JUAN CAMILO
MUÑOZ CASTELBLANCO
CORRECCIÓN SEGUNDO PARCIAL
ANÁLISIS DE ALGORITMOS
1.
int findNumber(int[] A){
int n = length(A);
int d = floor(log(n,2)) +
1; // numero de dígitos del elemento mayor
A[n] = 0;
int[]
B; // arreglo auxiliar para poder escoger los elementos candidatos
int find
= 0; // variable en la que se va formando el número desconocido
for (
int
j = d-1; i >= 0; i--){ // desde el dígito más significativo hasta el menos
significativo
int
l = length(A);
int
c1 = 0; // Contador para los ceros en ese dígito
int
c2 = 0; // Contador para los unos en ese dígito
for ( int
i
= 0; i
< l; i++){
if ( getDigit(A[i],j) == 0){ c1++ }
else
{ c2++ } // Cuenta de ceros y unos
}
if
(c1 < pot(2,j)){
// si falta un cero en ese dígito
int h = 0;
for
( int
i
= 0; i
< l; i++){
if ( getDigit(A[i],j) == 0){ // se
colocan el B los elementos candidatos
B[h]=A[i];
h++;
}
}
} else
{ si falta un uno en ese dígito
int h = 0;
for
( int i = 0; i < l; i++){ // se colocan el B los elementos candidatos
if ( getDigit(A[i],j)
== 1){
B[h]=A[i];
h++;
}
}
find = find + pot(2,j); // se
suma al valor esperado la potencia de dos elevado al dígito
}
A = B; // se hace a A
igual a B, que tiene un tamaño menor a ½ del tamaño de A
B = newArray();
// se reinicia el arreglo B
}
return
find; // Retorna el número encontrado.
}
Explicación
Como se hace un recorrido de los dígitos de
los elementos en sistema binario, eso se va a tomar un tiempo de log
n, pero dentro se hacen recorridos a un arreglo, al que su longitud decae en
razón de n/2, es decir
T(n) = log ( T(n/2))
+ c
Esta recursión es de orden n, no es
log
n, ya que se hacen recorridos internos a un arreglo, pero tampoco es nlogn,
ya que ese arreglo decae en su magnitud a razón de n/2.
2.
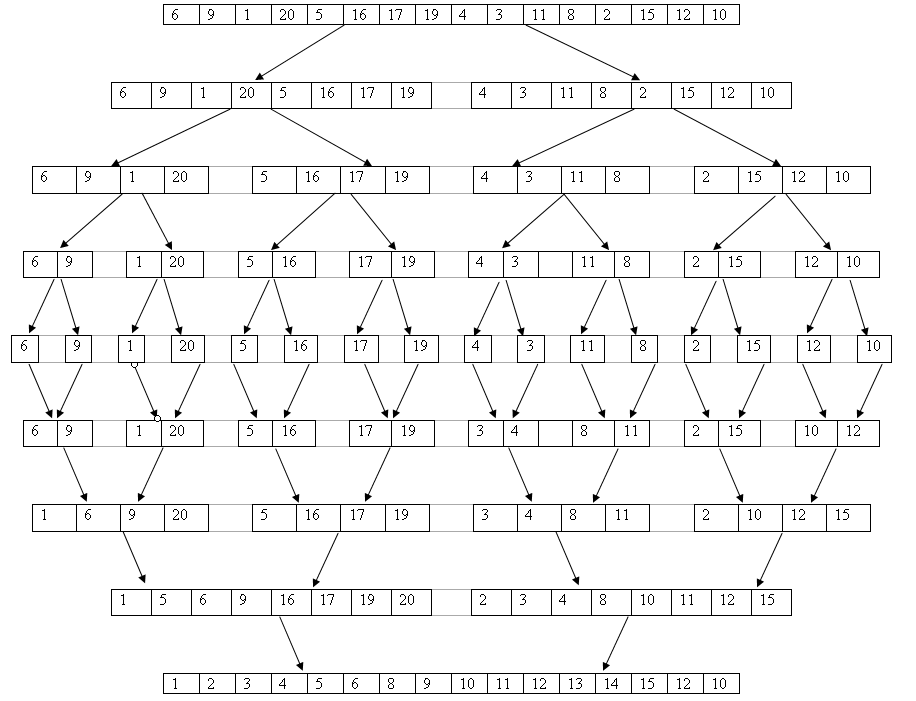
Memoización
En casos de n grandes, esta técnica es
ineficiente ya que solo le quita algunos pasos de orden lineal a la complejidad
de este ordenamiento que es de orden nlogn, además de que es muy
difícil que las comparaciones que se han de realizar se repitan, a no ser que
los elementos que se vayan a organizar sean muy repetidos, para este caso se
podría estudiar la posibilidad de usar countin, radix o bucket
sort,
por el rango pequeño de datos que pueda tener.
3.
int[] stopStation(int[]
A , n){
int
l = length(A);
int
h = 0;
int[] B; // arreglo auxiliar para poder recoger el
número de la estación el la que se va a realizar las
paradas
for ( int i = 1; i < l; i++){ //
el algoritmo sale si la gasolina no alcanza para algún recorrido entre
estaciones intermedias
if( A[i] > n){
return(B);
exit(0);
}
}
for
( int
i = 1; i < l; i++){ // Se van sumando las distancias para saber si se puede
alcanzar una
estación
mas lejana desde la primera posición
A[i] = A[i] +A [i-1];
}
int j = 0;
while
( j < l-1 ){ // Desde la posición cero hasta una posición menos va colocando
las estaciones
donde va a parar
if
( A[j] < n && A[j+1]-A[j] > n){ // si encuentra la estación más
lejana que puede alcanzar
desde que se encuentra
B[h] = j+1; //
Ingresa la posición en el vector de resultados
for
( int
k = j; k < l; k++){ // resta el combustible que ha perdido al llenar el
tanque
A[k] = A[k]
- A[j];
}
h++;
// aumenta una posición para ingresar otra estación a la solución
}
j++;
// examina la siguiente estación
}
return(B);
// Retorna una lista de las estaciones en que ha de parar
}