As previously mentioned, the compression algorithm is linear with respect to the size of the input. COMPRESS requires the helper function ENCODE. Let's look at ENCODE first.
ENCODE has two loop structures: the while loop at line 7, and the while loop at line 21. There are no other loop constructs in ENCODE. Both while loops do a constant amount of work, so the function ENCODE itself does a constant amount of work. Let's now examine COMPRESS.
In COMPRESS, the for loops at lines 2 and 4 do a linear amount of
work, or ![]() work. The while loop at line 14, the for loop at line 27,
and the while loop at line 32, all do a constant amount of work.
COMPRESS calls ENCODE on line 21, but remember ENCODE
itself does a constant amount of work. Therefore,
COMPRESS is linear or does a linear amount of work to compress
input data. If
work. The while loop at line 14, the for loop at line 27,
and the while loop at line 32, all do a constant amount of work.
COMPRESS calls ENCODE on line 21, but remember ENCODE
itself does a constant amount of work. Therefore,
COMPRESS is linear or does a linear amount of work to compress
input data. If ![]() is the linear size of the input, COMPRESS requires
time on the order of
is the linear size of the input, COMPRESS requires
time on the order of ![]() to compress input data.
to compress input data.
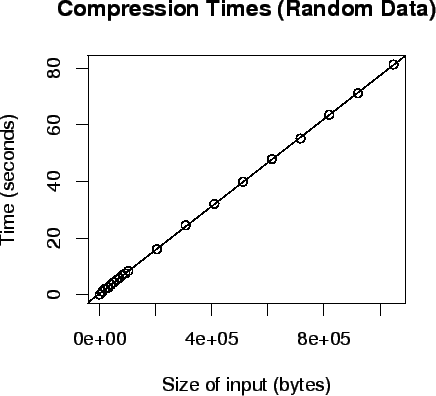
Figure 5 plots the time it takes to generate random data, and then compress
it. The open circles in the plot represent real data to which the plotted
line was fit. If the x-axis or the size of the input is ![]() , and if the y-axis
or time measured in seconds is
, and if the y-axis
or time measured in seconds is ![]() , then the equation of the line fitted
to the real data is approximately:
, then the equation of the line fitted
to the real data is approximately:
In other words, in the generation and compression of random data, the compression algorithm has overhead of approximately 0.3867179 seconds, and it takes approximately 0.00007705963 seconds to compress each byte in the random data.