- The Individual Programming Project (IPP) will require heavy use of both the Berkeley UNIX Networking facilities (often called the BSD Socket Interface) and either Solaris or Linux (FreeBSD) thread interface. The programming interfaces of these packages can be quite complex and confusing, so you are asked to do a relatively simple exercise to gain familiarity with these interfaces before you start using them in the IPP.
- In this assignment, you will use socket and thread interfaces to implement simple Remote Timestamp Protocol (RmTP). Your implementation will consist of both a client and a server application: the client can ask of the timestamp of files on a remote machine, while the server will satisfy the request. Thus, in addition to providing you with experience with the APIs mentioned above, you will also get a brief introduction to the concept of a client-server protocol, and the implementation of a protocol state machine.
- You will write two programs, a client and a server. The server creates a socket in the Internet domain bound to port SERVER_PORT (a constant you should define in a .h file included in both programs). The server receives requests through this socket, acts on those requests, and returns the results to the requester. The client will also create a socket in the Internet domain, send requests to the SERVER_PORT of a computer specified on the command-line, and (if you have done everything right) receive responses through this socket from a server. The whole process is defined below by RTP protocol state machine.
- RmTP uses User Datagram Protocol (UDP) as its transport layer protocol.
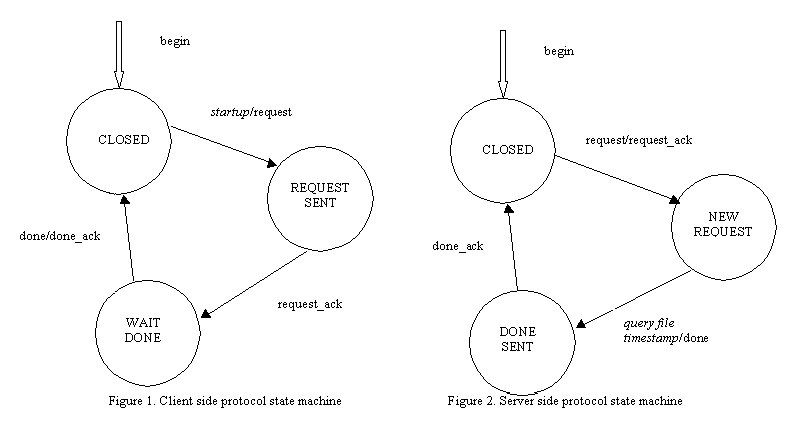
- Note: the state machines as given are for a single connection. You server must be able to handle multiple simultaneous connections, so it is probable that multiple state machines will be running simultaneously on a single server. In order to achieve this for this assignment, you are required to implement each server state machine as a separate thread. (client state machines can be implemented without multi-threading.) More about threads can be found below.
- The format of the packets used for communication between the client and server must be of the following form:
short connection_id;
short type;
short status;
char buffer[256];
- All shorts are defined to be 16-bit, signed integers.
- The type field should indicate the type of message represented by the packet. This corresponds to the various inputs and outputs found in the above protocol state machines. It should contain one of the following message types:
REQUEST, REQUEST_ACK, DONE, DONE_ACK
- For different packet types, the various packet fields’ contents are specified in table 1.
- Table 1: Packet content specification
|
Message Type |
Field |
Contents |
| REQUEST | Connection_id Status Buffer |
-1 0 pathname of remote file |
| REQUEST_ACK | Connection_id Status Buffer |
connection identifier 0 all zeros |
| DONE | Connection_id Status Buffer |
connection identifier 0 in case of success/error status in case of failure timestamp of remote file |
| DONE_ACK | Connection_id Status Buffer |
connection identifier 0 all zeros |
- Packets
When manipulating packets locally, you will probably find it convenient to use a struct to contain the various fields that make up the packet. In fact, its definition looks very much like a c-style struct. However, when sending packets over the network, there are two reasons why this is not a good idea. The definition of a protocol (including RTP) is not architecture, language or compiler dependent. In order for all implementations of a given protocol to correctly inter-operate, the position and length of fields within a packet must be exact. For this reason, before sending a packet onto the network, no assumptions can be made concerning the layout of the packet’s fields in memory. Your implementation must contain codes which explicitly lays each field into memory according to the packet definition. In other words, do not simply pass a pointer to a packet struct to the send() function.
In addition to language and compiler independence, there is an important architectural consideration. Since CPUs can be either big-endian or little-endian, care must be taken to insure that all multi-byte integers sent onto the network are laid-out in a standard network byte-order, which may or may not be identical to host byte-order. Several functions are provided for this purpose: ntohs(), ntohl(), htons(), htonl(). You are required to use these functions for any multi-byte integers sent over the network.
- Threads and Synchronization
As mentioned above, the server protocol state machine for each connection must be implemented as a separate thread. In your implementation, the initial, main thread should have the task of both creating these new threads for new connections, and of dispatching incoming datagrams to the correct state machines. The main thread should be the only one that executes the recvfrom() system call. The bulk of packet processing should be left to the new threads spawned by this main thread.
Since UDP provides no notion of a connection, incoming datagrams must be de-multiplexed to the appropriate thread by your implementation. It is for this purpose that we have designated the connection_id packet field. You should assign each new connection a unique connection_id, which can be used by the main thread to correctly de-multiplex subsequent incoming datagrams.
In addition to deciding to which state machine an incoming packet belongs, you must determine a mechanism by which the main thread can notify a waiting state machine of a packet arrival. Inefficient spin-waiting loops are not acceptable. Either semaphores or condition variables can be used to put to sleep and consequently notify a waiting thread.
- State Machines
The implementation of a protocol state machine is usually dominated by code for handling error conditions such as malformed or garbled packets, missing or out-of-order packets, etc. In the interest of simplicity, your implementation need not worry about these error conditions. You must, however, check return values of standard UNIX calls for error conditions (e.g., sendto(), recvfrom(), socket(), etc.).
The following items are required for full credit:
- must be commented
- adhere to the given packet structure
- use one thread per connection
- use some synchronization primitive (mutex, condition variables or semaphores) to implement the waiting and alerting of threads
- use a separate thread in the server for handling the socket and dispatching incoming datagrams
- all multi-byte integers sent over the network must be in network byte-order
- client command line: the client should accept an Internet hostname (e.g. apollo.ucl.ac.uk) and the filename of a remote UNIX file to be queried by the server
- client output: a client session should appear as follows:
sol22(22)% client apollo.cs.ucl.ac.uk public_html/index.html
Trying 128.xxx.xxx.xxx...
Server apollo.cs.ucl.ac.uk is querying the timestamp of public_html/index.html...
Timestamp of public_html/index.html is
Thu Sep 2 13:39:45 2005. - handing in: instructions for assignment hand-in will be given at a later date
- Start early. These programs will not be very long (about 400-500 lines total including comments), but they may be difficult to write, and they will certainly be difficult to debug.
- Watch the course webpage for additional tips and information concerning the assignment.