...Continuación
Debido a la separación entre la base de conocimiento y el mecanismo de inferencia, los sistemas expertos tienen gran flexibilidad, lo que se traduce en una mejor modularidad, modificabilidad y legibilidad del conocimiento.
Otra ventaja es que este tipo de sistemas pueden utilizar razonamiento aproximado para hacer deducciones y que pueden resolver problemas sin solución algorítmica.
Los sistemas expertos también tienen inconvenientes. El conocimiento humano es complejo de extraer y, a veces, es problemático representarlo. Si un problema sobrepasa la competencia de un sistema experto, sus prestaciones se degradan de forma notable. Además, las estrategias de razonamiento de los motores de inferencia suelen estar programadas procedimentalmente y se adaptan mal a las circunstancias. Están limitados para tratar problemas con información incompleta.
Un experto humano no estudia progresivamente una hipótesis, sino que decide de inmediato cuando se enfrenta a una situación análoga a otra ocurrida en el pasado Los sistemas expertos no utilizan este razonamiento por analogía.
Los costes y duración del desarrollo de un sistema experto son bastante considerables (aunque se suelen amortizar rápidamente) y su campo de aplicación actual es restringido y específico.
Finalmente, hay que tener en cuenta los problemas sociales que acarrean al ser susceptibles de influir en la estructura y número de empleos.
Arquitectura y funcionamiento de un Sistema Experto
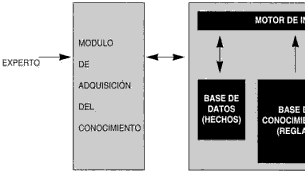
No existe una estructura de sistema experto común. Sin embargo, la mayoría de los sistemas expertos tienen unos componentes básicos: base de conocimientos, motor de inferencia, base de datos e interfaz con el usuario. Muchos tienen, además, un módulo de explicación y un módulo de adquisición del conocimiento. La figura 1 muestra la estructura de un sistema experto ideal.
Fig. 1
 |
 |
La base de conocimientos contiene el conocimiento especializado extraído del experto en el dominio. Es decir, contiene conocimiento general sobre el dominio en el que se trabaja. El método más común para representar el conocimiento es mediante reglas de producción. El dominio de conocimiento representado se divide, pues, en pequeñas fracciones de conocimiento o reglas SI . . . ENTONCES . . . Cada regla constará de una parte denominada condición y de una parte denominada acción, y tendrá la forma:
SI condición ENTONCES acción
Como ejemplo se puede considerar la siguiente regla médica:
SI el termómetro marca 39º
Y el termómetro funciona correctamente
ENTONCES el paciente tiene fiebre
Una característica muy importante es que la base de conocimientos es independiente del mecanismo de inferencia que se utiliza para resolver los problemas. De esta forma, cuando los conocimientos almacenados se han quedado obsoletos, o cuando se dispone de nuevos conocimientos, es relativamente fácil añadir reglas nuevas, eliminar las antiguas o corregir errores en las existentes. No es necesario reprogramar todo el sistema experto.
Las reglas suelen almacenarse en alguna secuencia jerárquica lógica, pero esto no es estrictamente necesario. Se pueden tener en cualquier secuencia y el motor de inferencia las usará en el orden adecuado que necesite para resolver un problema.
Una base de conocimientos muy ingenua, para identificar vehículos, podría ser la siguiente:
Regla 1: SI tiene 2 ruedas
Y utiliza motor
ENTONCES es una motocicleta
Regla 2: SI tiene 2 ruedas
Y es movido por el hombre
ENTONCES es una bicicleta
Regla 3: SI tiene 4 ruedas
Y utiliza motor
Y pesa menos de 3500 Kgs.
ENTONCES es un coche
Existen reglas de producción que no pertenecen al dominio del problema. Estas reglas se llaman metarreglas (reglas sobre otras reglas) y su función es indicar bajo qué condiciones deben considerarse unas reglas en vez de otras. Un ejemplo de metaregla es:
SI hay reglas que usan materias baratas
Y hay reglas que usan materias caras
ENTONCES usar antes las primeras que las segundas
La base de datos o base de hechos es una parte de la memoria del ordenador que se utiliza para almacenar los datos recibidos inicialmente para la resolución de un problema. Contiene conocimiento sobre el caso concreto en que se trabaja. También se registrarán en ella las conclusiones intermedias y los datos generados en el proceso de inferencia. Al memorizar todos los resultados intermedios, conserva el vestigio de los razonamientos efectuados; por lo tanto, se puede utilizar explicar las deducciones y el comportamiento del sistema.
El motor de inferencias es un programa que controla el proceso de razonamiento que seguirá el sistema experto. Utilizando los datos que se le suministran, recorre la base de conocimientos para alcanzar una solución. La estrategia de control puede ser de encadenamiento progresivo o de encadenamiento regresivo. En el primer caso se comienza con los hechos disponibles en la base de datos, y se buscan reglas que satisfagan esos datos, es decir, reglas que verifiquen la parte SI. Normalmente, el sistema sigue los siguientes pasos:
1. Evaluar las condiciones de todas las reglas respecto a la base de datos, identificando el conjunto de reglas que se pueden aplicar (aquellas que satisfacen su parte condición)
2. Si no se puede aplicar ninguna regla, se termina sin éxito; en caso contrario se elige cualquiera de las reglas aplicables y se ejecuta su parte acción (esto último genera nuevos hechos que se añaden a la base de datos)
3. Si se llega al objetivo, se ha resuelto el problema; en caso contrario, se vuelve al paso 1
A este enfoque se le llama también guiado por datos, porque es el estado de la base de datos el que identifica las reglas que se pueden aplicar. Cuando se utiliza este método, el usuario comenzará introduciendo datos del problema en la base de datos del sistema.
Al encadenamiento regresivo se le suele llamar guiado por objetivos, ya que, el sistema comenzará por el objetivo (parte acción de las reglas) y operará retrocediendo para ver cómo se deduce ese objetivo partiendo de los datos. Esto se produce directamente o a través de conclusiones intermedias o subobjetivos. Lo que se intenta es probar una hipótesis a partir de los hechos contenidos en la base de datos y de los obtenidos en el proceso de inferencia.
En la mayoría de los sistemas expertos se utiliza el encadenamiento regresivo. Este enfoque tiene la ventaja de que el sistema va a considerar únicamente las reglas que interesan al problema en cuestión. El usuario comenzará declarando una expresión E y el objetivo del sistema será establecer la verdad de esa expresión.
Para ello se pueden seguir los siguientes pasos:
1. Obtener las reglas relevantes, buscando la expresión E en la parte acción (éstas serán las que puedan establecer la verdad de E)
2. Si no se encuentran reglas para aplicar, entonces no se tienen datos suficientes para resolver el problema; se termina sin éxito o se piden al usuario más datos
3. Si hay reglas para aplicar, se elige una y se verifica su parte condición C con respecto a la base de datos.
4. Si C es verdadera en la base de datos, se establece la veracidad de la expresión E y se resuelve el problema
5. Si C es falsa, se descarta la regla en curso y se selecciona otra regla
6. Si C es desconocida en la base de datos (es decir, no es verdadera ni falsa), se le considera como subobjetivo y se vuelve al paso 1 (C será ahora la expresión E)
Existen también enfoques mixtos en los que se combinan los métodos guiados por datos con los guiados por objetivos.
El interfaz de usuario permite que el usuario pueda describir el problema al sistema experto. Interpreta sus preguntas, los comandos y la información ofrecida. A la inversa, formula la información generada por el sistema incluyendo respuestas a las preguntas, explicaciones y justificaciones. Es decir, posibilita que la respuesta proporcionada por el sistema sea inteligible para el interesado. También puede solicitar más información si le es necesaria al sistema experto. En algunos sistemas se utilizan técnicas de tratamiento del lenguaje natural para mejorar la comunicación entre el usuario y el sistema experto.
La mayoría de los sistemas expertos contienen un módulo de explicación, diseñado para aclarar al usuario la línea de razonamiento seguida en el proceso de inferencia. Si el usuario pregunta al sistema cómo ha alcanzado una conclusión, éste le presentará la secuencia completa de reglas usada. Esta posibilidad de explicación es especialmente valiosa cuando se tiene la necesidad de tomar decisiones importantes amparándose en el consejo del sistema experto. Además, de esta forma, y con el tiempo suficiente, los usuarios pueden convertirse en especialistas en la materia, al asimilar el proceso de razonamiento seguido por el sistema. El subsistema de explicación también puede usarse para depurar el sistema experto durante su desarrollo.
El módulo de adquisición del conocimiento permite que se puedan añadir, eliminar o modificar elementos de conocimiento (en la mayoría de los casos reglas) en el sistema experto. Si el entorno es dinámico es muy necesario, puesto que, el sistema funcionará correctamente sólo si se mantiene actualizado su conocimiento. El módulo de adquisición permite efectuar ese mantenimiento, anotando en la base de conocimientos los cambios que se producen.
Ejemplo de funcionamiento del motor de inferencia
Para ilustrar cómo trabajan los procedimientos de inferencia, se supondrá un sistema que contiene las siguientes reglas en la base de conocimiento:
R1:
SI abrigo ENTONCES bingo
R2: SI chaqueta ENTONCES dentista
R3: SI bingo
ENTONCES esposa
-Enfoque guiado por datos (o encadenamiento hacia adelante):
El
problema es determinar si se da esposa sabiendo que se cumplen abrigo y
chaqueta.
Lo primero que se hace es introducir en la base de datos abrigo y chaqueta:
B.D. = {abrigo, chaqueta}
El sistema identifica las reglas aplicables:
R = {R1, R2}
Selecciona R1 y la aplica. Esto genera bingo que se añade a la base de datos:
B.D. = {abrigo, chaqueta, bingo}
Como no se ha solucionado el problema, vuelve a identificar un conjunto de reglas aplicables (excepto la ya aplicada, que no cambiaría el estado de la base de datos):
R = {R2, R3}
Selecciona y aplica R2 quedando:
B.D. = {abrigo, chaqueta, bingo, dentista}
El problema todavía no se ha solucionado, luego el sistema selecciona otro conjunto de reglas aplicables:
R = {R3}
Seleccionando y aplicando R3, la base de datos queda:
B.D. = {abrigo, chaqueta, bingo, dentista, esposa}
Como esposa se encuentra en ella, se ha llegado a la solución del problema.
-Enfoque guiado por objetivos (o encadenamiento hacia atrás):
Se quiere determinar si se cumple esposa teniendo en la base de datos abrigo y chaqueta:
B.D. = {abrigo, chaqueta}.
El conjunto de reglas aplicables en este caso será:
R = {R3} (R3 es la única que tiene esposa en su parte derecha).
Se selecciona R3 y se genera bingo. Como no se encuentra en la base de datos ( no es verdadero ni falso) se le considera como subobjetivo.
El sistema intentará ahora probar bingo.
Identifica las reglas aplicables:
R = {R1}.
Aplica R1 y se obtiene abrigo que es verdadero en la base de datos. De esta forma, se prueba el subobjetivo, y al probar éste, se prueba esposa resolviendo el problema.
<--Volver al Indice del
trabajo