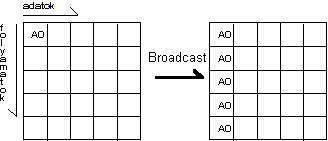
Ábra 9. Adatok lemásolása
Párhuzamos programozást támogató nyelvi eszközök összehasonlítása: Nyelvek, eszközök: MPI
2.2 MPI
MPI (Message Passing Interface) egy rutinkönyvtár
szabvány, amely a programok közötti üzenetek
útján való kommunikáció
biztosítását írja le.
Ilyen alapokból indulva alakult meg 1992-ben az MPI Forum, amely feladata az MPI szabvány fejlesztése. Ennek a testületnek sok hardware gyártó, software készítô cég és szervezet lett tagja. A szabványra a következô software-k készítôi voltak nagy hatással: IBM T. J. Watson Research Center, NX/2 (Intel), Express, Vertex (nCUBE), p4, PARAMACS, Zipcode, Chimp, PVM, Chameleon és PICL.
A felület kifejlesztésének a célja az volt, hogy egy széles körben használható, hordozható szabványt készítsenek üzenetek küldésére. Jelenleg több publikus és több hardware gyártók által támogatott változata is van a szabványban specifikált rutinkönyvtárnak. Az MPI szabványt használó programok forrásszinten hordozhatóak a különbözô változatok között.
A szabványban C és Fortran 77 nyelvekhez adtak meg felületet. A rutinkönyvtárral a következô feladatokat lehet megoldani:
A szabvány következô változatába az alábbi dolgokat kívánják bevenni:
Az MPICH implementációt az MPI szabvány
megvalósítására írták, a
CHIMP, LAM és UNIFY csomagok már
meglévô rutinkönyvtárakra épülnek
rá, ezért nem annyira hatékonyak.
2.2.2
Felhasználói felület
A felületben lévô rutinokra a következô - korábban nem említett - fogalmak használatosak:
A szabvány a nyelvek közötti átjárhatóság biztosítása érdekében törekedett az egységes felület kialakítására, ezért nem használják ki mindig az adott nyelv által biztosított lehetôségeket maximálisan.
A szabványban leírt rutinok alakja:
int MPI_Xxxxxxxx( ... )C nyelvben, ahol a visszatérési érték a rutin lefutásáról ad információt, és
MPI_XXXXXXXX( ..., IERROR)Fortran 77 nyelven, ahol az IERROR (utolsó) paraméternek van ilyen funkciója.
A program indulása után az MPI függvények használata elôtt kell meghívni az MPI könyvtár inicializálását: MPI_Init. Ez az eljárás parancssori argumentumokkal is foglalkozik, ezért azokat is át kell adni.
A program normális befejezése esetén a könyvtárban definiált (MPI_Finalize) eljárás meghívásával lehet az által lefoglalt erõforrásokat felszabadítani.
Hiba esetén a párhuzamos program futása megszakítható az MPI_Abort eljárással. Ezen a módon nem csak az adott folyamat, hanem a hozzá tartozó folyamatok is leállíthatóak. A leállítandó csoport leírására szolgál a comm paraméter.
Az comm paraméter egy kommunikációs közeget ír le. Az MPI_Init meghívása után létrejön egy MPI_COMM_WORLD nevû MPI_Comm típusú kommunikátor, amelyben minden taszk benne lesz. Ezt is paraméterül lehet adni az MPI_Abort rutinnak, hogy az egész programrendszer futását megszakítsa.
A kommunikátorokról elöljáróban: egy kommunikátor folyamatok egy csoportját azonosítja, és egy üzenetküldési réteget definiál, mellyel ugyanazon folyamatok között küldött üzenetek is teljesen elkülöníthetõek egymástól.
Ezek alapján a minimális MPI program:
#include mpi.h
void main(int argc, char *argv[])
{
MPI_Init(&argc, &argv);
/* a program utasitasai */
MPI_Finalize();
}
A legegyszerûbb küldõ rutin az MPI_Send Ez egy adott területrôl az MPI könyvtárban definiált típusú adatvektor elküldésére alkalmas. A címzésnél meg kell adni a fogadó sorszámát, az üzenet típusát és az üzenet továbbítására szolgáló kommunikátort. Ez egy blokkoló rutin.
Ebben a könyvtárban az MPI_Datatype típus adhatja meg egy üzenet adattípusát. Az MPI_Init végrehajtása után a felhasználó rendelkezésére a következô típusok állnak: MPI_CHAR, MPI_SHORT, MPI_INT, MPI_LONG, MPI_UNSIGNED_CHAR, MPI_UNSIGNED_SHORT, MPI_UNSIGNED, MPI_UNSIGNED_LONG, MPI_FLOAT, MPI_DOUBLE, MPI_LONG_DOUBLE, MPI_BYTE és MPI_PACKED. Új típusok is kialakíthatók struktúrák, illetve tömbrészletek leírására.
Egy üzenetben mindig benne van, hogy melyik folyamat küldte, mi az üzenet típusa, ki a címzett és mi a kommunikátor.
Blokkoló üzenet-vételre szolgál az MPI_Recv eljárás. Az üzenet forrása és típusa elõírható, de az MPI_ANY_SOURCE, illetve az MPI_ANY_TAG használatával bárkitôl bármilyen üzenetet is lehet fogadni.
Az vett üzenetrõl információkat az eljárás paramétereként adott status struktúrából lehet kinyerni. Ennek MPI_SOURCE, MPI_TAG és MPI_ERROR mezôibõl egy ismeretlen üzenet küldõjét, típusát, illetve a vétel sikerességét lehet megállapítani.
MPI-ban a vett adatok egyszerû adattípusának meg kell egyeznie a küldött adatok egyszerû adattípusával. Ez azt jelenti, hogy egy bonyolult struktúrát, vagy tömböt az MPI_Send-nél felsorolt típusokra lebontva pont ugyanazokat és ugyanannyi ilyen egyszerû adatot kell venni, mint amennyit küldtek. (Pl.: két {int, char} struktúra vehetô egyetlen {int,char,int,char} struktúraként) Az MPI nem gondoskodik típuskonverzióról - int típusú adatot nem lehet double-ként venni -, sôt ilyen esetben hibát jelez.
Az eljárásnak a használt kommunikátort is specifikálni kell. MPI-ban a kommunikátorból megállapítható, hogy a folyamatok azonos architektúrákon futnak-e, ha nem akkor a reprezentációk között automatikusan konvertálódnak az adatok.
A pont-pont közötti kommunikációknak még több fajtája elképzelhetô (* jelöli a fenti módszerre jellemzôt):
A pufferelt, ready és szinkron üzenetküldések alakja csak a nevében tér el a MPI_Send-tôl:
Pufferelt üzenetküldések használatához az MPI könyvtár rendelkezésére lehet bocsátani, illetve vissza lehet tôle venni egy memóriaterületet (MPI_Buffer_attach, MPI_Buffer_detach). Ezeket a területeket több üzenetküldési eljárás közösen használhatja, tehát mérete az üzenetek méretét meg kell hogy haladja.
Egy programban egyszerre csak egy aktív puffer lehet, azaz nem lehet minden üzenethez egy újabb memóriarészletet puffernek elõírni. (Érdekes, hogy az MPI szabványban nem definiáltak valamilyen automatikus és rugalmas puffer foglalási módszert, holott elõdei, sõt implementációi is tartalmaznak ilyeneket.
A fenti rutinoknak vannak nem blokkoló változataik is. Ez az MPI-ban azt jelenti, hogy egy mûveletet két részre lehet bontani: egy kezdeti inicializáló részre, illetve a mûvelet befejezôdését vizsgáló részre. Az ilyen szétbontásnak akkor van értelme, ha egy mûvelet hosszú ideig tart, és a várakozás helyett lehet hasznos számításokat is végezni. A nem blokkoló mûveletek akkor lehetnek hatékonyak, ha azokat a program egy másik végrehajtási szála, vagy egy másik - esetleg kommunikációra specializált - processzor hajtja végre. A végrehajtás módszerének részletei implementáció függõek.
A nem blokkoló rutinok mind egy MPI_Request típusú kérelmet használnak a háttérben futó mûvelet jellemzõinek tárolására.
Nem blokkoló üzenetküldés indítására az MPI_Isend rutin szolgál. Az eljárás paraméterei a blokkoló változattal megegyeznek, eltekintve az utolsó argumentumtól.
Az eljárás lefutása során inicializálja az utolsó paraméterként megadott MPI_Request típusú struktúrát. Ez tárolja a függõben lévõ, vagy háttérben futó eljárás jellemzõit. Ennek vizsgálatával megállapítható, hogy az üzenetküldés befejezõdött-e, vagy elõkerült-e valamilyen hiba.
Az eljárás az inicializálás után visszatér, és az üzenetküldés folyamata a program további futásával párhuzamosan fog megtörténni.
A küldendô adatokat a mûvelet befejezéséig nem illik bántani, mert nem definiált, hogy mikor olvassa ki azokat a rendszer.
Ennek persze megvannak a szokásos változatai:
A nem blokkoló üzenet küldéshez hasonló a nem blokkoló üzenet vétel. Ennek paraméterezése a normális üzenet vételhez hasonló, csak a MPI_Request típusú plusz paraméter jelent az MPI_Irecv eljárásban is eltérést.
Egy háttérben futó eljárás vizsgálatára a következô lehetõségek vannak:
Ha egy programban több nem blokkoló mûvelet is van, akkor ezeket egyszerre is lehet vizsgálni:
Üzenetek megérkezését - az üzenet tényleges vétele nélkül - az MPI_Probe és MPI_Iprobe eljárásokkal lehet vizsgálni. Ezen rutinok segítségével a program az üzenet vétele nélkül tájékozódhat annak méretérõ, típusáról, illetve feladójáról, de nem a tartalmáról.
Ezekkel a rutinokkal a program bõvebb mozgásteret kap, és bonyolultabb problémákat is megoldhat, mint egy Ada nyelvû program, hiszen az csak a randevú létrejötte után szerezhet ilyen információkat.
A eljárások az MPI_Recv és MPI_IRecv+MPI_Test rutinokhoz hasonlóan viselkednek, csak nem veszik az üzenetet.
Egy futó mûvelet megszakítása való az MPI_Cancel rutin. Az MPI_Cancel után egy MPI_Wait vagy MPI_Test mûvelettel lehet a nem blokkoló mûvelethez kapcsolódó erõforrásokat felszabadítani.
Ez az eljárás lényegében azt teszi lehetõvé, hogy valamilyen eseményhez kötött mûvelet-végrehajtás legyen a programban. Egy küldõ, vagy fogadó mûveletet ezen a módon egy meghatározott türelmi idõ letelte után, vagy valamilyen más esemény hatására - pl. felhasználó megnyomja az ESC billentyût - meg lehet szakítani. Ehhez hasonló eszközt az Ada 95 biztosít az aszinkron vezérlésátadás bevezetésével.A nem blokkoló mûvelet megszakításának sikerességét a kérelem befejezése után a MPI_Test_cancelled rutinnal lehet elvégezni. Ha nagyon sokszor kell azonos paraméterekkel leírt kommunikációt végezni, akkor ezeket a paramétereket egy kérelemben el lehet tárolni. Ilyen kérelmek létrehozására szolgálnak az MPI_Send_init és MPI_Recv_init eljárások.
Ezekkel létrehozott kérelmet, illetve kérelmeket az MPI_Start, illetve MPI_Startall eljárásokkal lehet elindítani.
A küldésnek megvannak a szokásos változatai:
Az MPI még egy kényelmes függvényt biztosít egyszerû kommunikációra: az MPI_Sendrecv eljárással egyesíteni lehet egy üzenet elküldésének és egy üzenet vételének folyamatát. A rutin hatása ekvivalens nem blokkoló üzenet küldés és vétel elindításával, majd a mûveletek befejezôdésének megvárásával.
Gyûrûbe kapcsolt folyamatok közötti eltolás -- mindenki az elõtte lévônek ad át adatot -- mûvelet végrehajtásakor lehet elônyös, mert így a holtpont elkerülhetô.
Az MPI_Sendrecv_replace Az elôzô mûvelet megfelelôje, azzal a különbséggel, hogy a küldô és fogadó adatterületek egybeesnek, tehát a vett üzenet az elküldött helyére másolódik be.
Egy új MPI adattípust egy MPI_Datatype átlátszatlan típusban lehet létrehozni. A létrehozás után a típust engedélyeztetni kell az MPI_Type_commit eljárással, ami lényegében a típus elismertetése a teljes rendszerben. Sikeres engedélyeztetés után az új típust bárhol használható az eddigi egyszerû típusok helyett, akár egy újabb típus létrehozására is.
Egy MPI adattípus lényegében egy egyszerû típusokból álló típus térkép. Leírja, hogy egymás után milyen egyszerû adattípusok vannak, és az egyes elemek milyen eltolással vannak eltárolva. Az adattípusok belsô tárolására persze tömörebb formát használnak, de ez a szemléletes kép jól használható az MPI típus-kompatibilitás megértéséhez.
Egy adott adattípussal küldött MPI üzenet csak olyan MPI adattípussal vehetô, amiben az egyszerû adattípusok sorrendje és száma megegyezik a küldött MPI típuséval. Ez azt jelenti, hogy az MPI_Datatype átlátszatlan típust az egyes folyamatokban különbözõképpen is lehet definiálni, mégis ekvivalensek, ha ugyan azt az egyszerû adattípus sorrendet írják le.
Ez a szemlélet sérti a programok közötti szigorú típus ekvivalenciára vonatkozó szemantikákat - pl. az Ada nyelv által definiált megkötéseket -, de matematikai számításoknál hasznos lehet. Például egy kétdimenziós tömb miden sorának elsõ elemét elküldve egy üzenetben, egy másik folyamat azt egy egy dimenziós vektorba is fogadhatja. Szigorúbb típus kompatibilitás másrészt csak akkor érhetõ el, ha a fordító program a kommunikációban résztvevõ mindkét folyamat forráskódját elemezni tudja, és a küldés-vétel párokat összehasonlítva megvizsgálhatja a közöttük átvitt adatok típusának egyezõségét. Ez egy rutinkönyvtárban nyilván nem definiálható, hiszen ez az adott nyelv fordítóprogramjára nincs hatással.
A legegyszerûbb konstrukciós rutin az MPI_Type_contiguous. Ezzel egy korábban definiált típusból kiindulva, adott hosszúságú - a memóriában folytonosan elhelyezkedô elemeket tartalmazó - vektor hozható létre.
Hasonló - egy dimenziós, és azonos adattípusú elemekbõl álló - szerkezetek létrehozására alkalmasak az MPI_Type_vector és MPI_Type_hvector rutinok. Ezeknél azonban a vektorban lévõ elemeket nem feltétlenül folytonosan helyezkednek el, blokkokban lehet õket definiálni.
A blokkok hossza (mindegyik egyforma hosszú), illetve a közöttük lévõ eltolás mértéke megadható. A két rutin között az a különbség, hogy az eltolást mértéke az MPI_Type_vector-nál az elemek adattípusának méretével, az MPI_Type_hvector rutinnál pedig byte-okban mérendô.
Ezekkel az eljárásokkal könnyedén lehet olyan típust definiálni, amely egy kétdimenziós tömb minden sorának elsõ elemét határozza meg (blokkhossz=1 és eltolás=sorhossz), így azokat egyetlen küldõ rutinnal lehet továbbítani egy másik folyamat felé.
Ha ez a leírás nem elégséges - pl. egy felsõ háromszög mátrixot kéne elküldeni -, akkor fel lehet használni az MPI_Type_indexed és MPI_Type_hindexed eljárásokat. Ezekben a blokkok hosszát, illetve eltolását már nem csak globálisan, hanem minden egyes blokkra lebontva is meg lehet határozni.
Az eljárások között ugyanaz a különbség, mint az elõzõ esetben.
Strukturált adattípus leírására szolgál az MPI_Type_struct . Az MPI_Type_hindexed eljáráshoz képest az a különbség, hogy minden egyes blokk adattípusát definiálni kell. Ezek az adattípusok bármilyen korábban definiált, MPI számára ismert adattípus közül kikerülhetnek.
Ezzel a rutinnal lényegében bármilyen adattípus leírható.
Egy adattípus felszabadítására való az MPI_Type_free eljárás. Ha egy kommunikáció éppen használja ezt, akkor az még rendben lefut, és csak utána kerül felszabadításra a hozzá tartozó memóriaterület.
Implementációs részletek: Két osztott rendszeren létrehozott implementáció részleteit vizsgálva kiderült, hogy semmilyen adattípus egyeztetés nem volt a különbözõ processzorok között folyó kommunikációban, csak az üzenet hossza számított (CHIMP, MPICH). Eddig csak egy osztott memórián (Cray T3D SPP rendszerén) mûködõ MPI implementációban találtam adattípus ellenõrzést különbözõ processzorok között folyó kommunikációban.Ha az üzenet nem állítható elõ egy lépésben, akkor azt valami köztes tárolóhelyen kell raktározni, és utána egyben elküldeni. Ezt a feladatot a programozó is megoldhatja, de az MPI is biztosít lehetõséget az üzenet pufferbe való többlépcsôs pakolásra is.
Egy üzenet összeállítására az MPI_Pack eljárást lehet használni. Ez a rutin lényegében az MPI_Send-hez hasonló formában megadott adatokat másol be a felhasználó által elõre lefoglalt puffer területre. Ezt a rutint többször meghívva tetszôleges adatokat lehet berakni egy üzenetbe. Az így elõkészített üzenet puffert a szokásos MPI_Send rutinnal lehet elküldeni, csak MPI_PACKED paramétert kell megadni az üzenet adattípusaként.
Az MPI_Unpack eljárással egy MPI_PACKED típussal vett üzenetbôl lehet kipakolni az adatokat. Szintaxisa a bepakolásra hasonlít.
A pakolt üzenetek küldésének kétségtelen elõnye, hogy több lépésben is össze lehet állítani az üzenetet, de így az MPI semmilyen típusellenôrzést nem tud végezni a küldött üzenetben.
Az MPI nem definiálja, hogy egy szokásos módon küldött üzenet vehetô-e MPI_PACKED típussal, illetve egy így küldött üzenet vehetô-e a szokásos módon. Egyes implementációkban ez mûködik, de erre nem mindenhol lehet számítani.
A pakolásos üzenet összeállítás, illetve vétel a PVM módszerére hasonlít leginkább, azzal a különbséggel, hogy itt a programozónak magának kell kezelnie az üzenet puffert.
Az MPI rendszer legfôbb elônye ezen rutinok használatában van.
Az eljárások nagy része egyszerû algoritmusokat valósít meg, melyek ezek nélkül is megoldhatóak lennének, de több okból is indokolt ezek használata:
Az MPI_Barrier rutinnal több folyamatot lehet egymással szinkronizálni. A rutin addig vár, ameddig az összes - a kommunikátorban lévô - folyamat meg nem hívja ugyanezt az eljárást.
Ábra 9. Adatok lemásolása
MPI_Bcast eljárás adatok lemásolására szolgál. Egy kijelölt folyamat adatterülete lemásolódik a mûveletben résztvevõ összes folyamat adatterületére.
Ez a mûvelet közösen használt változók, paraméterek elterjesztésére szolgálhat, például egy folyamat feldolgozza a parancssori argumentumokat, és az ezekbõl kinyert információkat megosztja a többi folyamattal.
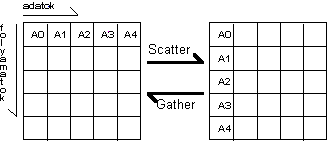
Ábra 10. Adatok szétszórása és összegyûjtése
Az MPI_Gather eljárás adatdarabkák összegyûjtésére szolgál. Minden folyamat egy adott mennyiségû adatot küld el, ami egy kijelölt folyamatban összegyûlik. A fogadó folyamatban a különbözõ helyrõl érkezõ adatelemek egy vektorba kerülnek, melyben az adatelem helyét a küldõ folyamat sorszáma határozza meg. A küldött és a vett adatok mennyiségének és típusának meg kell egyezni. (Ez a megkötés a további rutinokra is igaz.)
Az eljárás hatása ekvivalens azzal, hogy a kijelölt folyamat ciklusban fogad adatelemeket a többi folyamattól, és a vett adatokat elhelyezi egy vektorban.
Az MPI_Gatherv az elôzôvel megegyezô mûködésû rutin, csak meg lehet adni, hogy az egyes folyamatoktól érkezô adatok milyen eltolással tárolódjanak el a vételi tömbben.
Az MPI_Scatter és az MPI_Scatterv az összegyûjtõ eljárások inverzei, adatok szétosztására szolgálnak. Egy vektorban megadott adathalmazt osztanak szét a kollektív kommunikációban résztvevõ folyamatok között. Az egyes folyamatokhoz érkezõ adatelemek a kijelölt folyamatban lévõ vektorból származnak. Az MPI_Scatter-ben egyszerûen indexek alapján történik a szétosztás, az MPI_Scatterv-ben az adott sorszámú folyamathoz kerülõ adatelem kezdetét is meg lehet határozni.
Az MPI_Allgather és az MPI_Allgatherv az MPI_Gather, illetve MPI_Gatherv eljárásokra hasonlít, csak az összegyûjtött adatok minden folyamatban el lesznek tárolva.
Hatása olyan mint egy MPI_Gather majd egy MPI_Bcast rutin meghívása.
MPI_Alltoall és MPI_Alltoallv rutinok hatása a MPI_Allgather-re hasonlít, csak minden folyamat minden másiknak más-más adatokat küld. Hatása olyan, mintha MPI_Scatter és MPI_Gather rutinokat egyszerre hajtanánk végre.
MPI_Reduce asszociatív és kommutatív mûvelet végrehajtására használható a folyamatokban tárolt lokális adatokon. Az eredmény a egy kijelölt folyamatba érkezik meg.
A rendszer a következõ mûveleteket definiálja elõre:
Az asszociatív mûvelettel kombinálhatóak más kollektív eljárások is, melyek így hatékonyabban végrehajthatóak.
Ilyen az MPI_Allreduce , melynek mûködése az MPI_Reduce mûvelet végrehajtásával megegyezô, de az eljárás végén minden folyamatban meglesz a végeredmény másolata.
Az MPI_Reduce_scatter is hasonló, de a mûvelet befejezése után az MPI_Scatter rutinhoz hasonlóan kerülnek szétosztásra az eredmények.
Az MPI_Scan asszociatív mûvelet kiszámítása szolgál a folyamatokban tárolt lokális adatokon.
Az eljárás jellemzõje, hogy az adott indexig kiszámolt részeredmény lesz eltárolva a folyamatban eredményképpen. A 0 indexû folyamatban a bemenô értéket, a legnagyobb indexû folyamatban pedig az MPI_Reduce rutin eredményeképpen kapott értéket adja vissza.
Az MPI kollektív kommunikációival egyszerûen megoldható problémákat csak HPF nyelven lehet hasonló könnyedséggel kezelni.
2.2.2.5
Csoportok, környezetek kezelése
Nagy programok fejlesztésénél, illetve
rutinkönyvtárak kialakításánál nagyon
jó lehetõség, ha az abban folyó
kommunikációt el lehet választani a program többi
részétõl. Erre e problémára nagyon
jól használhatóak a folyamat csoportok, illetve
kommunikációs környezetek
kialakításának módszerei.
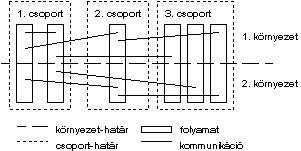
Ábra 11. Csoportok és környezetek
Folyamatok csoportba rendezésével egyes problémák egyszerûbben leírhatóak, nem kell a kód ismétlésével többször hivatkozni önálló folyamatokra. A csoportba rendezés emellett lehetõséget biztosít a rendszer számára magasabb szintû optimalizációra is, hiszen így még több információt kap a program mûködésérõl.
A kommunikációs környezetek arra szolgálnak, hogy egymástól független kommunikációs rétegeket lehessen kialakítani egy programon belül, akár azonos folyamatok között. Ez a megosztás nem vertikális - mint a csoportosítás -, hanem horizontális. Üzeneteket csak egy kommunikációs környezetben belül lehet küldeni. Egy adott környezetben utazó üzenet más környezet számára nem látható és annak mûködését nem zavarja. Ez az eszköz ideális rutinkönyvtárak kialakításakor, hiszen annak felhasználója elõl teljesen el lesz rejtve a benne zajló kommunikáció, még akkor is, ha az a program is MPI eljárásokat használ.
MPI-ban a csoportok és a környezetek összefogására szolgálnak a kommunikátorok.
Csoportok
Az MPI-ban folyamatokat csoportokba lehet összefogni, hogy ezeket együttesen lehessen kezelni a program hátralévõ részében. A csoportok folyamatok rendezett halmazai, melyben minden folyamatnak egy sorszáma van. A sorszámozás mindig nullával kezdõdik, és folyamatosan halad végig az összes folyamaton.
Ilyen csoportok az MPI_Group átlátszatlan típussal írhatóak le. Ez a leírás az adott folyamaton belül érvényes, nem lehet azt egy másik folyamatnak átadni.
Két speciális konstans létezik: az MPI_GROUP_EMPTY az üres, és az MPI_GROUP_NULL a nem létezõ csoport jelölésére szolgál.
A csoportok kialakítására szolgáló mûveletek mind lokálisak, azaz nem igényelnek kommunikációt más folyamatokkal. Az így létrehozott csoportok folyamatonként eltérõek lehetnek.
Az MPI_Comm_group eljárással lehet kinyerni egy kommunikátorhoz tartozó csoportot. Kezdetben csak az MPI_COMM_WORLD környezet létezik, és csak ennek a csoportját - azaz az összes folyamatot magában foglaló csoportot - lehet megkapni.
Ha már vannak csoportjaink, akkor azokra minden halmazmûveletet el lehet végezni, és így kialakíthatóak új csoportok. A lehetséges mûveletek: unió (MPI_Group_union), metszet (MPI_Group_intersection), különbség (MPI_Group_difference), egyedi, illetve több egymásután következõ folyamat bevétele egy halmazba (MPI_Group_incl, MPI_Group_range_incl), valamint kihagyása egy halmazból (MPI_Group_excl, MPI_Group_range_excl).
A csoportokat össze lehet hasonlítani (MPI_Group_compare), meg lehet tudni méretüket (MPI_Group_size), valamint le lehet kérdezni az adott folyamat sorszámát egy csoportban (MPI_Group_rank).
A nem használt csoportokat a MPI_Group_free mûvelettel lehet felszabadítani.
Kommunikátorok
Kommunikációs környezetek magukban nem hozhatóak létre, csak egy csoportra vonatkozóan lehet ilyen tulajdonságot definiálni. E két eszköz összefogásából alakulnak ki a kommunikátorok.
Minden kommunikációban meg kell adni egy ilyen kommunikátort.
Új kommunikátort létre lehet hozni egy csoportból az MPI_Comm_create eljárással, vagy egy másik kommunikátorból. (A tyúk/tojás problémát a csoportok és a kommunikátorok között az MPI_COMM_WORLD kommunikátor oldja meg, ami az MPI_Init végrehajtásakor létrejön.)
Új kommunikátor létrejöttekor a benne lévõ folyamatok egy kollektív mûvelet során kialakítanak egy új kommunikációs környezetet is, ezért az új kommunikátorban küldött üzenetek nem keveredhetnek a korábbiakkal.
Egy régi kommunikátor lemásolását végzi az MPI_Comm_dup eljárás. Ennek hatására a régi kommunikátor folyamat csoportja megmarad, de létrejön egy új kommunikációs környezet. Ez egy új - hosszabb ideig tartó, vagy többlépéses - eljárás indulásakor lehet hasznos, hogy a benne folyó kommunikáció ne keveredjen a program többi részével.
MPI_Comm_split mûvelettel lehet egy kommunikátort részekre bontani. Minden a mûveletben résztvevõ folyamat megmondhatja, hogy az új kommunikátorok közül melyikben szeretne benne lenni, és milyen sorszámot szeretne viselni. A folyamatok két részre osztása ezzel könnyedén megoldható, ha az egyes folyamatok ebben a két paraméterben a sorszám mod 2, illetve a sorszám div 2 értékeket használják.
Egy folyamat a kommunikátorokhoz kapcsolódó csoportokról azok kinyerése nélkül is szerezhet információkat az MPI_Comm_size , MPI_Comm_rank és MPI_Comm_compare eljárások használatával.
Egy kommunikátort az MPI_Comm_free eljárással lehet felszabadítani.
Távoli kommunikáció
Különálló folyamat csoportok közötti kommunikáció biztosítására szolgálnak az úgynevezett inter kommunikátorok. Ezzel az eszközzel egymástól teljesen független folyamtok között teremthetõ meg a kapcsolat. Az egyetlen feltétel az, hogy az egymással kommunikálni akaró folyamatok között legyen egy-egy, amelyek azonos kommunikátorba tartoznak, így ismerhetik egymást.
Ez az eszköz az MPI-ban a kliens szerver típusú programok írásához nyújthat segítséget. Ez a ígéretes lehetõségeket hordoz magában, hiszen az MPI elsõ változatának folyamat kezelése statikus, így minden folyamat ismerheti a másikat az MPI_COMM_WORLD kommunikátoron keresztül. Ha az MPI könyvtár adott implementációja tartalmaz dinamikus folyamat kezelésre szolgáló kiegészítéseket - például új folyamat indítása, vagy MPI világok csatlakoztatása -, akkor az új részt csatlakoztató folyamat hidat teremthet az eredeti és az új kommunikátorral leírt világ között ezzel az eszközzel.
Az ilyen kommunikátorokban csak a pont-pont közötti üzenetküldés megengedett.
Egy inter kommunikátor egy távoli és egy helyi kommunikátorból állítható össze az MPI_Intercomm_create mûvelettel.
A létrejött új kommunikátorban két folyamat csoport lesz: egy távoli és egy helyi. Amikor egy folyamat ezt a kommunikátort használja valamilyen kommunikációban címzésre, akkor a címben leírt sorszám a távoli folyamat csoportban lévõ folyamatokra vonatkozik.
Az új kommunikátoron végrehajtott csoportokkal kapcsolatos mûveletek a helyi csoportra vonatkoznak. Ahhoz hogy a távoli csoport méretét meghatározzuk az MPI_Comm_remote_size eljárást kell használni. A távoli csoport elérésére a MPI_Comm_remote_group mûvelet szolgál.
Egy inter kommunikátort semmilyen explicit jegy nem különböztet meg egy normálistól, de az MPI_Comm_test_inter rutin segítségével meg lehet különböztetni õket.
Kollektív mûveletek elvégzéséhez nem alkalmas ez a távoli kapcsolat. Az MPI_Intercomm_merge eljárás egy inter-kommunikátort alakít át normálissá, így alkalmassá téve bármely mûvelet elvégzésére.
Ez az eszköz az MPI-ban csak nagyon speciális helyzetekben használható, valószínûleg a szabvány következõ változata a dinamikus folyamat kezelés bevezetésével nagyobb fontosságot rendel majd hozzá.
Tulajdonságok
Kommunikátorokhoz a felhasználó tulajdonságokat rendelhet, amelyek speciális függvények felhasználásával továbbörökíthetõek a kommunikátorral végzett mûveletek során is.
Egy tulajdonság létrehozásakor (MPI_Keyval_create, MPI_Keyval_free) meg kell adni a tulajdonságot másoló, és törlõ függvényt is, amelyek az adott kommunikátor másolásánál, illetve törlésénél kerülnek felhasználásra.
A tulajdonságokhoz tartozó adatokat (kulcs, érték) párokkal lehet meghatározni, illetve a kulcs alapján elérni, törölni (MPI_Attr_put, MPI_Attr_get, MPI_Attr_delete).
Ez az eszköz alkalmas lehet arra, hogy egy könyvtár írója a saját könyvtárához szükséges információkat a kommunikátorhoz rendelje, és annak változásait rugalmasan követhesse.
Például egy többlépéses kollektív kommunikáció során az azt implementáló könyvtár létrehozhat egy saját kommunikátort (ezzel a könyvtárat is elválasztja a program többi kommunikációjától), majd ehhez hozzárendelheti a mûvelet aktuális állapotát. Ha a kommunikátort a program lemásolja, és az új kommunikátort adja meg paraméterül a könyvtári függvényeknek, akkor azok még midig a korábban megkezdett mûveletet tudják folytatni. (pl. több folyamat leállítása, amikor már mindegyik befejezte a saját feladatát)
Ezek a tulajdonságok alkalmasak lehetnek a következõekben bemutatásra kerülõ topológiák kezelésére is.
Ilyen kommunikációs gráfok megadásával folyamatok egymáshoz viszonyított elhelyezkedését, topológiáját lehet megadni. Ez a két elõnnyel is járhat:
Az MPI lehetõséget biztosít teljesen általános topológiák leírására is, de sokszor használatos változatokhoz is biztosít kényelmi függvényeket.
Egy új topológia létrehozására szolgáló eszközök:
Az MPI_Topo_test eljárással lehet megvizsgálni, hogy az adott kommunikátorhoz tartozik-e valamilyen topológia.
Ha igen, akkor az MPI_Graphdims_get , illetve az MPI_Graph_get eljárásokkal általános gráf topológiáról, az MPI_Cartdim_get , illetve az MPI_Cart_get rutinokkal hálózat topológiáról szerezhetõ információ.
Egy hálózatban az adott koordinátapozícióknál lévõ folyamat sorszáma az MPI_Cart_rank eljárással kérdezhetõ le. Az MPI_Cart_coords ennek inverze, a folyamat sorszáma alapján a hozzá tartozó koordináta pozíciókat határozza meg.
Tetszõleges topológiában az MPI_Graph_neighbours_count és MPI_Graph_neighbours eljárásokkal lehet a szomszédokkal való összekötöttségi viszonyokról információt szerezni.
A legtöbb topológiát használó algoritmus - pl. életjáték hálózata - valamilyen irányban lévõ szomszédokkal kommunikál. Egy adott dimenzió irányában fekvõ szomszédos folyamatok sorszámát az MPI_Cart_shift eljárással lehet lekérdezni.
Ha az algoritmusban egy hálózat részére van csak szükség, akkor az MPI_Cart_sub rutin felhasználásával annak egyes dimenzióit ki lehet emelni egy új kommunikátorba (pl. egy henger topológiát szét lehet tördelni gyûrûkre).
Ezek a lépések nyilván nem teremtenek binárisan egységes felületet az MPI programok tesztelése terén, de mégis definiálnak egy minimális követelményrendszert, melyet bármely implementáció elkészítésénél be kell tartani.
/* mandel_mpi.c */
/*
* Mandelbrot halmaz szamitasa (-2,-2)-(2,2)
*/
#include "mpi.h"
void main(int argc, char *argv[])
{
int rank;
MPI_Init(&argc, &argv); /* belepes az MPI-ba */
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0)
master(argc, argv); /* fo program */
else
slave(); /* alprogramok */
MPI_Finalize();
}
void master(int argc, char *argv[])
{
...
read_args(argc, argv, &mandel, &fn);
MPI_Comm_size(MPI_COMM_WORLD, &np); /* programok szama */
/* munka szetosztasa a programok kozott */
Mandel_t = reg_Mandel();
...
for(i=1, sy=0;
i<np;
i++, sy+=dy, work.y1+=delta_y, work.y2+=delta_y)
MPI_Send(&work, 1, *Mandel_t, i,
MANDEL_WORK, MPI_COMM_WORLD);
MPI_Type_free(Mandel_t);
...
/* maradek szamitasa helyben */
slice = calc_mandel_tile(&work);
/* eredmnyek osszegyujtese */
for(i=1, sy=0; i<np; i++, sy+=dy)
MPI_Recv(pix + (mandel.wd * sy), mandel.wd * dy,
MPI_BYTE, i, MANDEL_RETURN, MPI_COMM_WORLD,
&status);
bcopy(slice, pix + (mandel.wd * sy), mandel.wd * work.ht);
/* eredmeny kiirasa file-ba */
write_pix(fn, pix, &mandel);
}
void slave(void)
{
...
/* varakozas a munkara */
Mandel_t = reg_Mandel();
MPI_Recv(&work, 1, *Mandel_t, master, MANDEL_WORK,
MPI_COMM_WORLD, &status);
MPI_Type_free(Mandel_t);
/* a feladat elvegzese */
slice = calc_mandel_tile(&work);
/* az eredmeny visszakuldese */
MPI_Send(slice, work.wd * work.ht, MPI_BYTE,
master, MANDEL_RETURN, MPI_COMM_WORLD);
}
/* sajat adattipus a munka leirasara */
MPI_Datatype *reg_Mandel(void)
{
MPI_Datatype *Mandel_t;
int lengths[2];
MPI_Aint displs[2];
MPI_Datatype types[2];
Mandel_t = (MPI_Datatype*)malloc(sizeof(MPI_Datatype));
/* Mandel = 2*int, 4*double */
lengths[0] = 2;
displs[0] = 0;
types[0] = MPI_INT;
lengths[1] = 4;
displs[1] = sizeof(int) * 2;
types[1] = MPI_DOUBLE;
MPI_Type_struct(2, lengths, displs, types, Mandel_t);
MPI_Type_commit(Mandel_t);
return(Mandel_t);
}
A példa a feladat Task-Farm típusú megoldását tartalmazza.
A párhuzamos programok közötti kommunikáció helyesség ellenõrzésére az MPI minden üzenet számára külön típust használhat. Ez a programok helyességének ellenõrzését csak futásidõben biztosítja, és némi többletköltséggel is jár.
/* prodcons_mpi.c */
#include "mpi.h"
#include <stdio.h>
#include <stdlib.h>
#include <strings.h>
#define PRODCONS_GET 2
#define PRODCONS_GETACK 3
#define PRODCONS_PUT 4
#define PRODCONS_PUTACK 5
#define PRODCONS_END 6
#define PRODCONS_NUMBER 10
void queue_task(int);
void consumer_task(int);
void producer_task(int);
void main(int argc, char *argv[])
{
int rank;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0) queue_task(rank);
else if((rank % 2) == 0) consumer_task(rank);
else if((rank % 2) == 1) producer_task(rank);
MPI_Finalize();
}
void queue_task(int myrank)
{
int active_num, i;
int queue[PRODCONS_NUMBER];
int head=0, tail=0, full=0, empty=1;
MPI_Comm_size(MPI_COMM_WORLD, &active_num);
active_num--; /* exclude the queue task */
/*
* main cycle
*/
while(active_num > 0)
{
MPI_Status status;
int flag;
MPI_Iprobe(MPI_ANY_SOURCE,
PRODCONS_END, MPI_COMM_WORLD,
&flag, &status);
if(flag)
{
MPI_Recv(NULL, 0, MPI_INT,
MPI_ANY_SOURCE, PRODCONS_END,
MPI_COMM_WORLD, &status);
active_num--;
}
MPI_Iprobe(MPI_ANY_SOURCE,
PRODCONS_PUT, MPI_COMM_WORLD,
&flag, &status);
if(!full && flag)
{
int number;
MPI_Recv(&number, 1, MPI_INT,
MPI_ANY_SOURCE, PRODCONS_PUT, MPI_COMM_WORLD, &status);
queue[head++] = number;
head %= PRODCONS_NUMBER;
MPI_Send(NULL, 0, MPI_INT,
status.MPI_SOURCE, PRODCONS_PUTACK,
MPI_COMM_WORLD);
if(head == tail)
{
printf("t0x%x queue is full\n", myrank);
fflush(stdout);
full = 1;
}
empty = 0;
}
MPI_Iprobe(MPI_ANY_SOURCE, PRODCONS_GET,
MPI_COMM_WORLD, &flag, &status);
if(!empty && flag)
{
int number;
MPI_Recv(NULL, 0, MPI_INT,
MPI_ANY_SOURCE, PRODCONS_GET,
MPI_COMM_WORLD, &status);
number = queue[tail++];
tail %= PRODCONS_NUMBER;
MPI_Send(&number, 1, MPI_INT,
status.MPI_SOURCE, PRODCONS_GETACK,
MPI_COMM_WORLD);
if(head == tail)
{
printf("t0x%x queue is empty\n", myrank);
fflush(stdout);
empty = 1;
}
full = 0;
}
}
}
void producer_task(int myrank)
{
int queue_rank = 0;
int number;
int i;
srand(myrank);
number = rand() % 100;
for(i=0; i<PRODCONS_NUMBER; i++)
{
MPI_Status status;
number++;
printf("t0x%x producing: %d\n", myrank, number);
fflush(stdout);
MPI_Send(&number, 1, MPI_INT,
queue_rank, PRODCONS_PUT, MPI_COMM_WORLD);
MPI_Recv(NULL, 0, MPI_INT,
queue_rank, PRODCONS_PUTACK,
MPI_COMM_WORLD, &status);
}
MPI_Send(NULL, 0, MPI_INT,
queue_rank, PRODCONS_END, MPI_COMM_WORLD);
}
void consumer_task(int myrank)
{
int queue_rank = 0;
int number;
int i;
for(i=0; i<PRODCONS_NUMBER; i++)
{
MPI_Status status;
MPI_Send(NULL, 0, MPI_INT,
queue_rank, PRODCONS_GET, MPI_COMM_WORLD);
MPI_Recv(&number, 1, MPI_INT,
queue_rank, PRODCONS_GETACK,
MPI_COMM_WORLD, &status);
printf("t0x%x consuming: %d\n", myrank, number);
fflush(stdout);
}
MPI_Send(NULL, 0, MPI_INT,
queue_rank, PRODCONS_END, MPI_COMM_WORLD);
}
A rendszerrel szinte mindenféle feladat megoldható, bár a szabvány jelenlegi változatában csak a statikus folyamatmodellt támogatja, ezért nem használható jól kliens/szerver megoldások, illetve hibatûrõ alkalmazások írására.
A könyvtár kifejezetten párhuzamos folyamatok közötti kommunikáció támogatására íródott, nem tartalmaz elemeket adat párhuzamosság kezelésére (bár implementálhatóak vele ilyen könyvtárak is). Jelenlegi változata statikus folyamatmodellt használ, bár az egyes implementációk ezt a lehetõségeikhez mérten kiterjeszthetik (a következõ változatban már lesznek eszközök a dinamikus modell kezelésére is). Ez a rendszer lényegében csak egy rutinkönyvtár, ezért a párhuzamosságnak a szintjét a futtató rendszer határozza meg: alapvetõen programok lehetnek párhuzamosak, de - ha ezt a rendszer és az implementáció lehetõvé teszi - akár párhuzamosan futó folyamatszálak közötti kommunikációra is használható.
A folyamatok közötti kommunikáció terén az összes üzenetküldés fajtára kínál megoldást (az idõhöz kötött üzenetküldés is leírható nem blokkoló kommunikációval), sõt ezek kollektív változataival sok problémára kínál elõre elkészített, egyszerûsített megoldást. A szabvány következõ változatában az osztott memória használatára is vannak elõterjesztések.
A szinkronizáció területén csak a szinkron kommunikáció, illetve a több folyamatot összefogó korlát áll a programozó rendelkezésére. Bármilyen osztott adattípus megvalósítása során a programozónak az üzenetküldést kell felhasználnia a szinkronizálási feladatok megoldására.
A szabvány egyéb jellemzõi egy átgondolt könyvtár képét mutatják:
Az MPI szabvány tehát az üzenetküldést használó rendszerek programozásának nagyon jó alapja.

| 
| 
| 
|