
Distribución de Frecuencia
Generación de Histogramas
Generación de números aleatorios
Ajustamiento
Correlación y Regresión
Otras funciones estadísticas
Coef.de.correl:
Coeficiente.asimetria:
Coeficiente.r2:
Covar:
Cuartil:
Curtosis:
Desvest:
Desvestp:
Desvia2:
Desvprom:
Error.tipico.xy:
Max:
Media.acotada:
Media.armo:
Media.geom:
Mediana:
Min:
Moda:
Pendiente:
Percentil:
Var:
Varp:
Aplicaciones Estadísticas en Excel 5.0
oy día, una planilla de cálculo es una herramienta fundamental para el análisis estadístico, ya que tiene una manera muy sencilla y rápida de solucionar nuestros problemas. Así, gracias a sus funciones, podemos realizar cálculos que nos llevarían mucho tiempo si los hiciéramos con papel y lápiz. Además, gracias a la evolución que ha tenido la informática, tanto desde el punto de vista del Hardware como del Software, tenemos en el mercado productos que nos permiten realizar nuestros trabajos de la manera más óptima, presentable y al menor costo posible.
De las actuales planillas de cálculo; la que más se destaca por su facilidad de uso, su velocidad y su potencial es la que trataremos a continuación: Excel, que en este momento se encuentra en su versión 5.0.
Las características de Excel son muchas, podemos citar 3 muy importantes:
Crear una distribución de frecuencia, nos lleva unos pocos segundos: una vez que tenemos los datos de donde extraer la distribución, creamos la tabla de clases y en el bloque de salida (donde queremos el resultado) pondremos la función frecuencia. Su sintaxis es la siguiente: =Frecuencia(Datos; Clases). Frecuencia es una función matricial, ya que el resultado que devuelve es una matriz. A estas funciones no se las ingresa de la misma manera que a las comunes (las que el resultado ocupan una sola celda). La manera de definir una función matricial es la siguiente: marcar el conjunto de celdas de salida (donde va a estar el resultado), luego escribir la función y después apretar la combinación de teclas CTRL+SHIFT+ENTER. Luego de esto se verá que la función está entre llaves, de la siguiente manera {=Frecuencia(Datos; Clases)} (en todas las celdas de Frecuencia), estas llaves indican que la función es matricial.
Notas:
Para finalizar se dará un ejemplo:
Se tienen los siguientes datos.
|
36 |
24 |
34 |
33 |
30 |
26 |
26 |
24 |
29 |
22 |
|
36 |
24 |
22 |
35 |
34 |
32 |
38 |
28 |
28 |
23 |
|
20 |
36 |
39 |
28 |
21 |
26 |
34 |
21 |
39 |
20 |
|
36 |
27 |
31 |
35 |
37 |
28 |
30 |
38 |
36 |
29 |
|
23 |
30 |
29 |
35 |
30 |
31 |
24 |
28 |
32 |
24 |
|
23 |
29 |
28 |
35 |
23 |
27 |
28 |
32 |
35 |
27 |
|
30 |
38 |
39 |
32 |
27 |
32 |
21 |
37 |
27 |
36 |
|
30 |
20 |
29 |
20 |
26 |
26 |
36 |
22 |
31 |
37 |
|
29 |
22 |
38 |
32 |
21 |
36 |
23 |
23 |
35 |
22 |
|
25 |
32 |
36 |
38 |
24 |
33 |
38 |
35 |
28 |
34 |
Para generar la distribución de frecuencia hay que saber el rango, éste se logra con el mínimo y el máximo. También la cantidad de intervalos
|
Mínimo: |
20 |
||
|
Máximo: |
39 |
||
|
Rango: |
19 |
||
|
Intervalos: |
5 |
||
|
Módulo: |
4 |
||
|
Distribución de Frecuencia |
|||
|
24 |
|||
|
28 |
|||
|
32 |
|||
|
36 |
|||
|
40 |
|||
Luego de esto se puede
armar la siguiente tabla:
Y después se ingresa la función:
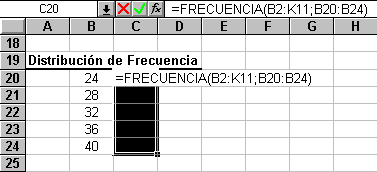
Para finalizar apretaremos Ctrl+Shift+Enter. Resultando:
Si no nos acordáramos del nombre de la función, podremos ir al asistente de funciones ![]() . Luego de hacer click en éste, nos aparecerá la siguiente pantalla:
. Luego de hacer click en éste, nos aparecerá la siguiente pantalla:

Vemos que tenemos categorías de funciones, cuando nos posicionamos en Estadísticas observamos sus funciones. Hacemos doble click sobre Frecuencia o un click y luego Siguiente, y pasamos a la próxima pantalla.
En ésta, Excel nos pide que ingresemos donde están los datos y donde los grupos. Notar que Datos y Grupos están como "requeridos", quiere decir que es obligatorio ponerlos; si no lo fueran, estarían como opcionales.

Una vez ingresados estos parámetros se hace click en Terminar. Notar que sólo queda el valor de la primera celda; para que nos devuelva la matriz hay que marcar todo el bloque de salida (si es que no se lo había seleccionado antes de ir al asistente), luego editar la celda que tiene la función (con F2) y después Ctrl+Shift+
Enter.
Una vez hecha una distribución de frecuencia, puede ser que se quiera representar gráficamente la información; para esto habrá que generar un Histograma.

Este paso es sencillo como el anterior; sólo hay que decirle a Excel que se quiere hacer un gráfico, y el nos guiará.
Para realizar un gráfico, primero hay que
seleccionar las celdas que lo conformarán:
Luego ir al ícono de asistentes para gráficos ![]() o al menú Insertar y elegir gráfico (desde el menú tendremos la opción de elegir si lo queremos en la hoja actual o en una nueva hoja); si elegimos poner el gráfico en la hoja actual el puntero del mouse cambiará a +, con él hacemos click en donde queramos que haya una esquina y desplazamos el mouse (con el botón apretado) hacia la otra esquina. Una vez hecho esto nos aparecerá la ventana de gráficos .
o al menú Insertar y elegir gráfico (desde el menú tendremos la opción de elegir si lo queremos en la hoja actual o en una nueva hoja); si elegimos poner el gráfico en la hoja actual el puntero del mouse cambiará a +, con él hacemos click en donde queramos que haya una esquina y desplazamos el mouse (con el botón apretado) hacia la otra esquina. Una vez hecho esto nos aparecerá la ventana de gráficos .

Rango es de donde a donde van los datos de los que se quiere realizar el gráfico.
Al elegir siguiente se va al próximo paso, en éste se elige el tipo de gráfico (torta, columnas, barras, 3-D, líneas, etc.), en nuestro caso será Columnas (notar que hay distintos tipos). Se debe continuar con el paso número 4, generalmente aquí no hay que cambiar nada, pero en este ejemplo se le debe indicar que la primera columna será la de los valores de X.

El gráfico resultante es el siguiente:

Anteriormente se comentó que Excel traía Herramientas para análisis estadístico y técnico. Con éstas podemos hacer muchas cosas, una de ellas es generar Histogramas, que si bien no salen como debieran, nos hacen ahorrar unos cuantos pasos.
Dichas herramientas se encuentran en el menú Herramientas; si no las llegáramos a encontrar, deberemos ir a macros automáticas y seleccionar Herramientas para análisis (si no llegara a estar la opción Macros automáticas o no llegara a estar Herramientas para análisis dentro de ésta hay que ejecutar Instalación de Excel elegir Agregar/Eliminar y marcar Macros Automáticas).
Para crear Histogramas con Análisis de datos sólo tenemos que cargarlo y elegir Histograma.

Nos aparecerá la ventana que vemos a la izquierda; en ésta pondremos el Rango de entrada (datos) y el Rango clases (clases). Tendremos la posibili-dad de elegir si queremos o no un gráfico (si no ponemos Crear gráfico el resultado será sólo una distribución de frecuencia).
Hay distintas opciones de salida: en un rango de la hoja actual, en una hoja nueva o en un libro nuevo. Las otras opciones que tiene son las siguientes:
Pareto: crea el histograma ordenado de mayor a menor.
Porcentaje acumulado: va poniendo en cada clase cual es el porcentaje acumulado.
|
Clase |
Frecuencia |
|
24 |
25 |
|
28 |
19 |
|
32 |
22 |
|
36 |
22 |
|
40 |
12 |
|
y mayor... |
0 |
Títulos: si la primera fila o columna de la selección fuera de títulos, deberemos activar esta opción.
El resultado que devuelve es el siguiente:

Vemos que las columnas del histograma están sepa-radas; para solucionarlo hay que cambiar el Ancho del intervalo de 150 a 0 (ya se ha comentado como se hace).
Generación de números aleatorios

Una vez seleccionada la opción Análisis de datos veremos una serie de herramientas, entre ellas habrá una que se llama Generación de números aleato-rios (que para eso sirve). La forma de utilización es muy fácil. Si por ejemplo queremos generar 40 números aleatorios con una distribución Uniforme entre 3 y 9 deberemos proceder de la siguiente manera: en Número de variables no pondremos nada ya que trabajamos con una sola. En Distribución elegiremos Unifor-me. Nos aparecerá Parámetros que tendrá Entre e Y (en nuestro ejemplo será entre 3 y 9) y la cantidad de números que quere-mos generar los pondremos en Cantidad de números aleatorios o en Rango de salida: si a Cantidad de números aleatorios lo dejamos en blanco y ponemos como Rango de salida A1:D10 (por ejemplo) tendremos nuestros 40 números y en el lugar que queramos. Los números también pueden ponerse En una hoja nueva o En un libro nuevo.
Además de ésta, tenemos otros tipos de distribuciones (como se ve en la ventana de arriba), cada una con sus propios parámetros. Así, por ejemplo, a la distribución Normal habrá que ingresarle el valor de la media y del desvío estándar.
Con Excel 5.0 podemos ajustar una nube de puntos con distintas funciones: lineal, polinómica (de grado 2, 3, 4, 5 y 6), potencial, logarítmica y exponencial… y de una manera muy sencilla: una vez que tenemos los datos seleccionados (valores de x y de y), tendremos que llamar al Asistente de Gráficos o elegir la opción Gráfico del menú Insertar e ingresar el área en donde vamos a poner el gráfico (de la misma manera que en Generación de Histogramas). En tipo de gráfico elegiremos dispersión y pondremos Terminar. Luego, editaremos el gráfico (recordar que se hacía con doble-click), seleccionaremos los puntos (con un click) y, apretando el botón derecho del mouse, veremos un cuadro con opciones; en éste elegiremos Insertar líneas de tendencia. Despues, nos va a aparecer un cuadro de diálogo que tendrá Tipo y Opciones. Con Tipo, elegiremos el tipo de función por la cual queremos ajustar nuestra nube de puntos; con Opciones podremos elegir dos cosas bastante interesantes: Presentar ecuación en el gráfico y Presentar el valor R en el gráfico. Éstos, lo que hacen es mostrarnos en el gráfico cual es la función de ajustamiento y cual el valor del coeficiente de regresión, respectivamente.
|
1 |
4 |
|
2 |
4 |
|
3 |
6 |
|
4 |
7 |
|
5 |
15 |
|
6 |
20 |

Si por ejemplo, tenemos estos datos y queremos ajustarlos con la función correspondiente, tendremos que graficarlos con un tipo de gráfico de dispersión. A la derecha vemos el gráfico resultante. En éste, se puede apreciar que un ajustamiento del tipo polinómico de grado 2 sería muy bueno. Para ello vamos al cuadro de diálogo de Insertar líneas de tendencia y en Tipo elegimos Polinómica y seleccionamos el grado correspondiente.

Luego podremos ir a Opciones a seleccionar Presentar ecuación en el gráfico y Presentar el valor R en el gráfico.

Luego daremos Aceptar y ya tendremos la nube de puntos ajustada, con la ecuación de ajustamiento y el coeficiente de regresión… que más podemos pedir.
Si tenemos que realizar un ajustamiento con una función del tipo hiperbólica, no podremos usar este método, sino que tendremos que "engañar" a Excel de la misma manera que a Qpro. Por lo tanto, este ajustamiento no se hará desde aquí sino desde Correlación y Regresión.
Para hacer un análisis de correlación y regresión deberemos ir a Análisis de Datos (recordar que se encontraba en el menú Herramientas) y elegir Regresión. Luego de esto nos aparecerá un cuadro de diálogo como el que se ve a continuación; éste está dividido en 2 partes: Entrada y Opciones de salida; a su vez, esta última está dividida en Residuales y Probabilidad normal.

Entrada: en esta se ingresarán los datos (valores de x y de y). Además, hay tres opciones:
Títulos: habrá que seleccionar esta opción si la primera fila del rango de entrada contiene los títulos de las columnas.
Constante igual a cero: se deberá seleccio-nar esta opción si se quiere que, incondi-cionalmente, la curva de regresión pase por el origen de coordenadas.
Nivel de confianza: el valor predeterminado de ésta es del 95%. Esto, hará que en la tabla de salida de regresión se muestre una columna con "inferior al 95%" y otra con "superior al 95%"; si se quiere ver otro "nivel de confianza", deberá ser elegido desde aquí.
Opciones de salida: tendremos la opción de elegir donde va a salir la tabla de regresión: si la queremos en la hoja actual, en otra hoja o en otro libro. Para que salga en la hoja actual tendremos que seleccionar Rango de Salida e ingresar la celda superior izquierda del área en donde va a estar la tabla. Para que salga en una hoja nueva tendremos que seleccionar En una hoja nueva y, en el espacio en blanco, podremos poner (no es necesario que se haga) el nombre de la nueva hoja. Y para que salga en un libro nuevo tendremos que seleccionar En un libro nuevo. En esta última no tenemos la posibilidad de ingresar un nombre ya que no lo podremos hacer hasta que grabemos el libro.
Residuos: tendremos que seleccionar esta opción si queremos que en la tabla de regresión nos aparezcan los residuos.
Residuos estándares: seleccionaremos esta opción si queremos que en la tabla de regresión aparezcan los residuos estándares... que otra cosa podría ser!.
Gráfico de residuales: habrá que seleccionar esta opción si queremos que Excel nos genere un gráfico con los residuos de cada uno de los valores de la variable independiente.
Curva de regresión ajustada: esta opción nos genera un gráfico donde se ven los valores observados y los pronosticados.
Trazado de probabilidad normal: seleccionaremos esta opción si queremos que Excel nos genere un gráfico con el trazado de probabilidades normales. (Debe entender el lector que estamos en la hoja 12)
Luego de haber ingresado todos los datos que necesitábamos para la regresión haremos click en Aceptar y Excel nos generará la tabla de regresión en el lugar solicitado (en la hoja actual, en otra hoja o en otro libro).

Haremos el análisis de correlación y regresión con los valores que se ven a la izquierda. Para esto, en el cuadro de regresión ingresaremos los siguientes datos:
Rango Y de entrada: B1:B6
Rango X de entrada: A1:A6
Y luego haremos click en Aceptar. Quedándonos las siguientes tablas (algunos títulos sido han simplificados para que las tablas entren en la hoja)
|
Estadísticas de la regresión |
|
|
Coeficiente de correlación múltiple |
0.986504105 |
|
Coeficiente de determinación R^2 |
0.973190349 |
|
R^2 ajustado |
0.966487936 |
|
Error típico |
0.763762616 |
|
Observaciones |
6 |
|
ANÁLISIS DE VARIANZA |
|||||
|
Grados de libertad |
Suma de 2 |
Prom. de los 2 |
F |
Valor crítico de F |
|
|
Regresión |
1 |
84.7 |
84.7 |
145.2 |
0.00027198 |
|
Residuos |
4 |
2.333333333 |
0.583333333 |
||
|
Total |
5 |
87.03333333 |
|||
|
Coeficientes |
Error típico |
Estadístico t |
Prob. |
Inferior 95% |
Superior 95% |
|||
|
Intercepción |
1.433333333 |
0.7110243 |
2.01587109 |
0.1140 |
-0.540790 |
3.4074573 |
||
| Variable X 1 |
2.2 |
0.1825741 |
12.0498962 |
0.0002 |
1.6930917 |
2.7069082 |
||
|
Análisis de los residuales |
||||||||
|
Observación |
Pronóstico para Y |
Residuos |
||||||
|
1 |
3.633333333 |
-0.63333333 |
||||||
|
2 |
5.833333333 |
0.66666667 |
||||||
|
3 |
8.033333333 |
-0.03333333 |
||||||
|
4 |
10.23333333 |
0.76666667 |
||||||
|
5 |
12.43333333 |
-0.93333333 |
||||||
|
6 |
14.63333333 |
0.16666667 |
||||||
Para finalizar comentaremos las funciones estadísticas que no se han comentado hasta el momento.
Nota: cuando se habla de matriz, se está hablando de un rango definido de la siguiente manera A1:A20 (por ejemplo).
Calcula el coeficiente de correlación entre dos rangos de celdas definidos por los argumentos matriz1 y matriz2. El coeficiente de correlación se usa para determinar la relación entre dos variables. Por ejemplo, para examinar la relación entre la temperatura promedio de una localidad y el uso de aire acondicionado.
Sintaxis
=COEF.DE.CORREL(matriz1; matriz2)
Matriz1: es un rango de celdas de valores.
Matriz2: es un segundo rango de celdas de valores.
Calcula la asimetría de una distribución. Esta función caracteriza el grado de asimetría de una distribución con respecto a su media. La asimetría positiva indica una distribución unilateral que se extiende hacia valores más positivos. La asimetría negativa indica una distribución unilateral que se extiende hacia valores más negativos.
Sintaxis
=COEFICIENTE.ASIMETRIA(número1; número2; ...)
Número1;número2; ... son de 1 a 30 argumentos cuya asimetría deseamos calcular. También podemos
utilizar una matriz única en lugar de argumentos separados con punto y coma.
Calcula el valor R cuadrado para una línea de regresión lineal creada con los datos de los argumentos matriz_x y matriz_y.. El coeficiente de determinación r2 se puede interpretar como la proporción de la varianza de y, que puede atribuirse a la varianza de x.
Sintaxis
=COEFICIENTE.R2(matriz_y; matriz_x)
Matriz_y: es una matriz o rango de puntos de datos.
Matriz_x: es una matriz o rango de puntos de datos.
Calcula la covarianza, o promedio de los productos entre las desviaciones, de los valores por
pares. Deberemos usar la covarianza para determinar la relación entre dos conjuntos de datos, por ejemplo, para examinar si un nivel elevado de ingresos corresponde a un mayor nivel educativo.
Sintaxis
=COVAR(matriz1; matriz2)
Matriz1: es el primer rango de celdas de números enteros.
Matriz2 es el segundo rango de celdas de números enteros.
Devuelve el cuartil de un conjunto de datos. Los cuartiles se usan con frecuencia en los datos de
ventas y encuestas para dividir las poblaciones en grupos. Por ejemplo, podemos utilizar la función CUARTIL para determinar el 25% de ingresos más altos en una población.
Sintaxis
=CUARTIL(matriz; cuartil)
Matriz: es la matriz o rango de celdas de valores numéricos cuyo cuartil desea obtener.
Cuartil: indica qué valor devolver.
Si cuartil es igual a La función CUARTIL devuelve
0 El valor mínimo
1 El primer cuartil (percentil 25)
2 El valor de la mediana (percentil 50)
3 El tercer cuartil (percentil 75)
4 El valor máximo
Calcula la curtosis de un conjunto de datos. La curtosis representa la elevación o achatamiento de una distribución, comparada con la distribución normal. Una curtosis positiva indica una distribución relativamente elevada, mientras que una curtosis negativa indica una distribución relativamente plana.
Sintaxis
=CURTOSIS(número1; número2, ...)
Número1;número2; ... son de 1 a 30 argumentos cuya curtosis deseamos calcular. También podemos utilizar una sola matriz en lugar de argumentos separados con punto y coma.
Calcula la desviación estándar de una muestra. La desviación estándar es la medida de la dispersión de los valores respecto a la media.
Sintaxis
=DESVEST(número1; número2; ...)
Número1; número2; ... son de 1 a 30 argumentos numéricos que corresponden a una muestra de población. También podemos utilizar una matriz única en lugar de argumentos separados con punto y coma.
Calcula la desviación estándar de la población total determinada por los argumentos. La desviación estándar es la medida de la dispersión de los valores respecto a la media.
Sintaxis
=DESVESTP(número1; número2; ...)
Número1; número2; ... son de 1 a 30 argumentos numéricos que corresponden a la población. También podemos utilizar una matriz única en lugar de argumentos separados con punto y coma.
Devuelve la suma de los cuadrados de las desviaciones de los puntos de datos a partir de la media de la muestra.
Sintaxis
=DESVIA2(número1; número2; ...)
Número1; número2 son de 1 a 30 argumentos cuya suma de las desviaciones cuadradas deseamos calcular. También podemos usar una sola matriz en lugar de argumentos separados con punto y coma.
Devuelve el promedio de las desviaciones absolutas de la media de los puntos de datos.
DESVPROM mide la dispersión de los valores en un conjunto de datos.
Sintaxis
=DESVPROM(número1; número2; ...)
Número1; número2; ... son de 1 a 30 argumentos cuyo promedio de las desviaciones absolutas deseamos calcular. También podemos usar una sola matriz en lugar de usar argumentos separados con punto y coma.
Devuelve el error típico del valor de y previsto para cada x de la regresión El error típico es una medida de la cuantía de error en el pronóstico del valor de y para un valor individual de x.
Sintaxis
=ERROR.TIPICO.XY(matriz_y; matriz_x)
Matriz_y: es una matriz o rango de puntos de datos dependientes.
Matriz_x: es una matriz o rango de puntos de datos independientes.
Devuelve el valor máximo de una lista de argumentos.
Sintaxis
MAX(número1;número2; ...)
Número1; número2; ... son entre 1 y 30 números para los que deseamos encontrar el valor máximo. También podemos usar una sola matriz en lugar de argumentos separados con punto y coma.
Devuelve la media del interior del conjunto de datos. MEDIA.ACOTADA calcula la media de un conjunto de datos después de eliminar el porcentaje de los extremos inferior y superior de los puntos de datos. Podemos utilizar esta función cuando queramos excluir del análisis los valores extremos.
Sintaxis
=MEDIA.ACOTADA(matriz; porcentaje)
Matriz: es la matriz o rango de valores que deseamos acotar y de los cuales se calculará la media.
Porcentaje: es el número fraccionario de observaciones que se excluyen del cálculo. Por ejemplo, si porcentaje = 0,2; se eliminarán cuatro puntos de un conjunto de datos de 20 puntos (20 x 0,2), dos de la parte superior y dos de la parte inferior del conjunto de datos.
Devuelve la media armónica de un conjunto de datos. La media armónica es la inversa de la media aritmética de los valores recíprocos.
Sintaxis
=MEDIA.ARMO(número1; número2; ...)
Número1;número2; ... son de 1 a 30 argumentos cuya media deseamos calcular. También podemos utilizar una sola matriz en lugar de argumentos separados con punto y coma.
Devuelve la media geométrica de una matriz o de un rango de datos positivos. Por ejemplo, es posible utilizar la función MEDIA.GEOM para calcular la tasa de crecimiento promedio, dado un interés compuesto por tasas variables.
Sintaxis
=MEDIA.GEOM(número1; número2; ...)
Número1;número2, ... son de 1 a 30 argumentos cuya media deseamos calcular. También podemos utilizar una matriz única en lugar de utilizar argumentos separados con punto y coma.
Devuelve la mediana de los números. La mediana es el número que se encuentra en medio de un conjunto de números, es decir, la mitad de los números es mayor que la mediana y la otra mitad es
menor.
Sintaxis
=MEDIANA(número1; número2; ...)
Número1; número2; ... son entre 1 y 30 números cuya mediana deseamos obtener. También podemos utilizar una matriz única en lugar de utilizar argumentos separados con punto y coma.
Devuelve el valor mínimo de una lista de argumentos.
Sintaxis
MIN(número1; número2; ...)
Número1; número2; ... son entre 1 a 30 números cuyos valores mínimos desea encontrar. También podemos utilizar una matriz única en lugar de utilizar argumentos separados con punto y coma.
Devuelve el valor que se repite con más frecuencia en una matriz o rango de datos. Al igual que MEDIANA, MODA es una medida de posición.
Sintaxis
=MODA(número1; número2; ...)
Número1; número2; ... son entre 1 y 30 argumentos cuya moda deseamos calcular. También podemos usar una matriz única en lugar de argumentos separados por punto y coma.
Devuelve la pendiente de una línea de regresión lineal creada con los datos de los argumentos matriz_x y matriz_y. La pendiente es la distancia vertical dividida por la distancia horizontal entre dos puntos cualquiera de la recta, lo que corresponde a la tasa de cambio a lo largo de la línea de regresión.
Sintaxis
=PENDIENTE(matriz_y; matriz_x)
Matriz_y: es una matriz o rango de observaciones numéricos dependientes.
Matriz_x: es el conjunto de observaciones independientes.
Devuelve el k-ésimo percentil de los valores de un rango. Esta función permite establecer un umbral de aceptación. Por ejemplo, podremos examinar a los candidatos cuya calificación sea superior al nonagésimo percentil.
Sintaxis
=PERCENTIL(matriz; k)
Matriz: es la matriz o rango de datos que define la posición relativa.
K: es el valor de percentil, debe estar en el intervalo de 0 a 1, inclusive.
Calcula la varianza de una muestra.
Sintaxis
=VAR(número1; número2; ...)
Número1; número2; ... son de 1 a 30 argumentos numéricos que se corresponden con una muestra de población. También podemos utilizar una matriz única en lugar de utilizar argumentos separados con punto y coma.
Calcula la varianza de la población total.
Sintaxis
=VARP(número1; número2; ...)
Número1; número2; ... son de 1 a 30 argumentos numéricos que se corresponden con una población. También podemos utilizar una matriz única en lugar de utilizar argumentos separados con punto y coma.