1. Chapitre 01 : Les réseaux de neurones
I. Historique
Les débuts furent avec le neurone formel de Mac. Culloch et Pitts en 1943 qui simulait de façon très simplifiée le neurone biologique.
Le neurone artificiel effectue une somme pondérée de stimuli provenant d’autres neurones. Si la somme des excitations est supérieure à un seuil donné alors le neurone est activé, sinon il ne transmet aucune information (de nature booléenne).
En parallèle, le neurophysicien Hebb établit le principe d’activation des neurones (ayant un fondement biologique) qui stipule que :
Si deux
neurones sont activés simultanément, alors la valeur des poids des connexions
entre ces neurones est augmentée, sinon les connexions restent inchangées.
En 1958, Rosenblatt développa le concept du perceptron pour expliquer et modéliser les facultés de reconnaissance des formes du système visuel. L’idée essentielle du perceptron est de considérer la rétine de l’œil comme une matrice de capteurs. Les capteurs de cette matrice sont reliés à des processus élémentaires intermédiaires qui réalisent des opérations prédéterminées. Pour reconnaître des formes visuelles particulières, les sorties de ces processus sont ensuite injectées à des systèmes à seuil non linéaires, binaires en vue de la classification automatique.
Vers le début des années 60, Widrow développa des concepts similaires pour la résolution des problèmes de filtrage adaptatif du signal en mettant au point l’Adaline et le Madaline. Il a démontré notamment que l’Adaline était capable de séparer linéairement des classes dans l’espace à deux dimensions.
De son côté Minsky et d’autres chercheurs ont analysé, sous l’angle mathématique, les performances du Perceptron et le trouvant incapable de résoudre la séparation pour l’opération logique "Ou exclusif" et qu’en conséquence ce modèle ne présente aucun intérêt.
De plus, ils affirment que même si les perceptrons multicouches sont capables de résoudre le fameux problème du " Ou exclusif", il n’existe pas un mécanisme susceptible d’apprendre les poids de connexion afin de minimiser l’erreur entre la sortie désirée et la sortie fournie par un Perceptron multicouches.
Entre 1969 et 1978, des chercheurs, dont Hopfield, ont cependant persévéré dans l’étude des réseaux de neurones artificiels en introduisant la notion d’énergie d’un ensemble de neurones interconnectés en se basant sur la physique quantique des " Verres de spin".
La découverte, en 1985, de l’algorithme de rétro-propagation du gradient énoncée par Rumelhart et al. permit de lever toutes les limitations énoncées par Minsky et Papert d’où le regain d’intérêt pour les réseaux de neurones. En effet, cet algorithme reste le modèle le plus étudié et le plus productif au niveau des applications (reconnaissance de la parole, reconnaissances de forme vision artificielle, aide à la décision).
II. Description des réseaux de neurones
Les réseaux de neurones formels sont un essai pour la modélisation mathématique du cerveau humain.
Les neurones formels sont des entités capables de réaliser quelques calculs élémentaires mais en les reliant entre elles on obtient un puissant élément de calcul numérique et de traitement parallèle de l’information.
Il est faut bien noter que les tenants de la
modélisation biologique veulent représenter un certain nombres de contraintes
liées à la nature du cerveau, et que de l’autre coté les tenants de la
puissance de calcul ne s’intéressent
qu’au modèle en lui même, sans aucun lien avec la réalité biologique.
II.1 Le Modèle Biologique
Dans le cerveau, les neurones sont reliés entre eux par l’intermédiaire d’axones et de dendrites. En première approche, on peut considérer que ces sorties de filaments sont des conducteurs d’électricité et peuvent ainsi véhiculer des messages depuis un neurone vers un autre. Les dendrites représentent les entrées du neurone, et son axone sa sortie.
Un neurone émet un signal en fonction des signaux qui lui proviennent des autres neurones. On observe, en fait au niveau d’un neurone, une intégration des signaux reçus au cours du temps, c’est-à-dire une sorte de sommation des signaux.
En général, quand la somme dépasse un certain seuil, le neurone émet à son tour un signal électrique.
La notion des synapses explique la transmission des signaux entre un axone et une dendrite, au niveau de la jonction, il existe un espace vide à travers lequel le signal électrique ne peut pas se propager.
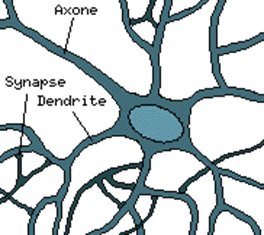
Figure 1‑1 Le neurone biologique
La transmission se fait alors par l’intermédiaire de substances chimiques les " Neuro-Mediateurs", quand un signal arrive au niveau de la synapse il provoque l’émission de "Neuro-Mediateurs" qui vont se fixer des récepteurs de l’autre côté de l’espace inter-synaptique.
Quand suffisamment de molécules se sont fixées, un signal électrique est émis de l’autre côté, et on a donc une transmission.
En fait, suivant le type de la synapse, l’activité d’un neurone peut renforcer ou diminuer l’activité de ces voisins. On parle, ainsi, de synapse excitatrice ou inhibitrice.
II.2 Le Neurone Formel
II.2.1 Le modèle
Le modèle de neurone formel présenté ici, dû à Mac Culloch et Pitts, est un modèle mathématique très simple dérivé d’une analyse de la réalité biologique.
La somme pondérée des signaux arrivant à chaque neurone est comparée ensuite à un seuil, et on déduit, de la comparaison, la sortie du neurone. Cette sortie sera par exemple égale à 1, si la somme est supérieure au seuil et à 0 dans le cas contraire.
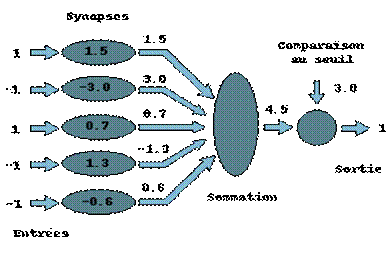
Figure 1‑2 Un neurone formel
Cet enchaînement de "sommations" puis de "non linéarité" représente finalement les propriétés physiques du neurone.
En résumé, un neurone formel réalise simplement une somme pondérée de ses entrées, ajoute un seuil à cette somme et fait passer le résultat par une fonction de transfert pour obtenir sa sortie.
II.2.2 L’utilisation
Pour fonctionner, un neurone formel utilise des entrées qui sont des grandeurs réelles. Si on relie un neurone au monde extérieur par l’intermédiaire de capteurs, il peut réaliser une simple analyse de ce qu’il "perçoit".
Si on représente les valeurs observées par le neurone sous forme d’un vecteur, le neurone réalise alors un découpage de son espace d’entrée (l’espace vectoriel auquel appartient le vecteur d’observation) en deux zones :
· La zone d’activation dont les vecteurs donnent une sortie égale à 1.
· La zone d’inactivation dont les vecteurs donnent une sortie égale à 0.
Comme le calcul effectué est, en fait, linéaire, la séparation l’est aussi. Les coefficients synaptiques et le seuil définissent l’équation d’un hyperplan qui est la frontière.
II.2.3 La connectivité
La connectivité des réseaux de neurones, c’est-à-dire la manière dont les neurones sont connectés, peut être totale (tous les neurones sont connectés entre eux) ou par couche (les neurones d’une couche ne sont connectés qu’aux couches suivantes). Il existe des réseaux mono couche ou multicouches.
II.2.4 Les fonctions d’activation :
Le déclenchement de l'activité intervient si la somme des excitations (activité, des neurones excitateurs, pondérée par les poids synaptiques) dépasse un certain seuil propre au neurone.
Fonction seuil :
F(x) = 1, si x > SEUIL.
F(x) = 0, sinon.
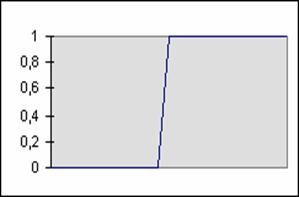
Figure 1‑3 Fonction seuil
Un neurone est d'autant plus actif qu'il est excité (fonction monotone croissante). Un neurone ne peut être matériellement actif (potentiel électrique) au-delà d'une certaine valeur (fonction bornée).
Fonction linéaire bornée :
F(x) = -1 ou +1, au-delà des bornes.
F(x) = A. x, sinon.
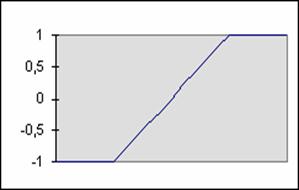
Figure 1‑4 Fonction linéaire
bornée
Fonction linéaire :
F(x) = A. x
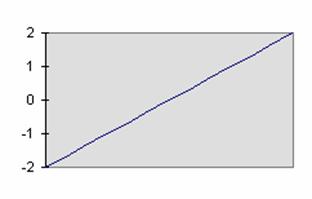
Figure 1‑5 Fonction linéaire
Fonction sigmoïde exponentielle :
F(x) = 1 / (1 + EXP (- x))
Dérivée : F’(x) = F(x). (1 – F(x))
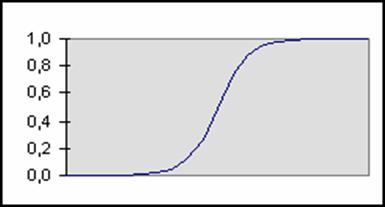
Figure 1‑6 Fonction
sigmoïde
II.2.5 Apprentissage, mémoire et oubli
Une caractéristique des réseaux de neurones est leur capacité à apprendre (par exemple à reconnaître une lettre, un son…). Mais cette connaissance n’est pas acquise dés le départ. La plupart des réseaux de neurones apprennent par l’exemple.
Ils ont donc une capacité à classer, généraliser, à mémoriser et aussi à oublier. Un réseau de neurones reconnaîtra d’autant plus facilement un objet qu’il aura « vu » souvent.
III. Architectures Des Réseaux De Neurones :
III.1 Le Perceptron :
C'est un des premiers réseaux de neurones, conçu en 1958 par Rosenblatt. Il est linéaire et monocouche. Il est inspiré du système visuel. La première couche (d'entrée) représente la rétine. Les neurones de la couche suivante sont les cellules d'association, et la couche finale les cellules de décision.
Les sorties des neurones ne peuvent prendre que deux états -1 et 1ou 0 et 1. Seuls les poids des liaisons entre la couche d'association et la couche finale peuvent être modifiés.
La règle de modification des poids utilisée est la règle de Widrow-Hoff :
· Si la sortie (celle d'une cellule de décision donc) est égale à la sortie désirée, le poids de la connexion entre ce neurone et le neurone d'association qui lui est connecté n'est pas modifié.
· Dans le cas contraire le poids est modifié en fonction de l'entrée :
W i <= w
i + k (d - s) (1.1)
Avec k : constante positive, s : sortie et
d : sortie désirée
III.2 Les Perceptrons Multicouches (PMC)
Ils sont une amélioration du perceptron comprenant une ou plusieurs couches intermédiaires dites couches cachées. Ils utilisent, pour modifier leurs poids, un algorithme de rétro-propagation du gradient, qui est une généralisation de la règle de Widrow-Hoff.
Il s'agit toujours de minimiser l'erreur quadratique, ce qui est assez simple quand on utilise une fonction F dérivable (la sigmoïde par exemple). On propage la modification des poids de la couche de sortie jusqu'à la couche d'entrée.
Les PMC (ou MLP pour Multi Layer Perceptron) agissent comme un séparateur non linéaire et peuvent être utilisés pour la classification, le traitement de l'image ou l'aide à la décision.
L'idée principale est de grouper des neurones dans une couche. On place ensuite bout à bout plusieurs couches et on connecte complètement les neurones de deux couches adjacentes.
Les entrées des neurones de la deuxième couche sont donc en fait les sorties des neurones de la première couche. Les neurones de la première couche sont reliés au monde extérieur et reçoivent tous le même vecteur d'entrée (c'est en fait l'entrée du réseau). Ils calculent alors leur sorties qui sont transmises aux neurones de la deuxième couche, etc. Les sorties des neurones de la dernière couche forment la sortie du réseau.

Figure 1‑7 Un réseau multi-couches
Un perceptron multicouches calcule donc une fonction vectorielle. On peut ajouter les valeurs des connexions synaptiques et des seuils afin de modifier la fonction calculée.
III.3 Les Réseaux Hopfield :
Un réseau de Hopfield réalise une mémoire adressable par son contenu. Il s'agit d'un réseau constitué de neurones de Mac. Culloch et Pitts (à deux états, -1 et 1 ou 0 et 1), dont la loi d'apprentissage est régie par la règle de Hebb (1949), qui veut qu'une synapse améliore son activité si et seulement si l'activité de ses deux neurones est corrélée (c'est-à-dire que le poids wij d'une connexion entre un neurone i et un neurone j augmente quand les deux neurones sont activés en même temps).
III.4 Les Réseaux De Kohonen
Contrairement aux réseaux de Hopfield où les neurones sont modélisés de la façon la plus simple possible, on recherche ici un modèle de neurone plus proche de la réalité.
Une loi de Hebb modifiée (tenant compte de l'oubli) est utilisée pour l'apprentissage, la connexion est renforcée dans le cas ou les neurones reliés ont une activité simultanée, et diminuée dans le cas contraire.
dwi/dt = k S ei - B(S) wi (1.2)
avec B(S) la fonction d'oubli et S : sortie (toujours positive).
Une loi d'interaction latérale (observée biologiquement) est aussi modélisée. Les neurones très proches (physiquement) interagissent positivement (le poids des connexions est augmenté autour quand une synapse est activée), négativement avec les neurones un peu plus loin, et pas du tout avec les neurones éloignés.
Les réseaux de Kohonen ont des applications dans la classification, le traitement de l'image, l'aide à la décision et l'optimisation.
IV. Classification des réseaux de neurones
Il est possible de définir deux grandes familles d’architecture de réseaux :
· Réseaux non bouclés.
· Réseaux bouclés.
IV.1 Les Reseaux Non Boucles
Les réseaux non bouclés produisent les signaux de sorties à partir d’information émanant directement d’autres cellules qui ne sont l’objet d’aucune contre réaction. On parle alors de réseaux à propagation directe.
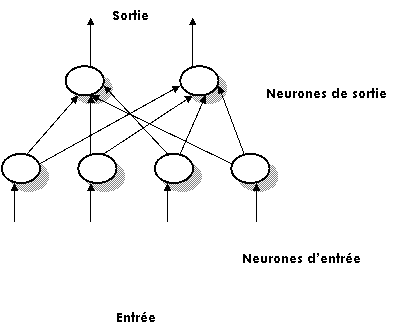 Le réseau peut être constitué de plusieurs couches. Les couches se
trouvant entre les couches d’entrée et
de sortie sont appelées couches cachées.
Le réseau peut être constitué de plusieurs couches. Les couches se
trouvant entre les couches d’entrée et
de sortie sont appelées couches cachées.

Figure 1‑8 Réseau non bouclé
Dans cette configuration tous les neurones sont connectés à toutes les entrées (ici, certaines connexions seulement ont été esquissées) et les neurones de la couche cachée sont seulement connectés à la couche de sortie, leur nombre variant de 1 à 2. Un tel réseau est défini par les ‘n’ neurones d’entrée, les neurones cachées et les ‘m’ neurones de sortie.
IV.2 Les Réseaux Boucles
A l’opposé des réseaux non bouclés, les réseaux bouclés sont le siège de contre réaction synchrone ou asynchrone en fonction du temps.
Ils sont particulièrement adaptés pour construire des réseaux de type Hopfield ou Boltzman avec des procédures d’apprentissage non supervisés.

Figure 1‑9 Réseau bouclé
Pour ces réseaux le temps intervient et le comportement des cellules du réseau est régi en général par des équations différentielles non linéaires.
Pour des conditions initiales données qui correspondent à l’exemple à mémoriser, les réseaux évoluent au cours du temps pour atteindre un état d’équilibre stable ou instable.
Comme en physique quantique et en automatique des systèmes non linéaires, un état instable se manifeste par des cycles d’oscillations autour d’un état donné.
V. Conclusion
A partir d'un modèle simple de neurones biologiques, des modèles plus complexes sont construits. Ces derniers permettent de calculer des fonctions vectorielles, adaptables à un ensemble d'exemples par le biais d'algorithmes d'optimisation.
Dans le chapitre suivant, nous essaierons de présenter quelques algorithmes permettant l’apprentissage de ces réseaux.