
UNIVERSIDAD YACAMBU
MINISTERIO DE
EDUCACION
DIRECCION DE
INVESTIGACION Y POSTGRADOS VIRTUALES
GERENCIA EN SISTEMAS
DE INFORMACION
Trabajo 7
Asignatura: Análisis y
Diseño de Sistemas
Integrante: Pérez Isilrobert José
Ochoa Feliana
Administración de
Bases de Datos
Introducción
Un sistema
de bases de
datos es básicamente un sistema computarizado para llevar registros,
es un depósito o contenedor de una colección de archivos
de datos
computarizados. Los usuarios del sistema pueden agregar nuevos archivos,
insertar, recuperar, modificar, eliminar datos dentro de estos archivos y
eliminar los archivos existentes dentro de la base de datos.
Administración de
Bases de Datos
1.- ¿Qué es un Sistema de Base de Datos?
Es un sistema computarizado cuya finalidad general es almacenar información y permitir a los usuarios recuperar y actualizar esa información con base en peticiones. Esta información puede ser cualquier cosa que sea de importancia para el individuo o la organización; es decir, todo lo que sea necesario para auxiliarle en el proceso general de su administración.
Un sistema de bases de datos comprende cuatro componentes principales: datos, hardware, software y usuarios.
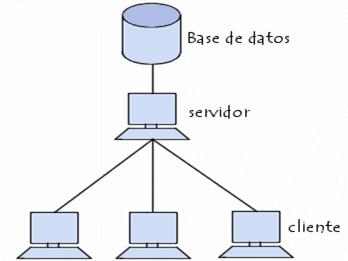
Los sistemas de bases de datos están disponibles en máquinas que van desde las computadoras personales más pequeñas hasta las mainfram es más grandes. En particular, los sistemas que se encuentran en máquinas grandes (sistemas grandes) tienden a ser multiusuario, mientras que los que se ejecutan en máquinas pequeñas (sistemas pequeños) tienden a ser de un solo usuario. Un sistema de un solo usuario es aquel en el que sólo un usuario puede tener acceso a la base de datos en un momento dado; un sistema multiusuario es aquel en el cual múltiples usuarios pueden tener acceso simultáneo a la base de datos.
En general, los datos de la base de datos, al menos en los sistemas grandes, serán tanto integrados como compartidos. Integrado se refiere a una unificación de varios archivos que de otro modo serían distintos, con una redundancia entre ellos eliminada al menos parcialmente. Compartido por que las piezas individuales de datos en la base pueden ser compartidas entre diferentes usuarios y que cada uno de ellos puede tener acceso a la misma pieza de datos, probablemente con fines diferentes. Distintos usuarios pueden en efecto acceder a la misma pieza de datos al mismo tiempo, lo que se conoce como acceso concurrente. Este comportamiento, concurrente o no, es en parte consecuencia del hecho de que la base de datos está integrada. Si la base de datos no es compartida, se le conoce como personal o como específica de la aplicación.
Que la base de datos sea integrada y compartida significa que cualquier usuario ocupará normalmente sólo una pequeña parte de la base de datos total; lo que es más, las partes de los distintos usuarios se traslaparán de diversas formas. En otras palabras, una determinada base de datos será percibida de muchas formas diferentes por los distintos usuarios. De hecho, aun cuando dos usuarios tengan la misma porción de la base de datos, su visión de dicha parte podría diferir considerablemente a un nivel detallado.
Los componentes de hardware del sistema constan de:
o Los volúmenes de almacenamiento secundario, como discos magnéticos, que se emplean para contener los datos almacenados, junto con dispositivos asociados de E/S, los controladores de dispositivos, los canales de E/S, entre otros.
o Los procesadores de hardware y la memoria principal asociada usados para apoyarla ejecución del software del sistema de base de datos.
El administrador de base de datos o servidor de base de datos conocido como sistema de administración de base de datos (DBMS) maneja todas las solicitudes de acceso a la base de datos ya sea para agregar y eliminar archivos, recuperar y almacenar datos desde y en dichos archivos. Por lo tanto, una función general que ofrece el DBMS consiste en ocultar a los usuarios de la base de datos los detalles al nivel de hardware. Es decir, que el DBMS ofrece a los usuarios una percepción de la base de datos que está en cierto modo, por encima del nivel del hardware y que maneja las operaciones del usuario expresadas en términos de ese nivel más alto de percepción.
El DBMS es el componente de software más importante del sistema en general, aunque no es el único.
Usuarios
Existen tres grandes clases de usuarios:
· Programadores de aplicaciones, que son los responsables de escribir los programas de aplicación de base de datos en algún lenguaje de programación. Estos programas acceden a la base de datos emitiendo la solicitud apropiada al DBMS. Los programas en sí pueden ser aplicaciones convencionales por lotes o pueden ser aplicaciones en línea, cuyo propósito es permitir al usuario final el acceso a la base de datos desde una estación de trabajo o terminal en línea.
· Los usuarios finales, quienes interactúan con el sistema desde estaciones de trabajo o terminales en línea. Un usuario final puede acceder a la base de datos a través de las aplicaciones en línea, o bien puede usar una interfaz proporcionada como parte integral del software del sistema de base de datos. Las interfaces proporcionadas por el fabricante están apoyadas también por aplicaciones en línea, aunque esas aplicaciones están integradas, es decir, no son escritas por el usuario. La mayoría de los sistemas de base de datos incluyen por lo menos una de estas aplicaciones integradas.
· La mayoría de los sistemas proporcionan además interfaces integradas adicionales en las que los usuarios no emiten en absoluto solicitudes explícitas a la base de datos, sino que en vez de ello operan mediante la selección de elementos en un menú o llenando casillas de un formulario. Estas interfaces controladas por menús o por formularios tienden a facilitar el uso a personas que no cuentan con una capacitación formal en tecnología de la información (IT). En contraste, las interfaces controladas por comandos tienden a requerir cierta experiencia profesional en IT, aunque tal vez no demasiada. Por otra parte, es probable que una interfaz controlada por comandos sea más flexible que una controlada por menús o por formularios, dado que los lenguajes de consulta por lo regular incluyen ciertas características que no manejan esas otras interfaces.
· El administrador de base de datos o DBA.
Una base de datos (cuya abreviatura es BD) es una entidad en la cual se pueden almacenar datos de manera estructurada, con la menor redundancia posible. Diferentes programas y diferentes usuarios deben poder utilizar estos datos. Por lo tanto, el concepto de base de datos generalmente está relacionado con el de red ya que se debe poder compartir esta información. De allí el término base. "Sistema de información" es el término general utilizado para la estructura global que incluye todos los mecanismos para compartir datos que se han instalado.
Datos
Persistentes
Es una costumbre referirse a los datos de la base de datos como persistentes, esto se refiere de manera intuitiva, que el tipo de datos de la base de datos difiere de otros datos más efímeros. En forma más precisa, se dice que los datos de la base de datos persisten debido a que una vez aceptados por el DBMS para entrar en la base de datos, en lo sucesivo sólo pueden ser removidos de la base de datos por alguna solicitud explícita al DBMS, no como un mero efecto lateral de algún programa que termina su ejecución. Por lo tanto, esta noción de persistencia permite dar una definición más precisa del término base de datos:
Una base de datos es un conjunto de datos persistentes que es utilizado por los sistemas de aplicación de alguna empresa dada.
Hoy en día las bases de datos se utilizan cada vez más también para otro tipo de aplicaciones. De hecho, las empresas mantienen generalmente dos bases de datos independientes; una que contiene los datos operacionales y otra, a la que con frecuencia se le llama almacén de datos, que contiene datos de apoyo para la toma de decisiones. A menudo el almacén de datos incluye información de resumen, la que a su vez se extrae periódicamente de la base de datos operacional.
Entidades
y Vínculos
El término entidad es empleado comúnmente en los círculos de bases de datos para referirse a cualquier objeto distinguible que va a ser representado en la base de datos.
Además de las propias entidades básicas habrá también vínculos que asocian dichas entidades básicas. El punto importante con respecto a los vínculos es que son parte de los datos tanto como lo son las entidades básicas. Por lo tanto, deben estar representados en la base de datos al igual que las entidades básicas.
Ambos son utilizados en la elaboración de los diagramas entidad/vínculo o entidad/relación (E/R), que son usados frecuentemente por los diseñadores para ayudar a modelar la base de datos.
Dentro de un diagrama E/R cada vínculo puede relacionarse con una o más de una entidad. Los vínculos que comprenden dos tipos de entidad son vínculos binarios, mientras los que se involucran con tres tipos de entidad se conocen como vínculos ternarios. Los vínculos que se relacionan con una sola entidad siguen siendo binarios, solo que los dos tipos de entidad que están vinculados vienen a ser la misma entidad.
En ocasiones surgen falsas inferencias que pueden causar mal interpretación y vínculos incorrectos entre las entidades, a lo que se le denomina trampa de conexión.
En general, un conjunto determinado de tipos de entidad podría vincularse entre sí en cualquier cantidad de vínculos distintos.
Si una entidad es cualquier objeto acerca del cual se quiere registrar información, entonces un vínculo se ajusta perfectamente a la definición. Por lo que un vínculo puede considerarse como una entidad por derecho propio.
Propiedades
Las entidades, incluyendo los vínculos, poseen propiedades que corresponden a la información que se desea registrar sobre ellas. Por lo tanto dichas propiedades deben estar representadas en la base de datos.
En general, las propiedades pueden ser tan simples o complejas como sea necesario. Cuando las propiedades son simples, se pueden ser representadas mediante tipos de datos simples, incluyendo números, cadenas de caracteres, fechas, horas, etcétera. En contraste, existen propiedades complejas como el dibujo arquitectónico y el texto descriptivo asociado.
Datos y Modelos
de Datos
Los datos en realidad son hechos dados, a partir de los cuales es posible inferir hechos adicionales. Esto es exactamente lo que hace el DBMS cuando responde a una consulta de un usuario. Un hecho dado corresponde a su vez a lo que en lógica se denomina proposición verdadera. En base a esto, una base de datos es en realidad una colección de tales proposiciones verdaderas.
Una razón por la que los sistemas de bases de datos relacionales se han vuelto tan dominantes, es que manejan en forma muy directa la interpretación precedente de los datos. Los sistemas relacionales están basados en una teoría formal denominada el modelo de datos relacional, de acuerdo con el cual:
· En tablas, los datos son representados por medio de filas, las que pueden interpretarse directamente como proposiciones verdaderas.
· Se proporcionan operadores para operar sobre las columnas de las tablas, y estos operadores soportan directamente el proceso de inferir proposiciones verdaderas adicionales a partir de las ya dadas.
Sin embargo, el modelo relacional no es el único modelo de datos. Existen otros aunque la mayoría de ellos difieren del modelo relacional en que son hasta cierto grado específicos, en vez de estar basados firmemente en la lógica formal.
Un modelo de datos es una definición lógica, independiente y abstracta de los objetos, operadores y demás que en conjunto constituyen la máquina abstracta con la que interactúan los usuarios. Los objetos permiten modelar la estructura de los datos. Los operadores permiten modelar su comportamiento.
La implementación de determinado modelo de datos es una realización física, en una máquina real, de los componentes de la máquina abstracta que en conjunto constituyen ese modelo.
Entonces, se puede decir que el modelo es aquello que los usuarios tienen que conocer, y la implementación es lo que los usuarios no tienen que conocer. La distinción entre ambos es en realidad sólo un caso de la conocida distinción entre lógico y físico.
Aunque el término modelo de datos es utilizado con dos significados muy distintos, la diferencia entre ambos puede ser caracterizada de esta manera:
· En el primer sentido, un modelo de datos es como un lenguaje de programación cuyos elementos pueden ser usados para resolver una amplia variedad de problemas específicos, pero que en sí y por sí mismos no tienen una conexión directa con ninguno de estos problemas específicos.
· En el segundo sentido, un modelo de datos es como un programa específico escrito en ese lenguaje. En decir, un modelo de datos que toma las características que ofrece algún modelo como el primero y las aplica a cierto problema específico. Puede ser visto como una aplicación específica de algún modelo con el primer significado.
2.- ¿Por qué una Base de Datos?
Algunas ventajas que proporciona el uso de un sistema de base de datos sobre los métodos tradicionales son:
· Compactación: Reduce la necesidad de archivos voluminosos en papel.
· Velocidad: La máquina puede recuperar y actualizar datos más rápidamente que un humano. En particular, las consultas específicas sin mucha elaboración pueden ser respondidas con rapidez, sin necesidad de búsquedas manuales o visuales que llevan tiempo.
· Menos trabajo laborioso: Se puede eliminar gran parte del trabajo de llevar a los archivos a mano.
· Actualidad: En el momento que se necesite, se tiene a disposición información precisa y actualizada.
Desde luego, estos beneficios se aplican aún con más fuerza en un entorno multiusuario, donde es probable que la base de datos sea mucho más grande y compleja que en el caso de un solo usuario. No obstante, en el entorno multiusuario hay una ventaja adicional: El sistema de base de datos ofrece a la empresa un control centralizado de sus datos.
3.- Administración de datos y administración
de bases de datos
El administrador de datos (DA) es la persona identificable que tendrá la responsabilidad central sobre los datos dentro de la empresa. Ya que los datos son uno de los activos más valiosos de la empresa, es imperativo que exista una persona que los entienda junto con las necesidades de la empresa con respecto a esos datos, a un nivel de administración superior. Por lo tanto, es labor del administrador decidir en primer lugar qué datos deben ser almacenados en la base de datos y establecer políticaspara mantener y manejar esos datos una vez almacenados.
El administrador de base de datos (DBA) es el técnico responsable de implementar las decisiones del administrador de datos. Por lo tanto, debe ser un profesional en IT. El trabajo del DBA consiste en crear la base de datos real e implementar los controles técnicos necesarios para hacer cumplir las diversas decisiones de las políticas hechas por el DA. El DBA también es responsable de asegurar que el sistema opere con el rendimiento adecuado y de proporcionar una variedad de otros servicios técnicos.
Rápidamente surgió la necesidad de contar con un sistema de administración para controlar tanto los datos como los usuarios. La administración de bases de datos se realiza con un sistema llamado DBMS (Database management system [Sistema de administración de bases de datos]). El DBMS es un conjunto de servicios (aplicaciones de software) para administrar bases de datos, que permite:
· un fácil acceso a los datos
· el acceso a la información por parte de múltiples usuarios
·
 la
manipulación de los datos encontrados en la base de datos (insertar, eliminar,
editar)
la
manipulación de los datos encontrados en la base de datos (insertar, eliminar,
editar)
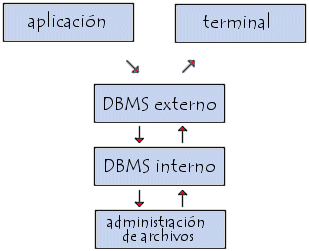
El DBMS puede dividirse en tres subsistemas:
·
El sistema de administración de archivos:
para almacenar información en un medio físico
·
El DBMS interno:
para ubicar la información en orden
·
El DBMS externo:
representa la interfaz del usuario.
Los principales sistemas de administración de bases de datos son:
· IBM DB2
· Ingres
· Oracle
· Sybase
· MySQL
· PostgreSQL
· mSQL
· SQL Server 11
4.- Beneficios del enfoque de base de
datos
· Los datos pueden compartirse
Compartir no solo significa que las aplicaciones existentes puedan compartir la información de la base de datos, sino también que sea posible desarrollar nuevas aplicaciones para operar sobre los mismos datos. Es decir, que sea posible satisfacer los requerimientos de datos de aplicaciones nuevas sin tener que agregar información a la base de datos.
· Es posible reducir la redundancia
En sistemas que no son de bases de datos, cada aplicación tiene sus propios archivos exclusivos. A menudo este hecho puede conducir a una redundancia considerable de los datos almacenados, con el consecuente desperdicio de espacio de almacenamiento. Esto no significa que toda la redundancia puede o debe necesariamente ser eliminada. Sin embargo, sí debe ser controlada cuidadosamente.
· Es posible evitar la inconsistencia
En ocasiones en las que las entidades no coincidan; cuando unas de ellas han sido actualizadas y otras no se dice que la base de datos es inconsistente. Si se elimina la redundancia, entonces no puede ocurrir tal inconsistencia. Como alternativa, si no se elimina la redundancia pero se controla entonces se puede garantizar que la base de datos nunca será inconsistente, asegurando que todo cambio realizado a cualquiera de las entidades será aplicado también a las otras en forma automática. A este proceso se le conoce como propagación de actualizaciones.
· Es posible brindar un manejo de transacciones
Una transacción es una unidad de trabajo lógica, que por lo regular comprende varias operaciones de la base de datos, en particular varias operaciones de actualización. Si se necesitan dos actualizaciones y se declara que ambas son parte de la misma transacción, entonces el sistema puede en efecto garantizar que se hagan ya sea ambas o ninguna de ellas, aun cuando el sistema fallará a la mitad del proceso.
· Es posible mantener la integridad
La integridad se refiere a asegurar que los datos de la base de datos estén correctos. La inconsistencia entre dos entradas que pretenden representar el mismo hecho es un ejemplo de la falta de integridad. Desde luego, este problema en particular puede surgir sólo si existe redundancia en los datos almacenados. No obstante, aun cuando no exista redundancia, la base de datos podría seguir conteniendo información incorrecta. El control centralizado de la base de datos puede ayudar a evitar estos problemas permitiendo que el administrador de datos defina y el DBA implemente las restricciones de seguridad que serán verificadas siempre que se realice una operación de actualización.
· Es posible hacer cumplir la seguridad
Al tener la completa jurisdicción sobre la base de datos, el DBA puede, bajo la dirección apropiada del DBA, asegurar que el único medio de acceso a la base de datos sea a través de los canales adecuados y por lo tanto puede definir las reglas o restricciones de seguridad que serán verificadas siempre que se intente acceder a los datos sensibles. Es posible establecer diferentes restricciones para cada tipo de acceso para cada parte de la información de la base de datos. Sin dichas restricciones la seguridad de los datos podría de hecho estar en mayor riesgo que en un sistema de archivos tradicionales. La naturaleza centralizada de un sistema de base de datos requiere, en cierto sentido, que también sea establecido un buen sistema de seguridad.
· Es posible equilibrar los requerimientos en conflicto
Al conocer los requerimientos generales de la empresa, el DBA puede estructurar los sistemas de manera que ofrezcan un servicio general que sea el mejor para la empresa.
· Es posible hacer cumplir los estándares
Con el control central de la base de datos, el DBA puede asegurar que todos los estándares aplicables en la representación de datos sean observados. Es conveniente estandarizar la representación de datos, en particular como un auxiliar para el intercambio de datos o para el movimiento de datos entre sistemas. En forma similar, los estándares en la asignación de nombres y en la documentación de los datos también son muy convenientes como una ayuda para compartir y entender los datos.
5.- La Independencia
de los Datos
Existen dos clases de independencia de los datos, física y lógica.
Los sistemas anteriores a los de base de datos tienden a ser dependientes de los datos. Es decir, la forma en que físicamente son representados los datos en el almacenamiento secundario y la técnica empleada para su acceso, son dictadas por los requerimientos de la aplicación en consideración, significa que el conocimiento de esa representación física y esa técnica empleada para su acceso están integrados dentro del código de la aplicación.
En un sistema de base de datos sería inconveniente permitir que las aplicaciones fuesen dependientes de los datos por las razones siguientes:
· Las distintas aplicaciones requerirán visiones diferentes de los mismos datos.
· El DBA debe tener la libertad de cambiar las representaciones físicas o la técnica de acceso en respuesta a los requerimientos cambiantes, sin tener que modificar las aplicaciones existentes.
La independencia de los datos se puede definir como la inmunidad de las aplicaciones a cambios en la representación física y en la técnica de acceso, lo que implica desde luego que las aplicaciones involucradas no dependen de ninguna representación física o técnica de acceso en particular.
Un campo general es la unidad más pequeña de datos almacenados. La base de datos contendrá muchas ocurrencias o ejemplares de los diversos tipos de campos almacenados.
Un registro almacenado es un conjunto de campos almacenados relacionados. Una ocurrencia de registro almacenado consta de un grupo de ocurrencias de campos almacenados relacionados.
Un archivo almacenado es la colección de todas las ocurrencias existentes actualmente para un tipo de registro almacenado.
En los sistemas que no son de bases de datos, el caso normal es que cualquier registro lógico dado es idéntico a un registro almacenado correspondiente. Sin embargo, éste no es necesariamente el caso en un sistema de base de datos, ya que tal vez el DBA necesita hacer cambios a la representación almacenada de datos aunque los datos, tal y como las aplicaciones los ven, no cambien.
Entre algunos de los aspectos de la representación almacenada que podrían estar sujetos a cambio se encuentran:
o Representación de datos numéricos
Un campo numérico podría estar almacenado en la forma aritmética interna o como una cadena de caracteres. En ambas formas, el DBA debe elegir una base apropiada (binaria o decimal), una escala(flotante o de punto fijo), un modo (real o complejo) y una precisión (el número de dígitos). Podría ser necesario modificar cualquiera de estos aspectos para mejorar el rendimiento, para apegarse a un nuevo estándar o por muchas otras razones.
o Representación de datos de caracteres
Un campo de cadena de caracteres podría ser almacenado mediante cualquiera de los distintos conjuntos de caracteres codificados (ASCII, Unicode).
o Unidades para datos numéricos
Las unidades en un campo numérico podrían cambiar (pulgadas a centímetros).
o Codificación de los datos
En ciertas situaciones podría ser conveniente representar los datos almacenados por medio de valores codificados. Por ejemplo, los colores podrían ser almacenados como un solo digito decimal de acuerdo a un esquema de codificación; 1 = azul, 2 = verde, etc…
o Materialización de los datos
El campo lógico corresponde por lo regular a cierto campo almacenado específico; aunque podría haber diferencias en el tipo de datos, la codificación, etc. En tal caso el proceso de materialización, es decir, la construcción de una ocurrencia del campo lógico a partir de la ocurrencia correspondiente del campo almacenado y presentarla a la aplicación, podría ser considerado como directo. Sin embargo en ocasiones un campo lógico no tendrá una sola contraparte almacenada; en su lugar, sus valores se materializarán por medio de algún cálculo, tal vez sobre varias ocurrencias almacenadas, en este caso el campo sería un campo virtual. Para estos campos el proceso de materialización es indirecto. Sin embargo el usuario podría ver una diferencia entre los campos real y virtual, en tanto que podría no ser posible actualizar una ocurrencia de un campo virtual, al menos no directamente.
o Estructura de los registros almacenados
Dos registros almacenados existentes podrían combinarse en uno. Un cambio así podría ocurrir cuando las aplicaciones existentes están integradas dentro del sistema de base de datos. Lo que implica que el registro lógico de una aplicación podría consistir en un subconjunto propio del registro almacenado correspondiente, es decir, ciertos campos de ese registro almacenado serían invisibles para la aplicación en cuestión.
Como alternativa, un solo tipo de registro almacenado podría ser dividido en dos. Esta separación permitiría que las porciones del registro original utilizadas con menos frecuencia sean almacenadas en un dispositivo más lento. Esto implica que un registro lógico de una aplicación podría contener campos de varios registros almacenados distintos; es decir, podría ser un súper conjunto propio de cualquiera de esos registros almacenados.
o Estructura de los archivos almacenados
Un determinado archivo puede ser implementado físicamente en el almacenamiento en una amplia variedad de formas. Pero ninguna de estas consideraciones deberá afectar de alguna manera a las aplicaciones salvo el rendimiento. Permitir que la base de datos crezca sin dañar de manera lógica las aplicaciones existentes es una de las razones más importantes para requerir, en primer lugar, la independencia de los datos.
6.- Los Sistemas Relacionales y
Otros Sistemas
Un sistema relacional es aquel en el que:
o Los datos son percibidos por el usuario como tablas.
o Los operadores disponibles para el usuario son operadores que generan nuevas tablas a partir de las anteriores.
El usuario de un sistema relacional ve tablas y nada más que tablas. En contraste el usuario de un sistema no relacional ve otras estructurasde datos, ya sea en lugar de las tablas de un sistema relacional o además de ellas. A su vez, esas otras estructuras requieren de otros operadores para manipularlas. En un sistema jerárquico, los datos son representados ante el usuario como un conjunto de estructuras de árbol y los operadores que se proporcionan para manipular dichas estructuras incluyen operadores para apuntadores de recorrido; es decir, los apuntadores que representan las rutas jerárquicas hacia arriba y hacia abajo en los árboles.
Los sistemas de bases de datos pueden de hecho ser divididos convenientemente en categorías de acuerdo con los operadores y estructuras de datos que presentan al usuario. De acuerdo con este esquema, los sistemas más antiguos o prerrelacionales se ubican dentro de tres categorías: los sistemas de listas invertidas, jerárquicos y de red.
El administrador de base de datos (DBA) es la persona responsable de los aspectos ambientales de una base de datos. En general esto incluye:
- Recuperabilidad - Crear y probar Respaldos
- Integridad - Verificar o ayudar a la verificación en la integridad de datos
- Seguridad - Definir y/o implementar controles de acceso a los datos
- Disponibilidad - Asegurarse del mayor tiempo de encendido
- Desempeño - Asegurarse del máximo desempeño incluso con las limitaciones
- Desarrollo y soporte a pruebas - Ayudar a los programadores e ingenieros a utilizar eficientemente la base de datos.
El diseño lógico y físico de las bases de datos a pesar de no ser obligaciones de un administrador de bases de datos, es a veces parte del trabajo. Esas funciones por lo general están asignadas a los analistas de bases de datos ó a los diseñadores de bases de datos.
Recuperación:
Las copias de seguridad son un proceso que se utiliza para salvar toda la información, es decir, un usuario, quiere guardar toda la información, o parte de la información, de la que dispone en el PC hasta este momento, realizará una copia de seguridad de tal manera, que lo almacenará en una cinta, DVD, BluRay,en Internet o simplemente en otro Disco Duro, para posteriormente si pierde la información, poder restaurar el sistema.
La copia de seguridad es útil por varias razones:
- Para restaurar un ordenador a un estado operacional después de un desastre (copias de seguridad del sistema)
- Para restaurar un pequeño número de ficheros después de que hayan sido borrados o dañados accidentalmente (copias de seguridad de datos).
- En el mundo de la empresa, además es útil y obligatorio, para evitar ser sancionado por los órganos de control en materia de protección de datos. Por ejemplo, en España la Agencia Española de Protección de Datos (AEPD)
Normalmente las copias de seguridad se suelen hacer en cintas magnéticas, si bien dependiendo de lo que se trate podrían usarse disquetes, CD, DVD, discos ZIP, JAZ o magnético-ópticos, pendrives o pueden realizarse sobre un centro de respaldo remoto propio o vía internet.
La copia de seguridad puede realizarse sobre los datos, en los cuales se incluyen también archivos que formen parte del sistema operativo. Así las copias de seguridad suelen ser utilizadas como la última línea de defensa contra pérdida de datos, y se convierten por lo tanto en el último recurso a utilizar.
Las copias de seguridad en un sistema informático tienen por objetivo el mantener cierta capacidad de recuperación de la información ante posibles pérdidas. Esta capacidad puede llegar a ser algo muy importante, incluso crítico, para las empresas. Se han dado casos de empresas que han llegado a desaparecer ante la imposibilidad de recuperar sus sistemas al estado anterior a que se produjese un incidente de seguridad grave.
Integridad:
El término integridad de datos se refiere a la corrección y completitud de los datos en una base de datos. Cuando los contenidos se modifican con sentencias INSERT, DELETE o UPDATE, la integridad de los datos almacenados puede perderse de muchas maneras diferentes. Pueden añadirse datos no válidos a la base de datos, tales como un pedido que especifica un producto no existente.
Pueden modificarse datos existentes tomando un valor incorrecto, como por ejemplo si se reasigna un vendedor a una oficina no existente. Los cambios en la base de datos pueden perderse debido a un error del sistema o a un fallo en el suministro de energía. Los cambios pueden ser aplicados parcialmente, como por ejemplo si se añade un pedido de un producto sin ajustar la cantidad disponible para vender.
Una de las funciones importantes de un DBMS relacional es preservar la integridad de sus datos almacenados en la mayor medida posible.
Tipos de restricciones de
integridad
- Datos Requeridos: establece que una columna tenga un valor no NULL. Se define efectuando la declaración de una columna es NOT NULL cuando la tabla que contiene las columnas se crea por primera vez, como parte de la sentencia CREATE TABLE.
- Chequeo de Validez: cuando se crea una tabla cada columna tiene un tipo de datos y el DBMS asegura que solamente los datos del tipo especificado sean ingresados en la tabla.
- Integridad de entidad: establece que la clave primaria de una tabla debe tener un valor único para cada fila de la tabla, sino la base de datos perderá su integridad. Se especifica en la sentencia CREATE TABLE. El DBMS comprueba automáticamente la unicidad del valor de la clave primaria con cada sentencia INSERT Y UPDATE. Un intento de insertar o actualizar una fila con un valor de la clave primaria ya existente fallara.
- Integridad referencial: asegura la integridad entre las claves ajenas y primarias (relaciones padre/hijo). Existen cuatro actualizaciones de la base de datos que pueden corromper la integridad referencial:
- La inserción de una fila hijo es cuando no coincide la clave ajena con la clave primaria del padre.
- La actualización en la clave ajena de la fila hijo, donde se produce una actualización en la clave ajena de la fila hijo con una sentencia UPDATE y la misma no coincide con ninguna clave primaria.
- La supresión de una fila padre, donde si una fila padre tiene uno o más hijos se suprime, las filas hijos quedaran huérfanas.
- La actualización de la clave primaria de una fila padre, donde si una fila padre tiene uno o mas hijos se actualiza su clave primaria, las filas hijos quedaran huérfanas.
Seguridad:
Seguridad significa la capacidad de los usuarios para acceder y cambiar los datos de acuerdo a las políticas del negocio, así como, las decisiones de los encargados. Al igual que otros metadatos, una DBMS relacional maneja la seguridad en forma de tablas. Estas tablas son las "llaves del reino" por lo cual se deben proteger de posibles intrusos.
7.- Procedimiento para la administración de una base
de Datos
En este caso tomaremos un ejemplo de la Universidad Católica de Bolivia.
Procedimientos de
revisión de log´s
Es responsabilidad del Administrador de la Base de Datos de la Universidad Católica Boliviana, el revisar diariamente el archivo de log de alertas (alert.log) de ORACLE, en este monitoreo se debe verificar que los usuarios no experimenten problemas y que la base de datos funcione correctamente.
En este archivo se identificarán errores cronológicos de la operación diaria de la base de datos, entre los errores que se pueden encontrar están:
- ORA-600 errores internos que necesitan corrección inmediata
- ORA-1578 errores de corrupción de bloques que necesitan recuperación
- ORA-12012 errores de la cola de trabajos
- Ejecución de comandos de: STARTUP, SHUTDOWN y RECOVER
- Comandos de CREATE, ALTER y DROP
- Comandos que modifican TABLESPACES, DATAFILES, y ROLLBACK SEGMENTS
- Cuando un comando es suspendido durante su operación
- Cuando el log writer (LGWR) no puede escribir en un miembro de grupo
- Cuando se inicia un proceso de Archive (ARCn)
- Información del Dispatcher
- Registro del cambio de parámetros dinámicos
- Se debe revisar el archivo mediante una búsqueda de errores ´ORA-´ para identificar cualquier error que se presente a nivel de base de datos. Adicionalmente se deberán revisar los comandos de modificación y/o creación de objetos en la base de datos.
- Cuando existan errores significativos que puedan afectar el funcionamiento de la base de datos se deberá emitir un informe sobre los mismos y sobre la solución aplicada.
- Se debe remover o limpiar el archivo alert.log regularmente luego de revisarlo, nunca deberá ser mayor a 5M.
- En
cuando a los archivos de rastreo de procesos de background, se debe
revisar diariamente el directorio en el cual se almacenan para identificar
la existencia de nuevos archivos generados y revisar los errores
reportados para así poder tomar las acciones pertinentes.
El directorio en el cual se encuentran almacenados se define mediante el parámetro BACKGROUND_DUMP_DEST, actualmente es: E:\U01\ORACLE\UCBL\ADMIN\bdump. - Adicionalmente, se registran log´s de rastreo de usuarios cuando se reportan errores, estos log´s se revisan juntamente con el alert.log ya que éste genera las llamadas a los archivos de user trace que muestran el detalle de los errores a nivel de código de máquina.
Procedimiento de
administración de usuarios
Activación
de cuentas
- La creación o activación de cuentas en la base de datos y en las aplicaciones se realiza a solicitud mediante una carta o nota interna autorizada por el Director de Recursos Humanos quien es responsable de notificar al Centro de Sistemas de Información la incorporación de personal que requiera del uso de alguno o varios de los Sistemas de la Universidad.
- Una vez que se tiene la autorización y especificación respectiva se crea el usuario en la base de datos con un formato de nombre que depende del tipo de usuario que se va a crear; para cargos genéricos este nombre deberá tener el siguiente formato: [SIGLA DEPARTAMENTO][SIGLA CARGO][NUMERO CORRELATIVO]. Por ejemplo: ADMDIR.
Para cargos específicos, se
crea el usuario con el siguiente formato de nombre:
[INICIAL NOMBRE][APELLIDO]
Por ejemplo: MBLANCO
3. El siguiente paso es asignar los roles y permisos respectivos según el cargo.
4. Adicionalmente, se registra al usuario en la base de datos mediante la aplicación de Control de Usuarios y Accesos donde se registra además el responsable, perfil, rol, departamento y facultad. Los permisos se asignan en base a perfiles según el cargo del usuario y se controlan a nivel de aplicaciones.
Modificación
de roles
La modificación de roles ocurre cuando una persona cambia de cargo dentro de la Universidad y ya tiene una cuenta registrada, en este caso se debe revisar la base de datos, modificar los roles asignados y el perfil de la persona a nivel de la aplicación.
La modificación del rol y perfil de un usuario se realiza cuando se recibe una notificación del cambio de cargo y/o Departamento firmada por el Director de Recursos Humanos.
Bloqueo
de cuentas
Las cuentas se bloquean cuando una persona deja de trabajar en la Universidad o cambia su cargo y ya no precisa el uso de ningún sistema. Este bloqueo se realiza cuando se notifica al Centro de Sistemas de Información sobre cambios y/o retiros de personal.
Adicionalmente se realizan revisiones mensuales sobre los usuarios que acceden a la base de datos. Estas revisiones se realizan a nivel de base de datos y de aplicación.
- Base de
datos: Consulta para la revisión de usuarios activos a nivel del sistema
de gestión de base de datos: select username, account_status, temporary_tablespace from dba_users where
account_status = ‘OPEN’; - Aplicación: Adicionalmente, para la revisión de usuarios activos sin asignación activa de cargo en el Departamento de Personal.
Nota: El usuario que ha sido bloqueado, no se elimina físicamente de la Base de Datos debido a que es necesario mantener el registro histórico de todas las transacciones que éste usuario realizó en el desempeño de sus funciones.
8.- Cómo
Evitar Desastres a Través de Buenas Prácticas de Administración de Base de
Datos?
Las siguientes prácticas le pueden ayudar a mantener su instalación de Adaptive Server Enterprise trabajando al máximo. Al mantener estas prácticas, usted puede maximizar el tiempo de disponibilidad del servidor, corregir problemas proactivamente y estar preparado para manejar emergencias.
Ø Mantenga copias de respaldo (backups) al día
El mantener copias de respaldo al día de sus datos es vital para cualquier plan de recuperación. Mantenga múltiples generaciones de copias y mantenga algunas fuera de sitio como precaución extra.
Realice backups regulares de:
o La base de datos master. Para asegurarse de que su copia de respaldo de master está siempre actualizada, genere una copia de respaldo de master después de cada comando de mantenimiento que afecte dispositivos de base de datos, almacenamiento, bases de datos o segmentos. Por ejemplo, después de crear o borrar bases de datos, inicializar nuevos dispositivos de base de datos y crear o modificar segmentos.
o La base de datos model (si usted ha hecho modificaciones o ha agregado objetos a esta base de datos).
o La base de datos sybsystemprocs (si usted ha hecho modificaciones o ha agregado objetos a esta base de datos).
o Bases de datos de usuario
Recuerde que las últimas versiones de ASE incorporan varias características adicionales, como configuración de memoria compartida para el Backup Server y compresión de Backups.
Ø Mantenga copias de las tablas de datos y scripts de creación de objetos (DDL)
Mantenga copias actualizadas de las siguientes tablas:
o sysusages
o syslogins
o sysloginroles
o sysdatabases
o sysdevices
o syscharsets
o sysconfigures
o sysservers
o sysremotelogins
o sysresourcelimits (11.5 y posterior)
o systimeranges (11.5 y posterior)
Utilice el programa bcp de Sybase para copiar el contenido de estas tablas. Adicionalmente, mantenga una copia escrita imprimiendo la salida de las siguientes consultas:
select * from sysusages order by vstart
select * from sysusages order by dbid, lstart
select * from syslogins
select * from sysloginroles
select * from sysdatabases
select * from sysdevices
select * from syscharsets
select * from sysconfigures
select * from sysservers
select * from sysremotelogins
select * from sysresourcelimits (11.5 y posterior)
select * from systimeranges (11.5 y posterior)
También mantenga:
o Copias de su archivo de configuración, $SYBASE/$SYBASE_ASE/nombre_del_servidor.cfg en Unix, y %SYBASE%\%SYBASE_ASE%\nombre_del_servidor.cfg en Windows.
o Todos los scripts de creación de objetos (scripts DDL) que usted utilice para crear objetos de usuario. Utilice el programa Sybase Central para generar los scripts. Desde la versión 12.5, ASE incorpora el utilitario ddlgen, el cual permite la generación de scriprs DDL desde la línea de comandos del sistema operativo. Para mayor información sobre éste utilitario vea el documento Generación de Sentencias DDL con ddlgen (DocId: 10132).
Ø Verifique la consistencia de las bases de datos
Ejecute comandos dbcc regularmente para monitorear el estado de sus bases de datos. Las verificaciones a nivel de base de datos se pueden realizar con dbcc checkdb, dbcc checkalloc, y dbcc checkstorage (11.5 y posterior). Para mayor explicación sobre los comandos dbcc, vea el manual System Administration Guide de Sybase.
Dado que los comandos dbcc pueden ser intensivos en uso de recursos, considere adoptar una estrategia que saque provecho de los comandos dbcc a nivel de objeto. Es posible utilizar dbcc checktable y dbcc tablealloc para verificar la consistencia de un conjunto de tablas particulares. Por ejemplo, si su base de datos tiene 200 tablas, adicionales a las tablas del sistema, ejecute dbccs sobre las tablas del sistema en un día, dbccs sobre un grupo de 50 tablas otro día, y así sucesivamente; al final de la semana habrá completado la verificación para la totalidad de las tablas y podrá comenzar el ciclo nuevamente.
Estrategias alternas incluyen:
o Cargar la base de datos en otro servidor (usando dump database y load database), y ejecutar los comandos dbcc en ese servidor.
o Usar el comando dbcc checkstorage (11.5 y posterior); para mayor información vea el documento Configuración y Uso del Comando dbcc checkstorage (DocId: 10052).
El incorporar las verificaciones dbcc dentro de sus tareas regulares de generación de copias de respaldo y mantenimiento puede asegurarle que usted tiene copias de respaldo consistentes y exactas en todo momento.
Ø Implemente Discos Espejo
Los discos espejo, a nivel de Adaptive Server Enterprise o a nivel de sistema operativo, pueden proporcionar recuperación con disponibilidad continua en el evento de fallas de medios de almacenamiento (discos físicos).
Los factores que usted necesita considerar y las instrucciones para implementar discos espejo en Adaptive Server Enterprise, están detallados en el manual System Administration Guide. Vea también el documento Aspectos Importantes sobre Sybase y RAID (DocId: 10020).
Ø Realice Mantenimiento Continuo
Como parte del programa rutinario de mantenimiento del servidor de datos, usted debería:
o Monitorear el log de errores de Adaptive Server Enterprise. Note que los usuarios generalmente no son notificados de errores con severidad 17 o 18, si su trabajo no se ve interrumpido.
Defina una rutina que busque mensajes específicos en el log de errores de Adaptive Server Enterprise. Para información sobre el formato del log de errores y los niveles de severidad vea el manual System Administration Guide.
Nota:
Los usuarios de Windows NT/2000 también pueden monitorear los mensajes del
servidor de datos a través del Visor de Eventos de Windows (Event
Viewer).
Purgue el log de errores de manera regular a medida que éste crece, ya que Adaptive Server Enterprise agrega mensajes cada vez que arranca. Un log de errores sin espacio puede causar que el servidor de datos se congele. Recuerde bajar el servidor de datos primero y realizar una copia del log de errores, antes de purgarlo.
Un ejemplo de cómo purgar el log de errores en Unix:
% isql -Usa 1> shutdown2> go
% cp errorlog errorlog.fecha
% rm errorlog
donde fecha es la fecha actual.
o Monitoree el log de errores del sistema operativo para mantener conciencia del estado del hardware y sistema operativo. Muchos errores de Adaptive Server Enterprise pueden ser causados por problemas de hardware (discos, memoria, tarjetas de red, controladoras de disco, etc.) y pueden, en consecuencia, indicar problemas en el hardware.
o Monitoree la utilización de espacio utilizando los procedimientos almacenados del sistema sp_helpsegment, sp_spaceused y sp_helpdb. Al ejecutar el procedimiento sp_spaceused de manera regular, por ejemplo, usted puede determinar si una base de datos se está quedando sin espacio para nuevos objetos o para el log de transacciones.
De manera alterna, usted puede definir umbrales para monitorear el espacio libre por segmento. Para más información vea el manual System Administration Guide, o el documento Uso de Umbrales para Controlar el Espacio Libre en Adaptive Server Enterprise (DocId: 10005).
o Ejecute periódicamente el comando update statistics, ya que a medida que una tabla cambia, las estadísticas que el optimizador de ASE utiliza para resolver las consultas se vuelven obsoletas, y el servidor de datos puede comenzar a seleccionar la estrategia incorrecta para resolver dichas consultas.
En versiones anteriores a la 11.9.2, las páginas de distribución mantenían las estadísticas de distribución de los valores de las llaves de los índices; este enfoque era bastante limitado. Desde la versión 11.9.2, no se utilizan páginas de distribución; en su lugar, se utiliza un mecanismo basado en tablas del sistema, el cual es mucho más flexible y exacto. Haga referencia a los siguientes documentos para más detalles:
- Estadísticas del Optimizador desde Adaptive Server Enterprise 11.9.2 (DocId: 10047)
- Estadísticas del Optimizador después de Actualizar a Adaptive Server Enterprise 11.9.2 (DocId: 10049)
- Ejecute periódicamente el comando reorg. Desde la versión 11.9.2 se incluyen dos nuevos esquemas adicionales de bloqueo de datos (esquemas DOL, por la sigla en inglés de Data Only Locking), adicionales al esquema tradicional allpages; los nuevos esquemas de bloqueo DOL son datapages y datarows. Las tablas que usan estos esquemas de bloqueo (tablas DOL) son propensas a sufrir de fragmenteción de datos y a medida que van cambiando es posible que se degrade el rendimiento de las consultas. Para mayor información consulte los siguientes documentos:
- Preguntas y Respuestas Frecuentes sobre Esquemas de Bloqueo de Datos en Adaptive Server Enterprise (Doc Id: 10025)
- Cómo Detectar y Corregir la Fragmentación de Tablas DOL en Adaptive Server Enterprise 11.9.2 y Posterior (DocId: 10129).
o Monitoree el comportamiento general de su servidor de datos usando el comando sp_sysmon, el cual genera estadísticas de uso de los diferentes recursos de ASE (kernel, discos, cachés, índices, transacciones, etc.); el documento Notas Sobre el Procedimiento Almacenado del Sistema sp_sysmon (DocId: 10072) contiene más detalles.
Ø Evite Prácticas Riesgosas
o De ser posible, extienda tempdb fuera del dispositivo master, sobre todo cuando se requiera espacio adicional para cierto tipo de consultas, como aquellas que incluyan cláusulas order by, group by, etc. Desde la versión 12.5.0.3 de ASE se incluye un mecanismo que permite crear múltiples bases de datos tempdb, volviendo más flexible la administración del espacio temporal en el servidor de datos; para más información ves el documento Configuración y Uso de Múltiples Bases de Datos Temporales en ASE (DocId: 10134).
o Nunca ubique nada distinto a las bases de datos del sistema master, model y tempdb sobre el dispositivo master. Almacenar otras bases de datos en el dispositivo master puede hacer muy difícil la recuperación de las bases de datos del sistema o de las bases de datos de usuario, si alguna de ellas de daña.
Ø Consejos de Recuperación, o ¿Qué Hacer Cuando las Cosas Salen Mal?
o Seleccione el método correcto de recuperación. Su elección de métodos estará dictado por el tipo de falla que usted encuentre. Por ejemplo, la pérdida de un dispositivo físico requerirá recuperación a partir de copias de respaldo.
Las fallas de red o hardware usualmente tienen poco impacto en el servidor, pero pueden comprometer los datos en algunas situaciones, y la recuperación puede fallar.
o Si hay implementados discos espejo en su instalación, deshabilite los discos espejo antes de cargar una copia de respaldo, preservando así una copia de lo que usted tenía, por si acaso la copia de respaldo llega a estar corrupta.
o Nunca corra buildmaster en el dispositivo master original. Puede que éste contenga información que usted necesite posteriormente. Ejecute el buildmaster sobre un dispositivo distinto, y cuando su ambiente esté completamente restaurado, usted podría regresar a su dispositivo master original, si es necesario.
Importante:
Desde ASE 12.5 la funcionalidad del utilitario buildmaster
fue reemplazada por la del utilitario dataserver
(sqlsrvr.exe en Windows); vea el documento Recuperación
de la Base de Datos master o del Dispositivo master en Adaptive
Server Enterprise 12.5 (DocId: 10104).
Ø Consejos Adicionales
- Defina y documente claramente sus políticas y procedimientos de administración.
- Prueba sus procedimientos de administración (por ejemplo, simule una situación de emergencia en la cual requiera restaurar una base de datos de sus backups).
- Después de una actualización de sistema operativo, verifique los permisos sobre sus dispositivos de base de datos.
Ø Documentos Adicionales
Los siguientes documentos contienen temas de Administración que pueden complementar ésta Nota Técnica:
o Uso del Cron de Unix para Programar Copias de Respaldo Automáticas en Adaptive Server Enterprise
o ¿Cómo Generar un Script SQL Dinámicamente a Partir de Otro Script SQL? (UNIX)
o Documentos Técnicos de Syabase
Infografias:
http://es.kioskea.net/contents/bdd/bddintro.php3
http://www3.uji.es/~mmarques/f47/apun/node76.html
Date (1993), Connolly, Begg y Strachan (1996) y Hansen y Hansen (1997).
http://www.ucb.edu.bo/Procedimientos/BaseDeDatos/ProcedimientoAdmBaseDatos.htm
http://www.mtbase.com/contenido/documento.jsp?id=10035