Summary:
Throughout the electronic computer's short history, the evolution of the user interface has roughly paralleled the industry's other advances and expansions. Today the GUI is standard, but still less than ideal. The next logical step is a spoken-natural-language-controlled user interface, certain building blocks of which have already been built. Still, existing software has not come close to conquering certain barriers.
This project proposes to explore and attempt to conquer some of those barriers. The main emphasis will be on marrying current natural language processing technology and theory to an operating system. Ideally, software running under the operating system will request input from the OS, and receive processed voice input as easily as it can currently receive keyboard input. Since crafting an OS with this in mind is far beyond the scope of this project, I will write a shell to run on top of an existing OS, or modify existing public-domain OS code.
While I have only begun to study natural language processing, I have studied the basic issues within an OS. I believe that my C-HTML and generic parser projects have demonstrated to you that I pursue a project on my own, and, allotted some time, will deliver a good project. I intend to deliver my code and report near the end of the Fall 1999 semester, at about the first week of December.
Introduction:
The problem of controlling an OS by voice may be broken down into several distinct problems, which include speech recognition, natural language parsing, semantics, and integration with an OS. Researchers have studied each of these pieces of the problem, and have begun to put the pieces together in a few applications.
The first piece, the actual speech recognition, is well on its way to reliability. Dragon Systems and IBM both have products on the market which use this technology to take dictation. IBM also offers Java source code that interfaces with its product, ViaVoice. This allows developers to write applications which use ViaVoice technology, which, in turn, runs on top of MS Windows.
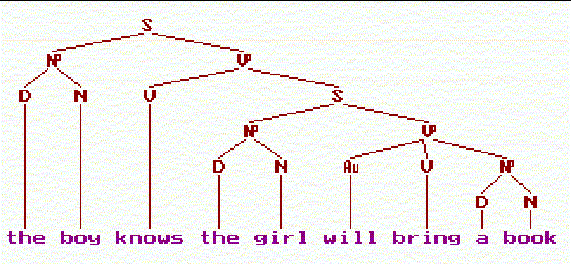
Researchers have been studying natural language parsing (NLP) very seriously. As the parse tree diagramed by software from New York University ("Research") explains, the NLP software must recognize the parts of speech of the words in a sentence.
Complex algorithms, often in Prolog or Lisp, look the words up in a dictionary, and recognize the sentence structure. Dr. Ray Dougherty, a professor in the New York University linguistics department ("Research"), is also working on combining speech recognition with NLP. He illustrates the process with Figure 2.
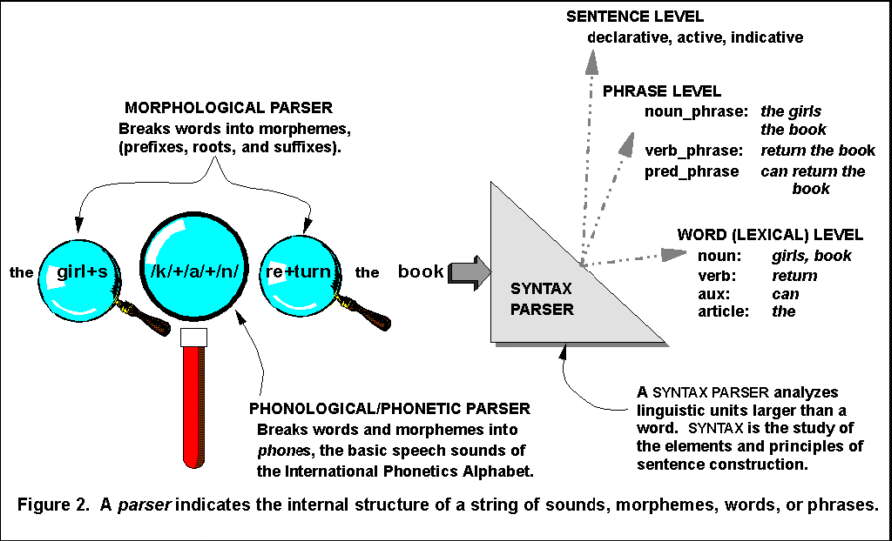
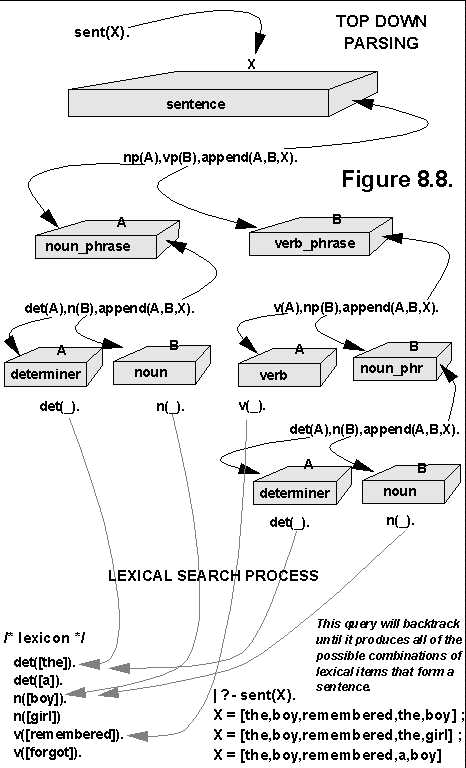
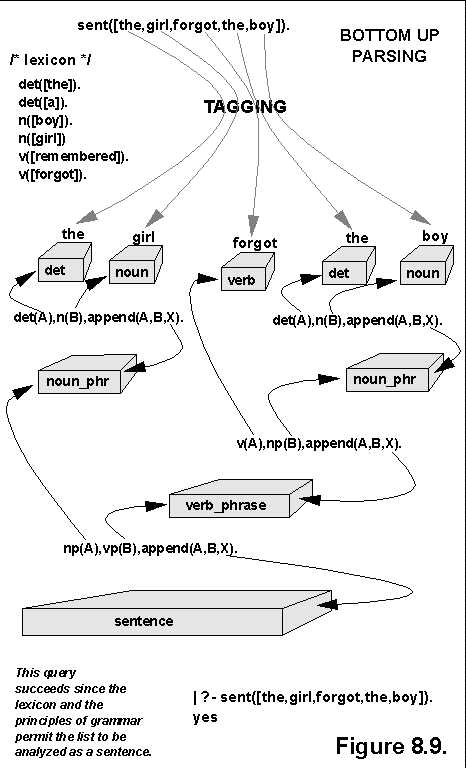
This view leaves the syntax parser a "black box", an item whose input and output are visible, but whose inner workings are not. He goes on to explain and illustrate two different basic methods of parsing. Top-down parsing, illustrated in Figure 3 begins with the concept of a sentence, and works down to the individual words. On the contrary, bottom-up parsing, illustrated in Figure 4 views all the words, and assembles them into phrases and finally sentences.
This parsing is similar in many ways to the parsing of context-free grammars, which has been automated for a couple decades now. It is, of course, more complex, in that more sentence structures are possible and each sentence may relate to a previous sentence. But the concept is similar, and researchers have made good progress with it.
After the computer has determined the sentence structure, it can begin to determine the semantics, or meaning of the sentence. Certain words will be more important to controlling a computer than others. Verbs will probably be the deciding factors, with linguistic "artifacts", such as "wow" and "well " omitted. This is important, because no one wants to speak DOS or UNIX commands. The user wants to say "show me the details on all the files in the directory", not "ls -a -l." This issue of semantics deals with this kind of translation process, which leads to the final topic, integration with an OS.
The ideal program would be a part of the OS and allow applications to receive input from the NLP system or the keyboard with a simple query of the OS. For this project, the options are either inserting a call to an NLP system in a public-domain OS, such as Linux, or building a shell that would run on top of either Linux or Windows and execute system commands. The latter solution probably would not allow applications to get their input from the NLP system, unless they were written with that in mind. I will detail the proposed processes for each of these methods later in the proposal.
Procedure:
I propose to study and integrate four distinct technologies in this project. The tools, source code, and research available will determine the platform on which I will implement the project. The four fields are:
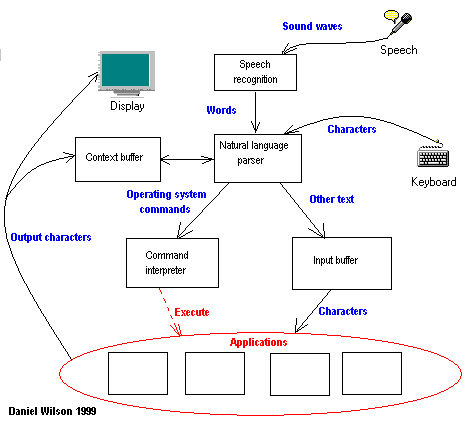
Figure 5 illustrates the basic architecture.
Speech Recognition -- turning sound waves into words
The Speech Recognition (SR) unit will take sound from the microphone via the sound driver. It will output the words as ASCII strings. The unit will have a command-line flag that will dump its output to the screen. This screen dump will allow me to analyze the unit's accuracy, and will mark the completion of the SR unit.
The commercial success that Dragon Systems, IBM, Creator Ltd. and some others are realizing in this field is both an encouragement and a liability. It is encouraging, in that it proves that the theory and technology to reliably turn sound waves into ASCII strings are quickly maturing.
The liability is that free source code and tools are hard to find. This is not a field which universities seem to be studying a whole lot, or at least, not publishing lots of results. This is one big reason for developing for a Windows platform.
The tools I have found for microcomputers are almost exclusively Windows-based. IBM has a package of JAVA classes for developers to use. Its purpose is to allow developers to put ViaVoice technology to work in their own applications ("IBM"). Each end user must have ViaVoice, which, naturally enough, runs on top of Windows. Similarly, Microsoft offers MSAgent and TruVoice, a set of Windows utilities("Web Workshop"). I am not yet sure if these are stand-alone applications, or if developers can easily integrate with them.
Creator Ltd. offers a package of development software to create Living Objects ("Creator"). These Living Objects are toys or appliances that respond to human speech. The Living Objects do not have true NLP capabilities, however, for "at this point, the technology allows use of single words and word clusters("Creator")." Its speech generation is actually just selecting a WAV file to play, but it claims to sound like natural speech. Creators software interfaces with its own hardware controllers. It is not designed to write software for microcomputers. Thus, while this is another example of the technologys success, it is not helpful for this project.
Natural Language Parsing
The Natural Language Parsing (NLP) unit will take words and construct them into sentences. It's input will come from the SR unit, but for testing purposes it will allow input from an ASCII file. Its output will be a parse tree, something like that diagrammed in Figure 1. A command-line parameter will tell the unit to print the tree in some meaningful text format. When spoken input is reliably parsed, this unit is complete.
Dr. Ray Dougherty at New York University ("Research") as well as researchers at MIT and Carnegie-Mellon have published theory, programs, and source code for this part of the project. Dr. Dougherty's source code that is to accompany his book, Natural Language Computing: An English Generative Grammar in Prolog, is available on the Internet, as are the Prolog compilers to compile it. The Prolog compilers are available for both Windows and UNIX platforms, so that should not be a constraining factor.
Semantic Analysis/Parsing
In this phase of the project, I will determine which words are important, which are extraneous, and which are secondary. If the input is a command to the operating system, I will also translate it into the appropriate system call or OS command. This is one of the pieces that really needs some intelligence.
The Semantic Analysis unit will take a parse tree as its input. Once again, this will ultimately come from the previous unit, but may be loaded directly from a file for testing purposes. Its output, in the case of OS commands, will be those commands, translated for the particular OS for which I design this software. In the case of dictation, it will be a simple text dump.
One very interesting project that deals with both this and NLP is Brainhat ("Brainhat"). Brainhat operates on a tree structure of words. It knows certain words as nouns, others as verbs, and others as adjectives. All nouns descend or inherit from one or more other nouns, and eventually from "thing". Verbs, adjectives, and prepositions do likewise. Brainhat recognizes certain sentence structures, and can parse a sentence made of words it knows. The user can tell Brainhat facts, by typing simple English sentences. He can then query Brainhat, again using simple English. Brainhat can correctly answer questions dealing with the facts it has been given, as well as things that those facts imply. It can give answers that use basic Modus Ponens and Modus Tollens logic. Interestingly enough, Brainhat is not written in a procedural language or a language typically used for AI. Rather, it is written in C and runs under Unix. As such, it can be ported to any operating system.
Intelligence similar to Brainhats should drive my command shell. Mere dictation, obviously, does not need this kind of intelligence. But switching between dictation mode and command mode will need some intelligence. I will probably set my software to recognize certain words while dictating, to go back into command mode. Those words could be preceded with some "escape sequence" of words if returning to the command mode was not what was desired. Ideally, the computer would not need these verbal cues. Humans would recognize the change in tone of voice, but that is really far beyond the scope of this project.
Operating System Integration
Since writing a new operating system with voice control in mind is beyond the scope of a semester project, I will integrate my package with an existing OS.
I see two possible ways to implement the architecture I illustrated in Figure 5.
As I already indicated, I intend to turn in the final version of my
software and code the first week of December. Along with it, I will turn
in a report detailing the things the software does and does not do. I will
explain the precise procedure I followed, and the challenges encountered.
In order to ensure that I don't get behind, I will set the following schedule.
| September 3: | Project Starts |
| September 17: | SR unit written |
| October 8: | NLP unit written and integrated with SR |
| October 22: | Semantic analysis unit written and integrated |
| November 12: | OS integration |
| December 3: | Final deliverable |
Works Cited:
"Brainhat." The Brainhat Project. Dowd, Kevin. February 19,1999. <http://www.brainhat.com/>.
"Creator." Creator Ltd. Website. Creator Ltd. March 22,1999. <www.creator.co.il>.
"Research in Natural Language Computing." New York University Website. Dougherty, Dr. Ray. February 1, 1999. <http://www.nyu.edu/linguistics/ling.html>. As of October 8, 1999, the site is <http://www.nyu.edu/pages/linguistics/>.
"Web Workshop Microsoft Agent Downloads." Microsoft Developers Network. Microsoft Corp. February 30, 1999. <http://msdn.microsoft.com/msagent/agentdl.asp#sr>.