
Conceptos básicos
En Control de Calidad, es importante tener claros algunos conceptos estadísticos que son fundamentales para entender cierto tipo de fenómenos:
Una "muestra" es una parte pequeńa de un grupo entero, llamado población.
En una población, los valores de estimación se llaman "parámetros", en cambio, los valores de estimación en una muestra, se llaman "estadígrafos".
El objetivo del muestreo, es obtener muestras que sean representativas de la población. En otras palabras, los estadígrafos deben representar los parámetros.
Si los datos que recogemos de una población a través del muestreo, lo organizamos y presentamos para hacer una descripción de ellos, entonces estamos haciendo ESTADISTICA DESCRIPTIVA.
Si además sacamos conclusiones acerca de las características desconocidas de la población, entonces estamos haciendo ESTADÍSTICA INFERENCIAL.
Si en cambio, nos dedicamos a realizar predicciones, entonces, actuamos en el campo de la ESTADÍSTICA PREDICTIVA
Los datos recogidos de una población lo podemos relacionar con su frecuencia de aparición, a través de una gráfica de distribución de frecuencias o histograma.
Én esta gráfica podemos apreciar cómo se comportan los datos de una muestra. Pero si hacemos que el número de datos tienda a infinito, entonces obtenemos la función de distribución de probabilidad de la población
Las funciones pueden ser discretas o contínuas
Las más comunes son
Distribución discretas de probabilidad
Distribuciones contínuas de Probabilidad
De todas éstas, la distribución de probabilidad normal merece una atención especial, pues se utilizan ampliamente en el desarrollo de las gráficas de control.
La función de una distribución de probabilidad normal está dada por la siguiente ecuación:
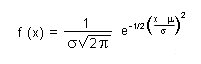
donde x representa los valores para las medidas individuales, y nu la media aritmética para un número infinito de estas medidas. La expresión (x - mu) es la desviación respecto a la media; f (x), la frecuencia con que aparece cada valor de (x - mu). Pi, tiene el significado habitual; e, es la base de los logaritmos neperianos 2,718... El parámetro sigma se llama desviación típica y es una constante que tiene un valor único para cualquier serie que contenga un elevado número de medidas.
Si nosotros queremos determinar la curva de distribución de probabilidad, debemos entonces calcular el área bajo la curva, o sea, integrar la ecuación anterior.
Como esta integración es muy compleja, se realiza un pequeńo truco, se hace cero la media poblacional (mu), y 1, la varianza poblacional (sigma al cuadrado). Con esto obtenemos una ecuación estandarizada, llamada "canónica";

La variable z reemplaza a la variable x, que se distribuye normalmente, pero con media = 0 y varianza= 1.
En la curva de distribución de probabilidad "normal", también llamada "Campana de Gauss", existe una relación que es constante, cualquiera sea la forma que adapte la curva, achatada o alargada. En el eje X de coordenadas, los valores de z asumen en la base de la curva valores hasta 3 y fracción. La probabilidad en el intervalo que va desde -1 a 1 es exactamente del 68,27% (K = 1). En el intervalo que va desde -2 hasta 2, es del 95,45 % (K = 2), y en el intervalo que va desde -3 hasta 3z, la probabilidad es del 99,73 %.
Una forma más representativa de aproximarnos más a mu, es considerar la media de los resultados individuales, debido a que las mediciones de las medias se encuentran más agrupadas entre sí que las mediciones originales. A esta curva se le conoce con el nombre de “distribución muestral de la media”; Su media, x, es la misma que la de la población original y su desviación estándar se denomina “error estándar de la media” (e.e.m.).
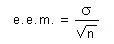
De esta ecuación se desprende; que aunque la población original no esté distribuida normalmente, tiende a la distribución normal a medida que aumenta n, lo que se conoce con el nombre de Teorema del límite central.
Límites de confianza de la media
El intervalo donde podemos suponer de manera razonable que se encuentra el valor verdadero, se le conoce como “intervalo de confianza”, y a los valores extremos de este intervalo se les denomina “límites de confianza” (El término “confianza” se refiere a que podemos afirmar con cierto grado de seguridad, o probabilidad, que el intervalo de confianza sí incluye el valor verdadero).
En Control de Calidad, específicamente en el Control Estadístico del proceso, a menudo se utilizan intervalos de confianza hasta 3 sigmas, en vez de 3 y fracción,porque el sesgo que se produce es tan pequeńo, alrededor del 0,3 %, que prácticamente no tiene relevancia en los resultados
Límites de confianza cuando s es una buena aproximación de sigma
La amplitud de la curva de error normal viene determinada por sigma. También viene dada por z. Mediante la siguiente ecuación, se calcula el área bajo la curva normal relativa al área total, para cualquier valor deseado de z.
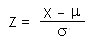
Esta relación se denomina nivel de seguridad y mide la probabilidad de que la desviación absoluta (x - mu) sea menor que z*sigma. Así el área de la curva delimitada por z = ± 1,96 sigma corresponde a un 95 % del área total. La expresión que denota el límite de confianza de una medida sencilla es:
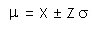
Ahora bien, cuando se trata de datos agrupados o el promedio de N medidas repetidas, entonces:

Límites de confianza cuando se desconoce sigma.
Muchas veces se corre el riesgo de que la desviación estándar calculada, s, a partir de un conjunto limitado de datos, esté sujeto a considerable incertidumbre, esto ocurre con mucha frecuencia cuando el químico tiene que emplear métodos con lo cual no está familiarizado, cuando dispone de poco tiempo o cuando la cantidad de muestras disponibles (muy pocas) excluye la correcta estimación de s. En estos casos, se utiliza el factor t en lugar de z, y se define como:

El intervalo de confianza para datos agrupados o un promedio de N medidas repetidas, es:

Donde t es una constante que se obtiene de tablas estadísticas conocido como t-student, y que depende de dos factores; del número de grados de libertad y del grado de confianza requerido.