``Vegetation is known to be closely correlated with the enviroment (including past enviroment), and a vegetational space is required that, in contrast to species-dimensional space, reflects directly the enviromental space.
[...]
Althought individual species do not relate linearly with the enviroment, it might be supposed that some measure of overall vegetational difference between samples might do so. The dimensions of such a vegetational space will be then determined by vectors of vegetational change from point to point (i.e.: from sample to sample)''
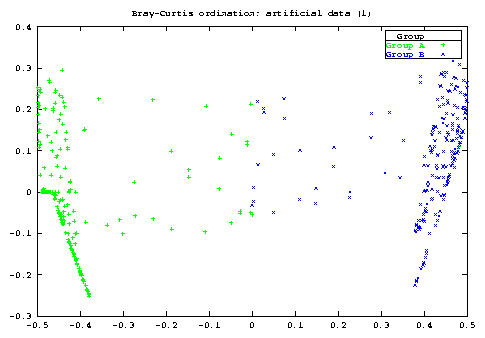
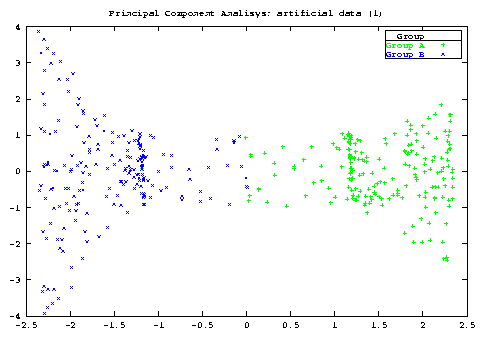
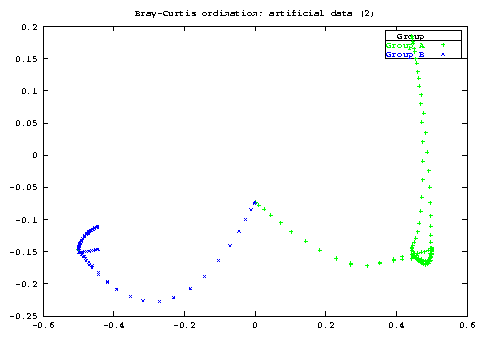
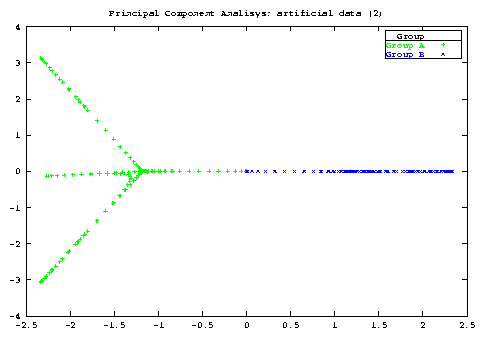
The model implied by Bray and Curtis ([3]) was nearly the same, and, it is much a better model than that implied by Euclidean distance, where each species is considered as an axis perpendicular to each other. The accent on Euclidean distance is dictated by the role it has in PCA (recall the equivalence of Principal Coordinate Analysis with Euclidean distance and PCA).
Major faults in BC ordination seem to be the methods originally developed to select reference points for the construction of axes.
Beals, however, describe a robust method to select such points, and the implementatio follows his description.
A file, containing a series of numbers is given you as a present; it looks like this:
where o-c-i stands for optional-column-identifier.
Assume also that that fine missing is absent from our data.
The general idea is that each observation/row (for our question: each site) belongs to a space each variable/column (for our question: each species) is an axis of2.
Such idea bring us to search for meaningfull directions in this space, where meaningfullness is not necessarly mathematical or geometrical. Each method search for direction in a different way.
Ok, let's search.
First of all, a distance matrix is computed from the data given as input.
Beals strongly recommend to use Sorensen distance and so do I. I've added an option for Euclidean distance.
Here the formula (xhj is the number of individuals for the j-th specie in the h-th site):
Sorensen Distance is a `City-Block metric' (also know as Canberra metric) it is computed thinking at the space as a city (think at Manhattan, where, to go from here to there you can follow only perpendicular roads); in this space each dimension (i.e.: each species), contribute to the overall distance in proportion to their relative differences in the two samples. Quoting Beals:
``This necessarly weights an enviromental factor according to the number of species responding to it, as well as to how dramatically they respond.''
Beals suggests to standardize data before computing distance. I've set some standardization avaiable from SBRACO, but my experience is that no-standarization works fine in most cases.
Ok, this is the first step. Now take this beautiful square matrix and search the site (i.e.: the column or the row of this distance matrix) whose distances show the higest variance. Found ? Ok, keep it. Now search, between the remaining sites, the one whose distance show the lower linear regression coefficient with the distance of the first point3. Found it ? Ok, you have the second reference point for the first axis.
With this searching algorithm we try to extract a gradient at a time and so we should be able to examine complex-shaped enviromental gradients from the coordinates we are going to compute.
Now, you can project the i-th sample onto this axis with the following obscure equation:
o-c-i o-c-i o-c-i � o-c-i
optional-row-identifier 0 1 � � 123
optional-row-identifier 0 31 � � 10
� � � � � �
optional-row-identifier 0 1 � � missing
optional-row-identifier 32 231 � � 2
1.2 What to do...
Ordination techniques are multivariate in nature: the information coded in more1 than one variable is used to explore the data for groupings, regular patterns, relationships, indipendencies and so on. Also, some kind of data reduction is searched for. This allows graphical inspection of data and, hopefully, an improved knowledge on the content of the answer we have been invited to to give in 1.1.
1.3 ...and how
Here I only try to explain how BC ordination (best: BC ordination as actually implemented in SBRACO) search.
Dhi =
�
j
| xhj - xij|
�
j
xhj +
�
j
xij
Dhi =
�
�
�
j
(xhj -xij)2
|
| (1) |
We have n numbers and we can do anything with them. We only want to plot them, so it would be fine to have another axis.
Take a coffee or a tea or an italian wine (also think at how much povetry coffee and tea have brought in the southern parts of the world). Then keep on reading.
In order to compute following axes we try to remove the distance accounted by previous axes from the original distance matrix, i.e., we try to construct a residual distance matrix4.
So we use the following equation to ideally-compute a second distance matrix on the axis already computed5 with elements:
|
Ok, from now on it is a matter of looping for how many axes you choose and subtracting a matrix from another. The loop stop (hopefully) if the reference points are too close (or the denominator in (1) will be zero !).
On output you'll have the coordinates of each sample for each of the axis SBRACO had been able to compute and store.
This method of searching is called Variance-Regression by Beals and is the only one actually implemented as it seems to me the most robust of all (Beals recomends it too).
The user interface was written with JPTUI, a freeware library in C++ written by Jeepy ( www.teaser.fr/~jpdelprat ).
If you like the program and have some money, fund one of this two project or buy some roses to your love, as you prefer.
My experience with it ranges from an 80486 with 8Mb RAM, MS-DOS, to a P200MMX with 80Mb RAM, Windows NT 4.0. The first machine will work out a file with 800 samples and 102 species in ... I don't remeber, say 5 minutes (the time necessary to disk swapping is very long, with more RAM you can get it faster). On a 64Mb machine with Windows NT I manage to run an ordination of 2758 samples, 18 variables.
Away from tecnhical information remember that you have to provide to SBRACO a DPMI program. It is infact distribuited with a DPMI server called CWSDPMI.EXE for use under DOS. If you use Windows or a DOS emulator such as linux DOS-EMU, you'll needn't it, but put it somewhere in your PATH (please refer to DOS documentation about it) or simply put it in the same directory if you are using DOS. DJGPP programs are smart enough to use long names where they can, i.e. under Windows 95 (not under Windows NT).
As you will see there are other distances I've played with in the past (Jaccard, Morosita, Horn) but they all perform bad for me. Also, for binary data, Sorensen distance works fine. I decided to disable them, for the moment.
The program provides you a little editor in main window. Actually it can display only 255 columns, but it can read file of any size (provide it founds enough memory).
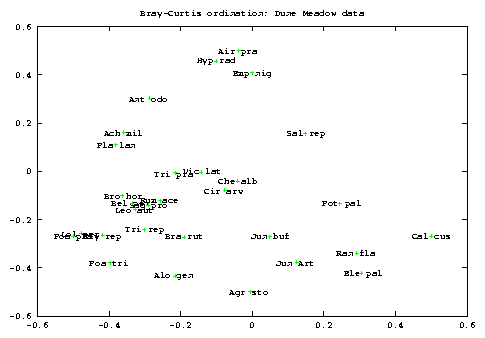
You can ask to order column or rows of the data provided. Don't use BC ordination to ordinate species. Even if some graphs seem very beautiful, I have tried with the Dune Meadow data of [4] and I found that it gives bad results for species. [2] suggests a different approach for species-ordination, but I haven't implemented it, yet. This option is only provided to avoid you the job of trasposing file coded with species as rows ( ;-)).
Of course you may use your favourite graphing software.
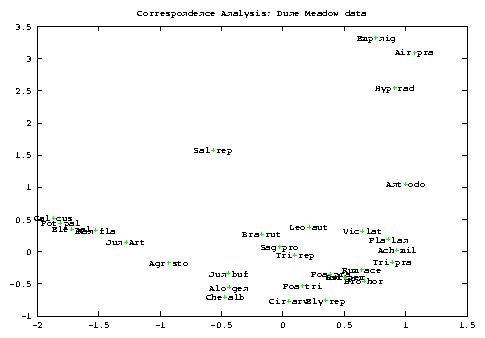
As a general point, if you want to study both row and column at the same time then Correspondence Analysis is much better. I recomend to try BC ordination if you cannot uncover any gradient in your data by means of PCA, CA or any other method. Maybe it will help ..., maybe not. I don't include graphs here but you should be able to see from the file meadow.dat that the ordination of sites are instead very similar for BC and CA (notice that the sites are, here, the column).
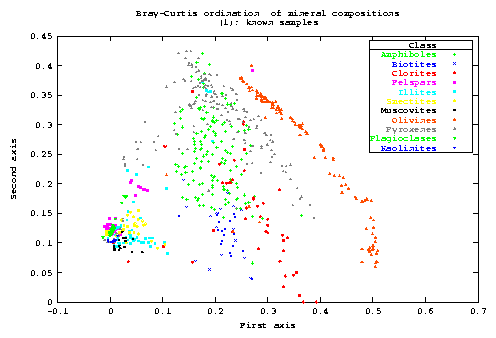
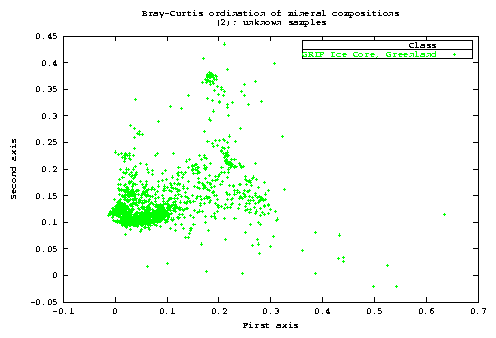
I used it to check if they can be thought as coming from the same region of compositional space. Also it serves as a well know dataset to test the program and the method7.
1 in ecology this seems more like a more
2 In the case of an ecological survey, we have already pointed out the fact that the description and the coding of this space could be critical.
3 I refer to the term b in the equation: first = a+b(second)
4 Here Beals promised to give a formula to compute residual for `city-block', but he did ? (Let me know if you have it !).
5 It is a waste of memory to have two matrix allocated and it is EXACTLY what SBRACO actually does. The developement stopped as I realized to have to rewrite all the low-level function for data management and storage. Future version will use a quarter of the memory needed now. It allows also to add other analysis (PCA, COA, ...)
6 It is not directly related to it, I guess.
7 SBRACO allocated about 140Mb for this run.