
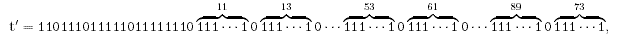
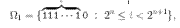
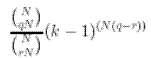
| C(x)/|x| l‰hell‰ 0 |
*korkeasti pakattavissa *j‰rjest‰ytynyt *tuotettavissa yksinkertaisella s‰‰nnˆll‰ *matala informaatio *ei-satunnainen *frekvenssilt‰‰n toistuva *satunnaisesti valittu merkkijono tuottaa pienell‰ todenn‰kˆisyydell‰. |
| C(x)/|x| l‰hell‰ 1 |
*vaikeasti pakattavissa *suuri informaation m‰‰r‰ *ei tuotettavissa yksinkertaisella s‰‰nnˆll‰ *satunnainen *frekvenssilt‰‰n vaihteleva *satunnaisesti valittu merkkijono tuottaa suurella todenn‰kˆisyydell‰. |