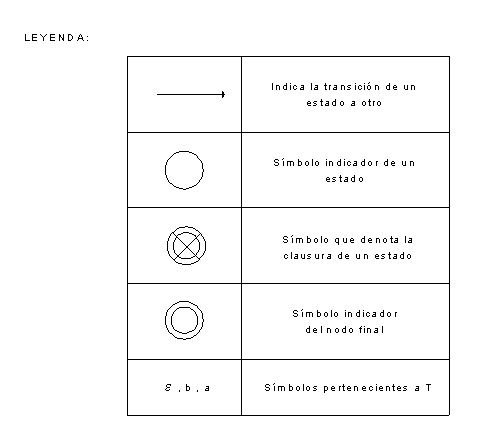
·
Alfabeto T
·
Definición Intuitiva de T*
Operaciones sobre T*
·
Definición Precisa de T*
·
Definición del Lenguaje L sobre un
alfabeto T
·
Operaciones Sobre L
·
Expresiones Regulares
·
Axiomas sobre Expresiones Regulares (ER)
·
Grafo Asociado a una Expresión Regular
·
Representación del Grafo Asociado a una Expresión
Regular como un Autómata
Finito
no Determinístico (AFND)
·
Función de Reconocimiento de un AFND
·
Definición de AFD (Autómata Finito
Determinístico)
·
Función de Reconocimiento
de un AFD
Puntos de Interés a Investigar
·
AFD Parcialmente Especificado
·
AFD Completamente Especificado
·
K-Indistingibles
·
Algoritmo de Minimización de un
AFD
·
Reconocimiento del mismo lenguaje
por el AFD y por el AFD mínimo equivalente
·
Teorema de Unicidad
·
Demostración: Para un Autómata de
k estados, se necesitan a lo más k-2 pasos
para obtener el autómata mínimo asociado
·
Lema de Bombeo (Pumping Lemma)
·
Otra Visión de los AFD y de los AFND
·
Lenguajes Regulares
·
Gramáticas Libres de Contexto
·
Definición General de Gramática
Regular Lineal a la Derecha
·
Lenguaje Generado por una Gramática G
(L(G))
·
Substituciones (Derivaciones)
·
Tipificación de las Gramáticas (Chomsky)
·
Autómatas de Pila
·
Definición de Autómatas
de Pila
·
Definición de Gramática Extendida
·
Definición de Autómatas
de Pila de Items de G
·
Autómatas de Pila con salida
·
Definición de Gramática LL(k)
·
Definición de Gramática LR(k)
·
Teorema
·
Operaciones de un Reconocedor Shift Reduce
·
Introducción a las GramáticasSLR(1)
·
Definición de Gramática SLR(1)
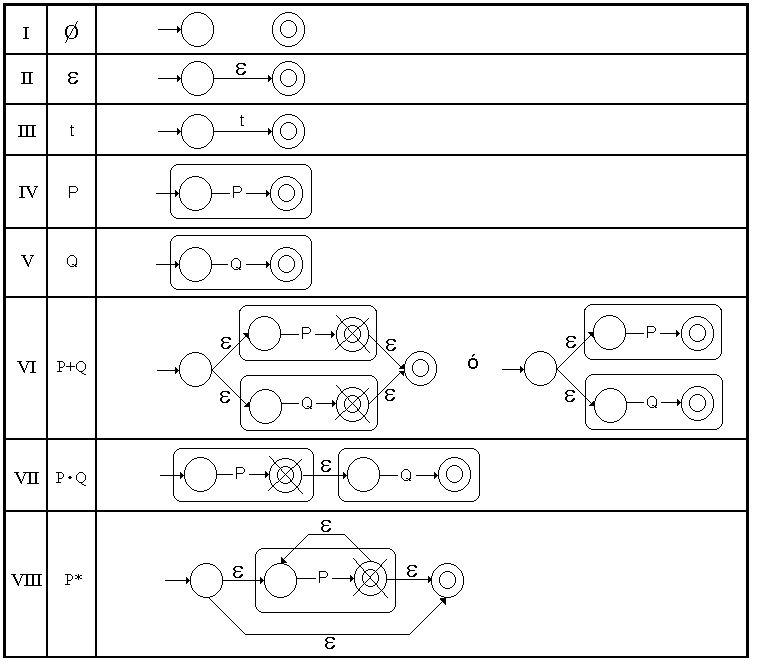
Por lo tanto, sea T* = (T, · , e ) y supongamos que x,y,z Î T entonces se cumple que:
(x · y) · z = x · (y · z) (Asociatividad)
x · e = e · x = x (Elemento Identidad)
T* se define como el conjunto de todas las secuencias finitas de elementos de T.
·
Longitud:
long: T* ® Nat
long: cantidad de símbolos que tiene un elemento de T*
·
La cadena nula se define como:
long ( e ) = 0, (
" x ) ( x Î
T* => x · e
= e · x = x)
·
Ejemplo: long ( ty ) = 1 + long ( y )
· L1 · L2 = { x·y | (x Î L1 Ù y Î L2) }
· Lº = { e }
·![]()
·![]()
· ( a
+ b ) + g = a + ( b + g )
· ( a
· b ) · g
= a · ( b ·
g )
· a ·
( b + g ) = ( a · b ) + ( a ·
g )
· ( a + b ) ·
g = ( a · g ) + ( b ·
g )
· a + b = b + a
· a + a = a
· Æ + a = a + Æ = a
· Æ ·
a = a · Æ = Æ
· e ·
a = a · e = a
· e + ( a
· a* ) = a*
· ( e + a
)* = a*
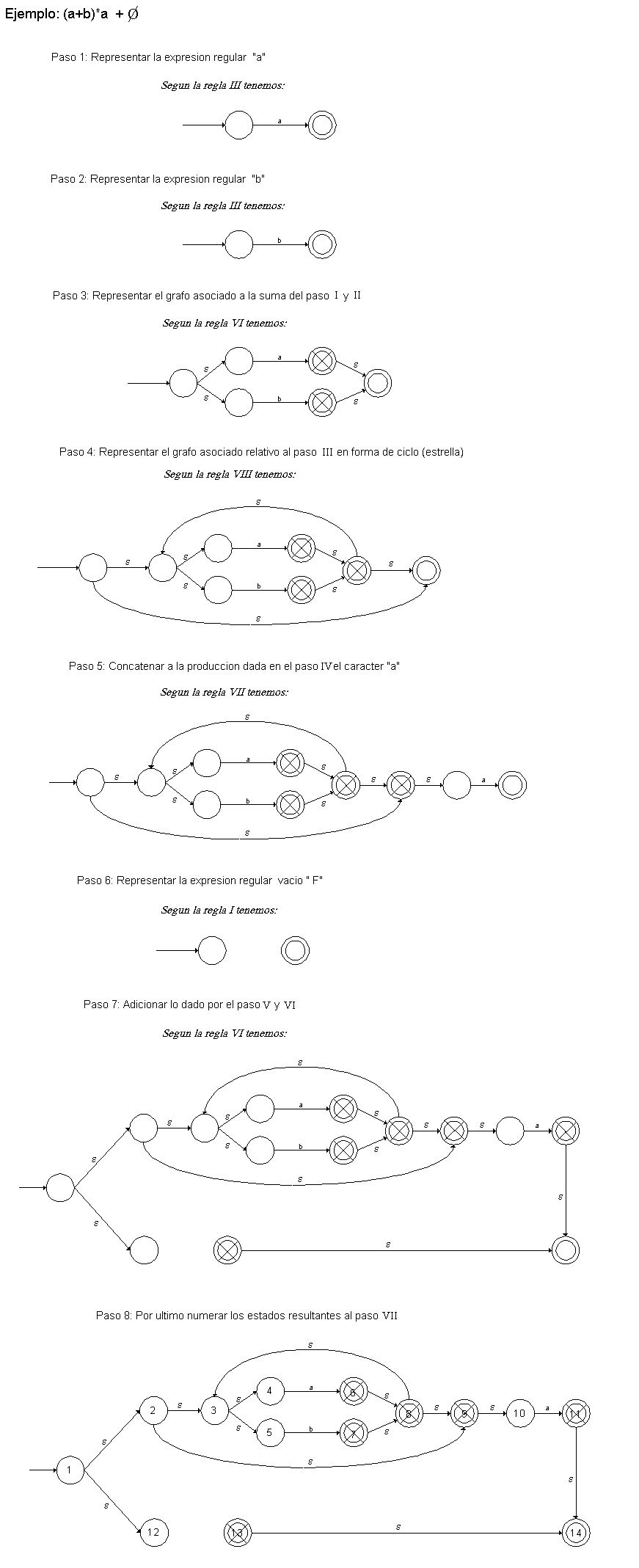
·
Un AFN se define como A = (Q,T,d,S,F) donde:
o Q es el conjunto Finito de Estados
o T es el Alfabeto
o S Î Q, S es el Estado Inicial
o F Í Q, Q es el conjunto de Estados
Finales
o d Es el conjunto finito de Transiciones
entre Estados
d: Q ´ (T È
{ e }) ® Ã(Q)
·
Ejemplo: AFND = (Q,T,d,S,F) donde:
o
Q = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 13, 14}
o
T = { a , b }
o
S = 1
o
F = { 14 }
o d
= { < 1, e , 2 >, < 1,
e , 12 >, < 2, e
, 3 >, < 2, e ,
9 >, < 3, e , 4 >, < 3,
e , 5 >, < 4, a,6 >, <
5, b , 7 >,
< 6, e , 8 >, < 7,
e
, 8 >, < 8, e ,
3 >, < 8, e , 9 >, < 9,
e ,10 >, < 10, a,11 >, <
11, e ,14 >, < 13,
e
,14> }
Observación:
La cadena de caracteres "aba"
![]()
Se reconoce a la cadena "aba" ya que el conjunto de
estados intersectados con el conjunto de estados finales
es diferente al vacío. Nótese que para "ab"
no sucede.
![]() (Q,w) = Æ
( I )
(Q,w) = Æ
( I )
![]() (P, e)
= P
( II )
(P, e)
= P
( II )
![]() (P, t.w) =
(P, t.w) = ![]() (d´´(P,t), w)
( III )
(d´´(P,t), w)
( III )
donde
d´´:
Ã(Q) ´ T
® Ã(Q)
d´´:
(Q,w) = Æ
( IV )
d´´(P,t)
= e ´(d´(P,t))
( V )
donde
d´: Ã
(Q) ´ T ® Ã
(Q)
d´(Æ,t)
= Æ
( VI )
d´(P,t) = Èd(q,t)
( VII )
q Î p
y
e´: Ã(Q)
® Ã(Q)
e´(P) =
È
e( q )
( VIII )
q Î p
donde:
e:
Q ® Ã(Q)
se define como:
t Î e( t )
x Î e( t ) Ù
z Î d( x, e
) ® z
Î e( t )
tendremos que:
x Î L Û ![]() ( e( S ), x )
Ç
F ¹ Æ
( e( S ), x )
Ç
F ¹ Æ
Esta última fórmula se determina rápidamente por medio del teorema de inducción:
- Cláusula base: Si es cierta la formulación anterior debe cumplirse
tanto para el lenguaje vacío como con los
elementos "t" y "e"
L = Æ
(" x) x Î
L Û ![]() (
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
se tiene que:
(
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
se tiene que:
(" x) L = Æ Û ![]() (
e( S ), x ) Ç
F = Æ
(
e( S ), x ) Ç
F = Æ
S = 1 y F = { 2 }
Ahora, se sabe que el dominio de ![]() :
Ã(Q) x T* ®Ã(Q),
por lo que x Î T*.
:
Ã(Q) x T* ®Ã(Q),
por lo que x Î T*.
Y si x Î T*, entonces "x" puede ser
e
ó
de la forma yt.
Para x = e
(" x) L = Æ Û ![]() (
e( S ), x ) Ç
F = Æ (Sustituyendo el valor
de x en la fórmula)
(
e( S ), x ) Ç
F = Æ (Sustituyendo el valor
de x en la fórmula)
(" x) L = Æ Û ![]() (
e( S ), e
) Ç F =
Æ (Aplicando la fórmula II)
(
e( S ), e
) Ç F =
Æ (Aplicando la fórmula II)
(" x) L = Æ Û
e(
S ) Ç F =
Æ
(Sustituyendo el valor de S y F)
(" x) L = Æ Û
e(
1 ) Ç { 2
} = Æ
(Viendo el autómata obtenemos la clausura)
(" x) L = Æ Û
{
1 } Ç { 2
} = Æ
(Aplicando la intersección de los dos elementos)
(" x) L = Æ Û
Æ
Para x = yt
(" x) L = Æ Û ![]() (
e( S ), x ) Ç
F = Æ (Sustituyendo el valor
de x en la fórmula)
(
e( S ), x ) Ç
F = Æ (Sustituyendo el valor
de x en la fórmula)
(" x) L = Æ Û ![]() (
e( S ), yt )
Ç
F = Æ
(
e( S ), yt )
Ç
F = Æ
Debido a que yt Î T*, vemos el autómata y se sabe que para "y" no esta definida, por lo tanto
![]() (
e( S ), yt ) = Æ
(
e( S ), yt ) = Æ
(" x) L = Æ Û Æ
Ç F =
Æ
(Aplicando la intersección de los dos elementos)
(" x) L = Æ Û Æ
Con ello podemos argumentar que para todo x ÎL,
si ese lenguaje L = Æ, pues tan solo el
autómata podrá
reconocer a este mismo (elemento vacío).
L = { e }
(" x) x Î
L Û ![]() (
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
tenemos que:
(
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
tenemos que:
(" x) L = { e
} Û ![]() (
e( S ), x ) Ç
F ¹ Æ
(
e( S ), x ) Ç
F ¹ Æ
S = 1 y F = { 2 }
Ahora, se sabe que el dominio de ![]() :
Ã(Q) x T* ®Ã(Q),
por lo que x Î T*.
:
Ã(Q) x T* ®Ã(Q),
por lo que x Î T*.
Y si x Î T*, entonces "x" puede ser
e
ó
de la forma yt.
Para x = e
(" x) L = { e
} Û ![]() (
e( S ), x ) Ç
F ¹ Æ (Sustituyendo
el valor de x en la fórmula)
(
e( S ), x ) Ç
F ¹ Æ (Sustituyendo
el valor de x en la fórmula)
(" x) L = { e
} Û ![]() (
e( S ), e
) Ç F ¹
Æ (Aplicando la fórmula II)
(
e( S ), e
) Ç F ¹
Æ (Aplicando la fórmula II)
(" x) L = { e
} Û e( S )
Ç
F ¹ Æ
(Sustituyendo el valor de S y F)
(" x) L = { e
} Û e( 1 )
Ç
{ 2 } ¹ Æ
(Viendo el autómata obtenemos la clausura)
(" x) L = { e
} Û { 2 } Ç
{ 2 } ¹ Æ
(Aplicando la intersección de los dos elementos)
(" x) L = { e
} Û { 2 }¹ Æ
Para x = yt
(" x) L = { e
} Û ![]() (
e( S ), x ) Ç
F ¹ Æ (Sustituyendo
el valor de x en la fórmula)
(
e( S ), x ) Ç
F ¹ Æ (Sustituyendo
el valor de x en la fórmula)
(" x) L = { e
} Û ![]() (
e( S ), yt )
Ç
F ¹ Æ
(
e( S ), yt )
Ç
F ¹ Æ
Debido a que yt Î T*, vemos el autómata y sabemos
que para "y" no esta definida, por lo tanto
![]() ( e(
S ), yt ) = Æ
( e(
S ), yt ) = Æ
(" x) L = { e
} Û Æ Ç
F ¹ Æ
(Aplicando la intersección de los dos elementos)
(" x) L = { e
} Û Æ
Con ello decimos que para cualquier x ÎL,
si ese lenguaje L = { e
}, pues no podrá reconocer a un string
de la forma yt sino unicamente reconocerá al epsilón.
L = { t }
(" x) x Î
L Û ![]() (
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
tenemos que:
(
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
tenemos que:
(" x) L = { t } Û ![]() (
e( S ), x ) Ç
F ¹ Æ
(
e( S ), x ) Ç
F ¹ Æ
![]()
S = 1 y F = { 2 }
Ahora, sabemos que el dominio de ![]() :
Ã(Q) x T* ®Ã(Q),
por lo que x Î T*.
:
Ã(Q) x T* ®Ã(Q),
por lo que x Î T*.
Y si x Î T*, entonces "x" puede ser
e
ó
de la forma yw.
Para x = e
(" x) L = { t } Û ![]() (
e( S ), x ) Ç
F ¹ Æ (Sustituyendo
el valor de x en la fórmula)
(
e( S ), x ) Ç
F ¹ Æ (Sustituyendo
el valor de x en la fórmula)
(" x) L = { t } Û ![]() (
e( S ), e
) Ç F ¹
Æ (Aplicando la fórmula II)
(
e( S ), e
) Ç F ¹
Æ (Aplicando la fórmula II)
(" x) L = { t } Û
e(
S ) Ç F ¹
Æ
(Sustituyendo el valor de S y F)
(" x) L = { t } Û
e(
1 ) Ç { 2
} ¹ Æ
(Viendo el autómata se obtiene la clausura)
(" x) L = { t } Û
{
1 } Ç { 2
} ¹ Æ
(Aplicando la intersección de los dos elementos)
(" x) L = { t } Û
Æ
Para x = yw
(" x) L = { t } Û ![]() (
e( S ), x ) Ç
F = Æ (Sustituyendo el valor
de x en la fórmula)
(
e( S ), x ) Ç
F = Æ (Sustituyendo el valor
de x en la fórmula)
(" x) L = { t } Û ![]() (
e( S ), yw )
Ç
F = Æ (Aplicando la fórmula III)
(
e( S ), yw )
Ç
F = Æ (Aplicando la fórmula III)
(" x) L = { t } Û ![]() (d´´(
e( S ), y), w )
Ç
F = Æ
(d´´(
e( S ), y), w )
Ç
F = Æ
Debido a que d´´ está definida
en: Ã(Q) ´ T
® Ã(Q), entonces y Î
T con w Î T*.
Por ende, viendo el autómata se tiene que los únicos valores que pueden
tener "y" y "w" son: y=t, w=e
y para otro valor posible que pueda tener yw pues tan solo no será reconocido
por el autómata.
Con ello podemos argumentar que para todo x ÎL,
si ese lenguaje L = { t }, pues tan solo el autómata
podrá a un elemento x = t.
-Hipótesis Inductiva: Supongamos que para un lenguaje Lp y Lq funciona,
por lo tanto, si probamos que con un
string de cardinalidad mayor se cumple, pues se hará válida la
hipotesis de la inducción.
Para ello es necesario demostrar todas las propiedades (+, · , *)
La definición de un x Î Lp es:
(" x) x Î LpÛ p( e( Sp ), x ) Ç Fp ¹ Æ
Y para un y Î Lq es: L = P +
Q
(" x) x Î
L
viendo el autómata se logra obtener una expresión equivalente a la original;
donde
Esto significa que si z=x o z=y, entonces obtengo Fp o Fq que estan contenidos
en el estado final de Fp+q, L = P · Q
("
x) x Î L viendo
el autómata se logra obtener una expresión equivalente a la original;
donde
Esto significa que si z = x · y, entonces podemos partir de la clausura
de Sp con "x" como primer string llego a Fp cuya L =
P*
(" x) x Î
L
donde si z = X
- e
si n = 0
Se ha trabajado con d ´´ y solo con
los subconjuntos de Q que interesan donde se tiene el estadio inicial clausura
del estado inicial anterior (i.e. e ´({1})
= { Por construcción se puede ver que si un lenguaje es reconocido por un AFND,
el mismo lenguaje es reconocido por el AFD construido en base al AFND, esto
es:
Caso Æ: El resultado es el mismo grafo mostrado
en el caso AFND, y se demostró que pertenece a L.
Caso e: Al sacar la clausura queda que el
estado inicial y el final es el mismo, y ese autómata reconoce a e
que pertenece a L.
Caso t: Al sacar la clausura queda el mismo grafo y se demostró anteriormente
que t pertenece a L.
Caso P: Al sacar la clausura queda el mismo grafo y se demostró anteriormente
que P pertenece a L.
Caso Q: análogo al caso P.
Caso P + Q: Al sacar la clausura quedan tres estados, el inicial, y
dos finales que reconocen a P y a Q respectivamente, y se vió que en el caso
P y Q ambos pertenecen a L.
Caso P.Q: Al sacar la clausura quedan tres estados, el estado inicial,
el estado a donde llega P y el estado a donde llega Q (estado final), y se demostró
anteriormente como P.Q pertenece a L.
Caso P*: Al sacar la clausura queda un estado final con un bucle que
reconoce al estado P*
Esto es lo que se llama un AFD y se define como:
T = {a,b} Q = {1,2,3}
S = 1
F = {2}
d = {<<1,a>,2>,<<1,b>,3>,<<2,a>,2>,<<2,b>,3>,<<3,a>,2>,<<3,b>,3>}
Definición Formal de un Autómata Finito
Determinístico (AFD)
Un AFD se define como una 5-tupla A = (Q, T, d
, s, F) donde:
x Î L Û Demostración:
(Þ) Si x Î
L, entonces existe un autómata que lo reconozca, por lo tanto la
función de reconocimiento para esa palabra sobre ese autómata
que lo reconoce llega a un estado final.
(Ü) Si se tiene una función de
transición definida sobre un estado inicial S y una palabra x que
pertenece al conjunto de estados finales, esto quiere decir que el autómata
reconoce a la palabra x por lo cual x Î
L.
Si k es el número de estados del AFND, entonces hay 2k subconjuntos
de estados. Cada subconjunto corresponde a una de las posibilidades que
el AFD debe tomar en cuenta, entonces el AFD simulando el AFND podría
tener 2k estados.
Sea N = (Q, T, d, s, F) un AFND que reconoce
algún lenguaje L. Se construirá un AFD M que reconozca L.
Primero se considera el caso en el cual N no tiene e
, luego se tomará en cuenta.
Construimos M = (Q', T, d', s', F').
La construcción de M obviamente trabaja correctamente. En cada
paso de cálculo de M sobre un input claramente entra a un estado
que corresponde con un subconjunto de estados que N podría tener
en ese punto.
Luego de esta demostración se puede ver que el proceso de transformación
de un AFND a un AFD es finíto, ya que se parte de un conjunto k
de estados del AFD y se llega a un conjunto 2k posibilidades
que debe tomar en cuenta el AFD.
Por ejemplo si se tiene un autómata que reconoce todas las palabras
que terminan en 0
Y tengo las siguientes funciones:
d(a,0) = b
d(b,0) = b y supongo que esta última
no esta definida.
Entonces la palabra 100, 1010, 1000... etc no son reconocidas ya que
la función d es parcial. Sólo
son reconocidas las palabras que tienen n cantidad de 1`s y un 0 al final.
Formalmente:
Si d(q,x) no está definido Þ
d(r,a) = Æ donde q Î
Q y x Î T È{e}
Por lo tanto se tiene que agregar las siguientes definiciones:
d''(Æ, t
) = d(Æ, t)
= Æ
Para mejor entendimieto ofreceremos un ejemplo.
Un autómata finito determinístico o AFD (å
, Q, d , q0,
F) es parcialmente especificado si y sólo si d
es función total.
Un autómata finito determinístico o AFD (å
, Q, d, q0,
F) es completamente especificado si y sólo si
q1 =k q2 «
<q1, q2> Î
Rk « q1
y q2 son k-indistinguibles si y solo si "x
Î å
* long(x) £ k, entonces:
- - SALIDA: M' = (å , Q', d',
q0', F') un AFD que reconoce el mismo lenguaje
que M pero con la menor cantidad de estados posible.
1.- Construir la partición inicial P
: Finales y no Finales (G1=F y G2=Q-F)
Para el caso en que un autómata tenga varios estados finales,
la partición inicial no debe ser estados finales y estados no finales,
ya que cada estado final reconoce palabras distintas, dado que el autómata
es determinístico. Por lo tanto, la partición debe ser estados
no finales y cada estado final debe pertenecer a una partición diferente.
Se va a verificar si el lenguaje reconocido por un AFD es el mismo lenguaje
que el reconocido por su AFD Mínimo equivalente.
d'={ <Gi, a, Gj>
/ <gi, a, gj>}Î
d Ù gi
Î Gi Ù
gj Î Gj}
|Q|=k=2
P :
G1=F, |F|=1
G2=Q-F, |Q-F|=1
Si hay dos estados, uno debe ser el inicial y otro el final, lo que
significa que la partición inicial de cada grupo tiene un elemento
y no se puede seguir subdividiendo, por lo tanto número de paso
requeridos es cero (0).
|Q|=k=3
Si hay tres (3) estados se tienen dos casos: que hayan dos estados finales
y uno no final o que haya un estado final y dos no finales.
Caso1:
P :
G1=F, |F|=2
G2=Q-F, |Q-F|=1
A lo más se puede realizar un paso en el cual se divida G1
en dos subgrupos de un elemento cada uno.
k-2=3-2=1 (se cumple)
Caso2:
P :
G1=F, |F|=1
G2=Q-F, |Q-F|=2
A lo más se puede realizar un paso en el cual se divida G2
en dos subgrupos de un elemento cada uno.
k-2=3-2=1 (se cumple)
Hipótesis Inductiva:
Para un autómata de k estados |Q|=k, se necesitan a lo más
k-2 pasos para obtener el autómata mínimo asociado a éste.
P :
G2=Q-F, |Q-F|=k-t Tesis Inductiva:
P :
G1=F, |F|=p
G2=Q-F, |Q-F|=k+1-p
Por hipótesis inductiva, en el peor de los casos después
de k-2 pasos, se tiene una partición que tenga todos los grupos
de un solo elemento, exceptuando un grupo de dos elementos, si en este
punto es necesario otro paso el único posible será subdividir
el grupo de cardinalidad 2. Lo cual, significa que la minimización
tomó k-2+1 casos, por lo tanto, se cumple para |Q|=k+1.
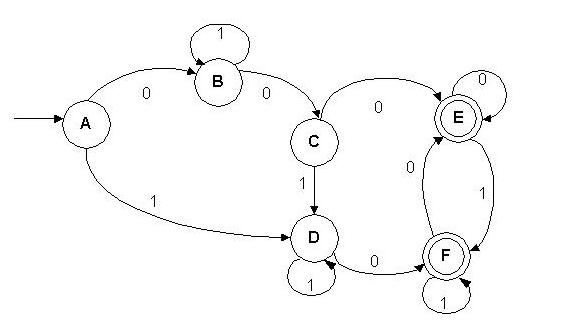
Ejemplo:
Sea el AFD=({0,1}, {A,B,C,D,E,F}, d, A,{E,F})
donde d={<A,0,B>, <A,1,D>, <B,1,B>,
<B,0,C>, <C,0,E>, <C,1,D>, <D,1,D>, <D,0,F>, <E,0,E>,
<E,1,F>, <F,0,E>, <F,1,F>}
Se sabe que se tienen que hacer n-2 pasos, es decir, 6-2=4 pasos hasta
llegar a la "Minimización" de AFD .
Sea la primera partición la siguiente, formada por los estados
no finales (no terminales) y los finales (terminales): (k=0)
Se verán ahora las frases de longitud igual a 1, se verifica
si se llega (S) o no (N)a un estado final, entonces trabajando con a) se
tiene lo siguiente:
Así que el AFD minimizado será el siguiente:
Min(ADF)= ({0,1}, {A,B,C-D,E-F}, dmin, A,{E-F})
("w) [ w Î L y
long(w) ³ |Q| ®
(x,y,z) Si el lenguaje es infinito tiene que haber un elemento estrella en la
Expresión Regular.
q0 ®t1
q1 ®t2
q2 ... ®tn-1
qn-1®tn qn tk ... tk+j
Si la longitud de alguna de las expresiones que forman el lenguaje es
mayor que estados, entonces el Lenguaje es
Sea el AFD A=(Q, T, d , S, F), donde: d
: Q x T ® Q
Se define el conjunto de producciones de la siguiente manera:
P Í Q x ((T.Q) È
{e }) " <<q,
t>, q'>Î d
Þ <q, tq'> Î
P " q Î F Þ
<q, e> Î
P
El alfabeto T, representa los elementos terminales de la gramática,
mientras que el conjunto de estado Q representa los elementos no terminales.
Esto se llama una gramática regular (lineal a la derecha)
y se representa como:
G=(Q, T, P, S) <a , b
> Î P Û
a ® b
Las siguientes proposiciones son equivalentes:
Una gramática libre de contexto (o independiente del contexto)
es una 4-tupla (N, S , P, S) donde
- Notación
Las producciones (A,µ) se denotan A
® µ con
Sea G = (N, T , P, S) una gramática
general regular donde:
Definición:
(d1,d2 P Í D Í
D*
El lenguaje L(G) generado por una gramática se define como:
L(G)={x ½ x "A Î N:
L(S)= L(G)
Para recordar que la derivación es según las producciones de
la gramática G:
L(A)={ x ½ x Î
T* Ù AÞ
G* x }
Sea la gramática G=(N,T,P,S)
Ahora, bien se tienen las siguientes ecuaciones:
Ejemplo:
Sea el autómata A1=({S,A,B},{a,b}, d ,
S, {A,B}), donde d ={<S,a,A>, <S,b,B>,
<A,a,A>, <A,b,B>, <B,b,B>, <B,a,A>} y la gramática asociada G1=({S,A,B}, {a,b}, P1, S)
P1={S ® aA, S ® bB, A ® aA, A ® aB, A ® e, B ® bB, B ® bA, B ® e}
L(S)=a.A+b.B
S=aA + bB
Se sustituye el valor de A en B
Se sustituye el valor de A y el de B en S
Sea G = (N, T , P, S) donde
Tipo 1: (Dependientes del contexto o context Sensitive)
Tipo 2: (Independientes del contexto o context Free) Análisis
Sintáctico
Tipo 3: (Gramáticas Regulares) Análisis Lexicográfico
Autómatas Finitos con control
sobre. Se extiende la función de
movimiento (d )
para que dependa de: Como resultado de realizar un movimiento: Un ADP es una máquina M = ( Q , S , G , d , q0 , Z0 , F ) donde Donde la función de transición d se interpreta: El autómata se puede mover del estado q al estado pi (1 < i < m) al observar a en la entrada y Z en el tope de la pila. En ese caso, El autómata se puede mover del estado q al estado pi (1 < i < m) independientemente de la cinta al observar Z en el tope de la pila. En ese caso,
En todo Autómata de pila se puede definir: Configuración Inicial Se define de la forma (q0 , w) para cualquier w Î S * Configuración Final Se define de la forma (a f, e ) para cualquier a Î Q* y f Î F Movimiento Se define como una relación |¾ al subconjunto de (Q* x S *)x(Q* x S *) t.q (a , w) |¾ (a ', w') ssi a = a 1 a 2
a ' = a 1 a 3
w = aw' (a 2, a, a 3) Î d Para algún a 1 Î Q*, a 2 Î Q*, a 3 Î Q* a Î S * È {e } Ejemplos de un autómata de pila. Sea P1 = ( { 0, 1 } , { E, R, S, C, U, B} , d , E, {R} ) Donde definimos a d como los siguientes movimientos: (E, e , ES) (S, 0, CS) (S, 1, V) (S, e , B) (CB, 0, B) (UB, 1, B) (EB, e , R) ¿La secuencia "00" pertenece al lenguaje reconocido por P1. ? (E, 00) |¾ (ES,00) |¾ (ECS, 0) |¾ (ECCS, e ) |¾ (ECCB , e ) Fallo, el estado final no es válido, es decir, no es una configuración final (E, 00) |¾ (ES,00) |¾ (EB, 00) |¾ (R, 00) Fallo, el estado final no es válido, es decir, no es una configuración final (E, 00) |¾ (ES,00) |¾ (ECS, 0) |¾ (ECB, 0) |¾ (EB , e ) |¾ (R, e ) Reconocido, el estado obtenido es una configuración final. ¿La secuencia "010" pertenece al lenguaje reconocido por P1. ? (E, 010) |¾ (ES,010) |¾ (ECS, 10) |¾ (ECUS, 0) |¾ (ECUB ,0) Fallo, el estado final no es válido, es decir, no es una configuración final. ¿La secuencia "0110" pertenece al lenguaje reconocido por P1. ? (E, 0110) |¾ (ES,0110) |¾ (ECS, 110) |¾ (ECUS, 10) |¾ (ECUB ,10) |¾ (ECB ,0) |¾ (EB , e ) |¾ (R, e ) Reconocido, el estado obtenido es una configuración inicial. Sea G = (N, S ,
P, S), una gramática libre de contexto cualquiera. Se define GRAMATICA EXTENDIDA de G como G' = (N', S , P', S') donde: N'= N È {S'}
con S'Ï N
y P' = P È {S'
® S} Un Item de G es una 3-tupla (A, a , b ) con A ® a b Î P' y se denota como [A ® a .b ] Ejemplo: G = ({S,A}, {0,1,2,3}, P, S) Donde P corresponde a las producciones: S ® 0A1 A ® 2A A ® 3 A ® e Entonces G' = ({S', S, A}, {0,1,2,3}, P, S') Donde P corresponde a las producciones: S'® S S ® 0A1 A ® 2A A ® 3 A ® e Entonces, los items de G son: [S' ®
.S] (No se ha reconocido S) [A ®
.3] [S' ®
S.] (Ya se reconoció S) [A
® 3.]
[S ® .0A1] ..... [A ® .2A]
[S ® 0.A1] [A ® 2.A]
[S ® 0A.1] [A ® 2A.]
[S ® 0A1.] [A ® .] Dada una gramática libre de contexto G = (N, S , P, S) con gramática extendida G' = (N', S , P', S'), el AUTOMATA DE PILA DE ITEMS de G es: Kg = (S ,Itg, D , [ S' |¾ S], F) Donde d se define como { ( [A |¾ a .Bb ] , e , [A |¾ a .Bb ] [B |¾ .g ] ) | A Î N' ; B Î N ; a ,b ,g Î (N È S )* ; A |¾ a Bb Î P' ;
B |¾ g Î P } Transiciones de Expansión à se empilan È "unido" { ( [A |¾ a .xb ] , x , [A |¾ a .xb ] ) | A Î N' ; x Î S ; a ,b Î (N È S )* } Transiciones de Lectura È
"unido" { ( [A |¾ a .Bb ] [B |¾ g .] , e , [A |¾ a B.b ] ) | A Î N' ; B Î N ; a ,b ,g Î (N È S )* ; A |¾ a Bb Î P' ;
B |¾ g Î P } Transiciones de Reducción à se desempilan Ejemplo: Obtener KG1 de: G1 = ({S,A}, {0,1}, P1, S) S'® S
S ® AS
S ® e P1 P1'
A ® 0 Se tiene que los Items de G' son: [S' ® .S]
[S' ® S.]
[S ® .AS]
[S ® A.S]
[S ® AS.]
[S ® .]
[A ® .0]
[A ® 0.] D = {([S' ®
.S], e
, [S' ®
.S] [S ®
.AS]), ([S' ®
.S], e
, [S' ®
.S] [S ®
.]), ([S ®
.AS], e
, [S ®
.AS] [A ®
.0]), ([S ®
A.S], e
, [S ®
A.S] [S ®
.AS]), ([S ®
A.S], e
, [S ®
A.S] [S ®
.]), ([A ®
.0], 0, [A ®
0.]), ([S' ®
.S] [S ®
AS.], e
, [S' ®
S.]), ([S' ®
.S] [S ®
.], e
, [S' ®
S.]), ([S ®
.AS] [A ®
0.], e
, [S ®
AS.]), ([S ®
A.S] [S ®
AS.], e
, [S ®
AS.]), ([S ®
A.S] [S ®
.], e
, [S ®
AS.])} KG1 = ({0, 1}, ITG,
D, S' ®
S, {[S' ®
S]}) ([S' ®
.S], 00) |¾
([S' ®
.S] [S ®
.AS], 00) |¾
([S' ®
.S] [S ®
.AS] [A®
.0], 00) |¾
([S' ®
.S] [S ®
.AS] [A®
0.], 0) |¾
([S' ®
.S] [S ®
A.S], 0) |¾
([S' ®
.S] [S ®
A.S] [S®
.AS], 0) |¾
([S' ®
.S] [S ®
A.S] [S®
.AS] [A®
.0], 0) |¾
([S' ®
.S] [S ®
A.S] [S®
.AS] [A®
0.], e) |¾
([S' ®
.S] [S ®
A.S] [S®
A.S], e) |¾
([S' ®
.S] [S ®
A.S] [S®
A.S] [S®
.], e) |¾
([S' ®
.S] [S ®
A.S] [S®
AS.], e) |¾
([S' ®
.S] [S ®
AS.], e) |¾
([S' ®
S.], e)
Autómata de pila sin salida Autómata de pila con salida M1 = ( Q, S
, d , q0,
F ) d Í
Q+ x (S
È
{e}) x
Q* Configuración Î
Q* x S
* Configuración Inicial: (q0,
w) Configuración Final: (af,
e), con
a Î Q* Ejemplo: Ap sin salida: ({A, B}, {0, 1}, {(A, 0,
AB), (B, 1, e)},
A, {A, B} Frases reconocidas (A, 0) |¾
(AB, e)
0 (A, 1) |¾
X (A, 001) |¾
(AB, 01) |¾
X (A, 01) |¾
(AB, 1) |¾
(A, e)
01
M2 = ( Q, S , G , d , q0, F ) d Í Q+x (S È {e}) x Q* x (G È {e}) Configuración Î Q* x S * x G * Configuración Inicial: (q0, w, e) Configuración Final: (af, e, v), con v Î G * Ejemplo: Ap con salida: ({A, B}, {0, 1}, {x, y}, {(A, 0, AB, e), (B, 1, e, x)}, A, {A, B} Frases reconocidas (A, 0, e) |¾ (AB, e, e) 0
(A, 1, e) |¾ X
(A, 001, e) |¾ (AB, e, 01) |¾ X
(A, 01, e) |¾ (AB, e, 1) |¾ (A, e, x) 01
Para definir que es una gramática LL(k), debemos comenzar hablando
de gramáticas ambíguas.
Una gramática es ambígua si se cumplen las siguientes propiedades:
- L (G) ={ w / w Î T* Ù
S Þ* w}
Esto quiere decir que se puede conseguir más de un árbol
de derivación que exprese la misma gramática.
Para ilustrar la idea de una gramática LL(k), se pudiese ver como
que los nodos terminales son representados
Por ejemplo:
Su representación gráfica (árbol de derivación)
se manipula bajo el concepto de top-down, haciendo que su
Más aún su interpretación es inmediata, para el ejemplo
anterior se diría que siempre una < condicion_if >
Ahora se explicará los conceptos basicos para entender LL(k), nos
enfocaremos para el caso k=1.
- primero (X) = { t | t
Î
T Ù X Þ*
tw para algun w Î
T* }
- siguiente (X) = { t |
t Î T Ù
S Þ* uXtw para algun u,w Î
T* }
- director (A ® X1X2......Xn) =
È
primero
(Xi) È (if seAnula(X1X2...Xn)
then siguiente(A) else Æ)
Una gramática
G es LL(1) Û A ®
a | b son 2 producciones distintas de
G y cumplen las siguientes condiciones:
1. Para a y bÎ
N,
$a
/
se puede derivar en ambos casos un string que comience con "a".
2. Al menos uno entre a y b,
se puede derivar en el string vacío.
3. Si b Þ*
e,
entonces a no deriva en otro string
que comience con un nodo terminal en el siguiente (A).
Para que se cumplan
estas condiciones, se debe tener que:
"
(A ® X1X2.....Xn) (A ®
Y1Y2....Ym)
Û
director (A ®
X1X2....Xn) Ç
director (A ®
Y1Y2......Ym) = Æ
Esto asegura que "A
Î
N se cumplen las condiciones anteriores.
En términos
generales las gramáticas LL(k) implica que se necesitan k elementos
para saber que producciones se debe
Una gramática
con derivación más a la izquierda nunca será fuertemente
LL(k) para ningún valor de k.
Definición
de una gramática fuertemente LL(k): Una gramática G fuertemente
LL(k) con un k>0 fijo, se define
Sea la producción A ® a
y A ® b
en P con el mismo lado izquierdo,al obtener el director de ese conjunto
Definición
de una gramática débil LL(k): Una gramática G
debilmente LL(k) con un k>0 fijo, se define como
Sea la producción A ® a
y A ® b
en P con el mismo lado izquierdo,al obtener el director de ese conjunto
Suponga G=(Vn, Vt, P, S) es una gramática libre de contexto y G=(Vn,
Vt, P, S) la gramática extendida de G obtenida al agregarle a G un
nuevo símbolo S y la producción S® S entonces G es una gramática LR(k) si:
S® aXw
® aBw
S® rYx
® aBy
k:w=k:y entonces
a=r, X=Y y x=y
Suponga S=a0
® a1
® a2
...
® an
= v es una derivación más a la derecha para una gramática
G libre de contexto. G será una gramática LR(k) si para cada derivación
el asa puede ser localizada y si la producción a ser aplicada puede ser
determinada.
Reconocedores predictivos pueden ser descendentes (top-down o LL(k))
o ascendentes (bottom-up o LR(k))
Los reconocedores ascendentes LR construyen el árbol de derivación
comenzando desde las hojas hasta la raíz y en post orden (derivación
más a la derecha).
Un asa (handle) es una subpalabra que corresponde con una parte derecha
de una producción tal que su reemplazo por la parte izquierda correspondiente
representa un paso a través de una derivación más a la
derecha.
Si la gramática no es ambigua entonces existe un asa única
para cada forma sentencial.
[empilar] (shift) el carácter de la entrada se consume y es empilado.
[reducir] (reduce) en el tope de la pila esta es la parte derecha de
un asa, la cual reemplazará por un no terminal para ello: -
se debe conocer cual es la longitud del
asa -
se debe conocer por cual producción
reducirla. El terminal de la
entrada no es consumido. [aceptar] (accept)
El analizador acepta la entrada. [error] (error) El
analizador encontró un error sintáctico Considere la siguiente gramática: G = (N, T, P, E) Con P = { E®E+E
E®E*E
E® (E)
E®id } Derivación
más a la derecha de id + id * id E®E+E
®E+E*E
®E+E*id
®E+id*id
®id+id*id Reconocimiento de id+id*id Pila Entrada Acción id+id*id Empilar Id +id*id Reducir E®id E +id*id Empilar E+ id*id Empilar E+id *id Reducir E®id E+E *id Empilar E+E* id Empilar E+E*id Reducir E®id E+E*E Reducir E®E*E E+E Reducir E®E+E E Aceptar
No existe un analizador sintáctico SLR(1) para toda gramática
canónica LR(1). Recíprocamente, toda gramática que tiene
un analizador sintáctico SLR(1) es una gramática LR(1).
El punto de partida por la construcción práctica de un
analizador sintáctico SLR(1) es un analizador sintáctico LR(0)
que ha sido previamente construido. Para eliminar los estados inadecuados, los
items completos dentro de los estados LR(0) son extendidos por conjuntos "lookahead".
Supóngase los items de un autómata característico
de pila K para una gramática G son extendidos de la manera que se describió
arriba usando los conjuntos "lookahead".
Un estado es inadecuado si: -
dos items [X1®a1.,L1] y [X2®a2. ,L2] con L1ÇL2¹Æ -
dos items [X®a.ab] y [Y®g. ,L] con aÎL Si no hay estados inadecuados, entonces G es una gramática SLR(1) NOTA:
Para obtener un SLR(1):
A los items de reducción de la forma [A®a.] se les agrega el siguiente "lookahead":
{a
Î
S
È {#}| S'#
Þder*
bAaw}, es decir, el SIGUIENTE (A)
De esta manera se eliminan los conflictos. Sea la gramática G con las siguientes producciones: S
® E E
® E+T | T T
® T*F | F F
® (E) | id Los estados del autómata asociado son los siguientes: S0={[S®.E], [E®.E+T], [E®.T], [T®.T*F], [T®.F], [F®.(E)], [F®.id]} S1={[S®E.], [E®E.+T]} S2={[E®T.], [T®T.*F]} S3={[T®F.]} S4={[F®(.E)], [E®.E+T], [E®.T], [T®.T*F], [T®.F], [F®.(E)], [F®.id]} S5={[F®id.]} S6={[E®E+.T], [T®.T*F], [T®.F], [F®.(E)], [F®.id]} S7={[T®T*.F], [F®.(E)], [F®.id]} S8={[F®(E.)], [E®E.+T]} S9={[E®E+T.], [T®T.*F]} S10={[T®T*F.]} S11={[F®(E).]} Los estados S1, S2 y S9
son inadecuados. Se extienden los items completos de cada uno de dichos estados utilizando
la definición de SIGUIENTE. Entonces se obtiene lo siguiente: S1''= {[S®E.,{#}], [E®E.+T]} El
conflicto fue eliminado: "+" no pertenece a {#} S2''={[E®T., {#, +, )}], [T®T.*F]} El conflicto fue eliminado:
"*" no pertenece a {#, +, )} S9''={[E®E+T., {#, +, )}], [T®T.*F]} El conflicto
fue eliminado: "*" no pertenece a {#, +, )}
Entonces, G es una gramática SLR(1) Sea la gramática G con las siguientes producciones: S'
® S S
® L=R | R L
® *R | id R
® L El conjunto de items, que forman los estados del autómata asociado
son los siguientes: S0={[S'®.S], [S®.L=R], [S®.R], [L®.*R], [L®.id], [R®.L]} S1={[S'®S.]} S2={[S®L.=R], [R®L.]} S3={[S®R.]} S4={[L®*.R], [R®.L], [L®.*R], [L®.id]} S5={[L®id.]} S6={[S®L=.R], [R®.L], [L®.*R], [L®.id]} S7={[L®*R.], [L®.id]} S8={[R®L.]} S9={[S®L=R.]}
S2
es un estado inadecuado y el SIGUIENTE(R)={#,=}. Cuando el item [R®L.] es extendido con el conjunto "lookahead", el conflicto shift-reduce
se mantiene, ya que el símbolo "=" a ser leído está contenido
en le conjunto "lookahead" ({#,=}) del item mencionado, por lo tanto
G no es una gramática SLR(0).
pagina original:
http://www.ldc.usb.ve/~soler/traductores3/
(" y) y Î
Lq ![]() q(e(
Sq ), y ) Ç
Fq ¹ Æ
q(e(
Sq ), y ) Ç
Fq ¹ Æ
![]() (
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
se tiene que:
(
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
se tiene que:
(" z) L = P + Q Û ![]() p+q(
e( Sp+q ), z ) Ç
Fp+q ¹ Æ
p+q(
e( Sp+q ), z ) Ç
Fp+q ¹ Æ
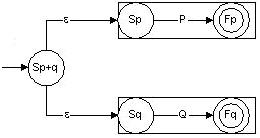
S = Sp+q y F = { Fp, Fq }
![]() p+q(
e( Sp+q ), z ) = È
(
p+q(
e( Sp+q ), z ) = È
(![]() p +q(
p +q( ![]() (
Sp+q ), x ) ,
(
Sp+q ), x ) , ![]() p+q(
p+q( ![]() (
Sp+q ), y)) "x
Î Lp, "y Î
Lq
(
Sp+q ), y)) "x
Î Lp, "y Î
Lq
= { Fp , Fq }
lo cual implica que la intersección de Fp+q será distinto de vacío,
por lo tanto z Î Lp+q
![]() (
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
se tiene que:
(
e( S ), x ) Ç
F ¹ Æ, partiendo de la fórmula original
se tiene que:
("
z) L = P · Q Û ![]() p·q(
e( Sp·q ), z ) Ç
Fp·q ¹ Æ
p·q(
e( Sp·q ), z ) Ç
Fp·q ¹ Æ
![]()
S = Sp y F = { Fq }
![]() p·q(
e( Sp+q ), z ) =
p·q(
e( Sp+q ), z ) = ![]() q(
q( ![]() (
(![]()
= ![]() q(
q( ![]() (Fp),
y)
(Fp),
y)
= ![]() q(
e(Sq),
y)
q(
e(Sq),
y)
= Fq
clausura es Sq, y el resto del string "y" puedo obtener Fq por medio de su clausura,
por ende Fq está contenido en el
estado final de Fp·q, lo cual implica que la intersección es distinto
de vacío, por lo tanto z Î
Lp·q.
![]() (
e( S ), x ) Ç
Fp* Æ,
partiendo de la fórmula original se tiene
que:
(
e( S ), x ) Ç
Fp* Æ,
partiendo de la fórmula original se tiene
que:
(" z) L = P*
Û ![]() p*(
e( Sp* ), z )
Ç
Fp* ¹ Æ
p*(
e( Sp* ), z )
Ç
Fp* ¹ Æ
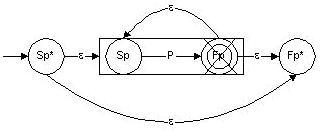
S = Sp* y F = {
Fp* }
![]() p*
se debe escribir como una función recursiva:
p*
se debe escribir como una función recursiva:
![]() p*(e(
Sp* ), z) =
p*(e(
Sp* ), z) =
- ![]() p*(
p*(![]() (
(![]() p(
e( Sp*
), x)), X
p(
e( Sp*
), x)), X
La función definida nos permite ver
que para el caso de e
estoy en el estado final (fin de la recursividad en la función),
mientras que cualquier string de la forma Xn será
reconocido por la función
![]() p*,
hasta que ese n sea igual a cero, por
ende al alcanzar el fin de la recursividad tendremos:
p*,
hasta que ese n sea igual a cero, por
ende al alcanzar el fin de la recursividad tendremos: ![]() p*(e(
Sp* ), z) =
p*(e(
Sp* ), z) = ![]() p*(e(
Fp* ), e)
p*(e(
Fp* ), e)
= e (Fp)
= Fp*
Veamos con el ejemplo anterior: ( a + b) * a
![]() Definición de AFD (Autómata Finito Determinístico)
Definición de AFD (Autómata Finito Determinístico)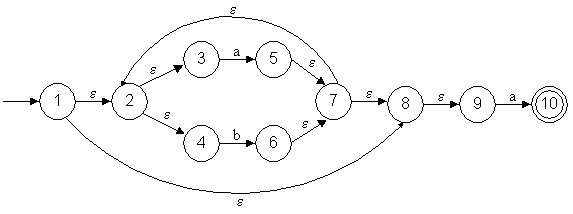
![]() }
}![]() ,
,![]() }
}![]() }
}![]() ,
,![]() },a)
= {5,10}
},a)
= {5,10}![]() ,
,![]() },a))
= {
},a))
= {![]() ,
,![]() }
}![]() ,
,![]() },b)
= {6}
},b)
= {6}![]() ,
,![]() },b))
= {
},b))
= {![]() }
}![]() },a)
= {5,10}
},a)
= {5,10}![]() },a))
= {
},a))
= {![]() ,
,![]() }
}![]() },b)
= {6}
},b)
= {6}![]() },b))
= {
},b))
= { ![]() }
}
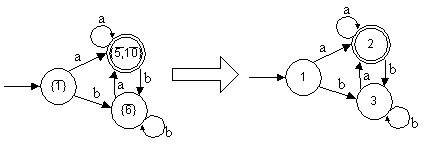
![]() })
y el (los) estado(s) final(es) es (son) aquel(los) c con un F anterior y es
diferente al vacío.
})
y el (los) estado(s) final(es) es (son) aquel(los) c con un F anterior y es
diferente al vacío.
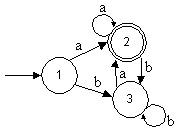
Sea A = {Q,T, d , S, F} un AFD :
![]() Función de Reconocimiento de un AFD
Función de Reconocimiento de un AFD![]() :
Q x T* ® Q
:
Q x T* ® Q
![]() (q,
e ) = q
(q,
e ) = q
![]() (q,
tw) =
(q,
tw) = ![]() (
d (q,t),w)
(
d (q,t),w)
![]() (S,x)
Î F
(S,x)
Î F
![]() (1,aba) =
(1,aba) = ![]() (
d (1,a), ba) =
(
d (1,a), ba) = ![]() (2,ba)
=
(2,ba)
=![]() (
d (2,b), a) =
(
d (2,b), a) =![]() (3,a)
=
(3,a)
=![]() (
d (3,a), e ) =
(
d (3,a), e ) = ![]() (2,
e ) = 2 Î F
(2,
e ) = 2 Î F
![]() Puntos de Interés a investigar
Puntos de Interés a investigar
Si un lenguaje es reconocido por un AFND, se debe mostrar que existe un
AFD que también lo reconoce, la idea es convertir el AFND en un
AFD equivalente que simule el AFND.
Cada estado de M es un conjunto de estados de N. (recordemos que
P(Q) es el conjunto de subconjuntos de Q)
Si R es un estado de M, es también un subconjunto de estados
de N. Cuando M lee un símbolo a en el estado R, el muestra donde
a toma cada estado en R, porque cada estado puede ir a un conjunto de estados,
nosotros tomamos la unión de todos esos estados. Otra forma de escribir
esta expresión es la siguiente:
M comienza en el mismo estado inicial que N
Que d sea parcial indica que no está
definida para ciertos valores. Esto implica que la función de reconocimiento
no reconocerá todas las palabras pertenecientes a cierto lenguaje.
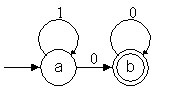
Se puede totalizar d diciendo que cuando no
tenga un valor se le asigna vacío.
El problema de construir el complemento del lenguaje a partir de
una función parcial esta que nos lleva al cálculo sólo un
subconjunto del complemento del lenguaje. Para calcular el complemento se deben
transformar a todos los estados no finales en finales, y los que eran antes estados
finales en no finales. Si la función es total, es decir, posee valor para
cualquier letra del alfabeto, el autómata obtenido representará
exactamente al complemento del lenguaje. En el caso de que la función es
parcial y no esta definida para todos los elementos del alfabeto, entonces el
autómata definido solo representará un subconjunto del lenguaje,
ya que existirán palabras que no las reconocerá ni el autómata
original ni el complemento del mismo.
![]() ?
(i.e. el complemento del lenguaje)
?
(i.e. el complemento del lenguaje)
Autómata que reconoce una serie de unos y luego una
serie de ceros, o simplemente una serie de ceros
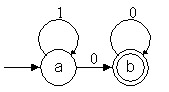
Autómata que reconoce el mismo lenguaje que el autómata
de al lado
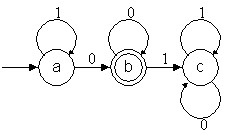
Complemento del autómata parcial
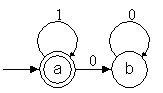
Complemento del autómata total
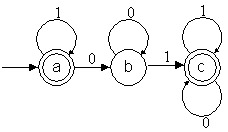
Propiedad
![]() AFD Parcialmente especificado
AFD Parcialmente especificado
Propiedad
![]() AFD Completamente especificado
AFD Completamente especificado
* å x Q ®
Q (cualquier elemento del dominio está definido)
Sea Ri Í Q
x Q, una relación de equivalencia (i=0, |Q|-2) y sean q1,
q2 Î Q
![]() K-Indistinguibles
K-Indistinguibles![]() (q1,
x) Ç F ¹ Ø
Ù d'
(q2, x) Ç F ¹
Ø, llegan a estados finales
(q1,
x) Ç F ¹ Ø
Ù d'
(q2, x) Ç F ¹
Ø, llegan a estados finales
![]() (q1,
x) Ç F = Ø
Ù d'
(q2, x) Ç F ¹
Ø, no llegan a estados finales
(q1,
x) Ç F = Ø
Ù d'
(q2, x) Ç F ¹
Ø, no llegan a estados finales
ENTRADA: M = (å , Q, d
, q0, F) un AFD total
![]() Algoritmo de Minimización de un AFD
Algoritmo de Minimización de un AFD
2.- Para cada grupo Gi de la partición P
(Gi Î P)
2.1.- Particionar Gi en subgrupos siempre que dos estados
s y t de Gi estarán en el mismo grupo si y solo si dichos
estados, a través de una transición "a" llegan a estados
que están en el mismo grupo Gi de la partición
P . En el peor de los casos un subgrupo contendrá
un solo elemento.
2.2.- Reemplazar Gi por los nuevos subgrupos de Gi
para crear la nueva partición P nuevo.
Sino volver al paso 2.
4.-Q'={Gi/ Gi Î
P final} (Los nuevos estados del
autómata, son las particiones de P final)
q0'= Gi/ GiÎ
P final y q0 Í
Gi (El nuevo estado inicial q0' es el grupo
que contiene a q0)
F'={Gi/ GiÎ P
final y $ f Î
F/ f Î Gi} (Los nuevos estados
finales son todos los grupos de las particiones que contiene estados que
estaban en los estados finales
del autómata original, es decir en M)
Finalmente el autómata minimizado es M'=(å
, Q', d', q0',
F') (Las nuevas transiciones son todas aquellas que existen en el autómata
inicial que unen los nuevos estados del autómata. No deben haber
transiciones repetidas)
¿L(M) = L(M')?
![]() Reconocimiento del mismo lenguaje por el AFD y por el AFD Mínimo Equivalente
Reconocimiento del mismo lenguaje por el AFD y por el AFD Mínimo Equivalente
Veamos las transiciones del autómata M'
Para la creación de d' se toma cada
una de las transiciones de M, adaptándolas según la definición.
Como "todas" las transiciones del autómata original son tomadas
en cuenta, el lenguaje generado es el mismo.
Sin embargo, |d | ³
|d'| y esto se debe a que al generar d'
pueden aparecer arcos repetidos porque Gi y Gj contiene
uno o varios estados del autómata original.
Teorema: El autómata mínimo es único para
cada lenguaje regular.
![]() Teorema de Unicidad
Teorema de Unicidad
Haciendo inducción sobre k (número de estados).
![]() Demostración: Para un autómata de k estados
|Q|=k, se necesitan a lo más k-2 pasos para obtener el autómata
mínimo asociado (siguiendo el algoritmo antes especificado)
Demostración: Para un autómata de k estados
|Q|=k, se necesitan a lo más k-2 pasos para obtener el autómata
mínimo asociado (siguiendo el algoritmo antes especificado)
k-2=2-2=0 (se cumple)
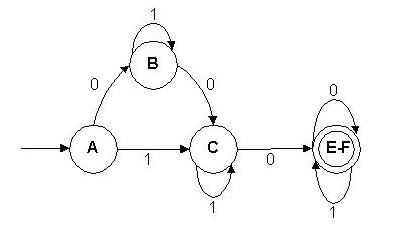
Si L es regular, un AFD A=(Q, T, d , S, F) que
reconoce a L
![]() Lema del Bombeo (Pumping Lema)
Lema del Bombeo (Pumping Lema)![]() T*
Ù ($ y): w = x.y.z
Ù 0 < long |y| £
long (w)]
T*
Ù ($ y): w = x.y.z
Ù 0 < long |y| £
long (w)]
x.yi.z ![]() L
L
qk ... qk+j son iguales ®
qk = qk+j, j >0, y= tk+1 ...
tk+j, el loop es tk+1 ... tk+j
infinito |L| = ¥
Existe otra manera de representar a los autómatas, la cual consiste
en la utilización de "Gramáticas Regulares".
![]() Otra Visión de los AFD y de los AFND
Otra Visión de los AFD y de los AFND
Teorema
![]() Lenguajes Regulares
Lenguajes Regulares
* L es denotado por alguna expresión regular
* L es reconocido por algún AFND (Autómata Finito no
Determinístico)
* L es reconocido por algún AFD (Autómata Finito Determinístico)
* L es generado por alguna Gramática Regular.
![]() Gramáticas Libres de Contexto
Gramáticas Libres de Contexto
Definición
* S es el alfabeto a cuyos elementos se
le llaman símbolos terminales
* P Í N x (N È
S )* cuyos elementos son llamados producciones
* S Î N es el símbolo inicial
µ Î
(N È S )*
(Combinación de elementos pertenecientes al conjunto de los terminales
y los no terminales)
![]() Definición General de Gramática Regular Lineal a la Derecha
Definición General de Gramática Regular Lineal a la Derecha
* |T| < ¥ y T ¹
Ø Conjunto de símbolos terminales
* S Î N Axioma o símbolo objetivo
* |P| < ¥ y P Í
((N È T)* N (N È
T)*) x (N È T)* Conjunto de Producciones,
<µ
, b > Î
P Û µ
® b
![]() Lenguaje Generado por una gramática G (L(G))
Lenguaje Generado por una gramática G (L(G))
P Í (N È
T)* x (N È T)*
![]() Substituciones (Derivaciones)
Substituciones (Derivaciones)
D Í (N È
T)* x (N È T)*,![]() D Û
g = d1.b
.d2 Ù
D Û
g = d1.b
.d2 Ù![]() P
Ù
P
Ù
![]() (N
È T)*); a
(N
È T)*); a![]() N;
b
N;
b![]() (N
È T)*
(N
È T)*
![]() D
Þ <l , g
>
D
Þ <l , g
> ![]() D*
D*![]() (N È T)* Þ
<l , l >
(N È T)* Þ
<l , l > ![]() D*
D*![]() D*
Ù <g , Y
>
D*
Ù <g , Y
> ![]() D* Þ
<l , Y >
D* Þ
<l , Y > ![]() D*
D*![]() D*
Û l Þ
* g
D*
Û l Þ
* g
![]() T*
Ù SÞ *x}
T*
Ù SÞ *x}
Ejemplo: Sea la gramática G1=({S,A}, {0,1}, P1, S) con P1 compuesta por:
S ® SA (0),
S ® 0 (1),
S ® 1A1 (2),
A ® 0 (3)
Un ejemplo de frase generada por G1 es: 00
S Þ (0) SA Þ (1) 0A Þ (3) 00
Por lo tanto, S Þ * 00
Por lo tanto 00 ![]() L(G1)
L(G1)
Ejemplo:
N={S, A}
T={a, b}
P={S ® aA, S ®
bS, A ® bS, A ®
aA, A ® e }
S Î N
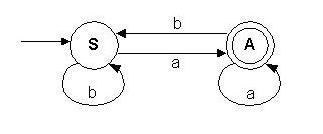
Se verá como a partir de una gramática dada se obtiene la expresión regular asociada:
A partir de las producciones de la gramática G se obtienen dos incógnitas, una por cada lenguaje:
L(S)={a}.L(A) È {b}.L(S)
L(A)={a}.L(A) È {b}.L(S) È
{e}
L(S)=a.L(A)+b.L(S)
L(A)=a.L(A)+b.L(S)+e
S=aA+bS
A=aA+bS+e = aA+(bS+e) asociando los dos últimos términos.
Utilizando x=a x+b Þ x=a *b (1), se obtiene:
A=a*(bS+ e)
Sustituyendo el valor de A en S, se obtiene:
S=a(a*(bS+ e))+bS
S=aa*bS + aa* + bS = aa*bS + bS + aa*, factorizando
S=(aa* + e)bS + aa*
Utilizando el axioma de expresiones regulares e+(a.a*) = a*
S=a*bS + aa*
Usando nuevamente (1), se tiene que:
S=(a*b)*aa![]() (a+b)*a
(a+b)*a
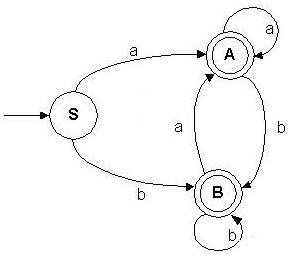
L(A)={a}.L(A) È {b}.L(B) È e
L(B)={b}.L(B) È {a}.L(A) È e
L(A)=a.A+b.B+e
L(B)=b.B+a.A+e
A=aA + bB + e
B=aA + bB + e = bB + (aA + e), asociando
Usando (1), se tiene que:
B=b*(aA+e )
Sustituyendo el valor de B en A:
A=aA + b(b*(aA+ e)) + e
A=aA + bb*aA + bb* + e
A=(a + bb*a)A+ bb* + e
A=b*aA+ b* Usando (1) se tiene que: A=(b*a)*b*
B=b*(a(b*a)*b* + e)
S=a(b*a)*b+ bb*(a(b*a)*b* + e )
![]() Tipificación de las Gramáticas (Chomsky)
Tipificación de las Gramáticas (Chomsky)
* | T | < ¥ y T ¹
Ø
* N Ç T= Ø
* S Î N
* | P | < ¥ y P Í
((N È T)* N (N È
T)*) x (N È T)*
" µ ®
b Î P
long(µ ) £
long(b )
" µ ®
b Î P
long(µ ) = 1
* Lineal a la izquierda
" µ ®
b Î P
µ Î
N y b Î (N È
{e }) .T*
* Lineal a la derecha
" µ ®
b Í P
µ Î
N y b Î T*
. (N È {e
})
![]() Definición de Autómatas de Pila
Definición de Autómatas de Pila
![]() Definición de Gramática Extendida
Definición de Gramática Extendida
![]() Definición de Autómatas de Pila de Items de G
Definición de Autómatas de Pila de Items de G
Donde P1 corresponde a las producciones:
1001
1001
- G = ( N, T, P, S ) | N |
£|
P |
- (" A Î N)
S Þ* aAb
A Þ* w Î
T*
La causa de ello, es la falta de prioridad definida en el lenguaje, como
LL(k) permite expresar prioridad en el
lenguaje, se puede decir entonces que LL (k) no es ambígua.
entre < > y los nodos terminales son elementos pertenecientes al alfabeto
T.
< condicion_if > :: = if < expresión
> then < instrucciones >
< opcional_else > fi
Donde el conjunto N={ expresión, instrucciones,
opcional_else } y T={ if,
then, fi }
método de parseo sea sencillo.
comienza con " if " y finaliza con " fi ", proviendo suficiente información
para la creación del árbol.
V
si X Þ*
e
- seAnula
(X) =
F
sino
escoger para reconocer un
string de un lenguaje determinado.
como una gramática
que tenga la siguiente característica:
de producciones y es además capaz de escoger entre 2 producciones,
pues podemos garantizar la condición de
fortaleza si la intersección entre los k-ésimos directores
es igual al vacío.
una gramática
que tenga la siguiente característica:
de producciones y es además capaz de escoger entre 2 producciones,
pues garantizar la condición de debilidad
si la intersección entre los k-ésimos directores es distinta
al vacío.
Los lenguajes LR son los lenguajes que pueden ser reconocidos por un autómata
de pila determinístico (ADPD).
![]() Operaciones
de un Reconocedor Shift Reduce
Operaciones
de un Reconocedor Shift Reduce
![]() Introducción a las Gramáticas SLR(1)
Introducción a las Gramáticas SLR(1)
![]() Definición de Gramática SLR(1)
Definición de Gramática SLR(1)
![]()