
Conceptos
Generales
Esta lección es de suma importancia, ya que se explican muchos conceptos que se utilizan en la implementación de una base de datos. Utilizar una herramienta como PostgreSQL (o una base de datos relacional propietaria) es como la persona que levanta una pared con block, ya que el trabajo efectuado corresponde a una fase dentro de una planificación mayor. La persona que levanta una pared con block está siguiendo un plano, donde se indica cual es la ubicación de la pared, el alto de la misma, donde se colocarán las columnas, etc. Una persona que utilice PostgreSQL creará tablas (o relaciones), vistas, insertará información, extraerá información pero igualmente seguirá un diseño, un diseño que indica que información es la importante y que por lo cual debe ser almacenada, donde debe ser almacenada, como debe de ser mostrada al usuario, etc.
Una persona que levanta una pared de block, no va a una parte del terreno y solamente comienza a levantar la pared. Igualmente una persona utilizando PostgreSQL no debería solamente a comenzar a crear tablas sin por lo menos una idea del plano que debe seguir (modelo de datos)
¿Porque es importante una base de datos? Una de las grandes preocupaciones del ser humano es disponer de información para ejecutar acciones. Por eso es que utilizamos una libreta para apuntar teléfonos, direcciones... o talvez fechas de cumpleaños. A pesar que no se ven de esa manera, una libreta de ese tipo puede considerarse como una base de datos. Otros ejemplos de bases de datos, son los directorios telefónicos, un libro de recetas de cocina, etc.
"Una base de datos es un conjunto de datos que pertenecen al mismo contexto almacenados sistemáticamente para su uso posterior" Ver m�s informaci�n
Lo más importante de esta definición es que nos indica que la base de datos tendrá un uso posterior y que es el momento más importante, ya que se utilizará información previamente almacenada. No podemos generar, ni obtener información de datos que no hayan sido grabados. Además de la calidad de datos ingresados al sistema dependerá en gran medida la calidad de los datos obtenidos.
Con el auge de los sistemas computacionales, aparecieron gestores de bases de datos. Los gestores de bases de datos son aplicaciones diseñadas para almacenar bases de datos en una computadora. Cada uno de estos gestores dispone de una arquitectura interna en la cual almacena la información(modelo). Sin embargo a travéz del tiempo han ido evolucionando
Los gestores de este modelo son llamados RDBMS (por sus siglas en ingles -Relational Database Management System-)
Éste es el modelo más utilizado en la actualidad para modelar problemas reales y administrar datos dinámicamente. Tras ser postuladas su bases en 1970 por Edgar Frank Codd, de los laboratorios IBM en San José (California), no tardó en consolidarse como un nuevo paradigma en los modelos de base de datos. Su idea fundamental es el uso de "relaciones". Estas relaciones podrian considerarse en forma lógica como conjuntos de datos llamados "tuplas". Pese a que esta es la teoría de las bases de datos relacionales creadas por Edgar Frank Codd, la mayoria de las veces se conceptualiza de una manera más fácil. Esto es pensando en cada relación como si fuese una tabla que esta compuestas por registros (las filas de una tabla), que representarían las tuplas, y campos (las columnas de una tabla).
En este modelo, el lugar y la forma en que se almacenen los datos no tienen relevancia (a diferencia de otros modelos como el jerárquico y el de red). Esto tiene la considerable ventaja de que es más fácil de entender y de utilizar para un usuario final de la base de datos. La información puede ser recuperada o almacenada por medio de "consultas" que ofrecen una amplia flexibilidad y poder para administrar la información.
El concepto de bases de datos relacionales es bastante amplio además la teoria de la cual se origina es puramente matemática.
Hay muchos productos de software que se llaman así mismos Administradores de Bases de Datos, sin embargo los importantes son los Administradores de Bases de Datos Relacionales. Una base de datos relacional tiene tres aspectos:
Aspecto Estructural: Nos permite ver la información
almacenada en la base de datos única y exclusivamente como tablas
Aspecto de Integridad: Las tablas satisfacen ciertas reglas,
que preservan la exactitud y fidelidad de los datos ingresados. (Llave primaria
-Primary Key-, Llave foránea -Foreign key-)
Aspecto de Manipulación: Existe un conjunto de operadores
sobre las tablas que como resultado generan otras tablas. Entre los operadores
más importantes se pueden mencionar restringir, proyectar y juntar.
Debido a que no es la finalidad extender la información sobre la definición de una base de datos relacional se exponen los términos de una manera muy resumida. Los tres aspectos mencionados son muy importantes y existe mucha información sobre ellos (ver Introducción a los Sistemas de Bases de Datos -CJ Date- 7a. edición)
El modelo de datos es una manera en la cual podemos ver la base de datos en su totalidad. Es un diagrama que representa a la base de datos. Al efectuar un proceso de Mapeo Lógico llegamos al modelo relacional (o de hecho, a cualquier otro modelo) y al aplicar un Mapeo Conceptual llegamos al Esquema conceptual, que es la parte donde ya utilizamos la sintaxis específica del producto para crear los objetos en la base de datos (tablas, vistas, secuencias, procedimientos, etc). Al mismo tiempo que Codd postulaba las bases para la teoría relacional, Peter Chen creaba el enfoque entidad-relación. En realidad, el resultado es el mismo, solamente que el enfoque de Peter Chen es visual y por lo tanto más fácilmente entendible.
Este modelo toma como punto de partida considerar la existencia de entidades, que representan objetos, personas, etc, sobre las que se quiere almacenar información relevante. Las entidades con las mismas características forman un tipo de entidad. A las características necesarias para describir completamente a cada tipo de entidad se les denominará atributo. Posteriormente, las entidades y sus atributos se representan físicamente a través de tablas (transformación en un modelo relacional) en las que los datos se almacenan en dos dimensiones. Las filas de la tabla contienen los atributos de cada una de las entidades, y las columnas el conjunto de atributos del mismo tipo de cada entidad. El grado de una entidad corresponderá al número de columnas de la tabla. La cardinalidad corresponderá al número de filas(o tuplas) que contenga la tabla. En este momento estaremos trasladando el modelo semántico entidad/relación al modelo clásico relacional, se decir, la transformación entre el modelo conceptual y el lógico. El principio fundamental en este modelado, que no puede obviarse de ninguna forma, es que hechos distintos deben almacenarse en objetos distintos.
Ejemplo de una entidad:
| |
Este es el ejemplo de una entidad. La entidad estudiante que almacena información sobre estudiantes. Existen diversas formas de representar el modelo entidad-relación, incluso existen programas, algunos comerciales otros tipo open-source que facilitan la creación de los mismos, sin embargo utilizaremos este diseño por ser uno de los más sencillos y prácticos. Se utiliza un cuadro con bordes redondeados para indicar que es una RELACION y no una tabla. El nombre de la relacion en mayúscula y en singular. El nombre de cada uno de los atributos en minúscula. |
El simbolo numeral (#) se utiliza para indicar que el atributo es de tipo LLAVE PRIMARIA. En algunas relaciones será necesario disponer de una llave primaria con un solo atributo. En el caso de la relacion estudiante (para un establecimiento educativo) el carnet será suficiente ya que cumple con los requisitos de una llave primaria que son:
El simbolo asterisco (*) se utilizará para indicar que el atributo es
necesario (not null) y que por lo tanto debe de ingresarse un valor en el mismo.
El simbolo (o) se utilizará para indicar que el atributo puede o no ingresarse.
Es un atributo de tipo opcional.
En el modelo entidad-relacion, los nombres de los atributos de cada relación pueden llevar espacios en blanco, esto no es una restricción del modelo, sin embargo, al hacer el mapeo hacia el esquema conceptual podría ser necesario quitar esos espacios, ya que algunos RDBMS no permiten espacios en el nombre del atributo. También es importante hacer notar que el modelo entidad-relacion no dice nada acerca del tipo de datos de cada uno de los atributos.
En otras relaciones será necesario disponer de más de un atributo para la llave primaria. Por ejemplo, en una relacion queremos llevar información de personas. Podriamos tener una relación tal como sigue
 |
En este caso el atributo no cedula es la llave primaria, y nuestro modelo podría trabajar perfectamente bien durante mucho tiempo, sin embargo debemos de recordar que, en nuestro caso -Guatemala-, algunos municipios utilizan el mismo número de orden para las cédulas (caso del municipio de Mixco y Guatemala, que ambas utilizan el número de Orden A-1). En este caso pueden existir dos personas que tengan el mismo número de cédula entonces ya no podría ser llave primaria porque ya no cumple con el requisito de Unicidad. |
 |
Ahora, en la misma relación tenemos dos atributos que conforman la llave primaria, el número de cédula junto al código de municipio, cumplen con el requisito de unicidad (ya que no existirán dos personas con el mismo número de cédula y código de municipio). El requisito de minimalidad significa que con los dos atributos son más que suficientes para garantizar la unicidad y que ya no es necesario utilizar alguno más. Por ejemplo se podría utilizar los atributos (no cedula, codigo municipio, fecha nacimiento) como llave primaria, ya que garantiza el requisito de unicidad, pero no minimalidad, ya que el campo fecha de nacimiento no es necesario, al quitarlo el par de atributos (no cedula, codigo municipio) sigue garantizando la unicidad |
Ya en la práctica es necesario manejar un conjunto de entidades, y mucho más importante, como se relacionan entre ellos.
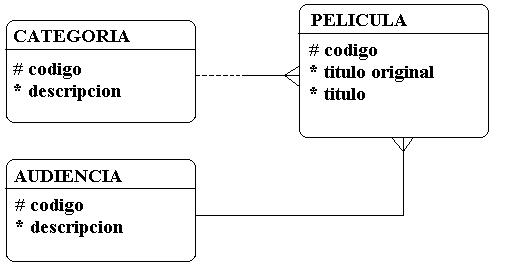
En el diagrama anterior vemos 3 entidades (PELICULA, CATEGORIA, AUDIENCIA), la entidad CATEGORIA contendrá las distintas categorías que pueda tener una película junto con su respectivo código (terror, comedia, drama, infantil, etc). La entidad AUDIENCIA se utilizará para almacenar los distintos tipos de audiencia para cada película (todo publico, mayores de 13 años, mayores de 18 años, etc). Para indicar que una entidad está relacionada con otra se utiliza una linea, para el caso de CATEGORIA y PELICULA existe una linea entre las dos entidades, señalando que en la entidad PELICULA existirá un campo donde se almacenará el codigo de la categoría a la cual pertenece una pelicula en particular (Este campo en la entidad PELICULA es también llamado Llave Foránea -Foreign Key-), observe que la primera parte de la linea está punteada, indicando que existe la posibilidad que algunas películas no tengan definida una categoría. Ya en el esquema conceptual dicho atributo tendría la posiblidad de aceptar nulos, la linea finaliza con una "pata de gallo", esto indica que la relación es de 1 a muchos. La explicación es sencilla, indica nada más y nada menos que existen varias películas que tienen la misma categoría. La entidad PELICULA también tiene una relación de 1 a muchos con la entidad AUDIENCIA, aquí el atributo es obligatorio, por lo que al hacer el mapeo al esquema conceptual dicho campo debería de ser NOT NULL.
Las relaciones entre entidades pueden ser entonces:
Cuando existe n cantidad de entidades relacionadas entre sí, por medio de relaciones de muchos a muchos se resuelve agregando una nueva entidad (entidad asociativa). Cada una de las entidades se relaciona con la nueva entidad con una relación de uno a muchos.
Cuando dos entidades tienen relación de uno a uno y ambas son de caracter obligatorio, la llave foranea puede estar en cualquiera de las dos entidades.
Cuando dos entidades tienen relación de uno a uno y una parte es optativa, la llave foránea se crea en la parte optativa.
Cuando dos entidades tienen relación de uno a uno y ambas partes son optativas, la llave foránea puede ir en cualquiera de las dos.
Observe que la entidad CATEGORIA y la entidad AUDIENCIA poseen basicamente los mismos atributos (codigo, descripcion) por lo tanto podrían ser, en vez de entidades separadas una misma entidad. Sería necesario agregar un atributo adicional para saber en que momento nos referimos a una categoria y en que momento nos referimos a un tipo de audiencia. También existen ocasiones en que una entidad está relacionada consigo misma. Por ejemplo, un dispositivo de computadora por si mismo puede ser un artículo que pueda estar a la venta en una tienda de computadoras, Memoria Ram, Disco Duro, Floppy Drive, etc. Pero también pueden formar parte de otro componente, por ejemplo, un CPU puede tener Memoria Ram, Disco Duro, Floppy Drive

en a) podemos ver como quedaría el modelo utilizando una entidad en vez de dos. en b) una entidad que tiene relación de 1 a muchos consigo misma.
La definici�n del modelo conceptual con la t�cnica propuesta por Chen propone una secuencia de fases para la obtenci�n del modelo:
1. Identificar las entidades dentro del sistema: para ello, debe conocerse el funcionamiento del sistema en estudio, a trav�s de estudios de usuarios, de necesidades de informaci�n, de tipos de informaci�n, etc. Como gu�a puede utilizarse para la definici�n de las entidades objetos reales, personas, actividades del sistema, objetos abstractos, etc.
2. Determinar las claves o identificadores de entidades: se�alar aquellos atributos que identifiquen inequ�vocamente cada ocurrencia de la entidad, y que no puedan ofrecer valores nulos.
3. Establecer las relaciones entre la entidades, describiendo el grado de las mismas: estudiar las asociaciones entre las entidades, para definir su importancia dentro del contexto del sistema, y obtener su cardinalidad.
4. Dibujar el modelo de datos: representar gr�ficamente el modelo obtenido.
5. Identificar y describir los atributos de cada entidad: se�alar aquellas propiedades de la entidad de inter�s para el sistema.
6. Verificaciones: eliminaci�n de las relaciones redundantes y que puedan ser obtenidas a trav�s de combinar otras asociaciones.
DDL: Lenguaje de definici�n de datos (que nos permite crear las estructuras )
DML: Lenguaje de manipulaci�n de datos (que nos permite tener acceso a las estructuras para suprimir, modificar e insertar)
SQL: Lenguaje de selección de datos
La mejor manera de comprender la definición de datos, la manipulación de datos y la selección de datos es trabajando un ejemplo desde el inicio, esto es desde la definición de la situación, modelo de datos, mapeo conceptual hasta la generación de resultados para el usuario.
Enunciado:
Una entidad educativa brinda varios cursos de computación. Cada curso
tiene una hora de inicio y una hora de finalización. Los cursos se dan
en variados días, algunos son diarios, otros algunos días de la
semana solamente. Los alumnos se asignan el curso al momento de cancelar y después
de pasar las respectivas evaluaciones obtienen su nota final. Elaborar un sistema
de base de datos para llevar el registro.
En la siguiente parte se elaborará el modelo de datos y se procederá a efectuar el mapeo al esquema conceptual. Como primer tarea práctica elabore el modelo de datos según su propio criterio y compárela con la mostrada en la siguiente lección. Es necesario aclarar que no necesariamente tiene que quedar iguales, para este tipo de situaciónes pueden conseguirse una gran cantidad de soluciones y probablemente todas correctas. Todo depende del nivel de abstracción que se utilice e incluso puede llegar a soluciones novedosas que afecten favorablemente el rendimiento.
DEFINICIONES:
Antes de pasar a otro punto, es necesario presentar las siguientes definiciones que deben de ser manejadas con claridad para comprender el resto de los conceptos en las bases de datos relacionales. Algunas son definiciones talvez un poco simples que serán extendidas y formalizadas posteriormente.
| Tupla | Es una hilera o fila en una tabla |
| Atributo | Es una columna en una tabla |
| Dominio | Es el conjunto de valores de los cuales los atributos obtienen sus valores |
| Llave | Es un atributo con una característica de relevancia para identificar la tupla |
| Llave Primaria | es una llave con valores únicos, es decir, que no ocurren más de una vez, cumple con los requisitos de unicidad y minimalidad |
| Cardinalidad | Número de filas en la tabla |
| Grado | Número de columnas en la tabla |
| Relación | Una definición simple es que se corresponde con una tabla y en ocasiones es preferible pensarlo de dicha manera. La definición canónica es que una relación es el producto cartesiano de dos o varios dominios. Podemos también decir que un dominio es un conjunto de valores escalares del mismo tipo, donde un valor escalar es la mínima unidad semántica de información en el sentido que son valores atómicos (no hay valores tipo conjunto, tipo registro o tipo tabla) |
| Tabla Base | Es una relación autónoma, a diferencia de las vistas y las tablas intermedias construidas a partir de una consulta |
| Vista | Es una relación virtual, que se construye a partir de tablas base o incluso otras vistas formada por atributos de estas otras tablas de forma directa o como resultado de una consulta |