REPÚBLICA BOLIVARIANA DE VENEZUELA
UNIVERSIDAD YACAMBU.
PREGADO: LICENCIATURA EN CONTADURÍA PÚBLICA
ASIGNATURA: ESTADISTICA INFERENCIAL
Participante: LUCI
RAMÍREZ

Caracas, 18-11-2.007
Muestreo
Aleatorio - Decisión Estadística
![]() Diferencia entre Estadística Descriptiva e Inferencial.
Diferencia entre Estadística Descriptiva e Inferencial.
La primera consiste en la
observación y análisis de los hechos que acontecen (colecta de la información) Se calcula a partir de los datos de una muestra o de una
población y la segunda, en la interpretación y obtención de
conclusiones.
Ejemplos:
Estadística Descriptiva: La
clase de Métodos Estadísticos se reúne dos veces por semana de 5:30 p.m. a 7:55
p.m. en el salón 117.
Estadística Inferencial: Los
estudiantes que obtuvieron un IQ de inteligencia sobre 120, probablemente obtendrán
sobre 700 puntos en cada área de la prueba del CEEB para ingreso a la universidad.
![]() Muestras y Población.
Muestras y Población.
Muestra - Es un
subconjunto fielmente representativo de la población. Hay diferentes tipos de muestreo. El tipo de
muestra que se seleccione dependerá de la calidad y cuán representativo se
quiera sea el estudio de la población. Por ejemplo, si estudiamos el precio de la vivienda en una ciudad,
la población será el total de las viviendas de dicha ciudad.
Población
- Es
el conjunto total de individuos, objetos o medidas que poseen algunas
características comunes observables en un lugar y en un momento determinado.
Cuando se vaya a llevar a cabo alguna investigación debe de tenerse en cuenta
algunas características esenciales al seleccionarse la población bajo estudio. Así, si se estudia el precio de la vivienda de una ciudad, lo
normal será no recoger información sobre todas las viviendas de la ciudad
(sería una labor muy compleja), sino que se suele seleccionar un subgrupo
(muestra) que se entienda que es suficientemente representativo.
La
población puede ser según su tamaño de dos tipos:
Población finita: cuando el
número de elementos que la forman es finito, por ejemplo el número de alumnos
de un centro de enseñanza, o grupo clase.
Población infinita: cuando el número de elementos que
la forman es infinito, o tan grande que pudiesen considerarse infinitos. Como
por ejemplo si se realizase un estudio sobre los productos que hay en el
mercado. Hay tantos y de tantas calidades que esta población podría
considerarse infinita.
![]() Diferencia entre Muestra y Población
Diferencia entre Muestra y Población
La diferencia radica en que la población es el conjunto
de elementos de referencia sobre el que se realizan las observaciones y la
muestra es un subconjunto de casos o individuos de una población.
![]() Técnicas de Muestreo
Técnicas de Muestreo
§
Muestreo
probabilística: Forman parte de este tipo de muestreo todos
aquellos métodos para los que puede calcularse la probabilidad de extracción de
cualquiera de las muestras posibles. Este conjunto de técnicas de muestreo es
el más aconsejable, aunque en ocasiones no es posible optar por él. En este
caso se habla de muestras probabilísticas, pues no es razonable hablar de
muestras representativas dado que no conocemos las características de la
población.
El
muestreo aleatorio simple puede ser de dos tipos:
Sin reposición de los elementos: cada elemento
extraído se descarta para la subsiguiente extracción. Por ejemplo, si se extrae
una muestra de una "población" de bombillas para estimar la vida
media de las bombillas que la integran, no será posible medir más que una vez
la bombilla seleccionada.
Con reposición de los elementos: las
observaciones se realizan con reemplazamiento de los individuos, de forma que
la población es idéntica en todas las extracciones. En poblaciones muy grandes,
la probabilidad de repetir una extracción es tan pequeña que el muestreo puede
considerarse sin reposición aunque, realmente, no lo sea.
Para realizar este tipo de muestreo, y en determinadas
situaciones, es muy útil la extracción de números aleatorios mediante
ordenadores, calculadoras o tablas construidas al efecto.
§
Muestreo
estratificado: Consiste en la división previa de la
población de estudio en grupos o clases que se suponen homogéneos respecto a
característica a estudiar. A cada uno de estos estratos se le asignaría una
cuota que determinaría el número de miembros del mismo que compondrán la
muestra.
Según la cantidad de elementos de la muestra que se han
de elegir de cada uno de los estratos, existen dos técnicas de muestreo
estratificado:
Asignación proporcional: el tamaño
de cada estrato en la muestra es proporcional a su tamaño en la población.
Asignación óptima: la muestra
recogerá más individuos de aquellos estratos que tengan más variabilidad. Para
ello es necesario un conocimiento previo de la población.
Por ejemplo, para un estudio de opinión, puede resultar
interesante estudiar por separado las opiniones de hombres y mujeres pues se
estima que, dentro de cada uno de estos grupos, puede haber cierta
homogeneidad. Así, si la población está compuesta de un 55% de mujeres y un 45%
de hombres, se tomaría una muestra que contenga también esa misma proporción.
§
Muestreo
sistemático: Se utiliza cuando el universo es de gran
tamaño o ha de extenderse en el tiempo. Primero hay que identificar las
unidades y relacionarlas con el calendario (cuando proceda). Luego hay que
calcular una constante, que se denomina coeficiente de elevación K= N/n; donde
N es el tamaño del universo y n el tamaño de la muestra. Determinar en qué
fecha se producirá la primera extracción, para ello hay que elegir al azar un
número entre 1 y K; de ahí en adelante tomar uno de cada K a intervalos
regulares. Ocasionalmente, es conveniente tener en cuenta la periodicidad del
fenómeno.
§
§
Muestreo por
conglomerados: Cuando la
población se encuentra dividida, de manera natural, en grupos que se suponen
que contienen toda la variabilidad de la población, es decir, la representan
fielmente respecto a la característica a elegir, pueden seleccionarse sólo
algunos de estos grupos o conglomerados
para la realización del estudio.
Dentro de los grupos seleccionados se ubicarán las
unidades elementales, por ejemplo, las personas a encuestar, y podría
aplicársele el instrumento de medición a todas las unidades, es decir, los
miembros del grupo, o sólo se le podría aplicar a algunos de ellos, seleccionados
al azar. Este método tiene la ventaja de simplificar la recogida de información
muestral.
Cuando, dentro de cada conglomerado, se extraen los
individuos que formarán parte de la muestra por m.a.s., el muestreo se llama bietápico.
Las ideas de estratificación y conglomerados son
opuestas. El primer método funciona mejor cuanto más homogénea es la población
respecto del estrato, aunque más diferentes son éstos entre sí. En el segundo,
ocurre lo contrario. Los conglomerados deben presentar toda la variabilidad,
aunque deben ser muy parecidos entre sí.
§
Muestreo no
probabilístico: Aquel para el que no puede calcularse la
probabilidad de extracción de una determinada muestra.
§
![]() Estadístico y Parámetro
Estadístico y Parámetro
Estadístico: Es una medida usada para describir alguna característica
de una muestra, tal como una media aritmética, una mediana o una desviación
estándar de una muestra.
Parámetro: Es una medida usada para
describir alguna característica de una población, tal como una media
aritmética, una mediana o una desviación estándar de una población
![]() Distribución en el Muestreo de
Distribución en el Muestreo de
Definición: La
distribución de muestreo de una estadística es la distribución de
probabilidad que puede obtenerse como resultado de un número infinito de
muestras aleatorias independientes, cada una de tamaño n provenientes de la
población de interés.
Distribución
muestral de medias
Definición: es la
distribución de probabilidad de todas las medias posibles de muestras de un
tamaño dado, n, de una población
Def. Sea x1,x2,…
xn una muestra aleatoria de tamaño “n” de una población con
función de densidad f(x) con media y varianza σ2. La media
muestral representada por , es la media aritmética de los elementos de la
muestra, es decir: .
Teorema: Sea x1,x2,…..,xn,
una muestra aleatoria que consiste de n variables aleatorias independientes
normalmente distribuidas con medias E(xi) = y varianzas Var(xi)
= σ2 , i = 1,2, ……, n. Entonces la distribución de la media
muestral es normal con media y varianza. En efecto:
E () = E () = = 1/n(n.μ) E() = μ.
Var () = Var = = Var () = .
De
aquí se tiene que ~N(μ, .)
Luego: Z = ~ N(0,1)
Teorema: Sean
x1,x2,……..xn una muestra aleatoria de tamaño
n, de una distribución normal con media μ y
varianza σ2. Entonces zi = (xi –
μ)/σ son variables aleatorias normales estándar e independientes, i =
1,2,..,n y = tiene una distribución 2
con n grados de libertad
En teoría de probabilidad y estadística la varianza es un estimador de la
dispersión de una variable aleatoria X respecto a su esperanza E [X] . Se define como la esperanza de la
transformación (X-E[X])² , esto es, V(X)=E[(X-E[X])²]
Está relacionada con la desviación estándar o desviación
típica, que se suele denotar por la letra griega σ y que es la raíz
cuadrada de la varianza,
![]() o
bien
o
bien ![]()
Propiedades
de la varianza
Algunas propiedades de la varianza son:
- V(X) ≥0, propiedad
que permite que la definición de desviación típica sea consistente.
- V (aX + b) = a²V (X) siendo a y b constantes
cualesquiera
Varianza muestral
Dentro de la estadística descriptiva, la varianza muestral se utiliza como
medida de dispersión, cuya definición es:
![]()
También se expresa como la diferencia entre el momento de
orden 2 y el cuadrado del valor esperado:
![]()
Otra medida de dispersión similar, pero con la propiedad
de insesgadez, es la cuasivarianza
muestral:

Mientras que la desviación estándar se puede interpretar
como el promedio de la distancia de cada punto respecto del promedio, la
varianza está medida en "unidades al cuadrado".
![]() Teorema Central del Límite
Teorema Central del Límite
El Lema de Límite
Central o Teorema Central del
Límite indica que, bajo condiciones muy generales, la distribución de la
suma de variables aleatorias tiende a una Distribución Normal (también llamada
Distribución Gaussiana) cuando la cantidad de variables es muy grande.
![]() Teorema: Sea X1, X2,...,
Xn una muestra aleatoria de una
distribución con media μ y varianza σ2.
Entonces, si n es suficientemente grande, la variable aleatoria
Teorema: Sea X1, X2,...,
Xn una muestra aleatoria de una
distribución con media μ y varianza σ2.
Entonces, si n es suficientemente grande, la variable aleatoria
tiene
aproximadamente una distribución normal con ![]() y
y
![]() .
.
También
se cumple que si
![]()
tiene
aproximadamente una distribución normal con ![]() y
y
![]() .
Cuanto más grande sea el valor de n, mejor será la aproximación.
.
Cuanto más grande sea el valor de n, mejor será la aproximación.
El Teorema del Límite Central garantiza una distribución
normal cuando n es suficientemente grande.
Existen diferentes versiones del teorema, en función de
las condiciones utilizadas para asegurar la convergencia. Una de las más
simples establece que es suficiente que las variables que se suman sean independientes,
idénticamente distribuidas, con valor esperado y varianza finitas.
La aproximación entre las dos distribuciones es, en
general, mayor en el centro de las mismas que en sus extremos o colas, motivo
por el que se prefiere el nombre "Teorema del Límite Central"
("central" califica al límite, más que al teorema).
Este
teorema, perteneciente a
Ejemplo:
Un día visitamos el Casino y decidimos jugar en la ruleta.
Nuestra apuesta va a ser siempre al negro y cada apuesta de 500 ptas. Llevamos
10.000 ptas. y queremos calcular que probabilidad tenemos de que tras jugar 80
veces consigamos doblar nuestro dinero.
Cada jugada es una variable independiente que sigue el modelo
de distribución de Bernouilli.
"Salir
negro", le damos el valor 1 y
tiene una probabilidad del 0,485
"No
salir negro", le
damos el valor 0 y tiene una probabilidad del 0,515
(*) La probabilidad de "no salir negro" es mayor ya
que puede salir rojo o el cero
La media y varianza de cada variable individual
es:
m = 0,485
s 2 = 0,485 * 0,515 = 0,25
A la suma de las 80 apuestas se le aplica el Teorema
Central del Límite, por lo que se distribuye según una normal cuya media
y varianza son:
Media: n * m = 80 * 0,485 = 38,8
Varianza: n * s2 = 80 * 0,25 = 20
Para doblar nuestro dinero el negro tiene que salir al menos
20 veces más que el rojo (20 * 500 = 10.000), por lo que tendrá que salir como
mínimo 50 veces (implica que el rojo o el cero salgan como máximo 30 veces).
Comenzamos por calcular el valor equivalente de la variable
normal tipificada:
![]()
Luego:
P (X > 50) = P (Y > 2,50) = 1 - P (Y < 2,50) = 1 -
0,9938 = 0,0062
Es decir, la probabilidad de doblar el dinero es tan sólo del
0,62% (así, que más vale que nos pongamos a trabajar).
![]() Aplicaciones Teorema Central del Límite
Aplicaciones Teorema Central del Límite
![]() Siendo X una V.A. con distribución normal de media µ y varianza
Siendo X una V.A. con distribución normal de media µ y varianza
σ2 , la
distribución de
•
es normal
con media = 0 y desvío estándar = 1
•
usualmente
llamada z o normal tipificada.
Ejemplo: En cierta población humana, el
diámetro craneal sigue una distribución normal con media
Tenemos que:
m = 185.6 s = 12.7
X1 = 190
![]() Solución: buscamos la
Solución: buscamos la
 Consultando
la tabla de z, encontramos P=0.1379 (área
Consultando
la tabla de z, encontramos P=0.1379 (área
bajo la curva a la derecha
de X1)
![]() Estimación de Parámetros:
Estimación de Parámetros:
Un estimador es un
valor que puede calcularse a partir de los datos muéstrales y que proporciona
información sobre el valor del parámetro. Por ejemplo la media muestral es un
estimador de la media poblacional, la proporción observada en la muestra es un
estimador de la proporción en la población.
Una estimación
es puntual cuando
se obtiene un sólo valor para el parámetro. Los estimadores más probables en
este caso son los estadísticos obtenidos en la muestra, aunque es necesario
cuantificar el riesgo que se asume al considerarlos
La estimación de parámetros consiste en el cálculo
aproximado del valor de un parámetro en la población, utilizando la inferencia
estadística, a partir de los valores observados en la muestra estudiada. Para
el cálculo del tamaño de la muestra en una estimación de parámetros son
necesarios los conceptos de Intervalo de confianza, variabilidad del parámetro,
error, nivel de confianza, valor crítico y valor α
![]() Estimación puntual y por Intervalos
Estimación puntual y por Intervalos
Estimación Puntual:
Consiste en la estimación del valor del parámetro
mediante un sólo valor, obtenido de una fórmula determinada. Por ejemplo, si se
pretende estimar la talla media de un determinado grupo de individuos, puede
extraerse una muestra y ofrecer como estimación puntual la talla media de los
individuos.
Estimación por intervalos:
Consiste en la obtención de un intervalo dentro del cual
estará el valor del parámetro estimado con una cierta probabilidad. En la
estimación por intervalos se usan los siguientes conceptos:
 Intervalo de confianza
Intervalo de confianza
Variabilidad del parámetro
Error de la estimación
Nivel de confianza
Valor α
Valor crítico
![]() Intervalos de confianza
Intervalos de confianza
Se llama intervalo
de confianza en estadística a un intervalo de valores alrededor de un
parámetro muestral en los que, con una probabilidad o nivel de confianza
determinado, se situará el parámetro poblacional a estimar. Si α es el error aleatorio que se quiere cometer, la
probabilidad será de 1 − α. A menor nivel
de confianza el intervalo será más preciso, pero se cometerá un mayor error.
Un intervalo de confianza es, pues, una expresión del
tipo [θ1, θ2] ó θ1
≤ θ ≤ θ2, donde θ es el parámetro a
estimar. Este intervalo contiene al parámetro estimado con una determinada
certeza o nivel de confianza 1-α.
Al ofrecer un intervalo de confianza se da por supuesto
que los datos poblacionales se distribuyen de un modo determinado. Es habitual
que lo hagan mediante la distribución normal. La construcción de intervalos de
confianza se realiza usando la desigualdad de Chebyshev.
![]() Error Probable
Error Probable
Los limites
de confianza de 50% de los parámetros poblacionales correspondientes al
estadístico S dados por S + - 0.675 s la cantidad de 0.675 s es conocida como
error probable de la estimación
![]() Calculo del tamaño de la muestra.
Calculo del tamaño de la muestra.
El tamaño de la muestra se determina para obtener una
estimación apropiada de un determinado parámetro poblacional.
Para calcular el tamaño de una
muestra hay que tomar en cuenta tres factores:
- El porcentaje de confianza con el cual se quiere
generalizar los datos desde la muestra hacia la población total.
- El porcentaje de error que se pretende aceptar al momento
de hacer la generalización.
- El nivel de variabilidad que se calcula para comprobar la
hipótesis.
![]() La confianza o el porcentaje de confianza es el porcentaje de seguridad
que existe para generalizar los resultados obtenidos. Esto quiere decir que un
porcentaje del 100% equivale a decir que no existe ninguna duda para
generalizar tales resultados, pero también implica estudiar a la totalidad de
los casos de la población.
La confianza o el porcentaje de confianza es el porcentaje de seguridad
que existe para generalizar los resultados obtenidos. Esto quiere decir que un
porcentaje del 100% equivale a decir que no existe ninguna duda para
generalizar tales resultados, pero también implica estudiar a la totalidad de
los casos de la población.
Para evitar un costo muy alto para
el estudio o debido a que en ocasiones llega a ser prácticamente imposible el
estudio de todos los casos, entonces se busca un porcentaje de confianza menor.
Comúnmente en las investigaciones sociales se busca un 95%.
![]() El error o porcentaje de
error equivale a elegir una probabilidad de aceptar una
hipótesis que sea falsa como si fuera verdadera, o la inversa: rechazar a
hipótesis verdadera por considerarla falsa. Al igual que en el caso de la
confianza, si se quiere eliminar el riesgo del error y considerarlo como 0%,
entonces la muestra es del mismo tamaño que la población, por lo que conviene
correr un cierto riesgo de equivocarse.
El error o porcentaje de
error equivale a elegir una probabilidad de aceptar una
hipótesis que sea falsa como si fuera verdadera, o la inversa: rechazar a
hipótesis verdadera por considerarla falsa. Al igual que en el caso de la
confianza, si se quiere eliminar el riesgo del error y considerarlo como 0%,
entonces la muestra es del mismo tamaño que la población, por lo que conviene
correr un cierto riesgo de equivocarse.
Comúnmente se aceptan entre el 4% y
el 6% como error, tomando en cuenta de que no son complementarios la confianza y el error.
![]() La variabilidad es la probabilidad
(o porcentaje) con el que se aceptó y se rechazó la hipótesis que se quiere
investigar en alguna investigación anterior o en un ensayo previo a la
investigación actual. El porcentaje con que se aceptó tal hipótesis se denomina
variabilidad positiva y se
denota por p, y el porcentaje con el que se rechazó se la hipótesis es
la variabilidad megativa,
denotada por q.
La variabilidad es la probabilidad
(o porcentaje) con el que se aceptó y se rechazó la hipótesis que se quiere
investigar en alguna investigación anterior o en un ensayo previo a la
investigación actual. El porcentaje con que se aceptó tal hipótesis se denomina
variabilidad positiva y se
denota por p, y el porcentaje con el que se rechazó se la hipótesis es
la variabilidad megativa,
denotada por q.
Hay que
considerar que p y q son complementarios, es decir, que su suma
es igual a la unidad: p+q=1. Además, cuando se habla de la máxima
variabilidad, en el caso de no existir antecedentes sobre la investigación (no
hay otras o no se pudo aplicar una prueba previa), entonces los valores de
variabilidad es p=q=0.5.
Una vez
que se han determinado estos tres factores, entonces se puede calcular el
tamaño de la muestra como a continuación se expone.
Hablando
de una población de alrededor de 10,000 casos, o mínimamente esa cantidad,
podemos pensar en la manera de calcular el tamaño de la muestra a través de las
siguientes fórmulas. Hay que mencionar que estas fórmulas se pueden aplicar de
manera aceptable pensando en instrumentos que no incluyan preguntas abiertas y
que sean un total de alrededor de 30.
Vamos a
presentar dos fórmulas, siendo la primera la que se aplica en el caso de que no se conozca
con precisión el tamaño de la población, y es: ![]()
donde:
n es
el tamaño de la muestra;
Z es
el nivel de confianza;
p es
la variabilidad positiva;
q es
la variabilidad negativa;
E es
la precisión o error.
Hay que
tomar nota de que debido a que la variabilidad y el error se pueden expresar
por medio de porcentajes, hay que convertir todos esos valores a proporciones
en el caso necesario.
También
hay que tomar en cuenta que el nivel de confianza no es ni un porcentaje, ni la
proporción que le correspondería, a pesar de que se expresa en términos de
porcentajes. El nivel de confianza se obtiene a partir de la distribución
normal estándar, pues la proporción correspondiente al porcentaje de confianza
es el área simétrica bajo la curva normal que se toma como la confianza, y la
intención es buscar el valor Z de la variable aleatoria que corresponda
a tal área.
![]() Relación entre el tamaño de la muestra y el error probable
Relación entre el tamaño de la muestra y el error probable
Los márgenes
de error incluyen el tamaño de la muestra, por lo que inductivamente es posible
determinar el tamaño de muestra necesario para construir el margen de error que
deseamos.
Si el margen de error es: 
El tamaño de
muestra requerido para obtener un intervalo de confianza con un margen de error
aproximado ![]() para una proporción se
encuentra de la siguiente forma:
para una proporción se
encuentra de la siguiente forma:

donde ![]() es el valor anticipado
que esperamos de la proporción y Z es el valor crítico normal estandarizado
para el nivel de confianza deseado.
es el valor anticipado
que esperamos de la proporción y Z es el valor crítico normal estandarizado
para el nivel de confianza deseado.
![]() Error Tipo I. Error Tipo II
Error Tipo I. Error Tipo II
![]() El error alfa o error tipo I es el que se comete cuando los datos indican un resultado estadísticamente
significativo a pesar de que no existe una verdadera asociación o diferencia en
la población. Es decir, el que se comete al rechazar la hipótesis nula cuando
esta es cierta.
El error alfa o error tipo I es el que se comete cuando los datos indican un resultado estadísticamente
significativo a pesar de que no existe una verdadera asociación o diferencia en
la población. Es decir, el que se comete al rechazar la hipótesis nula cuando
esta es cierta.
![]() El error tipo II o error tipo
beta es el contrario, el que se comete cuando los datos
indican un resultado estadísticamente no significativo a pesar de que existe
una verdadera asociación. Es decir, cuando aceptamos la hipótesis nula siendo
falsa.
El error tipo II o error tipo
beta es el contrario, el que se comete cuando los datos
indican un resultado estadísticamente no significativo a pesar de que existe
una verdadera asociación. Es decir, cuando aceptamos la hipótesis nula siendo
falsa.
Se produce un error tipo I (falso positivo) si se rechaza la
hipótesis nula que en realidad es verdadera en la población. Se comete un error tipo II (falso negativo)
si no se acepta una hipótesis nula que en realidad es falsa en la población.
Nunca es posible evitar totalmente los errores tipo I y II pero el investigador
puede reducir su probabilidad aumentando el tamaño de la muestra (cuanto más
grande es la muestra menor es la probabilidad de que difiera considerablemente
de la población) o modificando el diseño del estudio (minimizando los sesgos) o
mejorando la información nobtenida en las mediciones (muestras más eficientes).
La probabilidad de cometer un error tipo I se denomina alfa o nivel de significación
estadística. En general los investigadores lo fijan en el 5% (0,05). La
probabilidad de cometer un error tipo II se denomina beta. La cantidad
"1-beta" se denomina potencia o poder y es la probabilidad de
observar un efecto en la muestra si en la población existe uno de un tamaño
determinado o mayor. Si se fija una beta 0,10 significa que el investigador ha
decidido que está dispuesto a aceptar una probabilidad del 10% de no
detectar una asociación de una magnitud determinada ya fijada
![]() Nivel de Significación.
Nivel de Significación.
El
rechazo o aceptación de una hipótesis nula, se basa sobre algún nivel de
significación como criterio. Una diferencia se denomina significativa cuando la
distancia entre dos medias muestrales señala una diferencia verdadera entre los
parámetros de las poblaciones de las que se sacaron las muestras
![]() Contraste de Hipótesis entre un Estadístico y un Parámetro con
muestras grandes
Contraste de Hipótesis entre un Estadístico y un Parámetro con
muestras grandes
Un
contraste de hipótesis es un procedimiento estadístico que permite decidir
entre una de dos hipótesis complementarias
H0 y H1 que, en el caso paramétrico, se refieren al valor constante, pero
desconocido de un parámetro (e.g., la media o desviación estándar) de una variable aleatoria en una
población. Para tomar la decisión, se obtienen un conjunto de valores de la
variable (x)= (x1, x2,...xn) en una muestra de individuos
de esta población y, a partir de estos valores, se calcula el valor de un
estadístico ϋ(x). Puesto que la muestra se elige
aleatoriamente, el estadístico es una variable aleatoria, cuya distribución de
probabilidad depende del valor del parámetro.
El
conjunto de los valores posibles del estadístico se divide en dos regiones
complementarias: la primera de estas regiones (región crítica C) se elige de
modo que la probabilidad de que el estadístico tome valores en C es muy pequeña
cuando la hipótesis nula H0 es cierta. La región complementaria A se denomina
región de aceptación. Una vez tomada la
muestra, si el valor particular observado del estadístico en ell pertenece a la
región crítica, rechazaremos la hipótesis nula H0 y, en consecuencia,
aceptaremos la alternativa H1. El razonamiento seguido es el siguiente: o bien
la hipótesis nula era cierta y ha ocurrido un valor de probabilidad muy baja, o
bien la hipótesis nula era falsa.
La
aplicación de un contraste de hipótesis puede dar origen a dos tipos diferentes
de error: rechazar la una hipótesis nula que era cierta (error de tipo I) o
aceptarla siendo falsa (error de tipo II).
Aunque
no podemos estar seguros de haber cometido uno de estos errores en un contraste
particular, podemos determinar la probabilidad rechazar la hipótesis nula,
mediante la función
de potencia del contraste
Ρ(θ), que se define en la forma siguiente, siendo θ el valor
desconocido del parámetro:
Ρ (θ)
= P (Rechazar H0│ θ)
Si
suponemos que nuestra hipótesis nula establece un valor dado para el parámetro
θ=θ0 (caso de hipótesis nula simple), obtenemos el valor α,
nivel de significación del contraste o probabilidad de error de tipo I:
α = P
(Rechazar H0│H0 es cierta) = P (Rechazar H0│θ0) = P (θ0)
También
podemos calcular la probabilidad de aceptar H0 en función del parámetro:
ß(θ) = P (Aceptar H0│ θ )
En
caso de aceptar la hipótesis nula, cometeremos un error de tipo II siempre que
θ sea diferente del valor supuesto θ0. Podemos ver que, en el caso de
hipótesis nula simple, mientras que la probabilidad α de cometer un error
de tipo I es constante, la probabilidad ß de cometer un error de tipo II
depende del valor desconocido del parámetro. Finalmente, y puesto que los
sucesos aceptar y rechazar la hipótesis nula son complementarios, se cumple la
siguiente relación entre estas probabilidades:
α = 1-ß(
θ0 )
Esta
relación supone que al disminuir una de las probabilidades de error, la otra
aumenta, si mantenemos un mismo tamaño de muestra.
![]() Contraste sobre la diferencia de las medias de 2 muestras grandes.
Contraste sobre la diferencia de las medias de 2 muestras grandes.
DOS MUESTRAS
Contraste sobre la diferencia de dos medias
independientes.

Conocidas ![]() y
y ![]() :
:
Desconocidas
![]() y
y ![]() pero supuestamente
iguales:
pero supuestamente
iguales:

distribuida según t con (n1+n2 -2 ) g.l.

Desconocidas ![]() y
y ![]() pero supuestamente
diferentes:
pero supuestamente
diferentes:
distribuída según t
con g.l.:
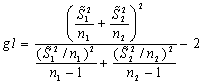
Contraste dos
medias relacionadas.
 es t con n-1 grados de libertad
es t con n-1 grados de libertad
![]() Distribución T de Student.
Distribución T de Student.
La distribución-t o distribución t de Student es una
distribución de probabilidad que surge del problema de estimar la media de una
población normalmente distribuida cuando el tamaño de la muestra es pequeño.
Ésta es la base del popular test de la t de Student para la determinación de
las diferencias entre dos medias muestrales y para la construcción del intervalo
de confianza para la diferencia entre las medias de dos poblaciones.
La distribución t surge, en la mayoría de los
estudios estadísticos prácticos, cuando la desviación típica de una población
se desconoce y debe ser estimada a partir de los datos de una muestra.
![]() Grados de Libertad.
Grados de Libertad.
Es un
estimador del número de categorías independientes en un test particular o experimento
estadístico. Se encuentran mediante la fórmula n-1, donde n=número de sujetos
en la muestra (también pueden ser representados por k-1 donde k=número de
grupos, cuando se realizan operaciones con grupos y no con sujetos
individuales).
Cuando
se trata de ajustar modelos estadísticos a un conjunto de datos, los residuos
-expresados en forma de vector- se encuenttran habitualmente en un espacio de
menor dimensión que aquél en el que se encontraban los datos originales. Los
grados de libertad del error los determina, precisamente, el valor de esta
menor dimensión.
Un ejemplo aclara el concepto. Supongamos
que:
X1,…………,
Xn Son variables aleatorias, cada
una de ellas con media μ, y que
![]()
es la "media muestral".
Entonces las cantidades Xi - Xn
Son
los residuos, que pueden ser considerados estimaciones de los errores Xi
− μ. La suma de los residuos (a diferencia de la suma de los
errores, que no es conocida) es necesariamente 0. Esto significa que los
residuos están restringidos a encontrarse en un espacio de dimensión n-1 ya que
si se conoce el valor de n-1 de estos residuos la determinación del valor del
residuo restante es inmediata. Así, se dice que "el error tiene n-1 grados
de libertad".
![]() Contraste de Hipótesis entre un Estadístico y un Parámetro en
muestras pequeñas
Contraste de Hipótesis entre un Estadístico y un Parámetro en
muestras pequeñas
![]() Contrastes sobre
Contrastes sobre
Se realizan dos muestras aleatorias simples de
tamaños n y m a dos poblaciones normales independientes
de igual varianza ![]() , pero
desconocida.
, pero
desconocida.
Los
datos se presentan en una lista de vectores reales:
![]() .
.
El
estimador de la diferencia de medias es
![]() .
.
Se
trata de contrastar la hipótesis nula
H0: "las medias de ambas
poblaciones son iguales: ![]() "
"
frente a la alternativa:
H1: "las poblaciones tienen
diferentes medias: ![]() ".
".
Para
ello se hará uso del estadístico

siendo ![]() y
y ![]() las
respectivas cuasivarianzas. El estadístico A se distribuye como
una tn+m-2 de Student cuando H0 es
verdadera.
las
respectivas cuasivarianzas. El estadístico A se distribuye como
una tn+m-2 de Student cuando H0 es
verdadera.
![]() Aplicaciones de los contrastes de Hipótesis.
Aplicaciones de los contrastes de Hipótesis.
Los contrastes de hipótesis, como la inferencia
estadística en general, son herramientas de amplio uso en la ciencia en
general. En particular, la moderna Filosofía de la ciencia desarrolla el
concepto de falsabilidad de las teorías científicas basándose en los conceptos
de la inferencia estadística en general y de los contrastes de hipótesis. En
este contexto, cuando se desea optar entre dos posibles teorías científicas
para un mismo fenómeno (dos hipótesis) se debe realizar un contraste
estadístico a partir de los datos disponibles sobre el fenómeno que permitan
optar por una u otra.
Las técnicas de contraste de hipótesis son también de
amplia aplicación en muchos otros casos, como ensayos clínicos de nuevos
medicamentos, control de calidad, encuestas, etcétera.
INFOGRAFIAS:
http://mx.geocities.com/a_alvaseg/estad_descrip_notas.pdf
http://ponce.inter.edu/cai/reserva/lvera/CONCEPTOS_BASICOS.pdf
http://es.wikipedia.org/wiki/Muestreo_en_estad%C3%ADstica
http://www.monografias.com/trabajos11/tebas/tebas.shtml
http://es.geocities.com/pestadistica2002/muestras
http://www.aulafacil.com/CursoEstadistica/Lecc-1-est.htm
http://thales.cica.es/rd/Recursos/rd97/UnidadesDidacticas/53-1-u-punt11.html#seccion2
http://es.wikipedia.org/wiki/Varianza
http://es.wikipedia.org/wiki/Teorema_del_l%C3%ADmite_central
http://descartes.cnice.mecd.es/materiales_didacticos/inferencia_estadistica/estimac.htm
http://es.wikipedia.org/wiki/Estimaci%C3%B3n#Estimaci.C3.B3n_por_intervalos
http://www.uaq.mx/matematicas/estadisticas/xu5.html
http://sameens.dia.uned.es/Trabajos6/Trabajos_Publicos/Trab_5/Sanchez_Ferron_5/DISCUSIÓN.htm
http://es.wikipedia.org/wiki/Error_tipo_I_y_tipo_II
http://www.estadistico.com/dic.html?p=1554&PHPSESSID=e9b98980c02a0f83dd2956c236a775bf
http://www.ugr.es/~batanero/ARTICULOS/Recherches.pdf
http://www.uv.es/~mperea/formularioADII.doc
http://es.wikipedia.org/wiki/Distribuci%C3%B3n_t_de_Student
http://sameens.dia.uned.es/Trabajos4/T5/T5_MartinezMaruagaAI/SignificacionEstadistica.htm