9 de agosto del 2003
Computación
distribuida
De Wikipedia, la enciclopedia libre.
La computación
distribuida, computación en grilla o informática en rejilla, es
un nuevo modelo para resolver problemas de computación masiva utilizando un
gran número de ordenadores organizados en racimo
incrustados en una infraestructura de telecomunicaciones distribuida.
La computación en rejilla ha sido diseñada para resolver
problemas demasiado grandes por cualquier simple superordenador, mientras mantiene la
flexibilidad de trabajar en multiples problemas más pequeños. Por tanto, la
computación en rejilla es un entorno multi-usuario.
Debido a esta razón, las técnicas de autorización segura
son esenciales para permitir que los recuros informáticos sean controlados por
usuarios remotos (distantes).
La informática en rejilla consiste en compartir recursos
heterogéneos (basadas en distintas plataformas,
arquitecturas de equipos y programas, lenguajes de programación), situados en
distintos lugares pertenecientes a diferentes dominios de administración sobre
una red que utiliza estándares abiertos.
Dicho brevemente, consiste en virtualizar los recursos informáticos.
En términos de funcionalidad, las Rejillas se clasifican
en Rejillas computacionales ( incluyendo las rejillas In terms of
functionality, Grids are classified into Computational Grids (incluyendo
rejillas de barrido de la CPU ) y en Rejillas de Datos.
La herramienta Globus ha emergido como
el estándar de facto para la capa intermedia (middleware) de la
rejilla. Globus tiene recursos para manejar:
a) La gestión de
recursos(Protocolo de Gestión de Recuros en Rejilla o Grid Resource
Management Protocol - GRAM)
b) Servicios de Información (Servicio de Descubrimiento y
Monitorización o Monitoring and Discovery Service - MDS)
c) Gestión y Movimiento de Datos (Acceso Global al
Almacenamiento Secunda Global Access to secondary Storage(GASS) y FTP
en Rejilla GridFTP)
La mayoría de rejillas que se expanden sobre las
comunidades académicas y de investigación de Norteamérica y Europa están basadas en las herramienta Globus Toolkit
como núcleo de la capa intermedia.
Los servicios web
basados en XML ofrecen una forma de acceder a diversos
servicios/aplicaciones en un entorno distribuido. Recientemente, el mundo de la
informática en rejilla y los servicios web caminan juntos para ofrecer la
Rejilla como un servicio web (Servicio de Rejilla). La arquitectura está
definida por la Open Grid Services Architecture (OGSA). Serán
ofrecidas varias funcionalidades, adheridas a la semántica de los Servicios de
Rejilla.
La versión 3.0 de Globus Toolkit, que actualmente se
encuentra en fase alfa, será una implementación de referencia acorde con el
estándar OGSA.
La rejilla ofrece una forma de resolver los problemas de Gran
Reto como el plegamiento de las proteinas y descubrimiento de
medicamentos, modelización financiera, simulación de terremotos, inundaciones y
otras catástrofes naturales, modelización del clima/tiempo, etc. Ofrecen un
camino para utilizar los recursos de las tecnologías de la información de forma
óptima en una organización.
Vease también:
Referencias
- Ian Foster, Carl Kesselman
(1999). La Rejilla: libro azul para una nueva infraestructura informática (The
Grid: Blueprint for a New Computing Infrastructure). Morgan Kaufmann
Publishers. ISBN
1558604758. Website.
- Fran Berman,
Anthony J.G. Hey, Geoffrey Fox (2003). La rejilla informática:
haciendo realidad la Infraestructura Global (Grid Computing: Making The Global
Infrastructure a Reality). Wiley. ISBN
0470853190. Online version.
Enlaces Externos
- El proyecto Globus
- Sitio web de informática en rejilla de IBM
- Proyecto de datos en rejilla de la UE
- http://www.gridcomputing.com/
- Artículo de O'Reilly sobre los programas de
informática en rejilla
- Como puede contribuir a la lucha contra las
enfermedades utilizando la informática en rejilla .
16 de agosto del 2003
Antecedentes
En un
sistema distribuido los procesos están repartidos en distintas máquinas, e
intercambian información mediante paso de mensajes sobre algún sistema de
comunicación. Cuando se les compara con los sistemas tradicionales,
“centralizados”, surgen nuevos problemas, debidos a la propia distribución:
retardos, particiones de la red, fallo independiente de máquinas, etc. Pero
también hay nuevas posibilidades, como por ejemplo la replicación de procesos
en diferentes máquinas para incrementar la tolerancia a fallos. Todo esto hace
que el diseño y la implementación de sistemas distribuidos sea una tarea
compleja y difícil. Así, es particularmente útil encontrar formas de
simplificar los problemas, y proporcionar módulos o paradigmas probados y
listos para usar, que resuelvan algún aspecto difícil de la construcción de
sistemas distribuidos. Esto se aplica en particular a los protocolos de
comunicación que se usan: dependiendo de las características que proporcione un
protocolo, la construcción de algún tipo de sistema distribuido sobre él puede
ser mucho más fácil.
Desde
un punto de vista histórico, las primeras primitivas de comunicación y los
primeros protocolos que se usaron para el intercambio de información
interproceso proporcionaban paso de mensajes entre dos procesos (comunicación
uno a uno), con diferentes calidades de servicio (QoS). La transmisión
orientada a conexión, FIFO y fiable y la no fiable orientada a datagramas son
las QoS más habituales en este caso, y ambas especifican el comportamiento en
caso de fallos de comunicación. Más adelante, con la adopción del modelo
cliente-servidor, se desarrollaron protocolos uno a uno optimizados para la
interacción con RPCs, especificando alguna QoS en caso de fallos de proceso
(semánticas al menos una vez o como mucho una vez).
Pero
cuando comenzaron a considerarse aplicaciones tolerantes a fallos, replicadas y
de tipo difusión, se reconoció la importancia de enviar mensajes a un conjunto
de procesos (comunicación uno a varios) como un
paradigma útil. En este escenario, los modelos de fallo útiles son muchos, y
las garantías que son útiles dependen mucho de la aplicación. Como las QoS más
estrictas son costosas, el diseñador está interesado normalmente en usar el
protocolo más barato posible, entre los que garanticen la QoS que requiera la
aplicación.
En
este capítulo se ofrece una descripción general de estos conceptos, con la
intención de centrar los problemas, las soluciones y las cuestiones abiertas
más habituales en el campo donde se sitúa esta tesis. Esta descripción comienza
presentando el concepto mismo de sistema distribuido (sección 2.1).
Más adelante, en la sección 2.2,
se introducen los modelos más habituales de computación distribuida, para poner
en perspectiva los problemas y las soluciones que se analizarán a lo largo de
esta tesis. En la sección 2.3
se detallan los conceptos específicos relacionados con los grupos de procesos
replicados, que son de gran importancia para el resto de esta exposición, ya
que los grupos replicados son uno de los paradigmas más habituales en la
computación distribuida tolerante a fallos. El capítulo termina con tres
secciones dedicadas más específicamente a temas relacionados con los sistemas
de comunicación: 2.4 se
dedica a la comunicación uno a uno en general (incluyendo diferentes semánticas
multienvío y QoS), 2.5 a
aproximaciones modulares para la construcción de protocolos (tanto unienvío
como multienvío) y 2.6 a
una descripción breve de algunos sistemas de comunicación.
Sistemas distribuidos
Antes
de analizar asuntos más específicos, vamos a introducir algunos conceptos
genéricos relacionados con los sistemas distribuidos.
Qué
es un sistema distribuido
Una de
las primeras caracterizaciones de un sistema distribuido fue realizada por
Enslow, ya en 1978 [Ens78],
que le atribuye las siguientes propiedades:
- Está compuesto por varios
recursos informáticos de propósito general, tanto físicos como
lógicos, que pueden asignarse dinámicamente a tareas concretas.
- Estos recursos están distribuidos
físicamente, y funcionan gracias a una red de comunicaciones.
- Hay un sistema operativo de
alto nivel, que unifica e integra el control de los componentes.
- El hecho de la distribución es transparente,
permitiendo que los servicios puedan ser solicitados especificando
simplemente su nombre (no su localización).
- El funcionamiento de los recursos
físicos y lógicos está caracterizado por una autonomía coordinada.
A
pesar del tiempo transcurrido, esta definición sigue siendo, en esencia,
válida. Así, para Coulouris [CDK94]
un sistema distribuido es aquél que está compuesto por varios ordenadores
autónomos conectados mediante una red de comunicaciones y equipados con
programas que les permitan coordinar sus actividades y compartir recursos. Bal
ofrece una definición muy similar [Bal90]:
``Un sistema de computación distribuida está compuesto por varios procesadores
autónomos que no comparten memoria principal, pero cooperan mediante el paso de
mensajes sobre una red de comunicaciones''. Y según Schroeder [Sch93],
todo sistema distribuido tiene tres características básicas:
- Existencia de varios ordenadores. En
general, cada uno con su propio procesador, memoria local, subsistema de
entrada/salida y quizás incluso memoria persistente.
- Interconexión. Existen vías que
permiten la comunicación entre los ordenadores, a través de las cuales
pueden transmitir información.
- Estado compartido. Los ordenadores
cooperan para mantener algún tipo de estado compartido. Dicho de otra
forma, puede describirse el funcionamiento correcto del sistema como el
mantenimiento de una serie de invariantes globales que requiere la
coordinación de varios ordenadores.
En cuanto
a los campos de aplicación, podemos distinguir por un lado aquellos donde la
distribución es fundamentalmente un medio para conseguir un fin y por otro
aquellos donde es un problema en sí misma [SC91].
Con respecto a los primeros, el uso de soluciones distribuidas sirve para
acercarse a las siguientes metas:
- Computación masivamente paralela,
de propósito general y de alta velocidad.
- Tolerancia a fallos (confianza,
disponibilidad).
- Respuesta a demandas con requisitos
de tiempo real.
En
los segundos, son los propios requisitos de la aplicación los que fuerzan a
evolucionar hacia soluciones distribuidas:
- Bases de datos distribuidas. Es
necesario acceder a los datos desde lugares geográficamente dispersos, y
además puede ser conveniente (e incluso imprescindible) almacenarlos
también en varios lugares diferentes.
- Fabricación automatizada. Es
necesaria la colaboración de muchos procesadores para coordinar las tareas
en una factoría.
- Supervisión remota y control. Los
sensores, los actuadores y los nodos donde se toman las decisiones de
control pueden estar en diferentes partes de un sistema distribuido.
- Toma de decisiones coordinada. Hay
muchas aplicaciones donde es necesario que varios procesadores participen
en la toma de decisiones, por ejemplo, porque cada uno de ellos tiene una
parte de los datos relevantes.
Principales problemas y áreas de investigación
Cuando se construye cualquier tipo de sistema distribuido
hay varios problemas que deben ser resueltos. Estos problemas son fundamentales
porque están presentes en cualquier sistema de este tipo, por su propia
naturaleza. De hecho, algunos autores deciden incluso si un sistema es ``más o
menos distribuido'' según el grado en que los presenta (y hablan entonces de síntomas
de distribución [Mul93b]).
Los más relevantes son los siguientes [Sch93]:
- Fallo independiente. Puede ocurrir
que parte de los ordenadores que componen el sistema dejen de funcionar, y
sin embargo el resto continúe correctamente. En este caso, habitualmente
se quiere que el sistema continúe prestando servicio, aunque quizás de
forma reducida.
- Comunicación no fiable. Las redes
que conectan los ordenadores no están, en general, exentas de errores. Es
muy habitual que los datos transmitidos se pierdan, se corrompan o se
repitan por problemas de la red. El sistema distribuido ha de estar
diseñado de forma que tolere estas situaciones.
- Comunicación insegura. En general,
los datos que se transmiten por la red pueden ser observados sin
autorización, o incluso modificados intencionadamente.
- Alto coste de la comunicación. En
la mayor parte de los casos la interconexión entre los ordenadores
proporciona menos ancho de banda y más latencia que sus buses de
comunicación internos.
Los
campos donde se concentra la investigación en sistemas distribuidos suelen
estar, bien relacionados con estos problemas, o bien con los dominios de
aplicación donde se pretende usar la distribución. También hay campos donde
temas ``tradicionalmente'' resueltos cobran nueva vida al intentar extenderlos
con soluciones distribuidas (por ejemplo, los servicios de nombrado de un
sistema operativo o los planificadores de procesos) . A continuación se ofrece
una lista, extensa pero por supuesto no exhaustiva, de las áreas más activas en
el ámbito de los sistemas distribuidos en los últimos años, construida a partir
de la ofrecida en [Sta94]:
redes de área local y extensa, sistemas operativos distribuidos, bases de datos
distribuidas, servidores de ficheros distribuidos, lenguajes de programación
concurrentes y distribuidos, lenguajes de especificación para sistemas
concurrentes, teoría de algoritmos paralelos, teoría de computación
distribuida, arquitecturas paralelas y estructuras de interconexión, sistemas
ultraconfiables y tolerantes a fallos, sistemas distribuidos de tiempo real,
técnicas de resolución cooperativa de problemas, depuración distribuida,
simulación distribuida, aplicaciones distribuidas y metodologías para el
diseño, construcción y mantenimiento de sistemas distribuidos grandes y
complejos, y herramientas de trabajo cooperativo.
Técnicas más habituales
Aunque los
dominios de aplicación de los sistemas distribuidos son muchos, hay una serie
de problemas comunes a todos ellos. Precisamente la recurrencia de estos
problemas es lo que hace que sistemas en principio muy diferentes (como por
ejemplo, bases de datos distribuidas o sistemas de encaminamiento en redes)
puedan tratarse, al menos parcialmente, de forma similar. Para resolverlos se
han ido desarrollando en los últimos años unas técnicas que componen hasta
cierto punto el ``corpus teórico'' en el que se apoya la investigación sobre
sistemas distribuidos. Para ver cuáles son éstas, basta con consultar el índice
de cualquiera de los textos clásicos sobre el tema ([CDK94,Mul93a,CS94b,Tan95]).
La siguiente lista incluye los más habituales:
- Comunicaciones ``uno a varios''
(multienvíos u omnienvíos, en el caso de ser ``uno a todos''). Cuando se
trata de comunicar varios procesos entre sí, las ``tradicionales''
comunicaciones punto a punto ofrecen una funcionalidad demasiado básica, y
por ello es necesario construir protocolos más complejos. Esto puede
ocurrir por las propias necesidades de las aplicaciones (por ejemplo,
teleconferencia sobre red de área extensa), o para aprovechar mejor la
infraestructura de comunicaciones (que en muchos casos proporciona
mecanismos de multienvío poco costosos, por ejemplo, omnienvío en
Ethernet).
- Replicación. Utilizada
fundamentalmente para conseguir fiabilidad y disponibilidad. Muy
importante cuando el sistema ha de ser de confianza.
- Consenso distribuido. Muy útil
siempre que hay un conjunto de procesos que han de tomar una decisión
coordinada (por ejemplo, para sincronizar relojes o para comprometer una
transacción atómica).
- Sincronización de relojes.
Especialmente necesaria en sistemas distribuidos de tiempo real. En muchos
casos no se necesita una sincronización ``real'', y basta con una
``lógica'' (por ejemplo, la lograda mediante relojes lógicos de Lamport [Lam78]
o vectores de tiempo [Mat89,Fid89,Fid94]).
- Cálculo de instantáneas (o panorámicas
de un sistema). Necesaria siempre que un proceso quiere tener una
percepción de alguna parte del estado del sistema distribuido, sobre la
que la información está repartida. Una vez percibida esa información,
pueden comprobarse propiedades de ese estado, que sirvan para tomar
decisiones (por ejemplo, estimaciones de la afiliación de un grupo de
procesos), o detectar propiedades del sistema (terminación, interbloqueos,
etc.).
- Técnicas de nombrado global. El
primer requisito para lograr disponibilidad de recursos remotos es poder
nombrarlos. Casi cualquier solución en sistemas distribuidos requiere de
la existencia de un servicio de nombrado global para sus elementos.
- Cifrado. Técnica básica para
garantizar desde seguridad en el paso de mensajes hasta autenticación de
un proceso frente a otros.
La
mayor parte de estas técnicas están fuertemente interrelacionadas, y a menudo
se utilizan juntas en los sistemas reales. Por ejemplo, uno de los niveles de
comunicaciones más utilizados proporciona multienvío atómico y causal2.1. Para
conseguirlo se usan habitualmente comunicaciones uno a varios, consenso
distribuido, sincronización lógica de relojes y cálculo de instantáneas
globales.
Modelos de computación
distribuida
Antes de
hablar sobre cualquier aspecto de un sistema, es conveniente definir claramente
qué supuestos hemos realizado sobre él. En otras palabras, cuál es el modelo
del sistema. Según [HT93],
los parámetros que determinan un modelo de sistema distribuido son los
siguientes:
- Sincronización de procesos y
comunicaciones (sistema síncrono o asíncrono).
- Semánticas de fallos de procesos.
- Semánticas de fallos de
comunicaciones.
- Topología de la red.
- Grado de determinismo de los
procesos.
Esta
caracterización, aunque será la utilizada de aquí en adelante, no es en
absoluto la única propuesta. Entre otras, cabe destacar la propuesta en [Jal94].
Según ella, un sistema distribuido puede considerarse a dos niveles:
- Nivel físico. El sistema está
compuesto por un grupo de ordenadores geográficamente dispersos,
conectados por una red de comunicaciones. La red de comunicaciones puede
ser de muchos tipos, atendiendo a su topología, capacidad, retardo
impuesto a los datos, etc.
- Nivel lógico. El sistema está
compuesto por un conjunto finito de procesos y canales que los comunican.
Caracterizando tanto los procesos como los canales se definiría el modelo
a este nivel.
A
continuación, retomamos los parámetros propuestos en [HT93],
y pasamos a estudiarlos con cierto detalle.
Sincronización
Las propiedades de sincronía se
definen no sólo sobre los protocolos de comunicación que usa un sistema, sino
también sobre las características de los procesos que trabajan en él. En
sentido estricto, se dice que un sistema es síncrono si [HT93]:
- El retardo de transmisión de los
mensajes (entre emisor y receptor) está acotado.
- Cada proceso dispone de un reloj
cuya deriva respecto al tiempo global de referencia está acotada.
- Existe un límite superior y otro inferior
en el tiempo que tarda en ejecutarse una instrucción en cada proceso.
Los
sistemas síncronos son muy útiles porque permiten usar plazos para
detectar fallos. Como en estos sistemas el retardo de un mensaje, en ausencia
de fallos, está acotado, basta con que se detecte un retraso para que el
receptor suponga que algo ha ido mal en el emisor o en el sistema de
comunicaciones. Además, en estos sistemas, incluso en presencia de fallos, los
relojes de los procesos pueden mantenerse sincronizados, de forma que la deriva
entre dos de ellos cualesquiera esté acotada [LMS85].
De estos relojes se dice que están sincronizados aproximadamente, y son
muy útiles para diseñar protocolos de comunicaciones. Para ciertas aplicaciones
esta propiedad es imprescindible (por ejemplo, sistemas de control con
requisitos de tiempo real).
Para
muchos problemas es posible simular, a partir de relojes sincronizados aproximadamente,
otros sincronizados perfectamente (con deriva cero). Con ellos se simplifica
mucho el diseño de algoritmos distribuidos.
Por otra
parte, en un sistema asíncrono no se puede hacer ninguna suposición
sobre el comportamiento temporal del sistema (retardos de mensajes, deriva de
relojes, etc.). Este modelo es atractivo por su sencillez, y porque las
soluciones que se encuentren para él serán válidas en prácticamente cualquier
sistema. Además, en el mundo real, raramente es posible encontrar un sistema
que se comporte siempre como sistema síncrono. Es habitual que, por el
contrario, cargas inesperadas o puntuales conviertan un sistema en asíncrono,
al menos en esos momentos. Sin embargo, las soluciones para sistemas asíncronos
son también, habitualmente, más complejas, y a veces incluso no existen (por
ejemplo, en ellos es imposible resolver el problema del consenso en presencia
de fallos [FLP85]).
Por
supuesto, el modelo síncrono y el asíncrono son los dos extremos de un amplio
espectro. Otros modelos intermedios pueden ser también de interés. Por ejemplo,
aquél donde los procesos tiene velocidades acotadas y relojes sincronizados perfectamente
pero los retardos de los mensajes no están acotados [DDS87].
Fallos de procesos
Un
proceso falla en su ejecución si se desvía de lo que prescribe el
algoritmo que está ejecutando. En caso contrario, el proceso es correcto.
El modelo de fallo especifica de qué formas puede un proceso desviarse del
funcionamiento correcto. Según [CASD85],
los modelos de fallo que se suelen considerar son los siguientes:
- Caída. El proceso se comporta
correctamente hasta que falla. A partir de ese momento, no hace nada. Un
fallo similar, con semántica más fuerte, es el de
fallo parada [SS83,Sch84].
En este caso, cuando un proceso cae, todos los procesos correctos son
informados del fallo (o pasa a un estado que permite que los demás lo
detecten) y además tienen acceso a toda la información que guardaba el
proceso antes de fallar.
- Omisión. El proceso falla al no
recibir o no enviar mensajes esporádicamente, o por caída, o por ambas
razones. Algunos autores (p. ej. [HT93])
diferencian también la omisión de envío y omisión de recepción como tipos
más especiales de fallo.
- Fallo bizantino (también llamado
arbitrario o malicioso). El proceso puede exhibir cualquier comportamiento
(incluyendo cambios arbitrarios de estado).
Figura 2.1: Diagrama que muestra
algunos modelos de fallo de procesos, y las relaciones de inclusión entre
ellos.
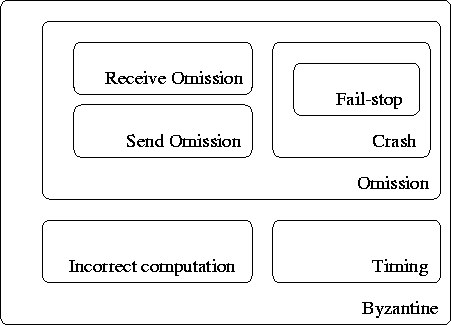
Estos
tipos de fallos representan diferentes niveles de ``severidad''. El más leve es
el de caída, y el más severo, y que incluye a todos los demás, el bizantino.
Por otra
parte, nada se ha dicho sobre los fallos que afectan al tiempo. Estos sólo son
de interés en sistemas síncronos, y habitualmente consisten, bien en derivas de
los relojes más grandes que las permitidas, o bien en violaciones de los plazos
en los que un proceso ejecuta un paso. Si incluimos estos fallos en la
clasificación anterior, podemos considerarlos más severos que los fallos de
omisión, pero menos que los bizantinos. La relación entre los cuatro tipos de
fallos (incluidos los de tiempo) es estudiada en [CAS86].
Puede
incluirse aún otro tipo de fallo, el debido a una computación incorrecta [Jal94].
Este es un subconjunto del tipo bizantino, pero que no implica fallo de tiempo,
sino que simplemente produce una salida incorrecta en respuesta a una entrada
dada.
En la
figura 2.1
se muestra un diagrama con las relaciones entre todos estos tipos de fallos.
Fallos de comunicación
Los tipos
de fallos que afectan al sistema de comunicaciones pueden clasificarse de una
forma muy similar a la utilizada para los procesos [HT93]:
- Caída. El enlace que falla se
comporta correctamente hasta que falla. En ese momento, deja de transmitir
mensajes.
- Omisión. El enlace pierde esporádicamente
mensajes enviados a través de él.
- Fallo bizantino. Puede exhibir
cualquier comportamiento, como cambiar el contenido de los mensajes o
generar mensajes espúreos.
Igual
que en el caso anterior, si consideramos sistemas síncronos, tenemos también la
posibilidad de fallos temporales (mensajes transmitidos más rápido o más
despacio que lo especificado).
Topología de la red
En
general, una red de comunicaciones puede ser modelada como un grafo. Estudiando
el grafo se deducen propiedades interesantes como, por ejemplo, si es posible
que se produzcan particiones2.2. En muchos
casos, el comportamiento de un algoritmo estará influenciado por la topología
de la red.
Grado de determinismo de los procesos
Un
proceso puede modelarse como un autómata, de número de estados quizás infinito.
Si es determinista, basta con conocer la relación de transiciones de estado
para determinar el estado resultante de la ejecución de un paso cualquiera de
su computación. Sin embargo, si el proceso tiene un comportamiento no
determinista, la ejecución de un paso dado puede resultar en uno cualquiera de
varios estados posibles. En este caso la transición a cada uno de éstos suele
llevar asociada una función de probabilidad.
Notas al pie
Una partición de red tiene lugar cuando
los nodos (máquinas) de una red se dividen en al menos dos conjuntos, con
máquinas que son capaces de comunicarse sólo con otras máquinas de su conjunto.