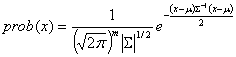
NOTE: There is a typo in the above equation
as noticed by Cory and it appears as if he is right. The last component needs
to be (x-
�
)T .
Using the sample mean x_bar and
covariance matrix S as estimates of the
mean �
and covariance matrix S
,
respectively, show that the log prob(x) is
equal to the Mahalanobis distance between a data point x and the sample mean
x_bar plus a constant that does not depend on x
.