Ábra 12. Függõségi viszonyok sync változókkal
Párhuzamos programozást támogató nyelvi eszközök összehasonlítása: Nyelvek, eszközök: CC++
2.4
CC++
Compositional C++ a C++ nyelv egy kiegészítése
párhuzamos elemekkel. A kiegészítésekkel a nyelv
alkalmas lesz folyamat és utasítás szintû
párhuzamosság kezelésére. Osztott
adattípusok implementálására, és
párhuzamosan futó programrészek közötti
kommunikáció és szinkronizáció
lépéseinek leírására.
2.4.1
Bevezetõ az eszközrõl
A CC++ nyelvet a kaliforniai California Institute of Technologie
egyetemen fejlesztik. Ez a nyelv most is még a fejlesztés
állapotában van, de megoldásait már más
nyelvek is átvették (pC++ és HPC++).
A nyelvet jelenleg Solaris 2.3 és 2.4, AIX 3.2.5 valamint IBM SP1-es rendszereken lehet használni. Minden helyen szükség van C++ fordítóra és egy thread könyvtárra is (a C++ fordító a GNU C++ fordító is lehet).
A CC++ nyelv a C++ nyelv kiterjesztése, azaz minden helyes C++ program helyes CC++ program is. Egy CC++ program lefordításához szükség van CC++ fordítóra és a hozzá tartozó könyvtárakra. Az így elkészített program futtatása a nyelvhez készített Nexus kommunikációs rendszerrel lehetséges.
A CC++ nyelv a következõ kiegészítéseket adja a párhuzamosság támogatására:
Itt csak a C++ és a CC++ nyelv közötti eltérésekrõl lesz szó, a C++ nyelvrõl nem.
Egy többprocesszoros, osztott memóriát használó rendszerben hatékonysági, vagy egy egyprocesszoros rendszerben a program egyszerûbb szerkezete érdekében szükségünk lehet több szálon futó programok írására. Erre e célra a CC++ nyelv a par, parfor és spawn kulcsszavakat biztosítja.
A par kulcsszóval a C nyelv szokásos blokk fogalmát lehet átalakítani párhuzamos blokká:
par {
a = 2;
b = 3 * 4;
}
Az
így definiált blokk utasításai
külön-külön lesznek végrehajtva egy-egy
önálló szálként a fõprogramban. Ha a
futtató rendszerben több processzor is rendelkezésre
áll, akkor ezek az utasítások valóban
párhuzamosan is végrehajtódhatnak. Az
utasítások végrehajtásának
sorrendjére a nyelv semmilyen megkötést nem tesz, és
a szálak közötti igazságos idõmegosztást
sem határozza meg, ezért a következõ
konstrukciók veszélyesek lehetnek:
a = 1;
par {
while(a);
a = 0;
}
Veszélyes,
mert lehet, hogy csak a végtelen ciklus fog futni.
par {
b = 3;
a = b * 2;
}
Veszélyes,
mert lehet, hogy elõbb a kap értéket.
A par blokk végén az elindított szálak megvárják egymást, és a blokk lefutása után megszûnnek, tehát a blokk vége egy implicit szinkronizációt tartalmaz.
Párhuzamos blokkok egymásba ágyazhatóak, és bármilyen CC++-beli utasítást tartalmazhatnak. Az egyetlen kikötés az, hogy nem tartalmazhatnak változó deklarációt, hiszen ennek a szemantika szempontjából nem lenne semmi értelme (a változó deklarációját kiértékelõ utasítás a többi utasítással párhuzamosan hajtódna végre).
A parfor kulcsszóval párhuzamosan végrehajtott ciklusmagokat lehet létrehozni. Az ilyen ciklusok fejrésze végigfut a ciklusváltozó lehetséges értékein, és az egyes értékekre a ciklusmagok egy-egy példányát több szálon elindítja, a ciklusmag utasításait szekvenciálisan futtatva:
int A[N]; parfor(int i=0; i<N; i++) A[i] = work(i);
A parfor kulcsszó a for kulcsszó helyett használható. A párhuzamos ciklusokra a következõ megkötések érvényesek:
Ezekkel a megkötésekkel a CC++ parfor ciklusa már Ada ciklusként is megírható, hiszen ott is ezek a szabályok érvényesek a ciklusváltozóra.
A ciklus lefutása után az újonnan indított szálak megvárják egymást, majd befejezik mûködésüket.
Nem strukturált elem az új spawn kulcsszó által bevezetett párhuzamosság:
void f(...); spawn f();
A spawn kulcsszóval eljárásokat lehet a fõprogramtól független végrehajtási szálon elindítani. Az ilyen függvények visszatérési típusa void kell, hogy legyen, hiszen nem térnek vissza a fõprogramhoz. A spawn-nal elindított függvények futása teljesen független szálon történik, semmilyen implicit szinkronizáció nem jön létre, mint az elõzõ két konstrukciónál.
A független futásnak megvannak a veszélyei is:
E három konstrukció tehát ugyanazt a lokális memóriaterületet használó folyamatszálak indítására szolgál. Az ilyen folyamatok indítása csak számolásigényes feladatoknál, vagy szemantikai szükségszerûségbõl indokolt az erõforrás-igény nagysága miatt. Egészekbõl álló tömb elemeinek inicializálására - ld. fent - ezek a konstrukciók nagy teljesítménycsökkenést eredményezhetnek.
class Value {
private:
int a;
public:
atomic void assign(int i)
{ a = i; }
};
int main(int argc; char *argv[])
{
Value v;
par {
v.assign(1);
v.assign(2);
}
}
Az
atomic kulcsszót osztályok
tagfüggvényeinek definiálásakor a static
és a virtual kulcsszavakkal megegyezõ módon lehet
használni. Az így deklarált tagfüggvények
köré a fordító egy szinkronizációs
kódot rak, amely gondoskodik róla, hogy a
tagfüggvénybõl egyszerre csak egy példány
futhasson egy objektumon belül. Ha az objektum bármely atomi
tagfüggvényét ezalatt egy másik
végrehajtási szálból is meghívják,
akkor annak a futása az atomi függvény
lefutásának idejére fel lesz függesztve.
Ez a viselkedés a monitorok kölcsönös kizárásának megfelelõ.
Veszélyes helyzetek elkerülése végett érdemes betartani a következõ szabályokat:
Az egyetlen megkötés a nyelvben az atomic kulcsszó használatával kapcsolatban az, hogy nem szerepelhet a static kulcsszóval együtt, mert az összes párhuzamossággal kapcsolatos konstrukció csak objektumok szintjén érvényesíthetõ (nincs önállóan futó osztály-objektum, amiben ezek kezelhetõek lennének).
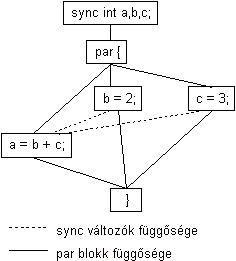
{
sync int a, b, c;
par {
a = b + c;
b = 2;
c = 3;
}
// a == 5, b ==2, c == 3
return a;
}
A sync kulcsszó típusmódosításra használható. Az így definiált változó egy késleltetett inicializálású konstans, avagy egy egyszer meghatározható értékû változó lesz.
A sync változónak csak egyszer lehet értéket adni - nem feltétlenül a létrehozásakor, mint a const változónak -, és ezt az értéket csak ezután lehet belõle lekérdezni. Ha egy folyamat az érték meghatározása elõtt szeretné megtudni egy ilyen változó értékét, akkor annál a pontnál a futása felfüggesztõdik, és addig fog várakozni, amíg egy másik folyamat nem inicializálja az adott változót. Az inicializálás után a változó konstansként viselkedik, bármely újabb értékadási kísérlet futás idejû hibához vezet.
A fenti példa a par blokk ellenére meghatározott végeredménnyel fog lezárulni, mert az a változóhoz csak a b és c változók ismert értéke után rendelõdhet érték. A sync változók hatására a program futása:
Ábra 12. Függõségi viszonyok sync változókkal
Sync típusmódosítót függvények argumentumlistájában és visszatérési értékénél is lehet használni, jelentése ott is hasonló lesz.
Az egyszeres értékadású változót nem lehet típuskényszerítéssel, vagy címének meghatározásával hagyományos változóvá konvertálni, és ezzel kikerülni a védõ mechanizmusát. Ebben a viselkedésben teljesen megegyezik a const változók használatánál betartandó szabályokkal.
Egy ilyen változó élettartalma a szokásos láthatósági viszonyoknak megfelelõ élettartammal egyezik meg. Ha a lokális sync változó nem elég, akkor persze lehet deklarálni dinamikusan lefoglalt változatát is:
{
sync int *a = new sync int;
*a = 3;
}
Ahhoz hogy több processzoron futó program külön memóriákban futó részei között valamilyen kapcsolat alakuljon ki a CC++ nyelv a *global típusmódosítót vezette be. Ez a kulcsszó a volatile, és register típusmódosítókkal egyezõen használható változók definiálásakor.
A globális mutatók (pl. int *global a) különálló memóriákban futó folyamatok számára is közösen láthatóvá tesznek memóriarészeket. A különbséget az egyes folyamatok számára alapvetõen az elérés ideje jelenti majd. Az a folyamat, amely memóriájában tartalmazza a változót sokkal gyorsabban tudja majd elérni azt, mint egy távoli társa. A hivatkozásban a két folyamat között nem lesz semmi jelölésbeli különbség, csak az elérés módszerében.
int *global pi; int * *global ppi; C *global pC;
Ezek a mutatók bármilyen típusra mutathatnak, kivéve a függvényeket.
Globális változók elérése a rendes mutatókkal megegyezõ:
int x = *pi + 1; int x += **pi;A használat során a programozónak nem kell figyelnie arra, hogy a változó valójában melyik processzor memóriájában foglal helyet.
Ha az adott mutató egy objektum, akkor annak tagfüggvényei is elérhetõek a mutatón keresztül:
pC->megoldas(42);Ábra 13. Távoli eljáráshívás CC++-ban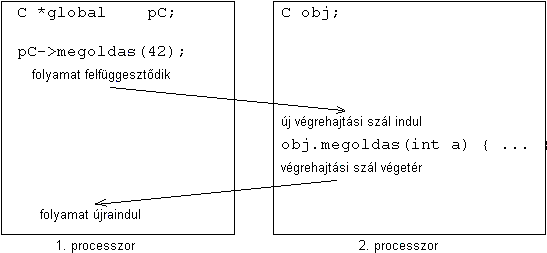
Ennél a lépésnél az éppen futó folyamat futása felfüggesztõdik, és a távoli objektum tagfüggvénye távoli eljáráshívással végrehajtódik. A végrehajtás idejére a globális mutatóval jelzett objektum processzorán egy új szál jön létre a tagfüggvény lefuttatására. Globális mutatóval jelölt objektumok tagfüggvényei közül ezért egyszerre több is futhat.
A távoli objektum konzisztenciája érdekében az ilyen távoli eljáráshívásban résztvevõ tagfüggvényeket atomic vagy sync kulcsszavakkal leírható konstrukciókkal lehet szinkronizálni.
A távoli eljáráshívás során a paramétereket a kommunikációhoz definiált CCVoid adatfolyammal adja át a rendszer.
Globális pointereket csak a == és != operátorokkal lehet összehasonlítani, a < és > operátorokkal nem.
Megengedett a globális pointerek explicit kényszerítése lokális pointerré, de ha az adott mutató nem helyi memóriát jelöl, akkor ez futásidejû hibához vezet.
Több virtuális processzor is leképezhetõ egyetlen fizikai processzorra. Ezt a programozó határozhatja meg a proc_t típuson keresztül.
Virtuális processzorokat normál C++ osztályok segítségével lehet alkotni, melyeket a global típusmódosítóval kell ellátni, pl.:
// Udvozlo.h
#include <iostream.h>
global class Udvozlo { // ez virtualis processzor lesz
public:
Udv() {};
void mondj_hellot(int id);
};
// Hello.cc++
#include <stdlib.h>
#include "Udvozlo.h"
int main(int argc, char *argv[])
{
int P = atoi(argv[1]);
parfor(int p=0; p<P; p++)
{
Udvozlo *global U;
proc_t elhelyezes = proc_t("Udvozlo", argv[2+p]);
U = new (elhelyezes) Udvozlo();
U->mondj_hellot(p);
delete U;
}
return 0;
}
// Udvozlo.cc++
#include "Udvozlo.h"
void Udvozlo::mondj_hellot(int id)
{
cout << "Hello a " << id << ". processzorrol! " << endl;
}
Ebben
a példában az Udvozlo osztály egy virtuális
processzort definiál. Az Udvozlo.cc++ forrást
külön kell lefordítani, hogy a virtuális processzorhoz
tartozó programot elkészíthesse a fordító.
Ennek a programnak az indításáról a rendszer
gondoskodik, amikor létrejön egy új példánya a
new utasítás hatására.
Ha egy osztály a global módosítóval van ellátva, akkor abból egy virtuális processzor lesz. Az összes adattagját és publikus eljárását elérhetik globális mutatón keresztül más processzorokról az ott futó folyamatok.
A global módosítószó nem befolyásolja az öröklõdést, azaz a private és protected láthatóságú osztály részeket a C++-hoz hasonlóan lehet elérni a leszármazott osztályokban.
Virtuális processzorok létrehozásakor mindig meg kell adni az elhelyezésüket is. Ez a CC++ nyelvben a proc_t típuson keresztül történik. Ebben az implementáció függõ típusban általában a virtuális processzort futtató fizikai processzor, vagy gép nevét lehet megadni, valamint a virtuális processzor futtatható kódját tartalmazó file elérési útját.
Az így létrehozott elhelyezési információval már használható a new operátor virtuális processzorok dinamikus létrehozására.
Ezen speciális objektumok elérése - mint az a fenti példákból kiderült - a hagyományos objektumok elérésével egyezik meg, csak költségesebb.
Egy dinamikusan lefoglalt virtuális processzor, vagy processzor objektumra mutató globális mutató felszabadításával meg lehet szüntetni az adott virtuális processzort:
delete U;
Minden CC++ programban lehet használni a ::this mutatót, amely mindig az adott processzoron futó processzor objektumra mutat.
Erre e feladatra a rendszer használhatná a memória másolást is, ez azonban a C programok mutatókkal teletûzdelt világában ritkán vezet jó eredményre. A probléma megoldására a CC++ nyelvben definiáltak egy új adatfolyamot, a CCVoid típust.
Minden kommunikációban résztvevõ típusnál definiálni kell a következõ operátorokat:
CCVoid& operator<<(CCVoid&, const TYPE& obj_in); CCVoid& operator>>(CCVoid&, TYPE& obj_out);
Ezek az összes beépített típusra definiálva vannak, így a mûveletek összeállításakor felhasználhatóak ezek a primitívek, pl.:
class Point {
float x;
float y;
friend CCVoid& operator<<(CCVoid&, const Point& p_in);
friend CCVoid& operator>>(CCVoid&, Point& p_out);
};
CCVoid& operator<<(CCVoid& v, const Point& p_in)
{
v << p_out.x << p_out.y;
return v;
}
CCVoid& operator>>(CCVoid& v, Point& p_out);
{
v >> p_in.x >> p_in.y;
return v;
}
Az egész módszer a istream és ostream folyamok használatával egyezik meg.
Ha a programozó definiálja ezeket az operátorokat, akkor azt a CC++ fordító automatikusan felhasználja, ha szüksége van rá. Ha nincsenek definiálva ezek, akkor a fordító megpróbál generálni ilyeneket, hogy a processzorok közötti kommunikációt megvalósíthassa. A fordító által generált kódok persze nem valószínû, hogy a programozó elvárásának megfelelõen kezelik a mutatókat és struktúrákat.
//
// Mandelbrot halmaz szamitasa (-2,-2)-(2,2)
//
#include <fstream.h>
int main(int argc, char *argv[])
{
int N = 512; /* kepmeret */
unsigned char *pix; /* a kep */
double x1,y1,x2,y2; /* sarkok */
x1 = -2; y1 = -2; x2 = 2; y2 = 2;
pix = new unsigned char [N * N];
/*
* A fo szamitasi ciklus
*/
x2 -= x1;
y2 -= y1;
parfor (int iy = N; iy > 0; iy--)
{
double y = (iy * y2) / N + y1; // re. coord.
for(int ix = N; ix > 0; ix--)
{
double x = (ix * x2) / N + x1; // im. coord.
double ar = x;
double ai = y;
double a1, a2;
for (int ite = 0; ite < 255; ite++)
{
a1 = (ar * ar);
a2 = (ai * ai);
if (a1 + a2 > 4.0) ite=255;
ai = 2 * ai * ar + y;
ar = a1 - a2 + x;
}
pix[iy * N + ix] = ~ite;
}
}
// az eredmeny kiirasa
ofstream mandel_f("mandel.pgm");
mandel_f << "P5\n# Mandelbrot set" << endl;
mandel_f << N << " " << N << endl << 255 << endl;
mandel_f.write(pix, N * N);
delete [] pix;
return(0);
}
Bonyolultabb a megoldás, ha osztott rendszeren kell megvalósítani a feladatot. Ekkor a processzorok közötti kommunikációt is meg kell szervezni egy új adattípus bevezetésével:
// CharArray.h
// karaktertomb az eredmenyek atvitelere
#ifndef __CHAR_ARRAY_DECLARE__
#define __CHAR_ARRAY_DECLARE__
class CharArray
{
public:
int size;
char *array;
CharArray(void);
CharArray(int lenght);
CharArray(const CharArray&);
CharArray& CharArray::operator=(const CharArray&);
void include(const CharArray& ca, int at);
~CharArray(void);
friend CCVoid& operator<<(CCVoid&, const CharArray&);
friend CCVoid& operator>>(CCVoid&, CharArray&);
};
#endif /* __CHAR_ARRAY_DECLARE__ */
ennek implementációja:
// CharArray.cc++
#include "CharArray.h"
#include <stdlib.h>
CharArray::CharArray(void)
{
size = 0;
array = (char*)0;
}
CharArray::CharArray(int length)
{
size = length;
array = new char [length];
}
CharArray::CharArray(const CharArray& ca)
{
size = ca.size;
array = new char[size];
memcpy(array, ca.array, size);
}
CharArray& CharArray::operator=(const CharArray& ca)
{
if(size != 0) delete [] array;
size = ca.size;
array = new char[size];
memcpy(array, ca.array, size);
}
void CharArray::include(const CharArray& ca, int at)
{
if((at + ca.size) > size) return;
memcpy(array + at, ca.array, ca.size);
}
CharArray::~CharArray(void)
{
delete [] array;
}
CCVoid& operator<<(CCVoid& v, const CharArray& ca)
{
v << ca.size << CCArray((char *)ca.array, ca.size);
return v;
}
CCVoid& operator>>(CCVoid& v, CharArray& ca)
{
if(ca.size != 0) delete [] ca.array;
v >> ca.size;
ca.array = new char [ca.size];
v >> CCArray((char *)ca.array, ca.size);
return v;
}
A tényleges munkavégzõ kódrészlet:
// mandel_slice.h
// CC++ class egy szelet szamitasara
//
#ifndef __MANDEL_SLICE_DECLARE__
#define __MANDEL_SLICE_DECLARE__
#include "CharArray.h"
global class Mandel_slice
{
public:
Mandel_slice(int width, int height,
double x_1, double y_1, double x_2, double y_2) :
wd(width), ht(height),
x1(x_1), y1(y_1), x2(x_2), y2(y_2) {};
CharArray calculate(void);
private:
int wd; // width
int ht; // height
double x1, y1, x2, y2;
};
#endif /* __MANDEL_SLICE_DECLARE__ */
és ennek implementációja:
// mandel_slice.cc++
#include "mandel_slice.h"
CharArray Mandel_slice::calculate(void)
{
CharArray pix(wd * ht);
x2 -= x1;
y2 -= y1;
for (int iy = ht; iy > 0; iy--)
{
double y = (iy * y2) / ht + y1; // re. coord.
for (int ix = wd; ix > 0; ix--)
{
double x = (ix * x2) / wd + x1; // im. coord.
double ar = x;
double ai = y;
double a1, a2;
for (int ite = 0; ite < 255; ite++)
{
a1 = (ar * ar);
a2 = (ai * ai);
if (a1 + a2 > 4.0)
break;
ai = 2 * ai * ar + y;
ar = a1 - a2 + x;
}
pix.array[iy * wd + ix] = ~ite;
}
}
return pix;
}
A feladat elosztása:
// mandel_set.h
#ifndef __MANDEL_SET_DECLARE__
#define __MANDEL_SET_DECLARE__
#include "CharArray.h"
class Mandel
{
public:
Mandel(int argc, char *argv[]);
void calculate(void);
void save(void);
~Mandel(void);
private:
int wd,ht;
double x1,y1,x2,y2;
CharArray *pix; // the set
char *fn; // output file name
friend CCVoid& operator<<(CCVoid&, const Mandel&);
friend CCVoid& operator>>(CCVoid&, Mandel&);
};
#endif /* __MANDEL_SET_DECLARE__ */
és implementációja:
// mandel_set.cc++
#include <stdio.h>
#include "mandel_set.h"
#include "mandel_slice.h"
#include "CharArray.h"
const char *hosts[] = {"augusta", "garfi", "sunny1", "sunny2", "sunny3"};
const int hosts_num = sizeof(hosts) / sizeof(hosts[0]);
#define MIN_WIDHGT 1
#define MAX_WIDHGT 2048
#define out_of_bounds(lambda) ((lambda < MIN_WIDHGT) || (lambda > MAX_WIDHGT))
Mandel::Mandel(int argc, char *argv[])
{
if (argc < 8)
{
fprintf(stderr, "usage: %s width height x1 y1"
" x2 y2 filename\n", argv[0]);
exit(-1);
}
wd = atoi(argv[1]);
ht = atoi(argv[2]);
sscanf(argv[3], "%lf", &x1);
sscanf(argv[4], "%lf", &y1);
sscanf(argv[5], "%lf", &x2);
sscanf(argv[6], "%lf", &y2);
fn = argv[7];
if (out_of_bounds(wd) || out_of_bounds(ht))
{
fprintf(stderr, "Width and height must be between"
" %d and %d\n", MIN_WIDHGT, MAX_WIDHGT);
exit(-1);
}
pix = new CharArray(wd * ht);
}
void Mandel::calculate(void)
{
double delta_y; // computed slice size
double step_y; // work area barrirer
int dy, sy; // pix slice size
delta_y = (y2 - y1) / hosts_num;
dy = ht / hosts_num;
if(dy == 0) dy = 1;
parfor(int h=0; h<hosts_num; h++)
{
CharArray slice;
Mandel_slice *Ms;
int sy; // slice's height
double y_1, y_2; // slice's coords
proc_t placement = proc_t("Mandel_slice", hosts[h]);
if(h == hosts_num-1) // last slice is different
{
sy = ht - h * dy;
y_1 = y1 + h * delta_y;
y_2 = y2;
}
else
{
sy = dy;
y_1 = y1 + h * delta_y;
y_2 = (h+1) * delta_y;
}
Ms = new (placement)
Mandel_slice(wd, sy, x1, y_1, x2, y_2);
slice = Ms->calculate();
pix->include(slice, h * dy * wd);
delete Ms;
}
}
void Mandel::save(void)
{
FILE *f;
f = fopen(fn, "wb");
if(!f)
{
perror(fn);
exit(-1);
}
fprintf(f, "P5\n# Mandelbrot set\n");
fprintf(f, "%3d %3d\n%3d\n", wd, ht, 255);
if(pix->size != fwrite(pix->array, 1, pix->size, f))
{
perror(fn);
exit(0);
}
fclose(f);
}
Mandel::~Mandel(void)
{
delete pix;
}
CCVoid& operator<<(CCVoid& v, const Mandel& m)
{
return v;
}
CCVoid& operator>>(CCVoid& v, Mandel& m)
{
return v;
}
És a fõprogram:
// mandel_dist.cc++
#include "mandel_set.h"
int main(int argc, char *argv[])
{
Mandel M(argc, argv);
M.calculate();
M.save();
return(0);
}
Az osztott sor:
// queue.h
class Queue
{
public:
Queue(int amax = 12);
void Put(int item);
int Get(void);
~Queue(void);
private:
int *queue;
int max;
int head, tail;
sync int *notfull, *notempty;
atomic void queue_put(int item);
atomic int queue_get(void);
};
és implementációja:
// queue.cc++
#include "queue.h"
Queue::Queue(int amax)
{
max = amax;
queue = new int[max];
head = tail = 0;
notfull = new sync int;
*notfull = 1;
notempty = new sync int;
}
void Queue::Put(int item)
{
// implicit wait if the queue is full
*notfull == 1;
queue_put(item);
}
void Queue::queue_put(int item)
{
queue[head] = item;
// it was empty
if(head == tail)
{
*notempty = 1;
}
head = (head + 1) % max;
// queue became full
if(head == tail)
{
delete notfull;
notfull = new sync int;
}
}
int Queue::Get(void)
{
// impicit wait if the queue is empty
*notempty == 1;
return queue_get();
}
int Queue::queue_get(void)
{
int item = queue[tail];
// the queue was full
if(head == tail)
{
*notfull = 1;
}
tail = (tail + 1) % max;
// the queue became empty
if(head == tail)
{
delete notempty;
notempty = new sync int;
}
return item;
}
Queue::~Queue(void)
{
delete [] queue;
}
A fõprogram:
// prodcons.cc++
#include <stdlib.h>
#include "queue.h"
#include <iostream.h>
//
// Producer task
//
void Producer(Queue& Q, int myid, int Work_length = 10)
{
int number;
srand(myid);
number = rand() % 100;
for(int i=0; i<Work_length; i++)
{
number++;
cout << "t0" << myid << " producing: "
<< number << endl;
Q.Put(number);
}
}
//
// Consumer task
//
void Consumer(Queue& Q, int myid, int Work_length = 10)
{
int number;
for(int i=0; i<Work_length; i++)
{
number = Q.Get();
cout << "t0" << myid << " consuming: " << number << endl;
}
}
// the main program
int main(int argc, char *argv[])
{
Queue Q;
parfor(int i=1; i<5; i++)
{
if((i % 2) == 0)
Producer(Q, i);
else
Consumer(Q, i);
}
}
A CC++ nyelv kiterjesztései jól támogatják rugalmas, helyzethez alkalmazkodó programok írását. A C++ nyelv kivételkezelésével kombinálva nagyon jó, és hibatûrõ alkalmazások írását teszi ez lehetõvé.
Kliens/szerver megoldások implementálására is nagyon jól felhasználható a nyelv, viszont nem definiál olyan eszközöket, amely futásidõben lehetõvé tenni futó alkalmazások összekapcsolását, ezért a PVM-hez hasonló gondokkal kell megküzdenie az ilyen programok íróinak.
A CC++ nyelven írt programok hatékonysága és biztonsága az alatta lévõ kommunikációs rétegtõl függ. Jelenleg ez a nyelv alkotói által biztosított Nexus rendszer. Ez nem teszi lehetõvé osztott operációs rendszer írását, de ennek lecserélésével a nyelv erre is alkalmas lehet.
A CC++ nyelv sok szinten támogatja a folyamatok párhuzamosságát. A par és parfor kulcsszavak az utasítások , kifejezések szintjén, a spawn utasítás a végrehajtási szálak szintjén és a processzor objektumok a párhuzamosan futó önálló memóriájú programok szintjén.
Folyamat modellje dinamikus, azaz a program bármely pontján lehet új végrehajtási szálajkat, illetve párhuzamos programokat indítani és megszüntetni.
Virtuális processzorok definiálásával a programozó az erõforrások elosztására is megkötéseket tehet.
A nyelv elfedi a programozó elöl az architektúra kommunikációs módszereit és egy egységes felületet biztosít. Ebben osztott memóriát - szálak közös memóriaterülete, globális mutatók -, és távoli eljáráshívásokat is lehet használni folyamatok közötti kommunikációra. Mindkét kommunikációs mód aszimetrikus, azaz a küldõ, illetve kérõ írja elõ a címzettet. A fogadó oldal nem tehet megkötéseket arra, hogy kitõl fogadja el a kommunikációs kérelmeket. Ezek a módszerek emellett szinkron, blokkoló kommunikációval járnak. A kommunikáció ilyen formája azért lehet mégis gyors, mert minden egyes kérelem kiszolgálásához egy külön végrehajtási szál indulhat el.
A CC++ nyelv két szinkronizációs eszközt ad a programozónak. Az atomic módosítóval definiált eljárásokra a monitorokhoz hasonló atomi végrehajtás lesz jellemzõ.
Bonyolultabb útkifejezések megvalósítására, illetve más szinkronizációs problémák megoldására csak a sync típusmódosító használható, amely mûködésében egy egyszer használatos szemaforhoz hasonlítható. Ez az elem eléggé sajátos algoritmusokat igényel, bár a nyelv alkotói szerint minden probléma megoldható ezzel is.
A CC++ nyelv tehát egy nagyon kellemes eszköz folyamat párhuzamosságot tartalmazó problémák megoldására, bár hatékony felhasználása - az objektumorientáltság és a párhuzamosság kombinálásából származó gondok miatt is - új programtervezési módszereket igényel.

| 
| 
| 
|