Estudios Virtuales
(Pregrado) Licenciatura en
Información y Documentación Trabajo Nº 6 Estadística Descriptiva

Realizado por:
Luisa Ochoa 7.142.068
Sorelix Sánchez 10.994.811
Eudy Yanez
Neyda Duque
Emwid Castillo
![]()
1.- Asociación entre Variables
Se afirma que hay asociación entre dos variables , cuando los cambios o fluctuaciones de los respectivos valores se corresponden, fluctúan con regularidad.
Por ejemplo si afirmamos que “ Cuando en una situación de aprendizaje se plantea un objeto de conocimiento nuevo, los estudiantes obtendrán mejores resultados cuanto mayor tiempo le dediquen al estudio y ejercitación de los temas nuevos planteados”
Si se quisiera comprobar experimentalmente esta proposición se podría trabajar con dos grupos de alumnos, de formaciones previas similares y tiempos de estudio y ejercitación distintos y observar luego los resultados de alguna prueba objetiva de conocimiento adquirido. Luego de la prueba se obtiene la mediana , entendiendo como mejores resultados los que estan por encima de la mediana y peores resultados los que están por debajo.
Trabajamos con 160 alumnos (N=160)
Una posibilidad es trabajar con dos variables dicotómicas ( una variable dicotómica admite solo dos valores) Esto nos da un cuadro o tabla de 2x2. como el que vemos acá.
Tabla Nº 1.
Estudiantes según los resultados o calificaciones obtenidas de acuerdo a el mayor o menor tiempo dedicado al estudio y ejercitación de contenidos nuevos. En valores absolutos.
|
|
|
Tiempo |
|
|
|
|
|
Mayor |
Menor |
Total |
|
Resultados |
Mejores |
60 |
20 |
80 |
|
Peores |
15 |
65 |
80 |
|
|
|
Total |
75 |
85 |
160 |
Como esta tabla esta en números absolutos es necesario pasarlo a Porcentajes.
Vamos a obtener los porcentajes en el sentido de las filas, en este caso la operación que debemos hacer es una regla de 3 .
No quedaría , como resultado de las operaciones la siguiente tabla.
Tabla Nº 2.
Estudiantes según los resultados o calificaciones obtenidas de acuerdo a el mayor o menor tiempo dedicado al estudio y ejercitación de contenidos nuevos. En valores absolutos
|
|
|
Tiempo |
|
|
|
|
|
Mayor |
Menor |
Total |
|
Resultados |
Mejores |
75 |
25 |
100 |
|
Peores |
18,75 |
81,25 |
100 |
|
|
|
Total |
56,25 |
-56,25 |
100 |
Estudiantes según los resultados o calificaciones obtenidas de acuerdo a el mayor o menor tiempo dedicado al estudio y ejercitación de contenidos nuevos. En valores relativos.
En este caso, a los porcentajes tomados en el sentido de las filas se efectúa la diferencia (resta) en el sentido de las columnas . La diferencia porcentual en este caso es de 56.25 lo que es una diferencia muy alta. Lo que indicaría que hay asociación entre los mejores resultados en el aprendizaje y el mayor tiempo de estudio y ejercitación.
Dentro de esta asociación de variables lo habitual es diferenciar entre la variable independiente (x) y la variable dependiente (y).
La variable independiente no sufre ni experimenta variaciones cuando la variable dependiente cambia sus valores. En cambio, esta en la naturaleza de la variable dependiente variar o cambiar si los valores de la variable independiente cambian.
En el ejemplo anterior el tiempo ( que se dedica al estudio y ejercitación) es la variable independiente y los resultados son la variable dependiente.
2.- Modelos de Regresión Bivariable Lineal
Análisis De Regresión
Consideremos la variable bidimensional (X,Y) , y sea E(Y/X) la regresión del promedio de Y sobre X , cuya forma dependerá de la relación existente entre las variables. En este capítulo nos limitaremos a las funciones de regresión que son lineales en los parámetros (o coeficientes).
Si la distribución de (X,Y) es Normal bivariada, entonces las funciones condicionales de probabilidad son también normales; es decir: dado un valor fijo X=x , la variable Y se distribuye en forma normal con media E(Y/X) = α + β.X y con variancia V(Y/X) = σ2/y(1 - p2 )−= σ2 constante, lo que significa, que no depende del valor X=x.
La diferencia que existe entre el valor que toma la variable Y (dado que X=x) y la esperanza condicional E(Y/x) se denomina residuo , desvío o error , y representa la parte aleatoria . En otras palabras, si (xi , yi ) es el valor que asume la variable bidimensional (X,Y), el residuo será = yεi - E(Y/xi ) , y por lo tanto yi = E(Y/xi ) + εi .
Considerando una relación lineal entre las variables , esto significa que yi= α + β.xi+εi, donde α + β.xi = E(Y/xi ) es la parte sistemática o determinística (sólo depende del valor x ), y es la parte aleatoria sobre la cual se establecerán condiciones o restricciones que determinan el comportamiento de la variable Y. Este modelo supone que para cada valor fijo x , existe una distribución de valores de la variable Y . ε
En este modelo identificamos las siguientes componentes:
α y β: parámetros poblacionales
X : variable "explicativa"
Y : variable "explicada"
ε : error residual
Este residuo ε se compone esencialmente de errores casuales, debida a la propia aleatoriedad de cada individuo, pudiendo además incluir errores de medición de los yi , como también deficiencias del modelo debidas, por ejemplo, a otras variables que no han sido consideradas en dicho modelo . En otras palabras, εi es la parte de yi que no está explicada por la regresión lineal de Y sobre xi .
Este modelo supone una distribución Normal de los errores o residuos , con media E(ε) = 0 y variancia constante V(ε ) = σ2 , característica que recibe el nombre de homocedasticidad y significa que la variancia de Y no depende del valor que tome la variable X . Es decir:
εi ~N (0,σ2)
A esta condición de normalidad se le agrega la de la independencia entre los errores, es decir:
cov (ei,ej) = 0∀i≠j
Estos supuestos sobre los errores implican supuestos sobre el comportamiento de las variables Y. Podemos, entonces, enunciarlos como sigue:
La variable "explicativa" X toma valores predeterminados por el investigador.
Para cada valor fijo de X, la variable Y se distribuye en forma normal.
La relación entre las variables X e Y es lineal, es decir, la regresión del promedio es lineal Simbólicamente: E (Y/X) = α + β.X , ya que E(ε) = 0
Los valores de la variable Y son independientes entre si ya que cov (εi,εj) =∀i ≠j
Homocedasticidad, ya que la variancia de los errores es constante, no depende del valor de X
La violación de supuestos se refiere a:
Autocorrelación entre los errores o dependencia entre los errores: cov (εi,εj) ≠ 0 para a 1g ún par i;j.
Heterocedasticidad , lo que significa que la variancia del error o residuo depende del valor de x , y trae como consecuencia que la variancia de Y condicionada a un valor de X tampoco es constante sino que depende de dicho valor.. O sea: V(Y/x) = H(x) = V(ε/x) .
Distribución no normal de los errores o residuos.
X es variable aleatoria , lo que significa que no han sido predeterminados los valores de X
La hipótesis de distribución normal de los errores y la de homocedasticidad traen como consecuencia inmediata la distribución normal de la variable Y condicionada a un valor fijo X = x . Es decir:
εi ~ N(0,σ2) ⇒ Y/ x ~ N (α +βx,σ2)
La inferencia estadística se ocupa de estimar los parámetros de la población bivariada (como así también los de la recta de regresión) en base a los resultados obtenidos a través de una muestra aleatoria.
3.- Estimación de Parámetros de Regresión
Estimación de los parámetros de la recta de regresión. El primer problema a abordar es obtener los estimadores de los parámetros de la recta de regresión, partiendo de una muestra de tamaño n, es decir, n pares (x1, Y1), (x2, Y2),..., (xn, Yn); que representan nuestra intención de extraer para cada xi un individuo de la población o variable Yi.
Una vez realizada la muestra, se dispondrá de n pares de valores o puntos del plano (x1, y1), (x2, y2),..., (xn, yn). El método de estimación aplicable en regresión, denominado de los mínimos cuadrados, permite esencialmente determinar la recta que "mejor" se ajuste o mejor se adapte a la nube de n puntos. Las estimaciones de los parámetros de la recta de regresión obtenidas con este procedimiento son:

Por tanto la recta de regresión estimada será:
![]()
Un ejemplo. La recta de regresión representada corresponde a la estimación obtenida a partir de 20 pares de observaciones: x representa la temperatura fijada en un recinto cerrado e Y el ritmo cardíaco de un vertebrado.
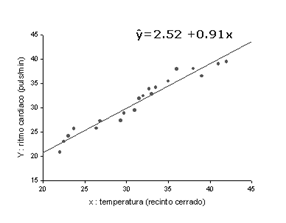
Estimación de los parámetros del modelo.
En el modelo de regresión
lineal simple hay tres parámetros que se deben estimar: los coeficientes de la
recta de regresión, ![]() 0 y
0 y ![]() 1; y la varianza de la
distribución normal,
1; y la varianza de la
distribución normal, ![]() 2.
2.
El cálculo de estimadores para estos parámetros puede hacerse por diferentes métodos, siendo los más utilizados el método de máxima verosimilitud y el método de mínimos cuadrados.
Método de máxima verosimilitud.
Conocida una muestra de tamaño
n, ![]() , de la hipótesis de normalidad se sigue que la
densidad condicionada en yi es
, de la hipótesis de normalidad se sigue que la
densidad condicionada en yi es
![]()
y, por tanto, la función de densidad conjunta de la muestra es,
![]()
Una vez tomada la muestra y,
por tanto, que se conocen los valores de ![]() i = 1n, se
define la función de verosimilitud asociada a la muestra como sigue
i = 1n, se
define la función de verosimilitud asociada a la muestra como sigue
esta función (con variables ![]() 0,
0, ![]() 1 y
1 y ![]() 2) mide
la verosimilitud de los posibles valores de estas variables en base a la
muestra recogida.
2) mide
la verosimilitud de los posibles valores de estas variables en base a la
muestra recogida.
El método de máxima
verosimilitud se basa en calcular los valores de ![]() 0,
0, ![]() 1 y
1 y ![]() 2 que maximizan la
función (9.3)
y, por tanto, hacen máxima la probabilidad de ocurrencia de la muestra
obtenida. Por ser la función de verosimilitud una función creciente, el
problema es más sencillo si se toman logaritmos y se maximiza la función
resultante, denominada función soporte,
2 que maximizan la
función (9.3)
y, por tanto, hacen máxima la probabilidad de ocurrencia de la muestra
obtenida. Por ser la función de verosimilitud una función creciente, el
problema es más sencillo si se toman logaritmos y se maximiza la función
resultante, denominada función soporte,
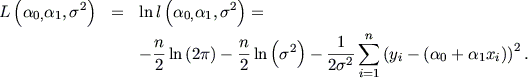
Maximizando la anterior se obtienen los siguientes estimadores máximo verosímiles,
![]()
![]()
![]()
donde se ha denotado ![]() e
e ![]() a las medias muéstrales de X e
Y, respectivamente; sx2 es la varianza muestral de
X y sXY es la covarianza muestral entre X e Y. Estos
valores se calculan de la siguiente forma:
a las medias muéstrales de X e
Y, respectivamente; sx2 es la varianza muestral de
X y sXY es la covarianza muestral entre X e Y. Estos
valores se calculan de la siguiente forma:
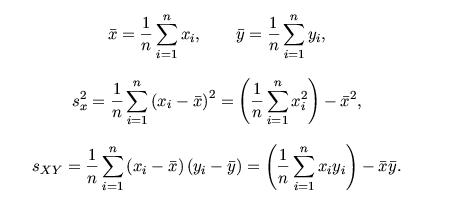
Método de mínimos cuadrados.
A partir de los
estimadores: ![]() 0 y
0 y ![]() 1, se pueden
calcular las predicciones para las observaciones muestrales, dadas por,
1, se pueden
calcular las predicciones para las observaciones muestrales, dadas por,
![]()
o, en forma matricial,
![]()
donde ![]() t =
t = ![]() . Ahora se definen
los residuos como
. Ahora se definen
los residuos como
|
ei |
= yi
- |
|
Residuo |
= Valor observado -Valor previsto, |
en forma matricial,
![]()
Los estimadores por mínimos cuadrados se obtienen minimizando la suma de los cuadrados de los residuos, ésto es, minimizando la siguiente función,
derivando e igualando a cero se obtienen las siguientes ecuaciones, denominadas ecuaciones canónicas,
![]()
![]()
De donde se deducen los siguientes estimadores mínimo cuadráticos de los parámetros de la recta de regresión
![]()
![]()
Se observa que los estimadores
por máxima verosimilitud y los estimadores mínimos cuadráticos de ![]() 0
y
0
y ![]() 1
son iguales. Esto es debido a la hipótesis de normalidad y, en adelante, se
denota
1
son iguales. Esto es debido a la hipótesis de normalidad y, en adelante, se
denota ![]() 0
=
0
= ![]() 0,MV
=
0,MV
= ![]() 0,mc
y
0,mc
y ![]() 1
=
1
= ![]() 1,MV
=
1,MV
= ![]() 1,mc.
1,mc.
4.- Varianza de la Regresión de la Muestra
Es a un modo alternativo de hacer contrastes sobre el coeficiente 1. Consiste en descomponer la variación de la variable Y de dos componentes: uno la variación de Y alrededor de los valores predichos por la regresión y otro con la variación de los valores predichos alrededor de la media. Si no existe correlación ambos estimadores estimarían la varianza de Y y si la hay, no. Comparando ambos estimadores con la prueba de la F se contrasta la existencia de correlación.
Esta técnica, permite analizar los datos así como también planificar los experimentos, es un forma estadística que permite dividir la variabilidad observada en componentes independientes que pueden atribuirse a diferentes causas de interés.
Función lineal
|
Se llama
función lineal de una variable, a una función de la forma |
|
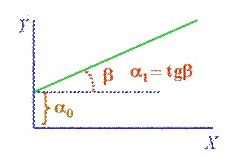
Son modelos estadísticos que explican la dependencia de una variable dependiente “Y” respecto de una o varias variables cuantitativas “X”.
Para obtener los estimadores de los parámetros desconocidos del modelo así como para realizar contrastes de hipótesis y la verificación del modelo,
Objetivos de los modelos de regresión
1) predictivo en el que el interés del investigador es predecir lo mejor posible la variable dependiente, usando un conjunto de variables independientes y
2) estimativo en el que el interés se centra en estimar la relación de una o más variables independientes con la variable dependiente.
Modelo de regresión lineal La regresión lineal es un modelo matemático mediante el cual es posible inferir datos acerca de una población. Se conoce como regresión lineal ya que usa parámetros lineales (potencia 1).Sirve para poner en evidencia las relaciones que existen entre diversas variables
Representamos en un gráfico los pares de valores de una distribución bidimensional: la variable "x" en el eje horizontal o eje de abcisa, y la variable "y" en el eje vertical, o eje de ordenada. Vemos que la nube de puntos sigue una tendencia lineal:
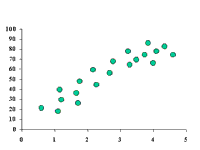
El coeficiente de correlación lineal nos permite determinar si, efectivamente, existe relación entre las dos variables. Una vez que se concluye que sí existe relación, la regresión nos permite definir la recta que mejor se ajusta a esta nube de puntos.
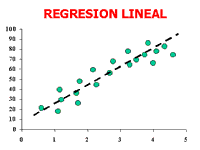
Una recta viene definida por la siguiente fórmula:
|
y = a + bx |
Donde "y" sería la variable dependiente, es decir, aquella que viene definida a partir de la otra variable "x" (variable independiente). Para definir la recta hay que determinar los valores de los parámetros "a" y "b":
El parámetro "a" es el valor que toma la variable dependiente "y", cuando la variable independiente "x" vale 0, y es el punto donde la recta cruza el eje vertical.
El parámetro "b" determina la pendiente de la recta, su grado de inclinación.
La regresión lineal nos permite calcular el valor de estos dos parámetros, definiendo la recta que mejor se ajusta a esta nube de puntos.
El parámetro "b" viene determinado por la siguiente fórmula:
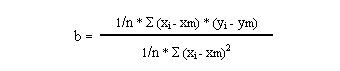
Es la covarianza de las dos variables, dividida por la varianza de la variable "x".
El parámetro "a" viene determinado por:
|
a = ym - (b * xm) |
Es la media de la variable "y", menos la media de la variable "x" multiplicada por el parámetro "b" que hemos calculado.
Ejemplo: vamos a calcular la recta de regresión de la siguiente serie de datos de altura y peso de los alumnos de una clase. Vamos a considerar que la altura es la variable independiente "x" y que el peso es la variable dependiente "y" (podíamos hacerlo también al contrario):
|
Alumno |
Estatura |
Peso |
Alumno |
Estatura |
Peso |
Alumno |
Estatura |
Peso |
|
x |
x |
x |
x |
x |
x |
x |
x |
x |
|
1 |
1,25 |
32 |
11 |
1,25 |
33 |
21 |
1,25 |
33 |
|
2 |
1,28 |
33 |
12 |
1,28 |
35 |
22 |
1,28 |
34 |
|
3 |
1,27 |
34 |
13 |
1,27 |
34 |
23 |
1,27 |
34 |
|
4 |
1,21 |
30 |
14 |
1,21 |
30 |
24 |
1,21 |
31 |
|
5 |
1,22 |
32 |
15 |
1,22 |
33 |
25 |
1,22 |
32 |
|
6 |
1,29 |
35 |
16 |
1,29 |
34 |
26 |
1,29 |
34 |
|
7 |
1,30 |
34 |
17 |
1,30 |
35 |
27 |
1,30 |
34 |
|
8 |
1,24 |
32 |
18 |
1,24 |
32 |
28 |
1,24 |
31 |
|
9 |
1,27 |
32 |
19 |
1,27 |
33 |
29 |
1,27 |
35 |
|
10 |
1,29 |
35 |
20 |
1,29 |
33 |
30 |
1,29 |
34 |
El parámetro "b" viene determinado por:
|
b = |
(1/30) * 1,034 |
|
|
----------------------------------------- |
= 40,265 |
|
|
(1/30) * 0,00856 |
|
Y el parámetro "a" por:
|
a = 33,1 - (40,265 * 1,262) = -17,714 |
Por lo tanto, la recta que mejor se ajusta a esta serie de datos es:
|
y = -17,714 + (40,265 * x) |
Esta recta define un valor de la variable dependiente (peso), para cada valor de la variable independiente (estatura):
|
Estatura |
Peso |
|
x |
x |
|
1,20 |
30,6 |
|
1,21 |
31,0 |
|
1,22 |
31,4 |
|
1,23 |
31,8 |
|
1,24 |
32,2 |
|
1,25 |
32,6 |
|
1,26 |
33,0 |
|
1,27 |
33,4 |
|
1,28 |
33,8 |
|
1,29 |
34,2 |
|
1,30 |
34,6 |
5.- Inferencias Acerca de los Coeficientes de Regresión de la Población
La inferencia estadística, que se dedica a la generación de los modelos, inferencias y predicciones asociadas a los fenómenos en cuestión teniendo en cuenta lo aleatorio e incertidumbre en las observaciones. Se usa para modelar patrones en los datos y extraer inferencias acerca de la población de estudio.
A veces interesa hacer inferencias sobre la propia regresión, es decir sobre mY|xi para cualquier valor de xi. Si a los valores xi de la muestra se les aplica la ecuación estimada, se obtiene una mestimación de Y|xi
![]()
cuya distribución muestral también es conocida. A veces se representan los intervalos de confianza para la regresión en la denominada banda de confianza de la regresión. En la figura se presenta la banda de confianza para los datos del
Ejemplo: Una muestra produce los siguientes datos:
|
X (sal) |
Y (Presión) |
|
1,8 |
100 |
|
2,2 |
98 |
|
3,5 |
110 |
|
4,0 |
110 |
|
4,3 |
112 |
|
5,0 |
120 |
La "salida" de un paquete estadístico es:
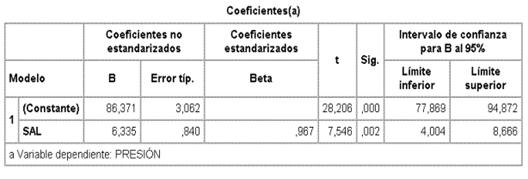
86,371 presión arterial media
sin nada de sal.
6,335 aumento de presión por cada gr de sal; como es distinto de 0 indica
correlación. La pregunta es ¿podría ser 0 en la población? En términos de
contrastes de hipótesis
H0 a: 1 = 0
H1 a :1 0¹
según iii)
|
|
aquí t=7,546 con un valor p=0,002 |
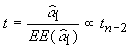
se rechaza H0.
Para hacer estimación por intervalos de la fuerza de la asociación o el efecto
![]()
en aeste ejemplo para 1 al 95%
6,335 2,776x0,840 = (4,004 8,666)±
y adel mismo modo, tiene menos interés, para 0
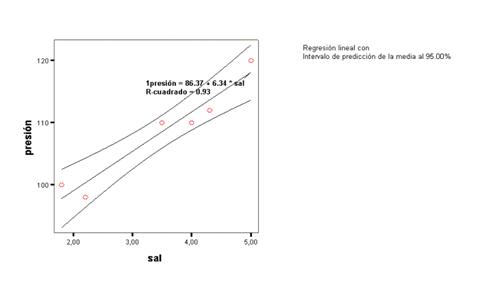
6.- Predicción y Pronosticación
Predecir: Anunciar por revelación, ciencia o conjetura algo que va a suceder, entonces se entiende como anunciar de antemano algo que sucederá en el futuro.
Pronosticar: Conocer por algunos indicios lo futuro. Al igual se puede mencionar que es emitir un enunciado sobre lo que es probable que ocurra en el futuro, basándose en análisis y en consideraciones de juicio.
Hacer un pronóstico es obtener conocimiento sobre eventos inciertos que son importantes en la toma de decisiones presentes.
7.- Análisis de Correlación
Análisis de Correlación
Es frecuente que estudiemos sobre una misma población los valores de dos o más variables estadísticas distintas, con el fin de ver si existe alguna relación entre ellas, es decir, si los cambios en una o varias de ellas influyen en los valores de la variable dependiente. Si ocurre esto decimos que las variables están correlacionadas o bien que hay correlación entre ellas. Este tipo de análisis funcione relativamente bien cuando las variables estudiadas son continuas, sin embargo no es adecuado hacer análisis de correlación con variables nominales.
El análisis de correlación es el conjunto de técnicas estadísticas empleado para medir la intensidad de la asociación entre dos variables. El principal objetivo del análisis de correlación consiste en determinar que tan intensa es la relación entre dos variables, estas pueden ser.
· Variable Dependiente.- es la variable que se predice o calcula. Cuya representación es "Y"
· Variable Independiente.- es la o las variables que proporcionan las bases para el calculo. Cuya representación es: “X”. Esta o estas variables suelen ocurrir antes en el tiempo que la variable dependiente.
8.- Coeficiente de Correlación de la Muestra
El coeficiente de
correlación más utilizado es el de Pearson, este es un índice estadístico que mide
la relación lineal entre dos variables cuantitativas, es una forma de medir la
intensidad de la relación lineal entre dos variables. El valor del coeficiente
de correlación puede tomar valores desde menos uno hasta uno, -1 < r < 1,
indicando que mientras más cercano a uno sea el valor del coeficiente de
correlación, en cualquier dirección, más fuerte será la asociación lineal entre
las dos variables. El coeficiente de correlación de cálculo “r” es un estimador
muestral del coeficiente poblacional Rho, ![]() .
.
Mientras más cercano a cero sea el coeficiente de correlación, este indicará que más débil es la asociación entre ambas variables. Si es igual a cero se concluirá que no existe relación lineal alguna entre ambas variables. Hay varias maneras de equivalentes de calcular “r”, a continuación se muestran tres formas.
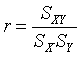 Coeficiente
Correlación Fórmula por Covarianzas y Desviaciones Típicas
Coeficiente
Correlación Fórmula por Covarianzas y Desviaciones Típicas
Siendo: “SXY” la covarianza de (X,Y) y “SX, SY” las desviaciones típicas de las distribuciones de las variables independiente y dependiente respectivamente.
Coeficiente Correlación Fórmula Clásica. Poco usada para cálculo.
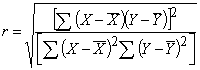
Coeficiente Correlación, Fórmula por suma de cuadrados. Se usa cuando se dispone de calculadoras de mano que hacen sumatorias y no correlación.
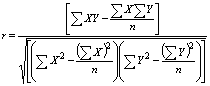
Gráfico de Dispersión de puntos. Es un diagrama de dispersión de punto X Y, el cual es una representación gráfica de la relación entre dos variables, muy utilizada en las fases de comprobación de teorías e identificación de causas raíz y en el diseño de soluciones y mantenimiento de los resultados obtenidos. Tres conceptos especialmente son destacables: que el descubrimiento de las verdaderas relaciones de causa-efecto es la clave de la resolución eficaz de un problema, que las relaciones de causa-efecto casi siempre muestran variaciones, y que es más fácil ver la relación en un diagrama de dispersión que en una simple tabla de números.
Según sea la dispersión de los datos (nube de puntos) en el plano cartesiano, pueden darse alguna de las siguientes relaciones, Lineal, Logarítmica, Exponencial, Cuadrática, entre otras. Estas nubes de puntos pueden generar polígonos a partir de ecuaciones de regresión que permitan predecir el comportamiento de la variable dependiente
Regresión
La regresión estadística o regresión a la media es la tendencia de una medición extrema a presentarse más cercana a la media en una segunda medición. La regresión se utiliza para predecir una medida basándonos en el conocimiento de otra. El término regresión fue introducido por Francis Galton en su libro Natural inheritance (1889), partiendo de los análisis estadísticos de Karl Pearson. Su trabajo se centró en la descripción de los rasgos físicos de los descendientes a partir de los de sus padres. Estudiando la altura de padres e hijos llegó a la conclusión de que los padres muy altos tenían una tendencia a tener hijos que heredaban parte de esta altura, pero los datos revelaban también una tendencia a regresar a la media. (Wikipedia, 2007 )
Los tipos de regresión más comunes entre dos variables son la regresión: lineal, logarítmica, exponencial, cuadrática y cúbica. Cuando hay más de una variable independiente “x”, la regresión más utilizada en la regresión múltiple.
A continuación se expresan matemáticamente los diferentes modelos:
|
REGRESIÓN |
ECUACIÓN |
|
Lineal |
y = b0 + b1 x |
|
Logarítmica |
y = b0 + b1 Ln (x) |
|
Exponencial |
y = b0 e (b1 x) |
|
Cuadrática |
y = b0+ b1 x +b2 x2 |
|
Cúbica |
y = b0+ b1 x +b2 x2 +b3 x3 |
|
Lineal Múltiple |
y = b0+ b1 x1 +b2 x2…+bn xn |
Ecuación de Regresión Lineal
Es el tipo de regresión más utilizada, es una ecuación que define la relación lineal entre dos variables.
Ecuación de regresión lineal Y= b0 + b1 x
Esta ecuación se
calcula según el principio de Mínimos Cuadrados. La cual es la técnica empleada
para obtener la ecuación de regresión, minimizando la suma de los cuadrados de
las distancias verticales entre los valores verdaderos de "Y" y los
valores pronosticados "![]() ".
".
La ecuación que minimizar la desviaciones de los valores de “Y” respecto a la ecuación de la recta, cuando “b0= 0”, es:
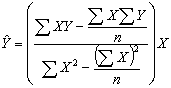
![]()
Por lo tanto la Expresión del coeficiente de regresión, “b1”, queda así:
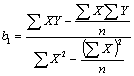
Como podemos escribir:
![]()
Que puede replantearse como:
![]()
![]() De tal manera que
la ordenada al origen, cuando “X” vale 0, “b0”, queda definida de la
siguiente manera:
De tal manera que
la ordenada al origen, cuando “X” vale 0, “b0”, queda definida de la
siguiente manera:
Ejemplo de regresión correlación lineal:
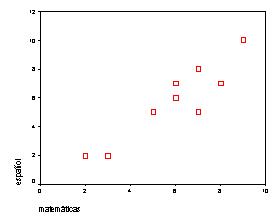
Se tienen las notas de examen final de diez alumnos de las asignaturas de matemáticas y español
|
2 |
3 |
5 |
5 |
6 |
6 |
7 |
7 |
8 |
9 |
|
|
Español |
2 |
2 |
5 |
5 |
6 |
7 |
5 |
8 |
7 |
10 |
Se supone que los alumnos con mejores notas en matemáticas, variable independiente “X”, tienen las mejores notas en español, variable dependiente “Y”. Esta pregunta se puede responder con un análisis de regresión correlación.
Lo primero que se hace es construir un gráfico de dispersión de punto como el que se muestra a continuación
|
|
|
Gráfico de dispersión de puntos de las notas de las asignaturas de matemáticas y español |
Datos generados con una calculadora de mano:
![]()
Luego se calcula el coeficiente de correlación “r”.
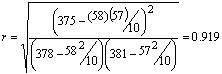
Este valor de “r” de 0.919 nos dice que hay una alta correlación entre las notas de matemáticas y español.
Para hacer la recta de regresión debemos calcular:
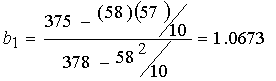
![]()
La recta de regresión esta queda determinada de la siguiente manera:
“Y = -0.4904 + 1.0673 X “.
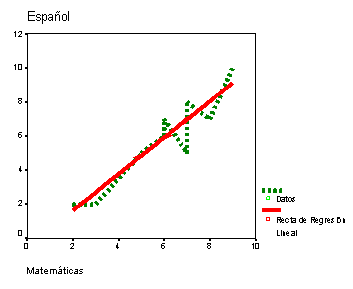
El gráfico de regresión es el siguiente:
|
|
|
Gráfico de Regresión. Se observa la recta de regresión y los datos observados en forma de línea discontinua. |
Ejercicio de Práctica: Tomar el peso y la altura de 10 personas, hacer el gráfico de dispersión, calcular el coeficiente de correlación y la recta de regresión de estos datos.
Análisis de Regresión Múltiple
A menudo en una
investigación el objetivo es explicar el comportamiento de una variable en
términos de más de una variable, por ejemplo sea la variable ![]() , cuyo comportamiento
explicaremos en términos de las variables
, cuyo comportamiento
explicaremos en términos de las variables ![]() ; ahora estudiaremos la situación donde el comportamiento de la
variable
; ahora estudiaremos la situación donde el comportamiento de la
variable ![]() (llamada
dependiente o respuesta) se explicará mediante una relación lineal en función
de las variables
(llamada
dependiente o respuesta) se explicará mediante una relación lineal en función
de las variables ![]() (llamadas independientes o también explicativas). La variable
respuesta es de tipo cuantitativa y las variables explicativas deben ser
cuantitativas y/o categóricas.(Sifuentes, V 2002)
(llamadas independientes o también explicativas). La variable
respuesta es de tipo cuantitativa y las variables explicativas deben ser
cuantitativas y/o categóricas.(Sifuentes, V 2002)
Modelo
Sea ![]() una variable respuesta y
una variable respuesta y ![]() variables
independientes; deseamos describir la relación que hay entre la variable
respuesta y las variables explicativas, si entre ellas hay una relación lineal
se espera que:
variables
independientes; deseamos describir la relación que hay entre la variable
respuesta y las variables explicativas, si entre ellas hay una relación lineal
se espera que:
![]()
![]() es la variable respuesta
cuantitativa para el i-ésimo objeto, este es un valor estimado.
es la variable respuesta
cuantitativa para el i-ésimo objeto, este es un valor estimado.
![]() , son los parámetros
poblacionales (valores constantes fijos) llamados coeficientes. Siendo “k” el número de de
variables independientes.
, son los parámetros
poblacionales (valores constantes fijos) llamados coeficientes. Siendo “k” el número de de
variables independientes.
Se espera que la variable dependiente varíe linealmente con las variables independientes.
Error del modelo
Siendo el valor observado “yi”
![]() .Donde i=1, 2,..., n objetos
de estudio. De esta ecuación se deduce que el error de cada dato,
.Donde i=1, 2,..., n objetos
de estudio. De esta ecuación se deduce que el error de cada dato, ![]() , se encuentra de
la siguiente manera:
, se encuentra de
la siguiente manera:
![]()
A ![]() se le llama error aleatorio,
es la diferencia entre el valor estimado “
se le llama error aleatorio,
es la diferencia entre el valor estimado “![]() ”menos el valor observado “yi”, esta es una distancia
entre ambos valores y puede ser negativa o positiva. Para hacer estudios
inferenciales de regresión el error debe tener las siguientes propiedades:
”menos el valor observado “yi”, esta es una distancia
entre ambos valores y puede ser negativa o positiva. Para hacer estudios
inferenciales de regresión el error debe tener las siguientes propiedades:
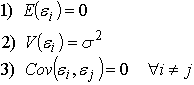
La primera propiedad indica que en promedio los errores es igual a cero, la segunda que las varianza de cada error, para un conjunto de variables “x” determinado son constantes (homocedástico) y la tercera que es que debe existir incorrelación entre los errores. (Sifuentes, V 2002)
Restricciones al modelo de Regresión Múltiple.
El modelo de una regresión múltiple sufre de restricciones cuando sus valores se quieren generalizar a una población, estas son:
· Las “xi” son variables fijas, no aleatorias, el modelo solo se aplica a los conjuntos de xi estudiados.
· Hay una sub población de “y” con distribución normal, para cada conjunto de “xi”.
· Las variancias de estas subpoblaciones son homocedásticas, lo que quiere decir que estiman una misma varianza poblacional.
· Los valores de “y” son independientes entre sí.
Coeficientes de Correlación Parcial y Múltiple
Coeficientes de correlación parcial
La correlación entre dos variables cuando una o más variables permanecen fijas a un nivel constante, se denomina correlación parcial, este coeficiente suele mejorar su valor respecto al coeficiente de correlación simple. También se utiliza para encontrar el coeficiente de correlación múltiple de manera general.
En el caso de tres viables, la correlación parcial entre “Y” y “X1”con un “X2” fijo se denota “ryx1.x2”, y se calcula a partir de las correlaciones simples de la siguiente manera:
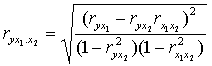
Análogamente “ryx2.x1” se calcula de igual forma
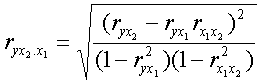
Generalizando, siempre existe una ecuación general que permite calcular un coeficiente parcial de cualquier orden “k” conocemos tres coeficientes parciales de un orden inferior donde.
Coeficiente de correlación múltiple
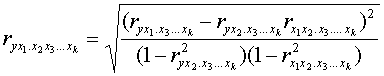
Al valor ![]() se le denomina
coeficiente de correlación múltiple y solo en el caso de regresión lineal
simple
se le denomina
coeficiente de correlación múltiple y solo en el caso de regresión lineal
simple ![]() , coincide con el
coeficiente de correlación de simple.
, coincide con el
coeficiente de correlación de simple.
Este coeficiente tiene una desventaja, su valor se incrementa cuando se introducen nuevas variables independientes en el modelo, por tanto resulta engañoso para el análisis.
El coeficiente de regresión múltiple se puede definir de manera general como la raíz cuadrada de la suma de los cuadrados explicados sobre la suma de los cuadrados totales.
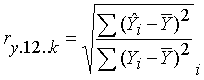
Ejemplo de cómo calcular “r” el coeficiente de correlación múltiple con tres variables “Y”, “X1” y “X2” a partir de correlaciones simples.
De manera operacional un ejemplo de tres variables se resuelve como
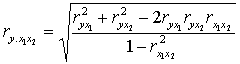
Se debe notar que en este ejemplo para hacer “ry.x1.x2” es necesario calcular previamente tres correlaciones simples de dos variables, “ryx1”,”ryx2” y “rx1x2”.
De manera general es posible encontrar una ecuación general de coeficiente de correlación múltiple que incluye “k” variables independientes, esta se puede construir a partir de los coeficientes de correlación parciales:
![]()
![]()
Como calcular los coeficientes b1 y b2 de una regresión múltiple con dos variables independientes x1 y x2.
Se debe plantear un sistema de ecuaciones normales basadas en las desviaciones a las medias como a continuación se detalla:
![]()
![]()
Para poder resolver una regresión múltiple se puede usar una calculadora de mano que tenga incorporada la función de regresión y permita calcular directamente suma de cuadrados y suma de productos de los valores de “x y”. Para esto se deben utilizar las siguientes igualdades conocidas:
![]()
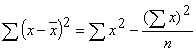
Como todas las sumatorias se pueden calcular, este sistema de ecuaciones se resuelve haciendo cero a b1 ó b2
Ejercicio: Hay una hipótesis que sugiere que el consumo de un producto dado, expresado en unidades compradas por persona en un año esta influido por: el ingreso por persona que trabaja y el tamaño de habitantes de la ciudad. Hacer estudio de regresión u correlación para responder a la suposición.
Datos
|
Millones de habitantes por ciudad x1 |
Ingreso per capita, en cientos C$ por habitante |
Consumo del producto, unidades año |
|
0.6 |
30 |
11 |
|
1.4 |
34 |
16 |
|
1.3 |
17 |
9 |
|
0.3 |
26 |
9 |
|
6.9 |
29 |
8 |
|
0.3 |
18 |
7 |
|
4.2 |
32 |
11 |
|
0.6 |
32 |
8 |
![]() El coeficiente de
regresión múltiple ry.x1x2 es igual a
El coeficiente de
regresión múltiple ry.x1x2 es igual a
La regresión se plantea como un sistema de ecuaciones normales, con los siguientes valores obtenidos a partir de las sumatorias antes definidas.
![]()
![]()
Luego se despeja b1 y b2, en este ejemplo los valores son respectivamente -0.26 y 0.28. Luego se despeja b0 sabiendo que
![]()
![]()
Pruebas de Hipótesis de Correlación y Regresión
Prueba de Hipótesis del Coeficiente de correlación simple ó múltiple
Prueba de hipótesis del coeficiente de correlación poblacional Rho, (letra griega) se estima con “r” y responde a la siguiente hipótesis:
![]()
![]()
El estadístico de Contraste es una prueba “t” donde el:
![]()
Esta prueba se hace con n-2 grados de libertad.
Ejemplo con los datos del problema de regresión y correlación con las asignaturas de “matemáticas y español” donde:
![]()
El valor 6.59 es mayor que el valor “t” de tabla de 2.3, por lo tanto se acepta como era de esperar la hipótesis alternativa, Rho es diferente de 0.
En la regresión
múltiple, se deben quitar de la ecuación aquellos parámetros no significativos,
junto con su variable asociada.![]()
9.- Coeficiente de Determinación y Análisis de Varianza en Regresión Lineal
Análisis de Variancia, ANDEVA, para la Regresión Simple ó Múltiple
El ANDEVA en este caso responde a la pregunta de hipótesis siguiente:
![]()
![]()
Esta prueba se puede usar en casos de regresión simple o de regresión múltiple.
Tabla de Análisis de Variancia, Andeva
|
Fuente Variación |
Suma de Cuadrados SC |
Grados de Libertad GL |
Cuadrado Medio CM |
“F” Calculada |
|
Total |
|
n-1
|
|
|
|
Regresión |
|
k |
|
|
|
Desviación, error |
|
n-k-1 |
|
|
Donde “k” es el número de variables independientes y el “n” número de individuos a los cuales se les toma los datos.
10.- Prueba F sobre Beta
El modelo de regresión lineal
· La relación se puede representar gráficamente mediante una línea recta.
Se supone que el error sigue una distribución normal con media cero y varianza sigma2.
· El modelo de regresión completo es
Y es el valor de la variable dependiente
A o alfa es el intercepto, donde cruza el eje Y
B o beta es la pendiente o inclinación
· Prueba de Ho: beta=0, mediante la estadística F
· Si beta es igual a cero, se concluye que:
· La relación es lineal y de fuerza para justificar el uso de ecuaciones de regresión simple para predecir y estimar Y para valores dados de X.
·
El
modelo lineal proporciona un buen ajuste para los datos, pero un modelo
curvilíneo podría proporcionar un mejor ajuste.
Correlación simple
· Es una extensión de la regresión simple.
· Mide la calidad del ajuste de una línea
· r es el coeficiente de correlación
· r2 es el coeficiente de determinación
Prueba de hipótesis
· Prueba de Ho: r=0, mediante la estadística F
· Si r es igual a cero, se concluye que no existe correlación entre las variables
Prueba de hipótesis para los coeficientes Betas
De manera particular es posible hacer una prueba de hipótesis “t” para cada coeficiente beta, donde.
![]()
![]()
Donde: 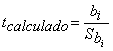
Con n-k-1 grados de libertad
Donde 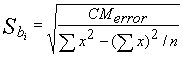
Intervalos de Confianza de los coeficientes Betas
También se pueden construir intervalos de confianza para los diferentes coeficientes de regresión Betas, estos se harían de la siguiente manera:
![]()
11. - Coeficiente de Correlación Por Calificación
Es el conjunto de técnicas estadísticas
empleado para medir la intensidad de la asociación entre dos variables.
El principal objetivo
del análisis
de correlación consiste en determinar que tan intensa es la relación entre dos
variables. Normalmente, el primer paso es mostrar los datos en un diagrama de
dispersión.
Diagrama de Dispersión.- es
aquel grafico que representa la relación entre dos variables.
Variable Dependiente.- es la variable que se predice o calcula. Cuya
representación es "Y"
Variable Independiente.- es la variable que proporciona las bases para el calculo. Cuya representación es: X1,X2,X3.......
Coeficiente de Correlación.- Describe la intensidad de la relación entre dos conjuntos de variables de nivel de intervalo. Es la medida de la intensidad de la relación lineal entre dos variables.
El valor del coeficiente de
correlación puede tomar valores desde
menos uno hasta uno, indicando que mientras más cercano a uno sea el valor del
coeficiente de correlación, en cualquier dirección, más
fuerte será la asociación lineal entre las dos variables. Mientras más cercano
a cero sea el coeficiente de correlación indicará que más débil es la
asociación entre ambas variables. Si es igual a cero se concluirá que no existe
relación lineal alguna entre ambas variables.
Análisis de regresión.- Es la técnica empleada para desarrollar la ecuación y
dar las estimaciones.
Ecuación de Regresión.- es una ecuación que define la relación lineal entre dos
variables.
Ecuación de regresión
Lineal: Y’ = a + Bx
Ecuación de regresión Lineal
Múltiple: Y’ = a + b1X1 + b2X2 + b3X3...
Principio de Mínimos Cuadrados.- Es la técnica empleada para obtener la
ecuación de regresión, minimizando la suma de los cuadrados de las distancias
verticales entre los valores verdaderos de "Y" y los valores pronosticados
"Y".
Análisis de regresión y Correlación Múltiple.- consiste en estimar una variable
dependiente, utilizando dos o más variables independientes.
Ecuación de regresión Múltiple.- La forma general de la ecuación de regresión múltiple con dos variables independientes es:
|
Y' = a + b1X1 + b2X2 |
X1,X2 : Variables Independientes
a : es la ordenada del punto
de intersección con el eje Y.
b1 : Coeficiente de Regresión (es la variación neta en Y por cada unidad de
variación en X1.).
b2 : Coeficiente de Regresión (es el cambio neto en Y para cada cambio
unitario en X2).
Prueba Global.- esta prueba investiga básicamente si es posible que todas las variables independientes tengan coeficientes de regresión neta iguales a 0.
Conclusiones
Del tema desarrollado se deriva que el análisis bivariable hace referencia al estudio de dos variables para determinar la relación y los efectos que puede o no tener una variable en otra y así obtener el comportamiento de una variable en una situación especifica o producto de su interacción con otra, debido a que en diversas oportunidades pueden resultar dependientes por lo tanto es necesario someterlo aun estudio comparativo. Estas interacciones se logran expresar en cantidades y proporciones, denominándose Asociaciones cuantitativas y en los caso en donde se expresen las características y cualidades, se llama Asociaciones Cualitativas.
Todos los elementos a los cuales se hace referencia en el presente trabajo forma parte de diferentes métodos de análisis dependiendo del caso al cual se aplique. Se inicia el trabajo con una descripción breve de lo que es una asociación de variables, las variables suelen estar representadas de una forma gráfica en plano con coordenadas abscisas (X) u horizontales y ordenadas (Y) o verticales en donde es más fácil observar el comportamiento de un resultado en relación a otra, en donde las aplicaciones de fórmulas son las que permiten analizar cada uno de los elementos que interactúan en la estrategia de las variables.
Bibliografía
Sifuentes, V.2002. Curso Análisis Multivariante aplicado a la industria pesquera. IMARPE.
Daniel, W. 2006. Bioestadística. Base para el análisis de las ciencias de la salud 4ta Edic. Edit Limusa Wiley. 924 p
Little T y Hills, J. 1990. Métodos estadísticos para la investigación en la agricultura. Edit Trillas. 270 pp.
Ross,S. 2002. Probabilidad y estadística para ingenieros. Ed Mc Graw Hill. 585 pp.
Infografía
http://es.wikipedia.org/wiki/Regresi%C3%B3n_%28estad%C3%ADstica%29
http://espanol.geocities.com/angelbartolucci/estadistica/asociacion1.htm