ubicados en la misma máquina, de esta forma los programas
CGI tienen acceso a cualquier programa de interfaz que deseen utilizar, las
consultas y los resultados devueltos no van y vienen a los programas CGI a
través de la red, de esta manera se optimiza el tiempo de
respuesta.
Sin
embargo se supone que los navegadores están accediendo a la información de
manera remota, si la base de datos es de mediano o gran tamaño, y hay muchos
usuarios, no es buena idea tener el servidor de base de datos, el servidor de
HTTP en la misma computadora. Si la base de datos incluye capacidades
interconstruidas de redes tiene la opción de correr el servidor de HTTP en una
máquina remota y acceder a la base de datos utilizando el software de bases para
red, muchas veces es preferible ubicar en el servidor de HTTP los programas CGI
y tener una máquina dedicada al servidor de la base de datos para evitar
problemas potenciales y proteger los datos tanto como sea posible, este método
funciona bien si se tiene más de un servidor de base de datos, un solo servidor
de HTTP puede acceder a varias máquinas con bases de datos mediante programas
CGI. Este método aligera la carga de una base de datos y se refleja un notable
incremento en el rendimiento, sin embargo esto sólo vale la pena en el caso de
bases de datos verdaderamente grandes.
Existen diferentes métodos
para transferir información de un navegador Web a un programa CGI, esto depende
de cómo se llame al programa en el documento HTML. Estos pueden
ser:
Por
transferencia de parámetros en la línea de comandos:
El lenguaje HTML proporciona un método
sencillo en la línea de comandos llamado ISINDEX, el método ISINDEX es la única
manera de enviar parámetros de esta forma a un programa CGI. <ISINDEX> es
una etiqueta HTML que debe escribirse dentro de la sección <HEAD> del
documento. En la utilización de ISINDEX el documento HTML y el programa CGI
están escritos en el mismo código.
La razón de ello es que cuando una
página Web utiliza el método ISINDEX, no hay forma de indicarle a dónde enviar
los parámetros en línea de comandos, entonces los parámetros son enviados
asimismo.
Por
transferencia de variables de entorno:
Las variables de entorno permanecen
desde que el Shell de comandos se activa hasta el momento en que se desconecta
de la máquina. Las variables pueden establecerse mediante algunos programas,
algunos buscan en su ambiente para saber cuales son los valores de ciertas
variables, si la variable no existe, el programa puede usar un valor
predeterminado o puede fallar desplegando un mensaje de error.
Un servidor Web utiliza las
variables de ambiente y establece los valores de distintas variables cada vez
que se llama un programa CGI. El programa CGI puede acceder a los contenidos de
esas variables si las necesita y las usa dentro del programa.
Las variables de entorno se
usan para alimentar información a un programa CGI. Un programa CGI se llama en
forma indirecta a través del servidor por el navegador, ya sea con un método de
solicitud HTTP GET o POST. El código CGI debe examinar una variable de entorno
REQUEST_METHOD para determinar si la solicitud fue un GET o un POST, y así, la
manera de obtener la información viene de la interactividad del usuario con una
página Web. La variable de entorno es creada por el servidor Web antes de que se
ejecute el programa CGI. Para el método POST la información llegará a través de
la entrada normal, mientras que con el método GET, la información residirá en la
variable de entorno QUERY_STRING.
La diferencia radica en que una
solicitud que utiliza el método GET pasa variables al incrustarlas en el URL,
esta técnica se conoce como codificación URL, y la porción del URL que codifica
las variables siempre comienza con un signo de interrogación. Esta porción del
URL se pasa al programa CGI como variable de entorno QUERY_STRING. Cada variable
se expresa como un par solicitado de la forma nombre=valor.
Por ejemplo si el valor de mi
nombre es una búsqueda yahoo, la solicitud se traduce en:
HTTP://av.yahoo.com/bin/search?p=carlos+jimenez
El URL informa al programa CGI receptor
que la variable p debe recibir el valor "carlos jimenez. Asimismo parte de la
codificación URL está compuesta por una variable de caracteres
especiales.
Transferencia de datos mediante entrada estándar :
Esta es la manera en como los
formularios HTML envían datos capturados por medio de listas de selección,
casillas de verificación, cuadros de entrada de texto y otras características
interactivas disponibles al servidor de HTTP y al programa CGI.
Generalmente la entrada
estándar es la terminal que está utilizando el usuario para correr el programa,
si un programa produce algún dato resultante mediante la ejecución del programa,
el resultado llega a la pantalla terminal mediante la salida estándar. Si el
programa produce algún mensaje de error, se envía a la pantalla por medio del
error estándar. Entrada, salida y error estándares son canales de datos
proporcionados por el sistema operativo para conectar un dispositivo de
entrada/salida, como su terminal a una pieza de software que sea capaz de enviar
o recibir datos. El servidor de HTTP puede recibir información enviada por el
usuario y transferirla a un programa CGI mediante la entrada estándar, para
después obtener los resultados mediante la salida estándar.
A diferencia de ISINDEX, el
servidor HTTP no procesa los argumentos antes de enviarlos al programa CGI. Los
argumentos llegan codificados al programa tal y como los envía el
navegador.
Cuando alguien usa un
navegador Web para acceder a una base de datos hay varios componentes que
intervienen para transferir la consulta del usuario a la base de datos y
devolver los resultados al navegador, la acción se desarrolla de la siguiente
manera:
1. El
usuario llama a un programa gateway que utiliza CGI, haciendo clic en un
Hipervínculo u oprimiendo un botón del formulario.
2. El navegador reúne toda la
información escrita por el usuario para enviarla al programa CGI.
3. El navegador contacta al
servidor de HTTP en la máquina donde reside el programa CGI, pidiéndole que
localice a este último y le transfiere la información.
4. El servidor de HTTP corrobora si la
máquina solicitante tiene autorización de acceso al programa CGI.
5. Si el usuario tiene
acceso, el servidor de HTTP localiza el programa gateway y transfiere a este la
información del navegador Web.
6. Se ejecuta el programa
Gateway.
7. El
proceso Gateway convierte la información recibida a un formato que la base de
datos sea capaz de entender.
8. El Gateway usa el módulo de la base de datos para transferir la
consulta a la interfaz de la base.
9. La interfaz de la base de datos
analiza la sintaxis de la consulta para asegurar que sea precisa.
10. Si la interfaz encuentra
un error de sintaxis en la consulta, se envía un mensaje de error al programa
Gateway.
11. El
mensaje de error se envía al servidor de HTTP, el cual lo transfiere al
navegador Web para que este lo despliegue al usuario.
12. Si no hay error, la interfaz envía
la consulta a la bases de datos.
13. La base de datos atiende la
consulta y devuelve los resultados al programa gateway a través de la
interfaz.
14.
El programa gateway formatea los resultados y los envía al servidor, por medio
del CGI, para su envío al navegador Web.
15. El navegador Web despliega los
resultados
Hacer inserciones,
actualizaciones y eliminaciones requiere de un procedimiento más complejo que el
necesario para hacer simples consultas. El código de inserción debe verificar si
existen los datos en la base de datos, con el fin de evitar duplicidad en la
información, el código de actualización debe asegurarse que la información
exista, antes de modificarla, en caso contrario debe originarse un error. Las
acciones de eliminación y edición debe de asignarse a un grupo reducido y
confiable para evitar la eliminación de datos necesarios.
Para procesar algo mas que
una simple consulta en un ambiente de esta naturaleza, es necesario algún tipo
de control de acceso como lo pueden ser el comparar el identificador de conexión
del usuario contra una lista de usuarios autorizados para determinada acción,
asignar a cada tipo usuario un identificador de conexión y asignar a cada tipo
nivel un nivel de acceso basándose en las funciones que tienen permitidas o
utilizar la autenticación de clave de acceso de la base de datos destino para
validar los niveles de acceso a los usuarios. En definitiva, el método que
utilice depende de como planee utilizar el programa de gateway.
La mayoría de las páginas Web tienen el formato HTML. Estos archivos son sencillos archivos de texto ASCII con códigos que indican formatos y vínculos de hipertexto. Las especificaciones de HTML están cambiando constantemente.
Diseño de archivos HTML
Para crear y modificar sus
archivos HTML puede usar cualquier editor de textos, como el Bloc de notas o
Write, pero normalmente encontrará que un editor HTML, como Microsoft(r)
FrontPage(tm) o Internet Assistant para Microsoft(r) Word, es más fácil de
usar.
Para
crear archivos HTML, que pueden incluir vínculos con otros archivos del sistema,
use un editor HTML o cualquier otro sistema. Si desea incluir imágenes o
sonidos, también necesitará el software apropiado para crear y modificar dichos
archivos.
Publicación de archivos con formato HTML y otros formatos
Los archivos pueden contener
imágenes y sonidos. Puede crear incluso vínculos con archivos de Microsoft(r)
Office o con casi cualquier otro formato de archivo. Los usuarios remotos tiene
que disponer de la aplicación visora apropiada para poder ver los archivos que
no sean HTML. Por ejemplo, si sabe que todos los usuarios remotos disponen de
Microsoft Word, puede incluir vínculos con archivos .doc de Microsoft Word. El
usuario puede hacer clic en el vínculo y en el equipo del usuario aparecerá el
documento de Word.
Una vez que haya creado la información en formato HTML o en otros
formatos, puede copiarla al directorio predeterminado InetPub\Wwwroot, o bien
puede cambiar el directorio particular predeterminado por el directorio que
contenga su información.
Si su sitio Web incluye
archivos que están en varios formatos, su equipo debe tener una asociación de
Extensión de correo Internet multipropósito (MIME) por cada tipo de archivo. Si
en el servidor no hay una asociación MIME para un determinado tipo de archivo,
los exploradores no podrán recuperar el archivo. Examine el Registro de
configuraciones de Windows NT para ver las asociaciones MIME
predeterminadas.
Para configurar asociaciones MIME adicionales, inicie el Editor
del Registro (Regedt32.exe) y abra
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\InetInfo\Parameters\MimeMap
Agregue el valor REG_SZ de la
asociación MIME necesaria en su equipo con la siguiente sintaxis:
<tipo
MIME>,<extensión de archivo>,<parámetro no usado>,<tipo
gopher>
Por
ejemplo:
text/html,htm,/unused,1
image/jpeg,jpeg,/unused,5
La cadena asociada con el valor (es decir, el contenido del valor) debe estar en blanco. La entrada predeterminada con la extensión de archivo asterisco (*) es el tipo MIME predeterminado que se usa cuando no existe ninguna asociación MIME. Por ejemplo, para administrar una petición del archivo Current.vgr cuando la extensión .vgr no se ha asociado a un tipo MIME, el equipo usará el tipo MIME especificado para la extensión *, que es el tipo usado para datos binarios. Normalmente, esto hace que los exploradores guarden el archivo en el disco.
Inclusión de otros archivos con la instrucción Include
Puede agregar información
repetitiva a un archivo HTML justo antes de enviarlo al usuario. Esta
característica es interesante cuando se incluye el mismo texto en todas las
páginas HTML, como la información de derechos de autor o un vínculo con la
página principal.
El formato de la instrucción Include es la
siguiente:
<!--#include file="valor"-->
El valor tiene que contener una ruta
relativa o la ruta completa, desde el directorio particular del servicio
WWW.
Por ejemplo, para incluir un vínculo con la página principal en todos los documentos HTML:
1. Cree el archivo
Linkhome.htm, que contiene los códigos HTML que quiere repetir; por ejemplo, un
botón que conduzca a su página principal. El archivo contendría código HTML
parecido al siguiente:
<A HREF="/homepage.htm"><IMG
SRC="/button_h.gif"></A>
2. Use la extensión de archivo .stm al
crear las páginas Web (en lugar de .htm o .html).
Notas: La extensión .stm informa a
Internet Information Server de que en el archivo hay una instrucción Include. Si
da un nombre al archivo con una extensión .htm o .html, la instrucción Include
se pasará por alto.
La utilización de archivos .stm puede afectar al rendimiento. Por
tanto, se recomienda utilizar dicha extensión sólo cuando sea absolutamente
necesario.
Sin
embargo, en el Registro de Windows NT puede cambiar la extensión .stm
predeterminada por cualquier otra extensión, excepto .htm o .html.
3. En cada archivo .stm, use
una instrucción include file donde quiera que aparezca la información que se
repite. Por ejemplo:
Puede volver a: <!--#include file="/linkhome.htm"--> en
cualquier momento
Observe que todas las rutas son relativas al directorio particular
de WWW y que pueden incluir directorios virtuales.
Una de las características más
atractivas de Microsoft Internet Information Server es la posibilidad de
desarrollar aplicaciones o archivos de comandos que los usuarios remotos inician
haciendo clic en vínculos HTML o completando y enviando un formulario HTML.
Usando lenguajes de programación como C o Perl, puede crear aplicaciones o
archivos de comandos que se comuniquen con el usuario mediante páginas dinámicas
HTML.
Creación
de aplicaciones o archivos de comandos
Las aplicaciones o los archivos de
comandos interactivos se pueden escribir en casi cualquier lenguaje de
programación de 32 bits, como C o Perl, o como archivos de proceso por lotes de
Windows NT (que tienen la extensión .bat o .cmd). Al escribir las aplicaciones o
los archivos de comandos puede usar una de las dos interfaces compatibles, la
Interfaz de programación de aplicaciones de Microsoft Internet Server (ISAPI) o
la Interfaz de puerto de enlace o gateway común (CGI). La documentación sobre
ISAPI está disponible en Microsoft mediante la suscripción a Microsoft Developer
Network (MSDN). En este capítulo se ofrece una introducción a CGI; la
documentación sobre CGI está disponible en Internet. Los archivos de proceso por
lotes pueden contener cualquier comando válido en el símbolo del
sistema.
Las
aplicaciones que usan ISAPI se compilan como bibliotecas de vínculos dinámicos
(DLL) que el servicio WWW carga al iniciarse. Como los programas residen en
memoria, los programas ISAPI son considerablemente más rápidos que las
aplicaciones escritas con la especificación CGI.
Hip, Inc., el distribuidor
independiente de software que desarrolla Perl para plataformas Win32, ha
desarrollado una versión de Perl que se ejecuta como una aplicación ISAPI. Esto
significa que los archivos de comandos de servidor de Perl pueden ejecutarse
mucho más deprisa que antes al sacar el máximo partido del modelo de proceso
interno de ISAPI. Actualmente, se puede cargar una versión no compatible de
ISAPI Perl en http://www.perl.hip.com/. En este sitio WWW también encontrará más
información al respecto. Para plantear sus dudas o enviar sus comentarios,
utilice el alias de correo electrónico [email protected], sobre todo si ya
dispone de archivos de comandos de Perl.
ISAPI para Windows NT se puede
utilizar para escribir aplicaciones que los usuarios de Web pueden activar
completando un formulario HTML o haciendo clic en un vínculo de una página HTML
de su sitio Web. La aplicación remota puede aceptar información introducida por
el usuario y tratarla de cualquier modo que se pueda programar, y después
devolver los resultados en una página HTML o enviar la información a una Base de
datos.
ISAPI se
puede usar para crear aplicaciones que se ejecuten como DLL en su servidor Web.
Si ha utilizado archivos de comandos CGI anteriormente, encontrará que las
aplicaciones ISAPI tienen un mejor rendimiento porque se cargan en memoria
durante la ejecución del servidor. Requieren menos tiempo de espera porque cada
petición no inicia un proceso distinto.
Internet Information Server puede
publicar tanto información como aplicaciones. Esto quiere decir que su sitio Web
puede contener desde páginas estáticas de información hasta aplicaciones
interactivas. También puede buscar y extraer información de bases de datos e
insertar información en las mismas.
Con este ejemplo de aplicación
explicaremos cómo:
* Preparar su equipo y la información que va a
publicar.
*
Instalar y utilizar aplicaciones interactivas en el equipo.
* Publicar usando orígenes de
datos que sean compatibles con Open Database Connectivity (ODBC).
Interfaz de puerta de enlace o
gateway común (CGI) es un conjunto de especificaciones para transferir
información entre el explorador de un cliente Web, un servidor Web y una
aplicación CGI. El explorador de un cliente Web puede iniciar una aplicación CGI
completando un formulario HTML o haciendo clic en un vínculo de una página HTML
del servidor Web. Como ocurre con ISAPI, la aplicación CGI puede aceptar
información escrita por el usuario y tratarla de cualquier modo que se pueda
programar, y después devolver los resultados en una página HTML o enviar la
información a una base de datos. Como las aplicaciones CGI sencillas a menudo
están escritas con lenguajes de archivos de comandos como Perl, a las
aplicaciones CGI también se les conoce como "archivos de
comandos".
Microsoft Internet Information Server puede usar la mayoría de las
aplicaciones de 32 bits que se ejecuten en Windows NT y cumplan las
especificaciones CGI.
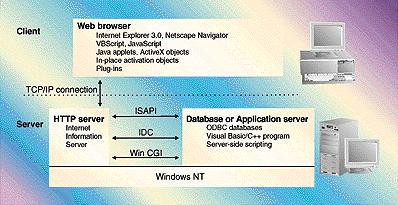
La siguiente ilustración muestra cómo intercambian información un
explorador, un servidor y una aplicación CGI utilizando CGI. El resto de esta
sección trata sobre este proceso que consta de cinco partes.
El cliente envía una petición
El explorador de un cliente
puede realizar una petición CGI a un servidor mediante uno de estos dos
métodos:
GET
El cliente añade los datos a la dirección URL que pasa al
servidor.
POST
El cliente envía los datos al servidor mediante el campo de datos
de mensajes HTTP, por lo que se pueden superar las limitaciones de espacio
inherentes al método GET.
El cliente inicia un proceso CGI haciendo clic en cualquiera de
los elementos siguientes de una página HTML:
* Un vínculo de hipertexto que ejecute
el archivo de comandos directamente.
* El botón "Enviar" de un formulario
HTML.
* Un
objeto en línea recuperado con el método GET.
* Un objeto de búsqueda (es decir, uno
que utiliza la etiqueta ISINDEX de HTML).
El servidor recibe la petición
La dirección URL que el
explorador del cliente envía al servidor contiene el nombre del archivo de
comandos CGI o la aplicación que va a ejecutarse. El servidor compara la
extensión del archivo con la clave de registro ScriptMapping del servidor para
decidir qué ejecutable debe iniciar. El servidor tiene entradas ScriptMap para
archivos .cmd y .bat, que inician Cmd.exe; y para archivos .idc, que inician el
Conector de bases de datos de Internet. Para permitir que el servidor inicie un
tipo de aplicación CGI sin asignación de extensión, agregue una entrada para
dicho tipo de aplicación a la clave del registro. Por ejemplo, para permitir la
ejecución de los archivos de comandos de Perl, agregue una entrada similar a la
siguiente:
.pl:
REG_SZ: C:\RESKIT\PERL\BIN\PERL.EXE %s %s
Donde
* \Reskit\Perl\Bin\ es el directorio
que contiene el ejecutable.
* Perl.exe es el comando ejecutado.
* El primer %s es la ruta de acceso
traducida del archivo de comandos de PERL (la dirección URL traducida a una ruta
de acceso local).
* El segundo %s es la cadena de consultas (información de la
dirección URL) y sólo se pasa como un parámetro de la línea de comandos si la
cadena de consultas no contiene el signo igual (=).
El servidor pasa la petición a la aplicación
El servidor pasa la información a la aplicación CGI utilizando variables de entorno y, a continuación, inicia la aplicación. Algunas de estas variables están relacionadas con el servidor pero la mayoría vienen del explorador del cliente y tienen relación con el explorador del cliente o con la petición que se está enviando. Para obtener una lista parcial de las variables de entorno, consulte la tabla de variables incluida al final de este capítulo.
La aplicación CGI devuelve los datos al servidor
La aplicación realiza su
procesamiento. Si son adecuados, la aplicación escribe los datos en un formato
que el cliente pueda recibir en el flujo de salida estándar (STDOUT). La
aplicación debe seguir un formato específico a la hora de devolver los
datos:
1. La
primera o primeras líneas contienen las directivas del servidor, así como el
tipo de contenido MIME. Otras directivas del servidor son Location (que el
cliente redirige o devuelve a otro documento) y Status.
2. A continuación de las directivas del
servidor debe haber una línea en blanco.
3. Los datos que la aplicación devuelve
al cliente siguen a la línea en blanco.
El servidor devuelve los datos al cliente
El servidor toma los datos que
recibe de STDOUT y agrega encabezados HTTP estándar y, a continuación, devuelve
el mensaje HTTP al cliente.
Para obtener más información acerca de CGI, consulte las
especificaciones de CGI en http://hoohoo.ncsa.uiuc.edu/cgi/.
El servicio WWW es compatible
con la especificación CGI (Interfaz de puerta de enlace o gateway común)
estándar. No obstante, debe ser consciente de lo siguiente, exclusivo para la
implementación de CGI en Internet Information Server:
* En esta versión, solo las
aplicaciones CGI de 32 bits funcionan con el servicio WWW.
* La variable de entorno
REMOTE_USER no está presente cuando el usuario inicia una sesión como usuario
anónimo (es decir, cuando se tiene acceso al servidor Web de forma
anónima).
*
Todas las variables definidas para aplicaciones ISAPI se pasan a las
aplicaciones CGI como variables de entorno.
Se dará cuenta de que las aplicaciones
CGI suelen ser ejecutables independientes en contraste a las aplicaciones ISAPI,
que suelen cargarse como DLL y son, por tanto, extensiones del servidor. Por
consiguiente, las aplicaciones ISAPI proporcionan mejor rendimiento que las
aplicaciones y archivos de comandos CGI.
Consideraciones acerca de la seguridad de los ejecutables
Los ejecutables CGI deben
utilizarse con mucho cuidado para evitar posibles riesgos de seguridad para el
servidor. Como regla general, sólo debe dar permiso de Ejecución a aquellos
directorios virtuales que contengan aplicaciones CGI o ISAPI (API de Internet
Server).
Recomendamos encarecidamente que configure la asignación de
archivos de comandos, ya que ésta garantiza que se inicie el intérprete correcto
(por ejemplo, Cmd.exe) cuando un cliente solicita un archivo
ejecutable.
A
los directorios de contenido de World Wide Web sólo hay que asignarles permiso
de Lectura. Aquellos archivos ejecutables cuya finalidad sea descargarlos desde
las unidades con el Sistema de archivos de Windows NT (NTFS) sólo deben tener
permiso de Lectura.
Es posible ejecutar archivos por lotes como archivos ejecutables
CGI, aunque debe hacerlo como mucho cuidado para que el servidor no sufra ningún
daño.
Nota: Los
archivos ejecutables de CGI también pueden tener las extensiones de archivo .exe
o .cgi.
Permiso
de ejecución para aplicaciones ISAPI
Internet Information Server abre
aplicaciones ISAPI en el contexto de seguridad del usuario que llama. Dicho
usuario debe pasar una comprobación de seguridad. Para restringir la ejecución
de usuarios seleccionados, los permisos de NTFS pueden utilizarse con
aplicaciones ISAPI, como el Conector de Bases de Datos de Internet
(IDC)
Por
ejemplo, para asegurar el IDC sin poner permisos en el archivo .idc, puede
otorgar permiso de Ejecución de NTFS para Inetsrv\Httpodbc.dll a los usuarios
adecuados. Httpodbc.dll es el nombre de la DLL de la aplicación ISAPI que
implementa el IDC. Posteriormente, cada vez que un usuario intente ejecutar el
IDC, el servidor comprobará los permisos y sólo se permitirá el acceso a
aquellos usuarios que dispongan de permiso de Ejecución.
Nota: Tras cargar una aplicación ISAPI,
ésta permanece cargada hasta que el servicio WWW se detiene. Una vez que la
aplicación ISAPI se ha cargado, Internet Information Server no realiza un
seguimiento de los cambios del descriptor de seguridad. Si cambia los permisos
para una aplicación ISAPI después de haberse cargado, tendrá que detener y
reiniciar el servicio WWW antes de que dicho cambio surta efecto.
Tenga cuidado a la hora de
definir las Listas de control de acceso (ACL) del directorio Winnt y sus
subdirectorios. Algunas aplicaciones y bases de datos ISAPI requieren acceso a
algunos archivos y DLL de estos directorios.
Nota: Las DLL de las aplicaciones ISAPI
pueden tener la extensión de archivo .dll o .isa.
Instalación de su aplicación en
Internet Information Server
Una vez que haya escrito la aplicación o el archivo de comandos,
colóquela en el directorio Scripts, un directorio virtual para aplicaciones.
Este directorio virtual tiene acceso de Ejecución.
También tiene que asegurarse de que
cualquier proceso iniciado por la aplicación se ejecuta usando una cuenta con
los permisos correctos. Si la aplicación interactúa con otros archivos, la
cuenta asignada al programa debe disponer de los permisos necesarios para usar
dichos archivos. De forma predeterminada, las aplicaciones se ejecutan usando la
cuenta IUSR_nombreequipo, que debe tener permisos de Administrador y Ejecución
para los archivos de la aplicación.
Ejecución de su aplicación
Si su aplicación no requiere
que el usuario escriba datos, normalmente creará un vínculo con dicha aplicación
en un archivo HTML sencillo. Si su aplicación requiere que el usuario escriba
datos, probablemente usará un formulario HTML. En otros casos puede enviar una
dirección URL, normalmente con parámetros, para llamar al
programa.
Un
vínculo HTML con una aplicación que no requiera que el usuario escriba datos
podría ser como el siguiente ejemplo:
http://www.organizacion.com/scripts/catalogo.exe
donde Scripts es el
directorio virtual para aplicaciones interactivas.
Si va a crear una aplicación que
requiera que el usuario escriba datos, tiene que conocer los formularios HTML y
cómo usarlos con ISAPI o con CGI. Puede encontrar esta información en Internet y
en otros lugares.
Asociación de intérpretes con aplicaciones
Como dispone de la
flexibilidad para crear aplicaciones en casi cualquier lenguaje de programación,
Internet Information Server utiliza la extensión del archivo para determinar el
intérprete que se llama para cada aplicación. A continuación se muestran las
asociaciones de intérpretes predeterminadas. Para crear asociaciones
adicionales, puede usar el Editor del registro de configuraciones.
Extensión
Intérprete
predeterminado
Extensión
Intérprete
predeterminado
.bat, .cmd
Cmd.exe
.idc
Httpodbc.dll
.exe, .com
System
Cuando permite que usuarios
remotos ejecuten aplicaciones en su PC, corre el riesgo de que algún pirata
intente entrar en su sistema. Microsoft Internet Information Server está
configurado de forma predeterminada para reducir el riesgo de intrusismo
malintencionado, de dos maneras.
En primer lugar, el directorio virtual
Scripts contiene las aplicaciones y está marcado como directorio de
aplicaciones. Sólo un administrador puede agregar programas a un directorio
marcado como directorio de aplicaciones. Así, los usuarios no autorizados no
pueden copiar y ejecutar un programa con malas intenciones en su PC sin tener
privilegios de administrador.
Es recomendable que otorgue permiso de Lectura y Ejecución a la
cuenta IUSR_nombreequipo del directorio asociado a la carpeta virtual y sólo
otorgue Control total al administrador. Los archivos de comandos de Perl
(extensión de archivo .pl) y los archivos IDC (extensiones de archivos .idc y
.htx) necesitan permiso de Lectura y Ejecución. No obstante, para evitar que
alguien instale algún archivo poco seguro en su servidor, no otorgue permiso de
Escritura.
En
segundo lugar, si el servicio WWW se ha configurado para permitir sólo inicios
de sesión anónimos, todas las peticiones de los usuarios remotos usarán la
cuenta IUSR_nombreequipo. De forma predeterminada, la cuenta IUSR_nombreequipo
no puede eliminar o modificar archivos usando el Sistema de archivos de Windows
NT (NTFS) a menos que el administrador le haya dado permiso para ello de manera
específica. Así, incluso si se hubiera introducido un programa
malintencionadamente en su PC, no podría provocar muchos daños en su contenido
porque sólo tendría acceso de IUSR_nombreequipo al equipo y a los
archivos.
Con el servicio WWW y los
controladores ODBC que proporciona Internet Information Server,
puede:
* Crear
páginas Web con información contenida en bases de datos.
* Insertar, actualizar y eliminar
información de la Base de datos según la entrada del usuario en una página
Web.
* Ejecutar
otros comandos del Lenguaje de consulta estructurado (SQL).
Funcionamiento del Conector
de bases de datos de Internet
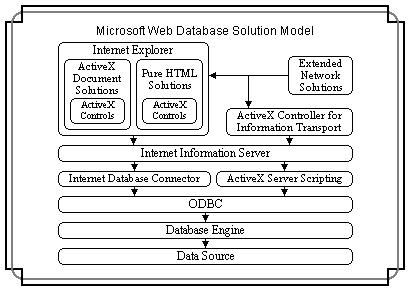
En el siguiente diagrama se muestra conceptualmente el acceso a
bases de datos desde Internet Information Server.
Los exploradores de Web (como
Internet Explorer o los exploradores de otros fabricantes como Netscape) remiten
peticiones al servidor Internet usando HTTP. El servidor Internet responde con
un documento en formato HTML. El acceso a las bases de datos se realiza mediante
un componente de Internet Information Server llamado Conector de bases de datos
de Internet (IDC). El Conector de bases de datos de Internet, Httpodbc.dll, es
una DLL ISAPI que utiliza ODBC para tener acceso a las bases de
datos.
La
siguiente ilustración muestra los componentes de Internet Information Server
para conectar con las bases de datos.
El IDC utiliza dos tipos de
archivos para controlar la forma de acceso a la Base de datos y el modo en que
se construye la página Web de salida. Dichos archivos son archivos del Conector
de bases de datos de Internet (.idc) y archivos de extensión HTML
(.htx).
Los
archivos del Conector de bases de datos de Internet contienen la información
necesaria para conectar con el origen de datos ODBC adecuado y ejecutar la
instrucción SQL. Además, contienen el nombre y la ubicación del archivo de
extensión HTML.
El archivo de extensión HTML constituye la plantilla para el
documento HTML real que se devolverá al explorador de Web cuando el IDC haya
combinado su información con la Base de datos.
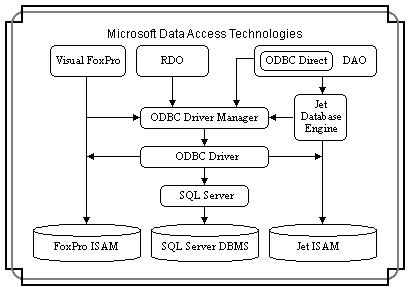
Instalación de ODBC y creación de los
orígenes de datos del sistema
Cuando selecciona la opción ODBC durante la instalación, se
instalan los componentes de ODBC versión 2.5. Esta versión de ODBC acepta DSN
(Nombres de origen de datos) del sistema y es necesaria para utilizar ODBC con
Microsoft Internet Information Server.
Los DSN del sistema se introdujeron en
la versión 2.5 de ODBC para permitir que los servicios de Windows NT usaran
ODBC.
El conector de bases de datos
de Internet requiere controladores ODBC de 32 bits. Para obtener información
acerca de la opción ODBC, vea los archivos de Ayuda de Internet Information
Server o el archivo de Ayuda de ODBC para Windows NT.
Controladores ODBC de Microsoft
Access
El
Conector de bases de datos de Internet requiere los controladores ODBC de 32
bits que se incluyen en Microsoft(r) Office 95 y Microsoft(r) Access 95. El
controlador ODBC de Microsoft Access 2.0 no funcionará con Internet Information
Server.
Creación de páginas Web con bases de datos de Access
Para proporcionar acceso a
una Base de datos SQL desde su página Web, necesitará crear un archivo del
Conector de bases de datos de Internet (extensión de archivo .idc) y un archivo
de extensión HTML (extensión de archivo .htx).
LINKS