COMP572
Neural Networks
Ludovic Hilde
Email:
[email protected]
Summer 2008
07/16/08
Assignment 4
NETWORK ARCHITECTURE
The purpose of this network
is to classify Cartesian points as class A or B. Class A points belong to a circle centered at
the origin with radius 1, whereas class B points are outside of the circle but
within a square centered at the origin with sides equal to 4. The network consists of 2 input nodes, 8
hidden nodes, and 2 output nodes. All
nodes between layers are interconnected.
The network is shown below.
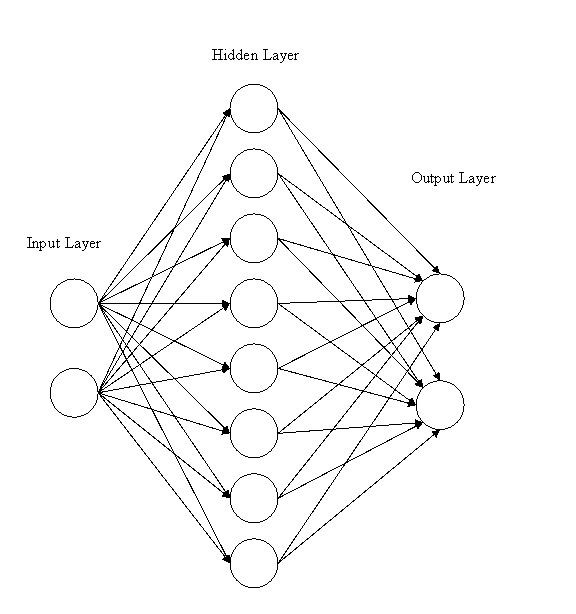
Although it is not shown in
the picture, each node on the hidden and output layers is biased externally.
SIMULATION
The simulation first trains the
network, and then tests it by feeding forward Cartesian points at the input
layer and by verifying that these points have been classified correctly at the
output layer.
Click on the link below to
access the source code of the simulation:
The 2-Class Problem source code
TRAINING
Selection Criteria
The training set consists of
points randomly selected. Points are
labeled as class A when their coordinates (x, y) satisfy x^2 + y^2 < 1 (i.e.
the circle with radius 1 centered at the origin). Otherwise, they are labeled as class B. The number of points chosen for each class
varied over multiple runs (detail in RESULTS).
The gain or step size is
fixed at 0.3 for all runs.
The momentum is set at 0.7
for all runs.
The maximum number of epochs
is set to 1000 for all runs.
Process
- Initialization
The simulation starts by
setting all weights randomly to values greater than -0.1 but less than
0.1. The arrays containing the old
weight values are initialized to zero.
(These old weight values are used to speed up the training
process.) The biases of the hidden and
output nodes are also set to values ranging from -0.1 to 0.1.
- Feedforward
The training process
continues by selecting one point from the training set and passing it through
the network.
- Error
The error value of each
output node is then calculated as shown below.
Error = targeted activation
- actual activation
- Backpropagation
The following steps of the
backpropagation process are executed sequentially.
- The error term of each output node is computed
as do = Error * ao * (1 – ao),
where Error is the value calculated in 3, ao is
the activation value of the output node.
- The error term of each hidden node is computed
as dh = (∑k Whok * dok) * ah * (1 – ah), where Whok is the
connection strength between the hidden node and one of its output node, k
is the output node index, and ah is the activation value of the hidden
node.
- The delta of each weight between a hidden node
and an output node is computed as dWho = ah * do * η, where η is the stepsize.
- The weight between a hidden node and an output
node is adjusted by Who (t+1) = Who (t) + dWho + momentum * (Who (t) - Who (t-1)), where Who
(t-1)) is the weight of the previous iteration.
- The delta of each weight between an input node
and a hidden node is computed as dWih = ai * dh * η, where ai
is the activation value of the input node.
- The weight between an input node and a hidden
node is adjusted by Wih (t+1) = Wih (t) + dWih + momentum *
(Wih (t) - Wih (t-1)),
where Wih (t-1)) is the weight of the previous
iteration.
- The bias of each hidden node is adjusted by bh = dh * η.
- The bias of each output node is adjusted by bo = do * η.
The backpropagation process
is repeated for each point in the training set.
Steps 2 to 4 of the training
process are repeated until the max epoch number is reached.
RESULTS
The network identified class
A points when the activation values of both output nodes were set to 0.99 and
0.01, and identified class B points when the activation values of both output
nodes were set to 0.01 and 0.99.
After training, the number of
Cartesian points fed through the network is set to 100 for all runs. The percent error is measured over several
runs for each training set.
|
Class A Training Points |
Class B Training Points |
Percent Error |
|
10 |
10 |
14 - 22% |
|
100 |
100 |
2 - 8% |
|
50 |
150 |
4 – 12 % |
|
1500 |
500 |
1 – 4 % |
|
1000 |
1000 |
0 – 1 % |
The network gave excellent
results when the training set contained a higher number of training
points. The best results occurred when
splitting each class with 1000 training points.
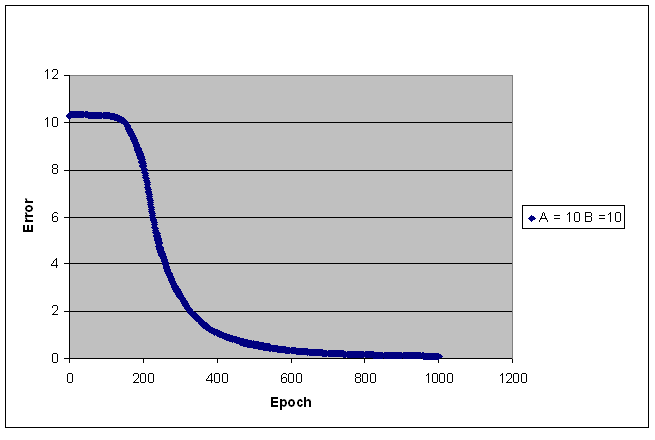
Sum Squared Error
The following pictures show
the error value versus the number of epoch.
The sum squared error is calculated as ∑k∑j (targeted activationik
- actual activationik)^2, where j is the
output node index, and k is the training set index.
The error value decreases
sharply within the first few 50 epochs when the training set is equal or
greater than 200 points.
The number of training
points for each class is indicated on the right hand side of each picture.
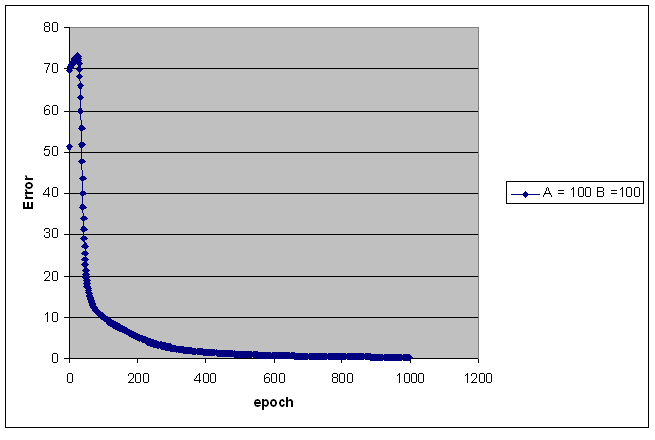
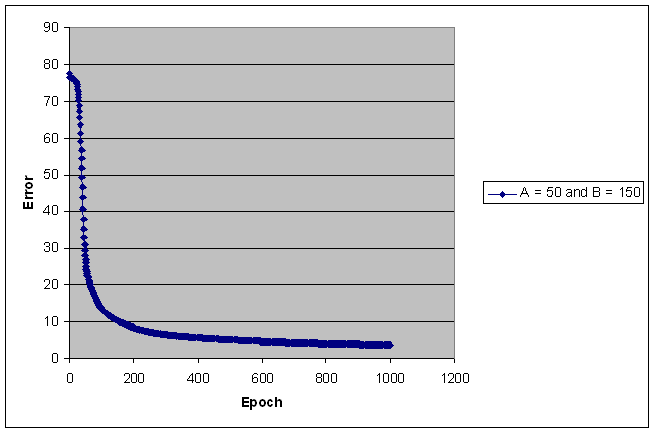
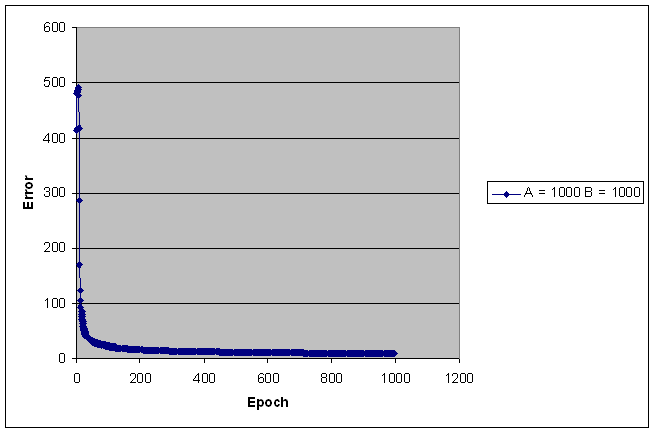
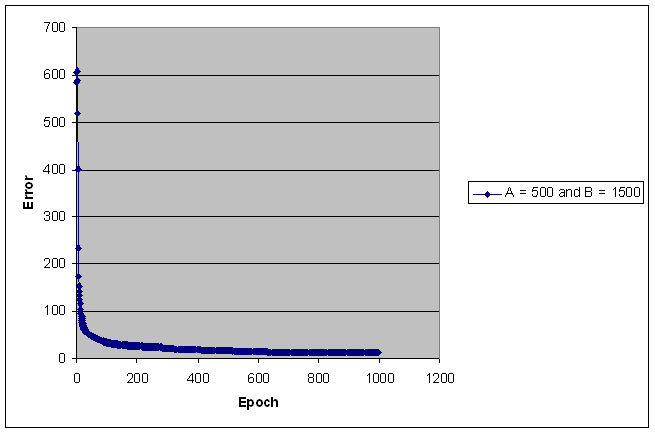
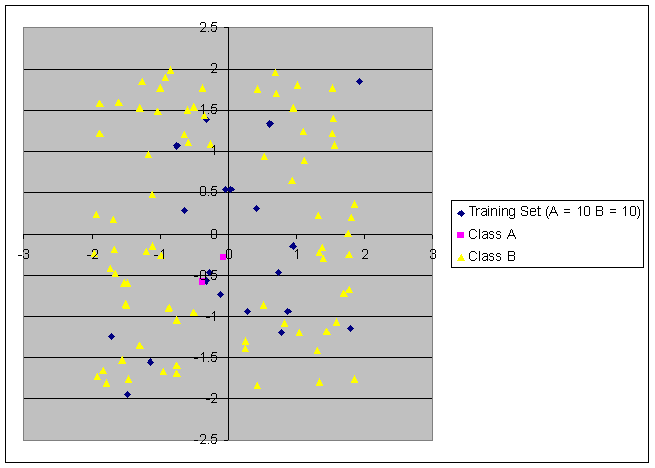
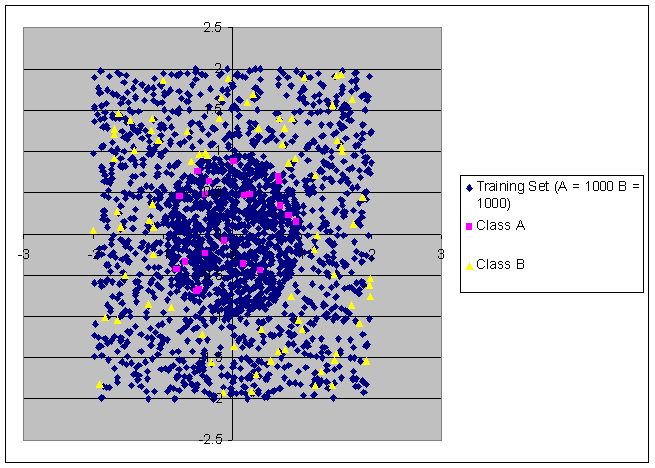
The following pictures show the
training set of the network, as well as the points that were correctly
classified. 20% of the points were
classified incorrectly for the 20 point training set, and only 2% of the points
were classified incorrectly for the 2000 point training set.