|





 TEST 1
TEST 1|
RED
|
COBERTURA
|
OBJ. EMPRESARIAL
|
CONMUTACIÓN
|
|
Red telefónica
|
WAN
|
Pública
|
Red de conmutación de circuitos
|
|
IEEE 802.3
|
LAN
|
Privada
|
Red de difusión
|
|
Frame Relay
|
WAN
|
Pública
|
Red de conmutación de
paquetes por circuitos virtuales
|
|
RDSI
|
WAN
|
Pública
|
Red de conmutación de circuitos
|
|
SMDS
|
WAN
|
Pública
|
Red de conmutación de
paquetes por datagramas
|
Pregunta 2:
Un paquete de estado de enlace es normalmente mucho más pequeño que un vector de distancias, ¿por
qué? ¿qué contiene cada uno? Diga otra
ventaja del encaminamiento de estado de enlace frente al de vector de distancias .
Solución
Pregunta 2:
La longitud de un vector de distancias es proporcional al número de nodos de la red (normalmente grande). Contiene la menor distancia conocida y el camino para cada destino, mientras que un paquete de estado de enlace sólo tiene las distancias conocidas a sus vecinos (además de los campos de edad, secuencia e identificador).
El número de nodos vecinos es menor que el número de nodos totales, así que si la red es bastante grande (los campos identificador + edad + secuencia ocupan menos que los nodos vecinos) el paquete de estado de enlace será menor.
Otra ventaja es que reacciona más rápido y es más estable, aunque requiere más memoria y más procesamiento por la CPU que el vector de distancias. Permite realizar un encaminamiento estático en cada nodo.
Vector de distancias:
|
Nodo destino
|
Dist. menor
conocida
|
Siguiente nodo
|
|
A
|
5
|
B
|
|
...
|
...
|
...
|
Tiene una entrada por cada nodo de la red. Si un paquete va al nodo A, se mandará por el nodo B, que está a una distancia de 5, en B se realizará a su vez el encaminamiento hacia A.
Estado de enlace:
|
A (identificador de nodo)
|
|
Nº secuencia
|
|
Edad
|
|
B
|
5
|
|
F
|
2
|
|
...
|
...
|
Es te paquete indica a los nodos vecinos de A, "hola soy A, mis vecinos y la distancia a éstos son: B,5; F,2; ... Tendré una entrada por cada nodo vecino.
Pregunta 3:
¿Qué tipo de control de congestión es el Token Bucket ("cubo con fichas")? ¿Cómo funciona?
Si la capacidad del cubo es C bits, la tasa de llegada
de fichas es N bits/s y la tasa máxima de salida es M bits/s, ¿cuál es la longitud máxima de ráfaga
que soporta?.
Solución
Pregunta 3:
Token Bucket es un algoritmo de control de congestión basado en el conformado de tráfico. Es de tipo bucle abierto, lo que significa que previene la congestión (no reacciona cuando ya se ha producido, sino que previene que no se produzca), y lo hace conformando el tráfico que entra a la red para que ésta sea más determinista.
Funcionamiento:
Permite que entren ráfagas de tráfico de unos ciertos parámetros. Las fichas se acumulan en el cubo
a una velocidad N de manera que hay un
número máximo de fichas, determinada por C. El tráfico llega al nodo, si hay ficha, la coge y se transmite
a una velocidad M, si no hay ficha ese tráfico
se descarta. Rellenaré el cubo con fichas a la tasa deseada para regular la velocidad de transmisión.
Longitud máxima de ráfaga:
En bits: 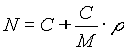
C: capacidad del cubo
C/M: tiempo que tardan en gastarse las fichas del cubo
C/M: velocidad de regeneración de las fichas
(C/M): fichas que se regeneran durante el tiempo en el que se gastan las acumuladas
Se trasnmiten N bits a M bits/s: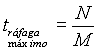
Pregunta 4:
¿Cómo son las direcciones en X.25? Estas direcciones sólo se usan en los paquetes de petición de
llamada (call request) y
de llamada entrante (incoming call). ¿Por qué no se usan en el resto de los paquetes del protocolo X25?
¿qué se usa en su
lugar? .
Solución
Pregunta 4:
Las direcciones en X.25 se componen de 14 dígitos:
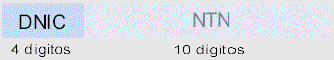
El DNIC (Data Network Identifier Code) identifica a cada red X.25 y distingue al operador público (Iberpac
(españa)tiene
uno, Transpac (Francia) tiene otro). Es único a nivel mundial. El NTN (Network Terminal Number) es el
número de
abonado, en España está limitado a 9 dígitos. Este tipo de dirección posibilita el encaminamiento jerárquico.
La codificación se hace en BCD, se uso un octeto para cada 2 dígitos. En algunas ocasiones, el número de dígitos es impar (España, por ejemplo) lo cual da lugar a medio octeto sobrante, para esto usaremos el relleno (padding). La utilización de estas direcciones es la siguiente: usaremos siempre el DNIC, incluso si llamamos a nuestra propia red (es como telefonear Madrid-Madrid marcando siempre el 91 delante, que por otra parte es lo que hacemos ahora). Otra opción de utilización es no usar el DNIC internamente, y usar para llamadas externas 0 + DNIC + NTN (esto es lo que usa Iberpac).
Los paquetes call request e incoming call necesitan la dirección ya que son paquetes que se usan para establecer la llamada, en éstos se asocia la comunicación a un circuito virtual de manera que en el resto de paquetes se usa el identificador del circuito virtual (CV) en lugar de la dirección (el encaminamiento sólo se realiza en el establecimiento de la conexión, después cada nodo tiene una tabla que asocia un camino con un identificador de circuito virtual). Estos identificadores de circuito virtual son los NCL (Número de Canal Lógico). El rango de NCL que pueden usarse, es algo a negociar con la empresa que ofrece el servicio(Telefónica, etc. ). Más NCL, mayor número de CVs establecibles. Un NCL se especifica con 12bits, lo cual da lugar a que puedan usarse como máximo 4095 NCLs (el 0 tiene un significado especial). Los NCLs se escogen por el DTE o por el DCE (la red en el fondo) cuando se necesitan, liberándolos cuando los acaban de usar. Ambos tienen una lista donde marcan los NCLs libres y ocupados (lo que se marca en una lista se refleja inmediatamente en la otra).
Pregunta 5:
¿Para qué sirven los campos de "identificación", "desplazamiento de fragmento (offset)"
y el bit "MF (more fragments) de la
cabecera del datagrama IP?.
solución
Pregunta 5:
S e utilizan cuando se fragmenta un datagrama, debido a la interconexión de redes distintas, por ejemplo, en la que cada red tiene una MTU (Maximum Transfer Unit) diferente, y para mandar un datagrama de una red a otra con MTU menor, es necesaria la fragmentación.
Identificador: es un número de secuencia. Es el mismo en todos los datagramas generados al segmentar e igual al del datagrama original.
Offset: posición de los datos del datagrama segmentado en el original, se cuenta por octetos.
Bit MF: si está puesto a "1" indica que hay más fragmentos, si está a "0" indica que ese es el último fragmento del datagrama segmentado.
