[Índice TCP/IP] ·
[Anterior] · [Publicaciones] · [Saulo.Net]
2.7 Protocolo ICMP
Debido a que el protocolo IP no es fiable, los datagramas pueden perderse o llegar defectuosos a su destino. El protocolo ICMP (Internet Control Message Protocol, protocolo de mensajes de control y error) se encarga de informar al origen si se ha producido algún error durante la entrega de su mensaje. Pero no sólo se encarga de notificar los errores, sino que también transporta distintos mensajes de control.
Nota: El protocolo ICMP está definido en la RFC 792 (en inglés, en español)
El protocolo ICMP únicamente informa de incidencias en la red pero no toma
ninguna decisión. Esto será responsabilidad de las capas superiores.
Los mensajes ICMP viajan en el campo de datos de un datagrama IP, como se puede apreciar en
el siguiente esquema:
| Tipo | Datos ICMP | |||
| Encabezado del datagrama | Área de datos del datagrama IP | |||
| Encabezado de la trama | Área de datos de la trama | Final de la trama | ||
Debido a que el protocolo IP no es fiable puede darse el caso de que un mensaje ICMP se pierda o se dañe. Si esto llega a ocurrir no se creará un nuevo mensaje ICMP sino que el primero se descartará sin más.
Los mensajes ICMP comienzan con un campo de 8 bits que contiene el tipo de mensaje, según se muestra en la tabla siguiente. El resto de campos son distintos para cada tipo de mensaje ICMP.
Nota: El formato y significado de cada mensaje ICMP está documentado en la RFC 792 (en inglés, en español).
| Campo de tipo | Tipo de mensaje ICMP | |
| 0 | Respuesta de eco (Echo Reply) | |
| 3 | Destino inaccesible (Destination Unreachable) | |
| 4 | Disminución del tráfico desde el origen (Source Quench) | |
| 5 | Redireccionar (cambio de ruta) (Redirect) | |
| 8 | Solicitud de eco (Echo) | |
| 11 | Tiempo excedido para un datagrama (Time Exceeded) | |
| 12 | Problema de Parámetros (Parameter Problem) | |
| 13 | Solicitud de marca de tiempo (Timestamp) | |
| 14 | Respuesta de marca de tiempo (Timestamp Reply) | |
| 15 | Solicitud de información (obsoleto) (Information Request) | |
| 16 | Respuesta de información (obsoleto) (Information Reply) | |
| 17 | Solicitud de máscara (Addressmask) | |
| 18 | Respuesta de máscara (Addressmask Reply) |
Los mensajes de solicitud y respuesta de eco, tipos 8 y 0 respectivamente, se utilizan para comprobar si existe comunicación entre 2 hosts a nivel de la capa de red. Estos mensajes comprueban que las capas física (cableado), acceso al medio (tarjetas de red) y red (configuración IP) están correctas. Sin embargo, no dicen nada de las capas de transporte y de aplicación las cuales podrían estar mal configuradas; por ejemplo, la recepción de mensajes de correo electrónico puede fallar aunque exista comunicación IP con el servidor de correo.
La orden PING envía mensajes de solicitud de eco a un host remoto e informa de las respuestas. Veamos su funcionamiento, en caso de no producirse incidencias en el camino.
En la orden anterior hemos utilizado el parámetro "-n 1" para que el host A únicamente envíe 1 mensaje de solicitud de eco. Si no se especifica este parámetro se enviarían 4 mensajes (y se recibirían 4 respuestas). Si el host de destino no existiese o no estuviera correctamente configurado recibiríamos un mensaje ICMP de tipo 11 (Time Exceeded).
Si tratamos de acceder a un host de una red distinta a la nuestra y no existe un camino para llegar hasta él, es decir, los routers no están correctamente configurados o estamos intentando acceder a una red aislada o inexistente, recibiríamos un mensaje ICMP de tipo 3 (Destination Unreachable).
|
Utilización de PING para diagnosticar errores en una red aislada

A>ping 192.168.1.12
Respuesta. El cableado entre A y B, las tarjetas de red de A y B, y la configuración IP de A y B están correctos.
Nota: El comando ping 127.0.0.1 informa de si están correctamente instalados los protocolos TCP/IP en nuestro host. No informa de si la tarjeta de red de nuestro host está correcta.
Utilización de PING para diagnosticar errores en una red de redes
A continuación veremos un ejemplo para una red de redes formada por dos redes (1 solo router). La idea es la misma para un mayor número de redes y routers.

A>ping 10.100.5.1
Respuesta. El cableado entre A y B, las tarjetas de red de A, R1 y B, y la configuración IP de A, R1 y B están correctos. El router R1 permite el tráfico de datagramas IP en los dos sentidos.
En el caso producirse errores de comunicación en una red de redes con más de un router (Internet es el mejor ejemplo), se suele utilizar el comando PING para ir diagnosticando los distintos routers desde el destino hasta el origen y descubrir así si el fallo es responsabilidad de la red de destino, de una red intermedia o de nuestra red.
Nota: Algunos hosts en Internet tienen deshabilitadas las respuestas de eco (mensajes ICMP tipo 0) como medida de seguridad. En estos casos hay que utilizar otros mecanismos para detectar si responde (por ejemplo, la apertura de conexión a un puerto, como veremos en el capítulo siguiente).
Mensajes ICMP de tiempo excedido
Los datagramas IP tienen un campo TTL (tiempo de vida) que impide que un mensaje esté dando vueltas indefinidamente por la red de redes. El número contenido en este campo disminuye en una unidad cada vez que el datagrama atraviesa un router. Cuando el TTL de un datagrama llega a 0, éste se descarta y se envía un mensaje ICMP de tipo 11 (Time Exceeded) para informar al origen.
Los mensajes ICMP de tipo 11 se pueden utilizar para hacer una traza del camino que siguen los datagramas hasta llegar a su destino. ¿Cómo? Enviando una secuencia de datagramas con TTL=1, TTL=2, TTL=3, TTL=4, etc... hasta alcanzar el host o superar el límite de saltos (30 si no se indica lo contrario). El primer datagrama caducará al atravesar el primer router y se devolverá un mensaje ICMP de tipo 11 informando al origen del router que descartó el datagrama. El segundo datagrama hará lo propio con el segundo router y así sucesivamente. Los mensajes ICMP recibidos permiten definir la traza.
La orden TRACERT (traceroute en entornos Unix) hace una traza a un determinado host. TRACERT funciona enviando mensajes ICMP de solicitud de eco con distintos TTL; traceroute, en cambio, envía mensajes UDP. Si la comunicación extremo a extremo no es posible, la traza nos indicará en qué punto se ha producido la incidencia. Existen algunas utilidades en Internet, como Visual Route, que conocen la localización geográfica de los principales routers de Internet. Esto permite dibujar en un mapamundi el recorrido que siguen los datagramas hasta llegar a un host.
|
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
2.8 Encaminamiento
Una red de redes está formada por redes interconectadas mediante routers o encaminadores. Cuando enviamos un datagrama desde un ordenador hasta otro, éste tiene que ser capaz de encontrar la ruta más adecuada para llegar a su destino. Esto es lo que se conoce como encaminamiento.
Los routers (encaminadores) son los encargados de elegir las mejores rutas. Estas máquinas pueden ser ordenadores con varias direcciones IP o bien, aparatos específicos. Los routers deben conocer, al menos parcialmente, la estructura de la red que les permita encaminar de forma correcta cada mensaje hacia su destino. Esta información se almacena en las llamadas tablas de encaminamiento. Observemos que debido al sistema de direccionamiento IP esta misión no es tan complicada. Lo único que necesitamos almacenar en las tablas son los prefijos de las direcciones (que nos indican la red). Por ejemplo, si el destino es la máquina 149.33.19.4 con máscara 255.255.0.0, nos basta con conocer el encaminamiento de la red 149.33.0.0 ya que todas las que empiecen por 149.33 se enviarán hacia el mismo sitio.
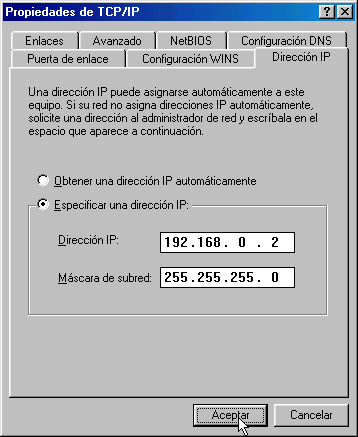
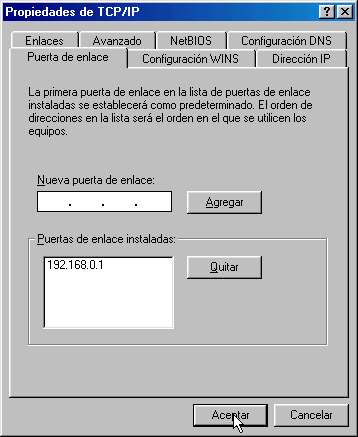
La orden Route muestra y modifica la tabla de encaminamiento de un host. Todos los hosts (y no sólo los routers) tienen tablas de encaminamientos. A continuación se muestra una tabla sencilla para un host con IP 192.168.0.2 / 255.255.255.0 y puerta de salida 192.168.0.1.
Estas tabla se lee de abajo a arriba. La línea (1) indica que los datagramas con destino "255.255.255.255" (dirección de difusión a la red del host) deben ser aceptados. La línea (2) representa un grupo de multidifusión (multicasting). La dirección "224.0.0.0" es una dirección de clase D que se utiliza para enviar mensajes a una colección de hosts registrados previamente. Estas dos líneas se suelen pasar por alto: aparecen en todas las tablas de rutas. La línea (3) indica que todos los mensajes cuyo destinatario sea "192.168.0.255" deben ser aceptados (es la dirección de difusión a la red del host). La línea (4) se encarga de aceptar todos los mensajes que vayan destinados a la dirección del host "192.168.0.2". La línea (5) indica que los mensajes cuyo destinatario sea una dirección de la red del host "192.168.0.0 / 255.255.255.0" deben salir del host por su tarjeta de red para que se entreguen directamente en su subred. La línea (6) es la dirección de loopback: todos los paquetes con destino "127.0.0.0 / 255.0.0.0" serán aceptados por el propio host. Finalmente, la línea (7) representa a "todas las demás direcciones que no se hayan indicado anteriormente". En concreto son aquellas direcciones remotas que no pertenecen a la red del host. ¿A dónde se enviarán? Se enviarán a la puerta de salida (gateway) de la red "192.168.0.1". Nótese que la tabla de rutas es la traducción de la configuración IP del host que habitualmente se escribe en las ventanas de Windows:
|
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
Capítulo 3
Capa de transporte
La capa de red transfiere datagramas entre dos ordenadores a través de la red utilizando como identificadores las direcciones IP. La capa de transporte añade la noción de puerto para distinguir entre los muchos destinos dentro de un mismo host. No es suficiente con indicar la dirección IP del destino, además hay que especificar la aplicación que recogerá el mensaje. Cada aplicación que esté esperando un mensaje utiliza un número de puerto distinto; más concretamente, la aplicación está a la espera de un mensaje en un puerto determinado (escuchando un puerto).
Pero no sólo se utilizan los puertos para la recepción de mensajes, también para el envío: todos los mensajes que envíe un ordenador debe hacerlo a través de uno de sus puertos. El siguiente diagrama representa una transmisión entre el ordenador 194.35.133.5 y el 135.22.8.165. El primero utiliza su puerto 1256 y el segundo, el 80.

La capa de transporte transmite mensajes entre las aplicaciones de dos ordenadores. Por ejemplo, entre nuestro navegador de páginas web y un servidor de páginas web, o entre nuestro programa de correo electrónico y un servidor de correo.
| HTTP (navegador web) |
HTTP (servidor web) |
Capa de aplicación | |||||
| mensaje HTTP | |||||||
| TCP (puerto mayor de 1024) |
TCP (puerto 80) |
Capa de transporte | |||||
| segmento TCP | |||||||
| IP (dirección IP privada o pública dinámica) |
IP (direcciones IP públicas) |
IP (dirección IP pública estática) |
Capa de red | ||||
| datagrama IP | |||||||
| Ethernet (dirección física) |
Ethernet (direcciones físicas) |
Ethernet (dirección física) |
Capa de acceso a la red |
||||
| trama Ethernet | |||||||
| UTP CAT 5 | UTP CAT5 en ambas redes | UTP CAT 5 | Capa física secuencia de bits |
||||
| Red 1 | Red n | ||||||
| Cliente | Secuencia de n routers | Servidor | |||||
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
3.1 Puertos
Un ordenador puede estar conectado con distintos servidores a la vez; por ejemplo, con un servidor de noticias y un servidor de correo. Para distinguir las distintas conexiones dentro de un mismo ordenador se utilizan los puertos.
Un puerto es un número de 16 bits, por lo que existen 65536 puertos en cada ordenador. Las aplicaciones utilizan estos puertos para recibir y transmitir mensajes.
Los números de puerto de las aplicaciones cliente son asignados dinámicamente y generalmente son superiores al 1024. Cuando una aplicación cliente quiere comunicarse con un servidor, busca un número de puerto libre y lo utiliza.
En cambio, las aplicaciones servidoras utilizan unos números de puerto prefijados: son los llamados puertos well-known (bien conocidos). Estos puertos están definidos en la RFC 1700 y se pueden consultar en http://www.ietf.org/rfc/rfc1700.txt. A continuación se enumeran los puertos well-known más usuales:
| Palabra clave | Puerto | Descripción |
| 0/tcp | Reserved | |
| 0/udp | Reserved | |
| tcpmux | 1/tcp | TCP Port Service Multiplexer |
| rje | 5/tcp | Remote Job Entry |
| echo | 7/tcp/udp | Echo |
| discard | 9/tcp/udp | Discard |
| systat | 11/tcp/udp | Active Users |
| daytime | 13/tcp/udp | Daytime |
| qotd | 17/tcp/udp | Quote of the Day |
| chargen | 19/tcp/udp | Character Generator |
| ftp-data | 20/tcp | File Transfer [Default Data] |
| ftp | 21/tcp | File Transfer [Control] |
| telnet | 23/tcp | Telnet |
| smtp | 25/tcp | Simple Mail Transfer |
| time | 37/tcp/udp | Time |
| nameserver | 42/tcp/udp | Host Name Server |
| nicname | 43/tcp/udp | Who Is |
| domain | 53/tcp/udp | Domain Name Server |
| bootps | 67/udp/udp | Bootstrap Protocol Server |
| tftp | 69/udp | Trivial File Transfer |
| gopher | 70/tcp | Gopher |
| finger | 79/tcp | Finger |
| www-http | 80/tcp | World Wide Web HTTP |
| dcp | 93/tcp | Device Control Protocol |
| supdup | 95/tcp | SUPDUP |
| hostname | 101/tcp | NIC Host Name Server |
| iso-tsap | 102/tcp | ISO-TSAP |
| gppitnp | 103/tcp | Genesis Point-to-Point Trans Net |
| rtelnet | 107/tcp/udp | Remote Telnet Service |
| pop2 | 109/tcp | Post Office Protocol - Version 2 |
| pop3 | 110/tcp | Post Office Protocol - Version 3 |
| sunrpc | 111/tcp/udp | SUN Remote Procedure Call |
| auth | 113/tcp | Authentication Service |
| sftp | 115/tcp/udp | Simple File Transfer Protocol |
| nntp | 119/tcp | Network News Transfer Protocol |
| ntp | 123/udp | Network Time Protocol |
| pwdgen | 129/tcp | Password Generator Protocol |
| netbios-ns | 137/tcp/udp | NETBIOS Name Service |
| netbios-dgm | 138/tcp/udp | NETBIOS Datagram Service |
| netbios-ssn | 139/tcp/udp | NETBIOS Session Service |
| snmp | 161/udp | SNMP |
| snmptrap | 162/udp | SNMPTRAP |
| irc | 194/tcp | Internet Relay Chat Protocol |
Los puertos tienen una memoria intermedia (buffer) situada entre los programas de aplicación y la red. De tal forma que las aplicaciones transmiten la información a los puertos. Aquí se va almacenando hasta que pueda enviarse por la red. Una vez que pueda transmitirse, la información irá llegando al puerto destino donde se irá guardando hasta que la aplicación esté preparada para recibirla.
Los dos protocolos principales de la capa de transporte son UDP y TCP. El primero ofrece una transferencias de mensajes no fiable y no orientada a conexión y el segundo, una transferencia fiable y orientada a conexión.
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
3.2 Protocolo UDP
El protocolo UDP (User Datagram Protocol, protocolo de datagrama de usuario) proporciona una comunicación muy sencilla entre las aplicaciones de dos ordenadores. Al igual que el protocolo IP, UDP es:
No orientado a conexión. No se establece una conexión previa con el otro extremo para transmitir un mensaje UDP. Los mensajes se envían sin más y éstos pueden duplicarse o llegar desordenados al destino.
No fiable. Los mensajes UDP se pueden perder o llegar dañados.
UDP utiliza el protocolo IP para transportar sus mensajes. Como vemos, no añade ninguna mejora en la calidad de la transferencia; aunque sí incorpora los puertos origen y destino en su formato de mensaje. Las aplicaciones (y no el protocolo UDP) deberán programarse teniendo en cuenta que la información puede no llegar de forma correcta.
| Encabezado UDP | Área de datos UDP | |||
| Encabezado del datagrama | Área de datos del datagrama IP | |||
| Encabezado de la trama | Área de datos de la trama | Final de la trama | ||
| 0 | 10 | 20 | 30 | ||||||||||||||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 | 3 | 3 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 |
| Puerto UDP origen | Puerto UDP destino | ||||||||||||||||||||||||||||||
| Longitud mensaje UDP | Suma verificación UDP | ||||||||||||||||||||||||||||||
| Datos | |||||||||||||||||||||||||||||||
| ... | |||||||||||||||||||||||||||||||
Puerto UDP de origen (16 bits, opcional). Número de puerto de la máquina origen.
Puerto UDP de destino (16 bits). Número de puerto de la máquina destino.
Longitud del mensaje UDP (16 bits). Especifica la longitud medida en bytes del mensaje UDP incluyendo la cabecera. La longitud mínima es de 8 bytes.
Suma de verificación UDP (16 bits, opcional). Suma de comprobación de errores del mensaje. Para su cálculo se utiliza una pseudo-cabecera que también incluye las direcciones IP origen y destino. Para conocer estos datos, el protocolo UDP debe interactuar con el protocolo IP.
Datos. Aquí viajan los datos que se envían las aplicaciones. Los mismos datos que envía la aplicación origen son recibidos por la aplicación destino después de atravesar toda la Red de redes.
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
3.3 Protocolo TCP
El protocolo TCP (Transmission Control Protocol, protocolo de control de transmisión) está basado en IP que es no fiable y no orientado a conexión, y sin embargo es:
Orientado a conexión. Es necesario establecer una conexión previa entre las dos máquinas antes de poder transmitir ningún dato. A través de esta conexión los datos llegarán siempre a la aplicación destino de forma ordenada y sin duplicados. Finalmente, es necesario cerrar la conexión.
Fiable. La información que envía el emisor llega de forma correcta al destino.
El protocolo TCP permite una comunicación fiable entre dos aplicaciones. De esta forma, las aplicaciones que lo utilicen no tienen que preocuparse de la integridad de la información: dan por hecho que todo lo que reciben es correcto.
El flujo de datos entre una aplicación y otra viajan por un circuito virtual. Sabemos que los datagramas IP pueden seguir rutas distintas, dependiendo del estado de los encaminadores intermedios, para llegar a un mismo sitio. Esto significa que los datagramas IP que transportan los mensajes siguen rutas diferentes aunque el protocolo TCP logré la ilusión de que existe un único circuito por el que viajan todos los bytes uno detrás de otro (algo así como una tubería entre el origen y el destino). Para que esta comunicación pueda ser posible es necesario abrir previamente una conexión. Esta conexión garantiza que los todos los datos lleguen correctamente de forma ordenada y sin duplicados. La unidad de datos del protocolo es el byte, de tal forma que la aplicación origen envía bytes y la aplicación destino recibe estos bytes.
Sin embargo, cada byte no se envía inmediatamente después de ser generado por la aplicación, sino que se espera a que haya una cierta cantidad de bytes, se agrupan en un segmento y se envía el segmento completo. Para ello son necesarias unas memorias intermedias o buffers. Cada uno de estos segmentos viaja en el campo de datos de un datagrama IP. Si el segmento es muy grande será necesario fragmentar el datagrama, con la consiguiente pérdida de rendimiento; y si es muy pequeño, se estarán enviando más cabeceras que datos. Por consiguiente, es importante elegir el mayor tamaño de segmento posible que no provoque fragmentación.
El protocolo TCP envía un flujo de información no estructurado. Esto significa que los datos no tienen ningún formato, son únicamente los bytes que una aplicación envía a otra. Ambas aplicaciones deberán ponerse de acuerdo para comprender la información que se están enviando.
Cada vez que se abre una conexión, se crea un canal de comunicación bidireccional en el que ambas aplicaciones pueden enviar y recibir información, es decir, una conexión es full-dúplex.
¿Cómo es posible enviar información fiable basándose en un protocolo no fiable? Es decir, si los datagramas que transportan los segmentos TCP se pueden perder, ¿cómo pueden llegar los datos de las aplicaciones de forma correcta al destino?
La respuesta a esta pregunta es sencilla: cada vez que llega un mensaje se devuelve una confirmación (acknowledgement) para que el emisor sepa que ha llegado correctamente. Si no le llega esta confirmación pasado un cierto tiempo, el emisor reenvía el mensaje.
Veamos a continuación la manera más sencilla (aunque ineficiente) de proporcionar una comunicación fiable. El emisor envía un dato, arranca su temporizador y espera su confirmación (ACK). Si recibe su ACK antes de agotar el temporizador, envía el siguiente dato. Si se agota el temporizador antes de recibir el ACK, reenvía el mensaje. Los siguientes esquemas representan este comportamiento:
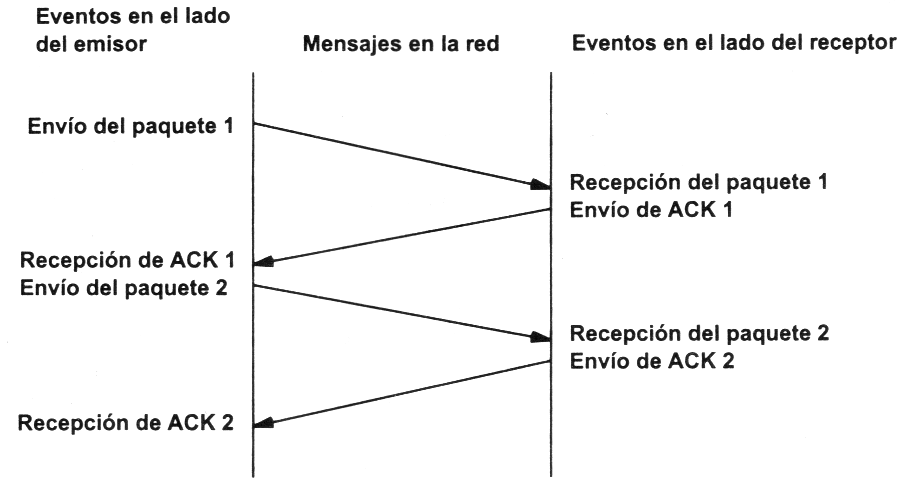
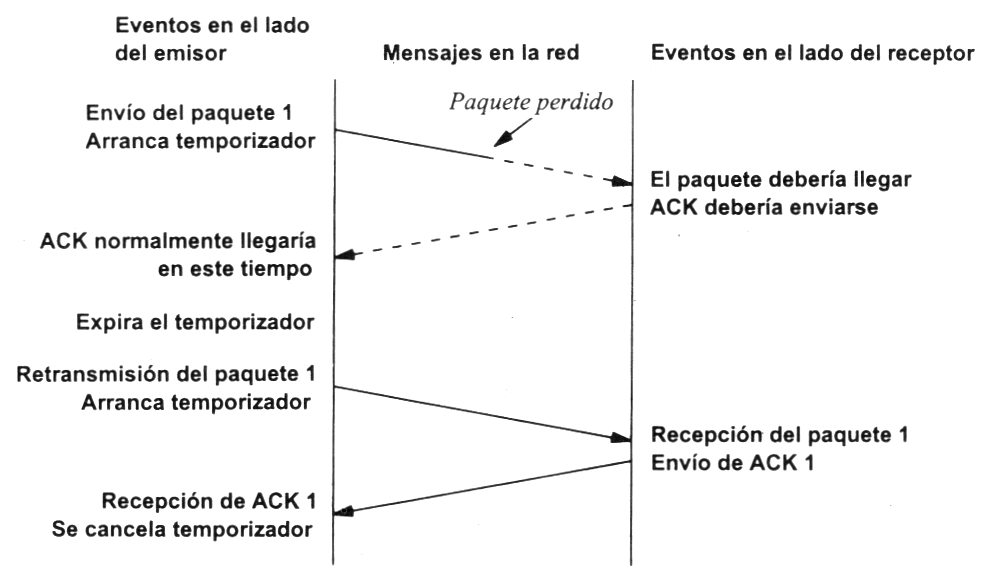
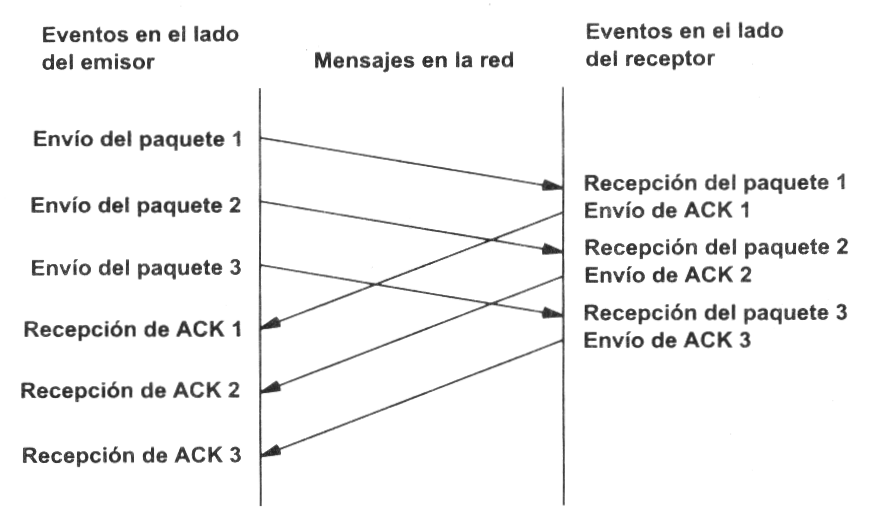
Este esquema es perfectamente válido aunque muy ineficiente debido a que sólo se utiliza un sentido de la comunicación a la vez y el canal está desaprovechado la mayor parte del tiempo. Para solucionar este problema se utiliza un protocolo de ventana deslizante, que se resume en el siguiente esquema. Los mensajes y las confirmaciones van numerados y el emisor puede enviar más de un mensaje antes de haber recibido todas las confirmaciones anteriores.
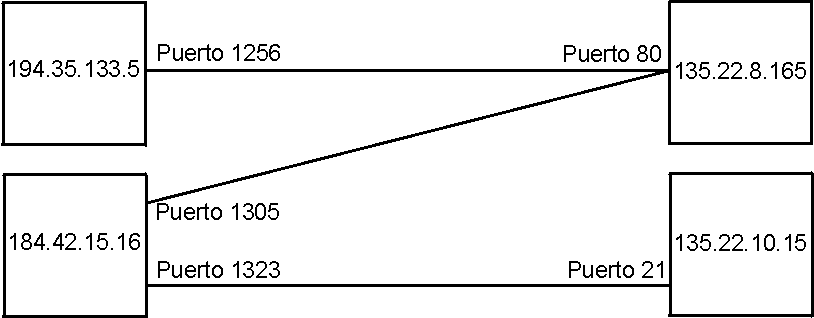
Una conexión son dos pares dirección IP:puerto. No puede haber dos conexiones iguales en un mismo instante en toda la Red. Aunque bien es posible que un mismo ordenador tenga dos conexiones distintas y simultáneas utilizando un mismo puerto. El protocolo TCP utiliza el concepto de conexión para identificar las transmisiones. En el siguiente ejemplo se han creado tres conexiones. Las dos primeras son al mismo servidor Web (puerto 80) y la tercera a un servidor de FTP (puerto 21).
| Host 1 | Host 2 |
| 194.35.133.5:1256 | 135.22.8.165:80 |
| 184.42.15.16:1305 | 135.22.8.165:80 |
| 184.42.15.16:1323 | 135.22.10.15:21 |
Para que se pueda crear una conexión, el extremo del servidor debe hacer una apertura pasiva del puerto (escuchar su puerto y quedar a la espera de conexiones) y el cliente, una apertura activa en el puerto del servidor (conectarse con el puerto de un determinado servidor).
Nota: El comando NetStat muestra las conexiones abiertas en un ordenador, así como estadísticas de los distintos protocolos de Internet.
Ya hemos comentado que el flujo de bytes que produce una determinada aplicación se divide en uno o más segmentos TCP para su transmisión. Cada uno de estos segmentos viaja en el campo de datos de un datagrama IP. Para facilitar el control de flujo de la información los bytes de la aplicación se numeran. De esta manera, cada segmento indica en su cabecera el primer byte que transporta. Las confirmaciones o acuses de recibo (ACK) representan el siguiente byte que se espera recibir (y no el número de segmento recibido, ya que éste no existe).
| 0 | 10 | 20 | 30 | ||||||||||||||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 | 3 | 3 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 |
| Puerto TCP origen | Puerto TCP destino | ||||||||||||||||||||||||||||||
| Número de secuencia | |||||||||||||||||||||||||||||||
| Número de acuse de recibo | |||||||||||||||||||||||||||||||
| HLEN | Reservado | Bits código | Ventana | ||||||||||||||||||||||||||||
| Suma de verificación | Puntero de urgencia | ||||||||||||||||||||||||||||||
| Opciones (si las hay) | Relleno | ||||||||||||||||||||||||||||||
| Datos | |||||||||||||||||||||||||||||||
| ... | |||||||||||||||||||||||||||||||
Puerto fuente (16 bits). Puerto de la máquina origen. Al igual que el puerto destino es necesario para identificar la conexión actual.
Puerto destino (16 bits). Puerto de la máquina destino.
Número de secuencia (32 bits). Indica el número de secuencia del primer byte que trasporta el segmento.
Número de acuse de recibo (32 bits). Indica el número de secuencia del siguiente byte que se espera recibir. Con este campo se indica al otro extremo de la conexión que los bytes anteriores se han recibido correctamente.
HLEN (4 bits). Longitud de la cabecera medida en múltiplos de 32 bits (4 bytes). El valor mínimo de este campo es 5, que corresponde a un segmento sin datos (20 bytes).
Reservado (6 bits). Bits reservados para un posible uso futuro.
Bits de código o indicadores (6 bits). Los bits de código determinan el propósito y contenido del segmento. A continuación se explica el significado de cada uno de estos bits (mostrados de izquierda a derecha) si está a 1.
URG. El campo Puntero de urgencia contiene información válida.
ACK. El campo Número de acuse de recibo contiene información válida, es decir, el segmento actual lleva un ACK. Observemos que un mismo segmento puede transportar los datos de un sentido y las confirmaciones del otro sentido de la comunicación.
PSH. La aplicación ha solicitado una operación push (enviar los datos existentes en la memoria temporal sin esperar a completar el segmento).
RST. Interrupción de la conexión actual.
SYN. Sincronización de los números de secuencia. Se utiliza al crear una conexión para indicar al otro extremo cual va a ser el primer número de secuencia con el que va a comenzar a transmitir (veremos que no tiene porqué ser el cero).
FIN. Indica al otro extremo que la aplicación ya no tiene más datos para enviar. Se utiliza para solicitar el cierre de la conexión actual.
Ventana (16 bits). Número de bytes que el emisor del segmento está dispuesto a aceptar por parte del destino.
Suma de verificación (24 bits). Suma de comprobación de errores del segmento actual. Para su cálculo se utiliza una pseudo-cabecera que también incluye las direcciones IP origen y destino.
Puntero de urgencia (8 bits). Se utiliza cuando se están enviando datos urgentes que tienen preferencia sobre todos los demás e indica el siguiente byte del campo Datos que sigue a los datos urgentes. Esto le permite al destino identificar donde terminan los datos urgentes. Nótese que un mismo segmento puede contener tanto datos urgentes (al principio) como normales (después de los urgentes).
Opciones (variable). Si está presente únicamente se define una opción: el tamaño máximo de segmento que será aceptado.
Relleno. Se utiliza para que la longitud de la cabecera sea múltiplo de 32 bits.
Datos. Información que envía la aplicación.
Establecimiento de una conexión
Antes de transmitir cualquier información utilizando el protocolo TCP es necesario abrir una conexión. Un extremo hace una apertura pasiva y el otro, una apertura activa. El mecanismo utilizado para establecer una conexión consta de tres vías.
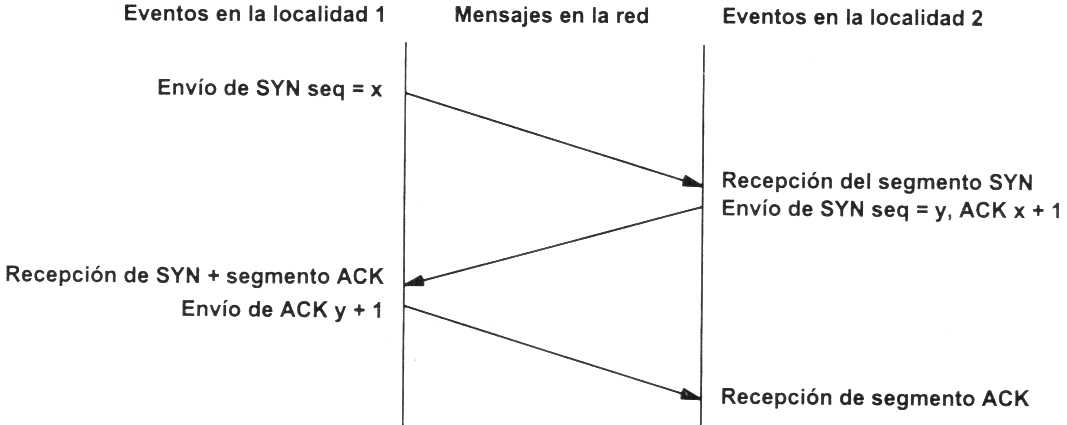
La máquina que quiere iniciar la conexión hace una apertura activa enviando al otro extremo un mensaje que tenga el bit SYN activado. Le informa además del primer número de secuencia que utilizará para enviar sus mensajes.
La máquina receptora (un servidor generalmente) recibe el segmento con el bit SYN activado y devuelve la correspondiente confirmación. Si desea abrir la conexión, activa el bit SYN del segmento e informa de su primer número de secuencia. Deja abierta la conexión por su extremo.
La primera máquina recibe el segmento y envía su confirmación. A partir de este momento puede enviar datos al otro extremo. Abre la conexión por su extremo.
La máquina receptora recibe la confirmación y entiende que el otro extremo ha abierto ya su conexión. A partir de este momento puede enviar ella también datos. La conexión ha quedado abierta en los dos sentidos.
Observamos que son necesarios 3 segmentos para que ambas máquinas abran sus conexiones y sepan que la otra también está preparada.
Números de secuencia.— Se utilizan números de secuencia distintos para cada sentido de la comunicación. Como hemos visto el primer número para cada sentido se acuerda al establecer la comunicación. Cada extremo se inventa un número aleatorio y envía éste como inicio de secuencia. Observamos que los números de secuencia no comienzan entonces en el cero. ¿Por qué se procede así? Uno de los motivos es para evitar conflictos: supongamos que la conexión en un ordenador se interrumpe nada más empezar y se crea una nueva. Si ambas han empezado en el cero es posible que el receptor entienda que la segunda conexión es una continuación de la primera (si utilizan los mismos puertos).
Cuando una aplicación ya no tiene más datos que transferir, el procedimiento normal es cerrar la conexión utilizando una variación del mecanismo de 3 vías explicado anteriormente.
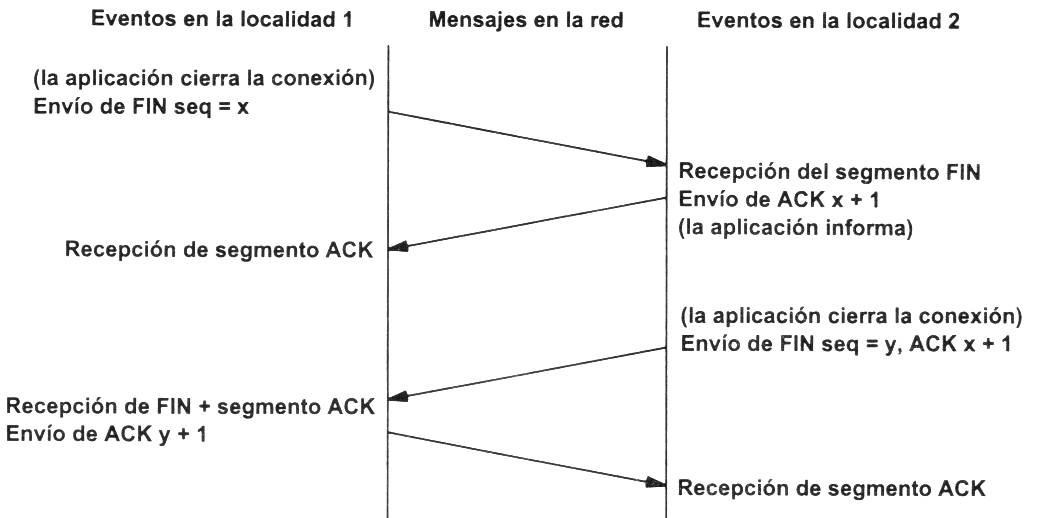
El mecanismo de cierre es algo más complicado que el de establecimiento de conexión debido a que las conexiones son full-duplex y es necesario cerrar cada uno de los dos sentidos de forma independiente.
La máquina que ya no tiene más datos que transferir, envía un segmento con el bit FIN activado y cierra el sentido de envío. Sin embargo, el sentido de recepción de la conexión sigue todavía abierto.
La máquina receptora recibe el segmento con el bit FIN activado y devuelve la correspondiente confirmación. Pero no cierra inmediatamente el otro sentido de la conexión sino que informa a la aplicación de la petición de cierre. Aquí se produce un lapso de tiempo hasta que la aplicación decide cerrar el otro sentido de la conexión.
La primera máquina recibe el segmento ACK.
Cuando la máquina receptora toma la decisión de cerrar el otro sentido de la comunicación, envía un segmento con el bit FIN activado y cierra la conexión.
La primera máquina recibe el segmento FIN y envía el correspondiente ACK. Observemos que aunque haya cerrado su sentido de la conexión sigue devolviendo las confirmaciones.
La máquina receptora recibe el segmento ACK.
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
4. Nombres de dominio
Generalmente nosotros no trabajamos con direcciones IP sino con nombres de dominio del estilo de www.saulo.net o msnews.microsoft.com. Para que esto pueda ser posible es necesario un proceso previo de conversión de nombres de dominio a direcciones IP, ya que el protocolo IP requiere direcciones IP al enviar sus datagramas. Este proceso se conoce como resolución de nombres.
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
4.1 Métodos estándar de resolución de nombres
A continuación se comentan brevemente los distintos métodos de resolución de nombres que utiliza Microsoft Windows para traducir un nombre de dominio a dirección IP. Estos métodos son aplicables a las utilidades TCP/IP que proporciona Windows (Ping, Tracert...) y son distintos a los utilizados desde Entorno de Red.
| Método de resolución | Descripción |
| 1. Local host name | Nombre de host configurado para la máquina (Entorno de Red, TCP/IP, configuración DNS) |
| 2. Fichero HOSTS | Fichero de texto situado en el directorio de Windows que contiene una traducción de nombres de dominio en direcciones IP. |
| 3. Servidor DNS | Servidor que mantiene una base de datos de direcciones IP y nombres de dominio |
| 4. Servidor de nombres NetBIOS | Servidor que mantiene una base de datos de direcciones IP y nombres NetBIOS. Los nombres NetBIOS son los que vemos desde Entorno de Red y no tienen porqué coincidir con los nombres de dominio |
| 5. Local Broadcast | Broadcasting a la subred local para la resolución del nombre NetBIOS |
| 6. Fichero LMHOSTS | Fichero de texto situado en el directorio de Windows que contiene una traducción de nombres NetBIOS en direcciones IP |
Cada vez que escribimos un nombre de dominio en una utilidad TCP/IP, por ejemplo:
C:\>ping www.ibm.com
se van utilizando cada uno de los métodos descritos desde el primero al último hasta que se consiga resolver el nombre. Si después de los 6 métodos no se ha encontrado ninguna coincidencia, se producirá un error.
El fichero HOSTS proporciona un ejemplo muy sencillo de resolución de nombres:
127.0.0.1 localhost
192.168.0.69 servidor
129.168.0.1 router
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
4.2 Necesidad del DNS
En los orígenes de Internet, cuando sólo había unos cientos de ordenadores conectados, la tabla con los nombres de dominio y direcciones IP se encontraba almacenada en un único ordenador con el nombre de HOSTS.TXT. El resto de ordenadores debían consultarle a éste cada vez que tenían que resolver un nombre. Este fichero contenía una estructura plana de nombres, tal como hemos visto en el ejemplo anterior y funcionaba bien ya que la lista sólo se actualizaba una o dos veces por semana.
Sin embargo, a medida que se fueron conectando más ordenadores a la red comenzaron los problemas: el fichero HOSTS.TXT comenzó a ser demasiado extenso, el mantenimiento se hizo difícil ya que requería más de una actualización diaria y el tráfico de la red hacia este ordenador llegó a saturarla.
Es por ello que fue necesario diseñar un nuevo sistema de resolución de nombres que distribuyese el trabajo entre distintos servidores. Se ideó un sistema jerárquico de resolución conocido como DNS (Domain Name System, sistema de resolución de nombres).
[Índice TCP/IP] ·
[Arriba] · [Publicaciones] · [Saulo.Net]
4.3 Componentes del DNS
Para su funcionamiento, el DNS utiliza tres componentes principales:
Clientes DNS (resolvers). Los clientes DNS envían las peticiones de resolución de nombres a un servidor DNS. Las peticiones de nombres son preguntas de la forma: ¿Qué dirección IP le corresponde al nombre nombre.dominio?
Servidores DNS (name servers). Los servidores DNS contestan a las peticiones de los clientes consultando su base de datos. Si no disponen de la dirección solicitada pueden reenviar la petición a otro servidor.
Espacio de nombres de dominio (domain name space). Se trata de una base de datos distribuida entre distintos servidores.
El espacio de nombres de dominio es una estructura jerárquica con forma de árbol que clasifica los distintos dominios en niveles. A continuación se muestra una pequeña parte del espacio de nombres de dominio de Internet:
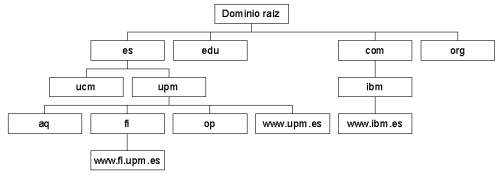
El punto más alto de la jerarquía es el dominio raíz. Los dominios de primer nivel (es, edu, com...) parten del dominio raíz y los dominios de segundo nivel (upm, ucm, microsoft...), de un dominio de primer nivel; y así sucesivamente. Cada uno de los dominios puede contener tanto hosts como más subdominios.
Un nombre de dominio es una secuencia de nombres separados por el carácter delimitador punto. Por ejemplo, www.fi.upm.es. Esta máquina pertenece al dominio fi (Facultad de Informática) que a su vez pertenece al dominio upm (Universidad Politécnica de Madrid) y éste a su vez, al dominio es (España).
Generalmente cada uno de los dominios es gestionado por un servidor distinto; es decir, tendremos un servidor para el dominio aq.upm.es (Arquitectura), otro para op.upm.es (Obras Públicas) y así sucesivamente.
Los dominios de primer nivel (Top-Level Domains) han sido clasificados tanto en función de su estructura organizativa como geográficamente. Ejemplos:
En función de su estructura organizativa:
| Nombre de dominio | Significado |
| com | organizaciones comerciales |
| net | redes |
| org | otras organizaciones |
| edu | instituciones educativas y universidades |
| gov | organizaciones gubernamentales |
| mil | organizaciones militares |
Geográficamente:
| Nombre de dominio | Significado |
| es | España |
| tw | Taiwán |
| fr | Francia |
| tv | Tuvalu |
Una zona de autoridad es la porción del espacio de nombres de dominio de la que es responsable un determinado servidor DNS. La zona de autoridad de estos servidores abarca al menos un dominio y también pueden incluir subdominios; aunque generalmente los servidores de un dominio delegan sus subdominios en otros servidores.
Dependiendo de la configuración del servidor, éste puede desempeñar distintos papeles:
Servidores primarios (primary name servers). Estos servidores almacenan la información de su zona en una base de datos local. Son los responsables de mantener la información actualizada y cualquier cambio debe ser notificado a este servidor.
Servidores secundarios (secundary name servers). Son aquellos que obtienen los datos de su zona desde otro servidor que tenga autoridad para esa zona. El proceso de copia de la información se denomina transferencia de zona.
Servidores maestros (master name servers). Los servidores maestros son los que transfieren las zonas a los servidores secundarios. Cuando un servidor secundario arranca busca un servidor maestro y realiza la transferencia de zona. Un servidor maestro para una zona puede ser a la vez un servidor primario o secundario de esa zona. Estos servidores extraen la información desde el servidor primario de la zona. Así se evita que los servidores secundarios sobrecargen al servidor primario con transferencias de zonas.
Servidores locales (caching-only servers). Los servidores locales no tienen autoridad sobre ningún dominio: se limitan a contactar con otros servidores para resolver las peticiones de los clientes DNS. Estos servidores mantienen una memoria caché con las últimas preguntas contestadas. Cada vez que un cliente DNS le formula una pregunta, primero consulta en su memoria caché. Si encuentra la dirección IP solicitada, se la devuelve al cliente; si no, consulta a otros servidores, apunta la respuesta en su memoria caché y le comunica la respuesta al cliente.
Los servidores secundarios son importantes por varios motivos. En primer lugar, por seguridad debido a que la información se mantiene de forma redundante en varios servidores a la vez. Si un servidor tiene problemas, la información se podrá recuperar desde otro. Y en segundo lugar, por velocidad porque evita la sobrecarga del servidor principal distribuyendo el trabajo entre distintos servidores situados estratégicamente (por zonas geográficas, por ejemplo).
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
4.4 Resolución de nombres de dominio
La resolución de un nombre de dominio es la traducción del nombre a su correspondiente dirección IP. Para este proceso de traducción los resolvers pueden formular dos tipos de preguntas (recursivas e iterativas).
Preguntas recursivas. Si un cliente formula una pregunta recursiva a un servidor DNS, éste debe intentar por todos los medios resolverla aunque para ello tenga que preguntar a otros servidores.
Preguntas iterativas. Si, en cambio, el cliente formula una pregunta iterativa a un servidor DNS, este servidor devolverá o bien la dirección IP si la conoce o si no, la dirección de otro servidor que sea capaz de resolver el nombre.
Veamos un ejemplo: Estamos trabajando con Internet Explorer y escribimos en la barra de dirección: www.ibm.com. En primer lugar, el navegador tiene que resolver el nombre de dominio a una dirección IP. Después podrá comunicarse con la correspondiente dirección IP, abrir una conexión TCP con el servidor y mostrar en pantalla la página principal de IBM. La siguiente gráfica muestra el esquema de resolución:

Nuestro ordenador (cliente DNS) formula una pregunta recursiva a nuestro servidor DNS local (generalmente el proveedor de Internet).
El servidor local es el responsable de resolver la pregunta, aunque para ello tenga que reenviar la pregunta a otros servidores. Suponemos que no conoce la dirección IP asociada a www.ibm.com; entonces formulará una pregunta iterativa al servidor del dominio raíz.
El servidor del dominio raíz no conoce la dirección IP solicitada, pero devuelve la dirección del servidor del dominio com.
El servidor local reenvía la pregunta iterativa al servidor del dominio com.
El servidor del dominio com tampoco conoce la dirección IP preguntada, aunque sí conoce la dirección del servidor del dominio ibm.com, por lo que devuelve esta dirección.
El servidor local vuelve a reenvíar la pregunta iterativa al servidor del dominio ibm.com.
El servidor del dominio ibm.com conoce la dirección IP de www.ibm.com y devuelve esta dirección al servidor local.
El servidor local por fin ha encontrado la respuesta y se la reenvía a nuestro ordenador.
Los clientes DNS también pueden formular preguntas inversas, esto es, conocer el nombre de dominio dada una dirección IP. Para evitar una búsqueda exhaustiva por todo el espacio de nombres de dominio, se ha creado un dominio especial llamado in-addr.arpa. Cuando un cliente DNS desea conocer el nombre de dominio asociado a la dirección IP a.b.c.d, formula una pregunta inversa a d.c.b.a.in-addr.arpa. La inversión de los bytes es necesaria debido a que los nombres de dominio son más genéricos por la derecha, al contrario que ocurre con las direcciones.
[Índice TCP/IP] · [Arriba] · [Publicaciones] · [Saulo.Net]
Documentación recomendada
Comer E., Douglas: Redes globales de información con Internet y TCP/IP, tercera edición. Prentice Hall, 1996. [Protocolos TCP/IP]
Stallings, William: Comunicaciones y redes de computadores, quinta edición. Prentice Hall, 1997. [Principios de redes y comunicaciones]
Tanenbaum, Andrew S.: Redes de computadoras, tercera edición. Pearson, 1997. [Estudio de las redes tomando como ejemplos TCP/IP y ATM]
Yraolagoitia, Jaime de: Windows 98. Paraninfo, 1998. [Redes en Windows 98]
Tella Llop, Jose Manuel: Fundamentos del TCP/IP. Publicado originalmente en septiembre de 1999 en los grupos de noticias microsoft.public.es.windows98. [TCP/IP orientado a Windows]
Request For Comments: http://www.cis.ohio-state.edu/hypertext/information/rfc.html [Especificaciones y estándares de Internet]
Categoría Protocolos de dmoz.org: http://dmoz.org/World/Español/Computadoras/Internet/Protocolos/ [Selección de páginas web en castellano que tratan sobre los protocolos de Internet]
[Índice TCP/IP] · [Subir] · [Anterior] · [Publicaciones] · [Saulo.Net]