
By :
Ido Milstein , ID 037684966
Amir Fish , ID 032025595
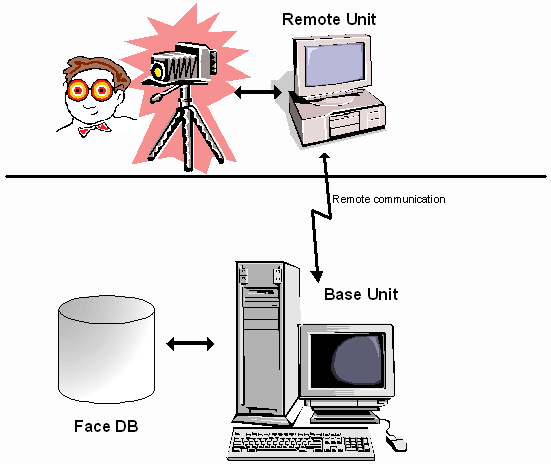
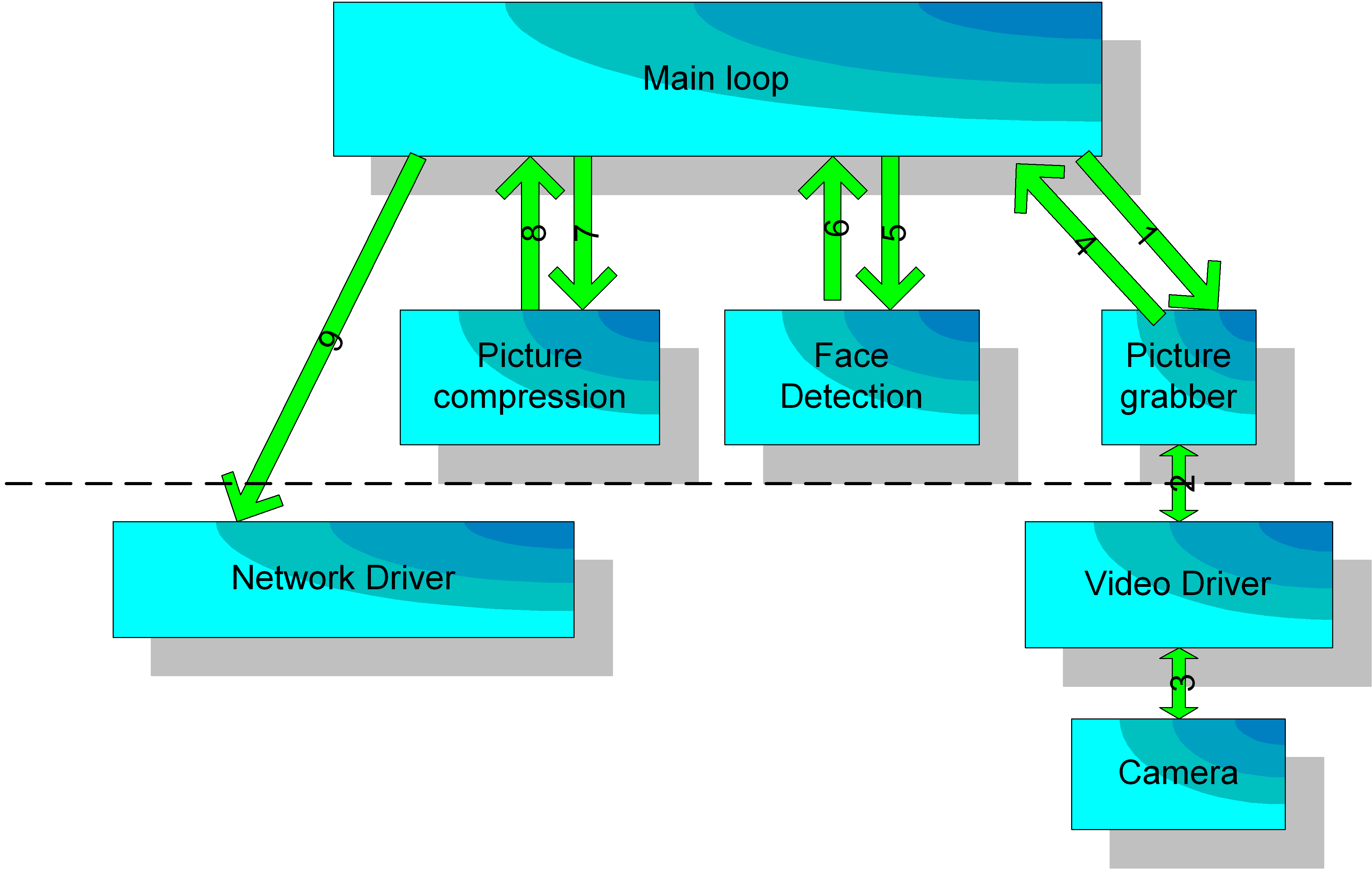
AVICap supports streaming video capture and single-frame capture in real-time. In addition, AVICap provides control of video sources that are Media Control Interface (MCI) devices so the user can control (through an application) the start and stop positions of a video source, and augment the capture operation to include step frame capture.
The windows you create by using the AVICap window class can perform the following tasks:
Training:
2. Apply preprocessing to the images (linear compensation for different light situations).
3. Add random images as an initial non face collection (and apply preprocessing to it too).
4. Train a neural network on the training-set.
5. Use the network to look for faces in scenery images that do NOT contain faces. Mark all the detections as false alarms and add them as such to the training set.
6. Repeat 4,5 a few times (8 times in our case).
7. Train several networks using this algorithm.
2. For each location mark how many times a face was found in a box that contains that location. If there is a location for which this number is greater than a threshold, find the center of the highest detections.
3. In this center, look for faces at various slightly separated scales (to get a better tuning for the scale). If the number of detections in this center does passes a second threshold, then a face is detected at that center with the given scale.
4. Knowing the location and size of the face, we compute the expected locations of eyes and mouth.
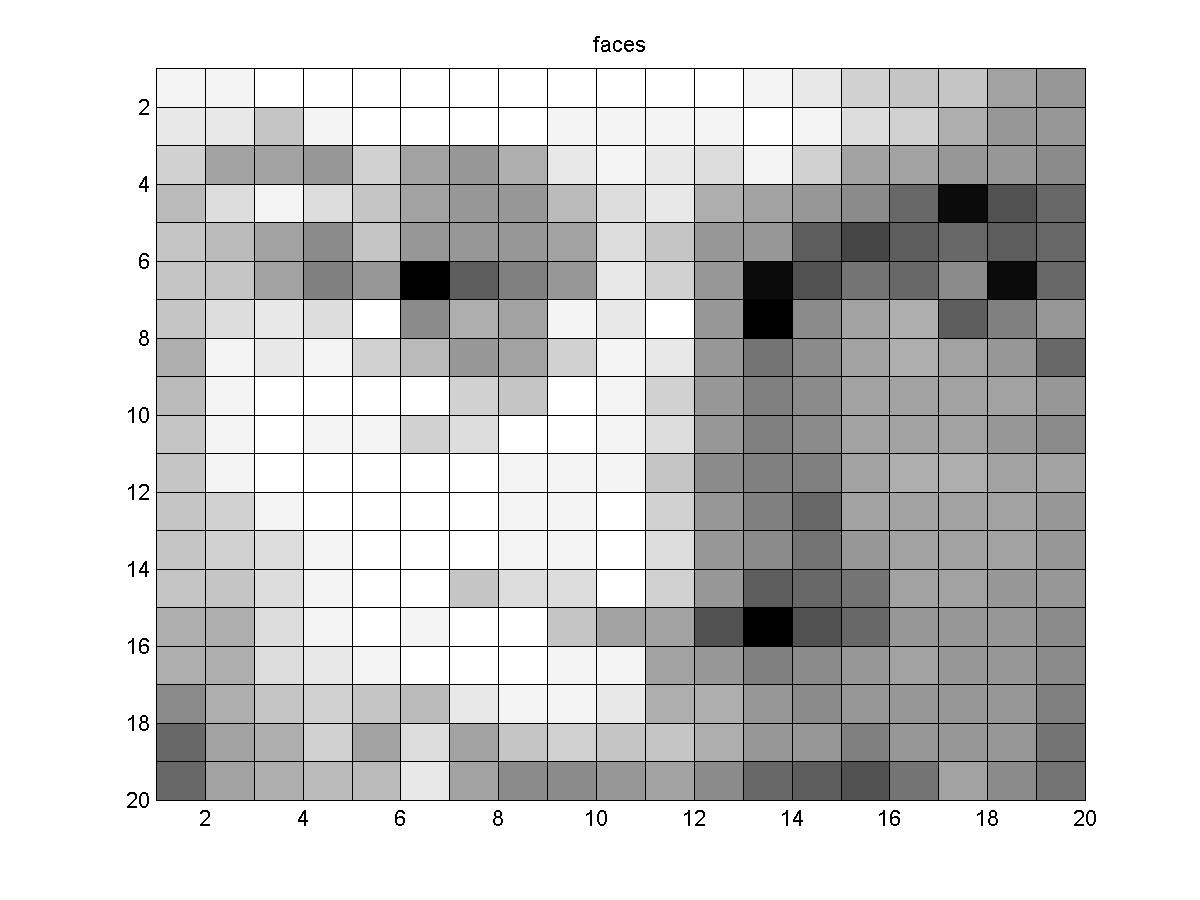
Example of face detection
: