TOPIC 4.3: DATA MANAGEMENT
ORGANISING FILES
Files stored on magnetic media can be organised in a number of ways, just as
in a manual system.
There are advantages and disadvantages to each type of file organisation, and
the method chosen will depend on several factors such as:
- how the file is to be used;
- how many records are processed each time the file is updated;
- whether individual records need to be quickly accessible.
TYPES OF FILE ORGANISATION
The available methods include:
1) Serial
2) Sequential
3) Indexed Sequential
4) Random
SERIAL FILE ORGANISATION
- The records on a serial file are not in any particular sequence, and so
this type of organisation would not be used for a master file as there would
be no way to find a particular record except by reading through he whole
file, starting at the beginning, until the right record was located.
- Serial files are used as temporary files to store
transaction data.
USE OF SERIAL FILES
- Serial files are normally only used as
transaction files, recording data in the order in which events take place; for
example, sales in a shop, customers taking cash from a cash machine, orders
arriving at a mail order company.
- The transactions may be batched and the
master files updated at a later time, or alternatively in a real-time system,
the files may be updated straight away but the transaction file is kept for
record-keeping purposes.
- It will also be used in the event of a
disaster like a disk head crash, to restore the master file from the previous
night's backup.
SEQUENTIAL FILE ORGANISATION
- As with serial organisation, records are stored one
after the other, but in a sequential file the records are sorted into key
sequence.
- Files that are stored on tape are always either
serial or sequential, as it is impossible to write records to a tape in any
way except one after the other.
- From the computer's point of view there is
essentially no difference between a serial and a sequential file.
- In both cases, in order to find a particular record,
each record must be read, starting from the beginning of the file, until the
required record is located.
- However, when the whole file has to be processed (for
example a payroll file prior to payday) sequential processing is fast and
efficient.
ADDING AND DELETING RECORDS ON A SERIAL FILE
- Most computer languages that are used for
data processing include statements which allow the file to be opened at the
end of existing records.
- Then, if one or more new records has to be
added to a serial file, there is no problem; the new records can simply be
appended to the end of the file.
- Deleting a record is more complex. It is
easy to understand the problem if you imagine the file is held on magnetic
tape, and understand that in any particular program run you can either
read from the tape or write to the tape.
- To find the record to be deleted, the
computer has to read the tape from the beginning; but once it has found it, it
cannot back up and 'wipe' just that portion of the tape occupied by the
record, leaving a blank space.
- The technique therefore is to create a brand
new tape, copying over all the records up to the one to be deleted, leaving
that one off the new tape, and then copying over all the rest of the records.
ADDING AND DELETING RECORDS ON A SEQUENTIAL
FILE
- With a sequential file, all the
records on the tape (or disk) are in order, perhaps of employee number, so
just adding a new record on the end is no good at all.
- Of course the records could then be sorted
but sorting is a very time-consuming process.
- The best and 'correct' way is to make a new
copy of the file, copying over all records till the new one can be written in
its proper place, and then copying over the rest of the records.
- It is exactly as if you had just made a list
on a nice clean sheet of paper of all the students in the class in order of
surname, and then discovered you had left out Carter, A.N.
- The only way to end up with a perfect list
is to copy it out again, remembering to include Carter this time.
- Deleting a record is exactly the same as for
serial organisation.
USE OF SEQUENTIAL FILES
- Sequential files are used as master files
for high hit rate applications such as payroll.
- The main bulk of processing time is taken up
with the weekly or monthly payroll, when every employee's record needs to be
accessed and the year-to-date fields brought up to date, and sequential
organisation is fast and efficient.
- It is not efficient when only a few
records need to be accessed; for example if an employee changes address and
the record needs to be updated, since the entire file has to be read and
copied over to a new master file. However, as this happens relatively
infrequently it still makes sense to use a sequential file organisation.
MERGING TWO SEQUENTIAL FILES
- Sometimes it is necessary to merge two files
which have exactly the same structure into one large file.
- For example, a garden centre may have kept
two separate files, one for perennial plants and another for pot plants.
- It now decides it wants to put all plants
into one file in order to produce a catalogue.
- Suppose the two files have key fields as
follows:
| Perennial File (A) |
Pot Plant File (B) |
| 111 Fragrant dianthus
112 Dwarf shasta daisy
117 Bellflower
171 Bee balm
200 Dwarf aster
201 Geranium
203 Swallow-wort |
156 Patio Dahlia
185 Cape Fuschia
187 Hanging Carnations
266 Begonia
268 Marguerite
|
- The merged file (which we'll call File C)
will have records in the sequence 111, 112, 117, 156, 171, 185, 187, etc.
- The procedure for merging is as follows:
| Procedure Merge
Read a record from File A
Read a record from File B
Repeat
If Key_of_A <
Key_of_B then
write Record A to File C
if not end-of-file A read another record from File A
else set Key_of_A to HighValue
endif
else write Record
B to File C
if not end-of-file B read another record from File B
else set Key_of_B to HighValue
endif
endif
until no more records on either file |
- In this procedure, HighValue is assumed to
be a value higher than any of the keys on either file.
- In fact HighValue or a similar identifier is
a reserved constant in some high level languages, used in this type of
situation.
- The algorithm does not allow for one of the
files being empty.
INDEXED SEQUENTIAL FILE ORGANISATION
- Just as in a sequential file, records are
stored in sequence based on the value in the key field of each record.
- In addition, however, an indexed file
contains an index consisting of a list of key filed values and the
corresponding disk address for each record in the file.
- The index is usually stored with the file
when the file is first created, and retrieved from disk and places in memory
when the file is to be processed.
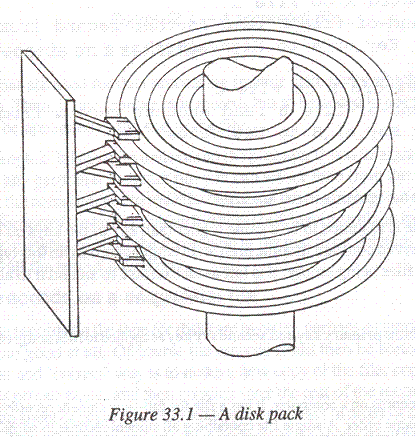
- For a large file held on a disk pack, more
than one level of index is required.
- The simplest indexing technique is called
cylinder-surface-sector indexing.
- For each disk pack in the file, there is a
cylinder index, or primary index, which will normally all be read into
memory and held there while the file is in use.
- It contains a list of the highest keys held
in each cylinder of the file.
- When looking for a record with a particular
key, this index is searched from the beginning until an entry is found which
is greater than or equal to the key required.
- The cylinder holding the record is thus
ascertained and the read-write heads can be move there (a process known as
seeking).
- A cylinder on a disk pack is made up
of all the tracks that can be accessed form one position of the read-write
heads; thus if each disk has 200 tracks, there will be 200 cylinders on the
disk pack.
- The cylinders do not of course really exist
in any touchable form, it is merely a convenient concept.
- When a large number of records is written to
a file, all the tracks in one cylinder are filled first and then the
read-write heads move across to the next cylinder.
- This minimises the movement of the
read-write heads and results in faster data transfer than filling up one
surface after another.
- Having reached the correct cylinder, a
further index is read and searched.
- This is the surface index, or
secondary index, which holds a list of the surface numbers and the highest
key to be found there.
- There is one of these indexes for each
cylinder of the file.
- By comparing these hi-keys with the one
required, the correct surface can be selected (a process known as switching).
- Once on the right track, a third level of
index, the sector index can be read and searched as before, to give the
sector number at which the record is to be found.
- For example, suppose we wish to access the
record with key 5584. The cylinder index might look like this:
| cylinder |
hi-key |
| 0
1
.
.
19
20
21 **
.
.
199 |
193
346
...
...
4382
5495
6608
...
...
49999 |
Searching this index, the first number which is
greater than or equal to 5584 is 6608. This shows that our record, if it exists,
is on cylinder 21.
Thus, the read/write heads are moved to
cylinder 21. On arrival, the surface index is located on surface 0 and is read:
| surface |
hi-key |
| 0 |
5510 |
| 1 ** |
5622 |
| 2 |
5843 |
| . |
... |
| . |
... |
| 7 |
6608 |
This means that record 5584 should be on
surface 1, so the read head for that surface is activated.
The sector index located on sector 0 of
cylinder 21, surface 1 is then read:
| sector |
hi-key |
| 0 |
5521 |
| 1 |
5538 |
| 2 |
5560 |
| 3 |
5568 |
| 4 |
5583 |
| 5 |
5597 |
| 6 |
5606 |
| 7 |
5622 |
This tells the system that the record with key
5584 should be in sector 5, so that sector 5 is read into main store. it will
then be serially searched until the correct record is located. If it is not
found, then
- either
the record does not exist
- or when
the record was added to the file, there was no room for it in cylinder 21,
surface 1, sector 5 and so the record was overflowed elsewhere.
All this disk accessing and searching is time
consuming, but still much faster than a serial search of a sequential file for
finding an individual record. However the indexes take up quite a lot of space,
and this is a disadvantage of indexed sequential organisation. The major
advantage of this file organisation is that it can be processed either
randomly using the indexes, or sequentially without using the
indexes.
OVERFLOW
- When a record, either a variable length
record which has become longer during updating, or a record which is being
newly inserted into the file, will not fit into the sector which should
accommodate it (i.e. its home sector), then an overflow has occurred.
- To allow for such a happening, an
overflow area is created on the disk pack.
- When a record will not fit onto its home
sector, it is placed into an overflow sector and a message or tag is
left in its home sector giving the key field of the record and the address of
the overflow sector in which it can be found.
- A second access then takes place and the
record can be retrieved.
- Where possible, overflow sectors should be
in the same cylinder as the corresponding home sectors so as to minimize head
movement.
- An indexed sequential file, then, consists
of three areas:
1. a
home area where the records are initially stored.
2.
One or more index areas set aside to hold the indexes.
3.
One or more overflow areas to hold records that are added at a later date
and will not fit in their correct home sectors or blocks.
BLOCKS
- When a file is recorded on disk or tape, the
physical space in which data is recorded is unlikely to be exactly the same
size as the record, which is the logical unit of the file.
- Both disks and tapes transfer data between
CPU and backing store in chunks called blocks. The number of logical
records stored in a block is called the blocking factor of the file.
- We have seen that data is recorded on a disk
around concentric circles called tracks, and that each track is divided
up into sectors.
- A block on disk takes up one sector, and so
the word 'sector' is often used interchangeably with 'block' when referring to
disk.
- When an indexed sequential file is first set
up, the user can specify how many records are to be placed in each block.
- The aims which he will take into
consideration include:
-
making file access as quick as possible;
-
dealing with additions and deletions to the file as efficiently as possible;
-
making the most efficient use of storage space.
- A common blocking strategy is to put
several records in one block, but to leave enough free space for extra records
to fit in each block before overflow occurs.
- This is particularly important if the file
is expected to grow and shrink frequently. The term block packing density
refers to the ratio of space allocated to records in each block to the
total space available.
- Similarly, cylinder packing density
is the ratio of tracts initially set aside for records to total number of
available tracks on the cylinder.
- It is common practice to allow some free
space on each cylinder to act as the overflow area.
- Example: A disk pack has 20 usable surfaces,
and each block consists of 512 bytes. Three records each of 100 bytes are
placed in each block, giving a block packing density of approximately
300/500 = 60%. Four tracks are left free on each cylinder, giving a
cylinder packing density of 16/20 = 80%.
FILE REORGANISATION
- After a period of time, if records are
continually being added to and deleted from an indexed sequential file, a
large proportion of records will end up in the overflow area.
- Indeed even the cylinder overflow areas may
become full and a secondary overflow area may come into use.
- This means that several blocks may have to
be read to locate a record, and access time increases dramatically.
- Sooner or later it becomes necessary to
reorganise the file. This entails reading the records in their logical
sequence and copying them to another file, once again allowing free space
in each home block for additional records, and recreating the indexes at the
same time.
INDEXED FILES ON FLOPPY DISKS
- For a small file, such as one that might be
held on a floppy disk, a less sophisticated procedure is used.
- The records are not held in sequence, and
the index contains an entry for every record in the file.
- The index has to be held in such a way that
it ca be quickly searched, and it is usually held as a binary tree.
USE OF INDEXED SEQUENTIAL FILES
- Indexed files are extremely useful as they
can be sequentially processed when all or most of the records need updating or
printing, and randomly when only a few need to be directly accessed.
- They are suitable for real-time stock
control systems, because each time a customer makes a purchase, the master
file can be looked up, using the index, to find the appropriate record and
ascertain the description and price to print on the receipt.
- The quantity in stock can be immediately
updated, and the record written back to the file.
- When reports of sales or stock are needed in
stock number sequence, the file can be processed sequentially, not using the
index at all.
- Sequential processing of an indexed file is
fast, but not as fast as the processing of a sequential file because each
block probably contains some empty space, and some records will be in a
separate overflow area; the records are not all in physical sequence
even though they are in logical sequence (i.e. they appear to the
user/programmer to be in sequence).
RANDOM FILES
- A random file (also called as a hash
file, direct or relative file) has records that are stored and retrieved
according to either their disk address or their relative position within the
file.
- This means that the program which stores and
retrieves the records has first to specify the address of the record in the
file.
- This is done by means of an algorithm
or formula which transforms the record key into an address at which the record
is stored.
- In the simplest case, record number 1 will
be stored in block 1, record number 1 in block number 1 and so on. This is
called as relative file addressing, because each record is stored at a
location given by its key, relative to the start of the file.
- More often, however, record keys do not lend
themselves to such simple treatment.
- If for example, we have about 1000 records
to store, and each record key is 5 digits long, it would be a waste of space
to allow 99999 blocks in which to store records. Therefore, a hashing
algorithm is used to translate the key into an address.
- One hashing method is the division/remainder
method. Using this method, a prime number close to the number of records to be
stored on the file is chosen and the key of the record is divided by this
number. The remainder is taken as the address of the record.
- For example, using the prime number 997, the
address of record number 75481 would be calculated as follows:
75481/997 = 75 remainder 706. Address = 706.
USE OF RANDOM FILES
- Random files are used in situations where
extremely fast access to individual records is required.
- To find a record, the hashing algorithm is
applied to the record key and the record address immediately found, so no time
is wasted looking up various levels of index.
- In a network system, user ids and passwords
could be stored on a random file; the user id would be the key field from
which the address is calculated, and the record would hold the password
(encrypted for security reasons) and other information on access rights.
- Random file organisation might also be used
in an airline booking system, where thousands of bookings are made every day
for each airline from terminals all over the country.
- A fast response time to the desired record
is crucial here.
- Note that random file organisation is not
suitable if reports are going to be needed in key sequence, as the records are
scattered 'at random' around the file.
SYNONYMS
- This method of file organisation presents a
problem: however cunning the hashing algorithm, synonyms are bound to occur,
when two record keys generate the same address.
- One method of resolving synonyms is to place
the record that caused the collision in the next available free space.
- Another technique is to have a separate
overflow area and leave a tag in the original location to indicate where to
look next.
- As with indexed sequential files, when the
file becomes very full and many records are not in their correct 'home', it
will be necessary to reorganise the file in order to improve access time.
- This may mean allocating more space to the
file, and/or changing the hashing algorithm.
- The records can then be read serially from
the old file and mapped to their recalculated addresses on the new file.
FIXED AND VARIABLE LENGTH RECORDS
In some circumstances records in a file may not
all be the same length. Variable length records may be used when either
- the number of characters in any field varies
between records;
- records have a varying number of fields.
A variable length record has to have some way
of showing where each field ends, and where the record ends, in order that it
can be processed. There are two ways of doing this;
- use a special end-of-field character at the
end of each field, and an end-of-record marker at the end of the record, as
shown below. (*is used as the end-of-field marker, and # is used as the
end-of-record marker)
| SH12345*laser printer * QMS
PS410*750.00*999.99*7# |
| MH452*colour flatbed scanner*Microtek
Scanmaker II*150.00*289.00*3# |
- use a character count at the beginning of
each field, and an end-of-record marker. In the implementation shown below,
the byte holding the count is included in the number of characters for the
field, and a real number is assumed to occupy 4 bytes, an integer 2 bytes.
| 8SH1234514aser
printer 10 QMS PS4105750.005999.9937# |
| 6MH45223colour
flatbed scanner22Microtek Scanmaker II5150.005289.0033# |
The advantage of allowing variable
length records is that it is more economical in terms of disk storage space. The
advantage of fixed length records is that they are simpler to process,
and allow an accurate estimate of storage requirements. When held in a direct
access file, fixed length records can be updated because the new record will
occupy exactly the same amount of space as the old record.
RESOURCE: P M Heatcote, [A Level Computing, 3rd.
Edition], Letts Educational Ltd., 1998.