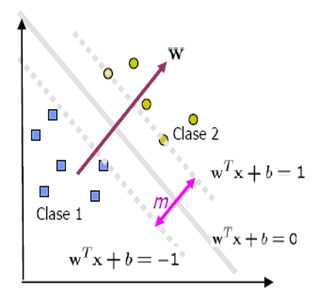
Figura 1. La frontera de decisión debe estar tan lejos de los datos
de ambas clases como sea.
SEMINARIO DE TRABAJO DE GRADO – TRABAJO FINAL
Título:
Modelo predictivo multivariable basado en Maquinas de Soporte Vectorial en
las cotizaciones dólar-euro
Autor:
Leandro José Pacheco Sebrihant Ing.
Electricista, mención sistemas y automática
INDICE GENERAL
El mercado de moneda extranjera se ha convertido en el mercado financiero más grande del mundo, durante los últimos 30 años. Con un monto mínimo de negociación y con requerimientos financieros rígidos, el mercado de la divisa, hasta hace poco, no había sido explorado por el comerciante común o el inversionista individual. Ahora cualquier inversionista promedio puede entrar a negocio de las divisas, pero debe tener una estrategia de inversión basada en premisas que fundamenten los movimientos que este realice.
Hay dos maneras principales para analizar a los mercados financieros: el
análisis fundamental y el análisis técnico. El análisis fundamental está basado
en la condición económica subyacente, mientras que el análisis técnico usa
precios históricos para predecir movimientos futuros.
Hay un debate permanente sobre qué metodología es más exitosa. Los operadores a
corto plazo prefieren usar el análisis técnico enfocando su estrategia
principalmente en la acción del precio, mientras que los operadores
fundamentales enfocan sus esfuerzos en determinar la valuación correcta de la
moneda, así como la valuación en el futuro.
En las Maquinas de Soporte Vectorial, se realiza un proceso de inducción en el cual se construye un modelo de un sistema basado en datos empíricos, del cual se espera que el sistema deduzca respuestas que aún no han sido observadas. Las Maquinas de Soporte Vectorial han ganado popularidad en los últimos años debido a que tienen un mejor desempeño empírico que las Redes Neuronales
Para la realización de este trabajo es necesario realizar comparaciones cuantitativas entre los valores reales, los arrojados por las máquina de soporte vectorial entrenada y tendencias de los valores que pueden tomar las divisas, en este caso el dolar-euro, para realizar una estrategia de inversión y generar mayores ganancias.
Implantar un modelo predictivo multivariable basado en Maquinas de Soporte Vectorial para las cotizaciones dólar-euro
Objetivo Específico
Estudiar las variables que afectan el valor de las cotizaciones
dólar-euro a fin de introducirlas en el modelo multivariable de maquinas de
soporte vectorial
Cuantificar los errores de tendencia de las cotizaciones dólar-euro
entre el modelo de las Maquinas de Soporte Vectorial creado y el valor real
Cuantificar el error absoluto de las cotizaciones dólar-euro entre el modelo de las Maquinas de Soporte Vectorial creado y el valor real
El mercado financiero más grande del mundo, del mercado de moneda extranjera,
de la divisa o del mercado de FX, todos los términos se utiliza para describir
el negocio de negociar de las varias modernidades del mundo, con más de $2
trillones que cambian a diario. El ser un mercado de moneda extranjera
internacional, las divisas es un mercado donde el dinero se vende y se compra
libremente. La DIVISA fue lanzada en los años 70, para convertirse en el mercado
financiero líquido más grande hoy, repartiendo en más de cientos veces negociar
diario en la bolsa de acción de Nueva York.
La DIVISA es un mercado perfecto a invertir adentro, pues está libre de
cualquier control externo y libre competencia. Sobre todo, todo el negociar de
la divisa es tentativo y desemejante de la bolsa que negocia, el mercado de la
divisa no es conducido por un intercambio central, sino en el mercado “interbancario”,
en el cual se piensa mientras que un mercado de OTC (sobre el contador). El
negociar ocurre entre los dos distribuidores, sobre el teléfono o a través del
Internet, por todo el mundo. Los centros que negocian principales son los que
está en Sydney, Londres, Francfort, Tokio y Nueva York, haciendo divisa 24
mercados de la hora
Aproximadamente el 5% de los movimientos es de compañias y gobiernos que estan
comprando o vendiendo productos y servicios en una moneda extranjera o tienen
que convertir sus ganancias de la moneda extranjera a su moneda local. El otro
95% son negociaciones de oportunidades o especulaciones.
Para los especuladores, se cree que las mejores oportunidades de inversion son
con las divisas comúnmente negociadas. Hoy en día mas del 85% de las
transacciones involucran al Dólar Americano, el Yen Japones, el Euro, la Libra
Inglesa, los Francos Suizos, el dólar Canadiense y el Dólar Australiano
Bajos estas hechos, se hace atractivo invertir en este tipo de mercado, por ello este trabajo sirve para presentar lo viable de una opción de análisis, como herramienta de apoyo al inversionista.
Antecedentes de la Investigación
En toda investigación es de suma importancia revisar los trabajos previos realizados, que permitan obtener ciertos aspectos que contribuyan al logro de los objetivos, dentro de ellos se encontraron:
El trabajo de Grado realizado por el ing. Cesas O. Seijas (2001) para optar al Título de Magíster en Ingeniería Eléctrica en la Universidad de Carabobo, Valencia, Venezuela. “Predicción de Series de Tiempo Usando Redes Neuronales Artificiales: Caso de Estudio Series de Tiempo Económicas Venezolanas”. En el se realizaron experimentos sobre series de tiempo económicas demostrando que el modelo basado en RNA y específicamente en RBF supera el modelo estadístico ARIMA, para pronóstico a corto y largo plazo, arrojando resultados más aproximados en valor absoluto y exhibiendo mejor índice en el indicador Matriz de Confusión. De los resultados obtenidos surgió la necesidad de evaluar modelos de pronósticos basados en RNA con series de tiempo económicas multivaluadas.
La publicación realizada por K. R. Müller, A. J. Smola y otros (1997). “Predicting Time Series with Support Vector Machines”. Proceedings of ICANN´97, Springer LNCS 1327, p. 999-1004. El artículo compara las SVM con las RNA de base radial en cuanto a la predicción de series de tiempo se refiere. Discuten el uso de diferentes tipos de funciones de pérdidas en el uso de SVM. Demuestran que ambas aproximaciones producen resultados con excelentes actuaciones con una ventaja para SVM en el régimen de alto ruido para los datos de Mackey- Glass.
La publicación realizada por Rüping Stefan (2002). “MVS Kernels for Time Series Análisis”. CS Department, AI Unit, University of Dortmund, 44221 Dortmund, Germany, E-Mail stefan.rueping@uni-dortmund. Este autor analiza la importancia del problema complejo del análisis de series de tiempo. Establece que las Máquinas de Soporte Vectorial son herramientas que permiten modelar aplicaciones del mundo real que pueden consistir en la predicción de series de tiempo con gran cantidad de datos y de alta dimensionalidad. Este artículo presenta algunas funciones de Kernel y discute sus méritos relativos, dependiendo del tipo de datos utilizados.
El trabajo de Grado realizado por el Ing. Miguel Fasanella Yacer (2004), para optar al Título de Magíster en Ingeniería Eléctrica en la Universidad de Carabobo, Valencia, Venezuela. titulado “Predicción De Series De Tiempo Usando Maquinas Vectoriales De Soporte. Caso De Estudio: Series De Tiempo Económicas Venezolanas”, en donde su objetivo principal fue elaborar un modelo predictivo de series de tiempo univaluadas no lineales económicas y financieras aplicando Máquinas de Vector de Soporte (SVM) consiguió menores errores en la desviación que en el modelo utilizado por Seijas (2004)
La publicación realizada por Kin Keung Lai, Lean Yu, Wei Huang and Shouyang Wang, “Multistage Neural Network Metalearning with Application to Foreign Exchange Rates Forecasting” A. Gelbukh and C.A. Reyes-Garcia (Eds.): MICAI 2006, LNAI 4293, pp. 338 – 347, (2006). Realizan comparaciones entre todos los modelos, empezando desde el pionero en su clase, las redes de inteligencia artificial (1943) pasando por ARIMA y llegando a las redes neuronales. En su estudio, se basaron en resultados empíricos, llegan a la conclusión que los mejores valores obtenidos para la predicción de tasas de cambio de moneda, lo obtienen con un modelo hibrido.
Todos estos trabajos, han planteado de una u otra forma la utilización de Maquinas de Soporte Vectorial y los datos con los cuales ha sido entrenadas han sido valores históricos de la misma variable a estudiar. Este trabajo, planta la utilización de otras variables que influyan en el comportamiento de las cotizaciones de las divisas, en este caso dólar-euro para predecir el valor futuro.
Teorías o referentes teóricos que sustentan la investigación:
Maquinas de Soporte Vectorial
Una Máquina de Soporte Vectorial (SVM por su nombre en ingles Support Vector Machines) aprende la superficie decisión de dos clases distintas de los puntos de entrada. Como un clasificador de una sola clase, la descripción dada por los datos de los vectores de soporte es capaz de formar una frontera de decisión alrededor del dominio de los datos de aprendizaje con muy poco o ningún conocimiento de los datos fuera de esta frontera. Los datos son mapeados por medio de un kernel Gaussiano u otro tipo de kernel a un espacio de características en un espacio dimensional más alto, donde se busca la máxima separación entre clases. Esta función de frontera, cuando es traída de regreso al espacio de entrada, puede separar los datos en todas las clases distintas, cada una formando un agrupamiento.
La teoría de las Máquinas de Soporte Vectorial (SVM) es una nueva técnica de clasificación y ha tomado mucha atención en años recientes. La teoría de la SVM esta basada en la idea de minimización de riego estructural (SRM). En muchas aplicaciones, las SVM han mostrado tener gran desempeño, más que las máquinas de aprendizaje tradicional como las redes neuronales y han sido introducidas como herramientas poderosas para resolver problemas de clasificación. Una SVM primero mapea los puntos de entrada a un espacio de características de una dimensión mayor (si los puntos de entrada están en Â2 entonces son mapeados por la SVM a Â3 ) y encuentra un hyperplano que los separe y maximice el margen m entre las clases en este espacio como se aprecia en la Figura 1.
Figura 1. La frontera de decisión debe estar tan lejos de los
datos
de ambas clases como sea.
Predicción financiera con Maquinas de Soporte Vectorial
La predicción de serie de tiempo en campos dinámicos son aportan grandes contribuciones en muchas disciplinas. El hecho de realizar predicciones de series en el tiempo en el campo financiero, ha sido una tarea difícil, las series de tiempo económicas y financieras a analizar son del tipo estocásticas, ya que estas dependen de un término estocástico que representa a todas aquellas variables difíciles de cuantificar o medir, que perfilan el comportamiento de la serie de manera aleatoria. Sin embargo, se han realizado hipótesis de mercado eficientes y al aplicarlas con técnicas de modelaje con la tecnología reciente, hace que los datos en el tiempo en el ámbito financiero, sean predecibles en cierto grado.
Una serie de tiempo esta compuesta desde el punto de vista de los métodos estadísticos por tres partes:
1. Componente de tendencia, variación de
largo plazo en el valor medio.
2. Componente estacional, comportamiento cíclico o periodo de la serie.
3. Componente aleatoria.
La teoría de aprendizaje estadístico trata con la búsqueda de una función f, que mejor aproxime la respuesta del sistema, esta función recibe el nombre de función objetivo, la cual puede ser obtenida de un conjunto de funciones desarrolladas por una máquina de aprendizaje (LM) siglas en ingles.
El método de los vectores soporte (SV) es un método general para la resolución de problemas de clasificación, regresión y estimación. Las Máquinas de Soporte Vectorial (SVM) se basan en el trabajo de V. Vapnik en 1964 sobre la teoría de aprendizaje estadístico, utilizando el principio de inducción de minimización del riesgo estructural como proceso de inferencia. En los años 90 fue generalizado y en la actualidad es objeto de un gran interés.
Las SVM son sistemas de aprendizaje que usan un espacio de hipótesis de funciones lineales en espacios de rasgos de mas alta dimensión, La idea básica es transformar los vectores de los datos de entrada x en una dimensión dada, en vectores de dimensiones más alta z, donde se puede operar en forma lineal.
RNA: Las Redes Neuronales
Artificiales (ANNs de Artificial Neural Networks) fueron originalmente una
simulación abstracta de los sistemas nerviosos biológicos, formados por un
conjunto de unidades llamadas "neuronas" o "nodos" conectadas unas con otras.
Estas conexiones tienen una gran semejanza con las dendrítas y los axones en
los sistemas nerviosos biológicos.
El Primer modelo de red neuronal fue propuesto en 1943 por McCulloch y Pitts
en términos de un modelo computacional de "actividad nerviosa". El modelo de
McCulloch-Pitts es un modelo binario, y cada neurona tiene un escalón o
umbral prefijado. Este primer modelo sirvió de ejemplo para los modelos
posteriores de Jhon Von Neumann, Marvin Minsky, Frank Rosenblatt, y muchos
otros.
Una primera clasificación de los modelos de ANNs podría ser, atendiendo a su
similitud con la realidad biológica:
Los modelos de tipo biológico. Este comprende las redes que tratan de
simular los sistemas neuronales biológicos así como las funciones auditivas
o algunas funciones básicas de la visión.
El modelo dirigido a aplicación. Estos modelos no tienen porque guardar
similitud con los sistemas biológicos. Sus arquitecturas están fuertemente
ligadas a las necesidades de las aplicaciones para las que son diseñados.
La investigación será cuantitativa.
Los datos de entrada del modelo son valores históricos expresados en dólares
americanos para los índices económicos significativos en la investigación y la
relación dólar-euro; y los resultados obtenidos son expresados a porcentajes de
errores absolutos en base a datos históricos reales según los que se hizo la
investigación.
Debido a que la SVM se entrenará para predecir la relación dolar-euro, introduciendo otras variables que afecten este valor, se debe entrenar la SVM para cada par de valores(Ej. valores históricos dolar-euro vs promedio del índice industrial del Dow Jones, para un rango de días) y comparar con cual de ellos tiene un comportamiento con el menor error absoluto y así obtener el par de variables con el cual la predicción sea mas efectiva
Población y Muestras
El principal índice dentro de los valores es la relación dolar-euro y algunas variables a utilizar para entrenar la SVM son el “Trade Weighted Exchange Index”, el precio del barril de petróleo, el promedio del índice industrial del Dow Jones entre otros.
Se trabajará con una población entre 50 y 20 valores históricos de las variables involucradas, los cuales empíricamente y bajo pruebas de la SVM se determinará la mejor cantidad de muestras a utilizar según lo errores arrojados en cada entrenamiento.
Los datos históricos se tienen dentro de una hoja de excel y se recopilan desde fuentes de bases de datos internacionales.
| DATE | VALUE dola-euro | Trade Weighted Exchange Index: Broad | Cushing, OK WTI Spot Price FOB (Dollars per Barrel) | Europe Brent Spot Price FOB (Dollars per Barrel) | DOW JONES INDUSTRIAL AVERAGE |
| 2007-07-26 | 1,3730 | 102,67 | 74,96 | 77,28 | 13473,57 |
| 2007-07-25 | 1,3711 | 102,47 | 75,74 | 75,21 | 13785,79 |
| 2007-07-24 | 1,3824 | 102,05 | 73,38 | 75,88 | 13716,95 |
| 2007-07-23 | 1,3817 | 102,21 | 74,65 | 78,36 | 13943,42 |
| 2007-07-20 | 1,3831 | 102,28 | 75,53 | 79,09 | 13851,08 |
| 2007-07-19 | 1,3811 | 102,31 | 75,9 | 78,37 | 14000,41 |
| 2007-07-18 | 1,3808 | 102,38 | 75,03 | 78 | 13918,22 |
| 2007-07-17 | 1,3782 | 102,5 | 74,03 | 77,59 | 13971,55 |
| 2007-07-16 | 1,3785 | 102,48 | 74,11 | 78,17 | 13950,98 |
| 2007-07-13 | 1,3788 | 102,6 | 73,89 | 78,12 | 13907,25 |
| 2007-07-12 | 1,3776 | 102,72 | 72,55 | 78,24 | 13861,73 |
| 2007-07-11 | 1,3757 | 102,9 | 72,58 | 77,44 | 13577,87 |
| 2007-07-10 | 1,3714 | 102,95 | 72,8 | 77,88 | 13501,7 |
| 2007-07-09 | 1,3623 | 103,2 | 72,14 | 77,1 | 13649,97 |
| 2007-07-06 | 1,3626 | 103,21 | 72,8 | 76,58 | 13611,68 |
| 2007-07-05 | 1,3592 | 103,4 | 71,81 | 75,4 | 13565,84 |
| 2007-07-03 | 1,3615 | 103,33 | 71,41 | 74,26 | 13577,3 |
| 2007-07-02 | 1,3627 | 103,27 | 71,11 | 72,9 | 13535,43 |
| 2007-06-29 | 1,3520 | 103,8 | 70,47 | 72,22 | 13408,62 |
| 2007-06-28 | 1,3466 | 103,91 | 69,61 | 71,96 | 13422,28 |
| 2007-06-27 | 1,3433 | 104,23 | 68,98 | 71,84 | 13427,73 |
| 2007-06-26 | 1,3468 | 104,15 | 67,78 | 71,41 | 13337,66 |
| 2007-06-25 | 1,3450 | 104,2 | 68,83 | 71,36 | 13352,05 |
| 2007-06-22 | 1,3438 | 104,13 | 68,85 | 72,04 | 13360,26 |
| 2007-06-21 | 1,3399 | 104,29 | 68,35 | 71,81 | 13545,84 |
| 2007-06-20 | 1,3426 | 104,03 | 68,5 | 70,55 | 13489,42 |
| 2007-06-19 | 1,3416 | 103,99 | 69,15 | 72,17 | 13635,42 |
| 2007-06-18 | 1,3401 | 104,22 | 69,06 | 72,33 | 13612,98 |
| 2007-06-15 | 1,3365 | 104,3 | 68,04 | 71,63 | 13639,48 |
| 2007-06-14 | 1,3311 | 104,59 | 67,62 | 71,18 | 13553,73 |
| 2007-06-13 | 1,3295 | 104,58 | 66,17 | 69,24 | 13482,35 |
| 2007-06-12 | 1,3325 | 104,37 | 65,36 | 68,56 | 13295,01 |
| 2007-06-11 | 1,3359 | 104,34 | 65,93 | 68,85 | 13424,96 |
| 2007-06-08 | 1,3359 | 104,44 | 64,78 | 70,04 | 13424,39 |
| 2007-06-07 | 1,3456 | 104,02 | 66,93 | 72,36 | 13266,73 |
| 2007-06-06 | 1,3492 | 103,78 | 65,97 | 71,5 | 13465,67 |
| 2007-06-05 | 1,3526 | 103,65 | 65,63 | 71,36 | 13595,46 |
| 2007-06-04 | 1,3488 | 103,65 | 66,17 | 70,9 | 13676,32 |
| 2007-06-01 | 1,3440 | 103,79 | 65,09 | 68,65 | 13668,11 |
| 2007-05-31 | 1,3453 | 103,98 | 64,02 | 68,18 | 13627,64 |
| 2007-05-30 | 1,3419 | 104,2 | 63,47 | 67,64 | 13633,08 |
| 2007-05-29 | 1,3483 | 104,01 | 63,19 | 69,31 | 13521,34 |
| 2007-05-25 | 1,3452 | 104,15 | 64,59 | 70,72 | 13507,28 |
| 2007-05-24 | 1,3429 | 104,36 | 63,62 | 71,96 | 13441,13 |
| 2007-05-23 | 1,3482 | 104,11 | 65,1 | 71,01 | 13525,65 |
| 2007-05-22 | 1,3464 | 104,23 | 64,91 | 70,05 | 13539,95 |
| 2007-05-21 | 1,3457 | 104,36 | 66,25 | 69,51 | 13542,88 |
| 2007-05-18 | 1,3511 | 104,32 | 64,93 | 69,26 | 13556,53 |
| 2007-05-17 | 1,3494 | 104,5 | 64,83 | 69,08 | 13476,72 |
| 2007-05-16 | 1,3522 | 104,47 | 62,57 | 66,83 | 13487,53 |
Tabla 1. Datos para el entrenamiento de la SVM
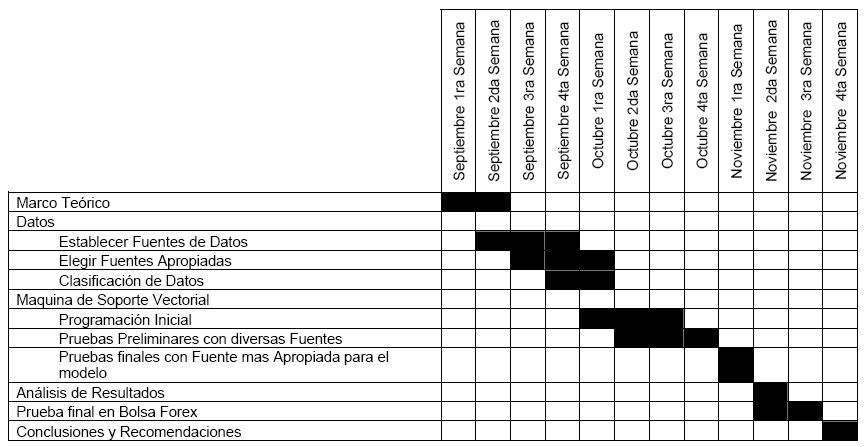
Etapas de la investigación:
1. Examinar las características de la investigación
La investigación a realizar se pudiera categorizar en dos clases, del tipo factible, en donde el problema práctico planteado es conocer el valor futuro de la cotización del dólar-euro, diseñando una herramienta que le permita el inversor de la bolsa de divisas generar ganancias y del tipo descriptivo, ya que la investigación no se limita en recolectar datos histórico, sino a predecir e identificar relaciones que existen entre dos o mas variables que afectan las cotizaciones del dólar-euro. La investigación recolecta datos sobre la base de una hipótesis o teoría, expone y resume la información de manera que los resultados puedan ser analizados a fin de extraer generalizaciones significativas que contribuyan al problema planteado
2. Definir y formular hipótesis.
Las hipótesis se formularan a partir de la
observación objetiva y su comprobación y enmarcado en el alcance de la
investigación a realizar
3. Eligen las fuentes apropiadas.
Las fuentes a utilizar serán bolsas de divisas actualmente en funcionamiento y trabajos realizados previamente en el ámbito de esta investigación
4. Seleccionar o elaborar técnicas para la recolección de datos.
Estudio de Correlación
Estudio de Desarrollo
5. Clasificar los datos, categorías precisas, que se adecuen al propósito del estudio y permitan poner de manifiesto las semejanzas, diferencias y relaciones significativas.
Establecer los datos mas significativos en
el modelo de maquinas de soporte vectorial que arroje valores con un mínimo
error en base a la peso que tengan algunas variables en las cotizaciones del
dólar-euro, como lo son el “Trade Weighted Exchange Index”, el precio del barril
de petróleo, el promedio del índice industrial del Dow Jones entre otros.
6. Realizar observaciones objetivas y exactas.
Identificar las características de los datos obtenidos y su relación con el problema planteado, describiendo el peso que puede tener una variable con respecto a la otra y concluyendo cual es la mas adecuada para el modelo de la investigación
7. Describir, analizar e interpretar los
resultados obtenidos, en términos claros y precisos.
Métodos, técnicas e instrumentos de recolección de la información:
Estudio de Correlación: dado que la
investigación se basa en un modelo multivariable, este estudio se utiliza para
determinar la medida en que dos variables se correlacionan entre sí, es decir el
grado en que las variaciones que sufre un factor se corresponden con las que
experimenta el otro. Las variables pueden hallarse estrecha o parcialmente
relacionadas entre sí. Puede decirse, en general, que la magnitud de una
correlación depende de la medida en que los valores de dos variables aumenten o
disminuyan en la misma o en diferente dirección. Si los valores de dos variables
aumentan o disminuyen de la misma manera, existe una correlación positiva; si,
en cambio, los valores de una variable aumentan en tanto que disminuyen los de
la otra, se trata de una correlación negativa; y si los valores de una variable
aumentan, los de la otra pueden aumentar o disminuir, entonces hay poca o
ninguna correlación. En consecuencia la gama de correlaciones se extiende desde
la perfecta correlación negativa hasta la no correlación o la perfecta
correlación positiva. Las técnicas de correlación son muy útiles en los estudios
de carácter predictivo. Si bien el coeficiente de correlación sólo permite
expresar en términos cuantitativos el grado de relación que dos variables
guardan entre sí, no significa que tal relación sea de orden causal. Para
interpretar el significado de una relación se debe recurrir al análisis lógico,
porque la computación estadística no dilucida el problema. Sus riesgos son los
mismos que en los estudios causales comparativos.
El modelo de Maquina de Soporte Vectorial se encargará de interpretar la
correlación entre las variables, y dará resultados expresados en porcentajes de
error para cada una de ellas
Estudio de desarrollo: Consiste en
determinar no sólo las interrelaciones y el estado en que se hallan los
fenómenos, sino también en los cambios que se producen en el transcurso del
tiempo. En él se describe el desarrollo que experimentan las variables durante
un lapso que puede abarcar meses o años, que en el caso de esta investigación
serán datos diarios. Abarca estudios de crecimiento y de tendencia. Los estudios
de tendencia consisten en obtener datos sobre aspectos sociales, económicos y
políticos y en analizarlos posteriormente para identificar las tendencias
fundamentales y predecir los hechos que pueden producirse en el futuro. En ellos
se combinan a veces técnicas históricas.
El modelo de Maquina de Soporte Vectorial se encargará de predecir la tendencia
de la variable dólar-euro, y dará resultados expresados en porcentajes de error
para la tendencia en función de los datos reales
Van Gestel, T., Espinoza, M., Baesens B., Suykens, J.A.,
Brasseus, C., De Moor, B. (2006) A Bayesian Nonlinear Support Vector
Machine Error Correction Model. Wiley InterScience
Tivegna, M. (2003) Day trading the euro-dollar with a news-based model of exchange rates. Descriptive result. University of Teramo
Lai, K.K.,Yu, L., Huang, W., Wang, S. (2006) Multistage Neural Network Metalearning with Application to Foreign Exchange Rates Forecasting. A. Gelbukh and C.A. Reyes-Garcia (Eds.)
Herbrich, R., Keilbach, M., Bollman-Sdorra, P., Graepel, T., Obermayer, K. (n.d.) Neural Networks in Economics Background Applications and New Developments. Department of Computer Science Technical University of Berlin
Clostermann, J., Schnatz, B. (2000) The determinants of the euro-dolar exchange rate. Economic Research Group of the Deutsche Bundesbank
Gunn, S. R. (1998) Support Vector Machines for Classification and Regression. University of Southampton
Alquist, R., Chinn M. D. (2002) Productivity and the euro-dollar exchange rate puzzle. National Bureau Of Economic Research
Download Data for Series: DEXUSEU, U.S. / Euro Foreign
Exchange Rate (n.d.) Extraido el 27 de Julio de 2007 desde:
http://research.stlouisfed.org/fred2/series/DEXUSEU/downloaddata?cid=94
Crude Oil in Dollars per Barrel, Products in Cents per
Gallon. (n.d.) Extraido el 27 de Julio de 2007 desde:
http://tonto.eia.doe.gov/dnav/pet/pet_pri_spt_s1_d.htm
Dow Jones Industrial Average.
Extraido el 27 de Julio de 2007 desde:
http://finance.yahoo.com/q/hp?a=00&b=3&c=1977&d=03&e=9&f=2004&g=d&s=%5Edji
Download Data for Series: DTWEXB, Trade Weighted Exchange
Index. Extraido el 27 de Julio de 2007 desde:
http://research.stlouisfed.org/fred2/series/DTWEXB/downloaddata?cid=32141