- El objetivo de esta parte es obtener el tiempo que tarda en escribir y leer vectores de distinto tamańo en memoria
- La métrica es el tiempo en segundos que obtendré como diferencia de fin-inicio con la función clock() de C.
- En este caso los elementos que van a influir sobre la medición son:
- Número de procesos que se arrancan en cada sistema operativo
- Capacidad de memoria RAM
- Ancho de banda del bus de memoria
- Ocupación de la memoria en el momento de la prueba
- Todas las pruebas se van a hacer con el sistema en baja carga, en este caso nada más arrancarlo que es cuando menos cosas se pueden estar ejecutando.
- Se realizará una prueba para cada sistema o más de una según sistemas operativos que tengan
- Se comentará el resultado obtenido al final
LECTURA Y ESCRITURA EN DISCO DE FICHEROS
En este caso utilizaremos un vector dinámico creado en la prueba anterior para escribir su contenido en u fichero en disco. Se escribirá por tanto un único fichero que al final tendrá (5+10+15+20)=50MB. En esta prueba vamos a medir el tiempo que tarda en escribirse y leerse cada uno de los vectores del contenedor. Al principio mediremos el tiempo de escribirlos para generar el fichero de 50MB y luego el tiempo de leerlos.- El objetivo de esta parte es obtener el tiempo que tarda en escribir y leer vectores de distinto tamańo en disco
- La métrica es el tiempo en segundos que obtendré como diferencia de fin-inicio con la función clock() de C.
- En este caso los elementos que van a influir sobre la medición son:
- Número de procesos que se arrancan en cada sistema operativo
- Ocupación del disco
- Características técnicas del disco como la latencia (menor-es-mejor) si es SATA o no, capacidad del disco,...
- Todas las pruebas se van a hacer con el sistema en baja carga, en este caso nada más arrancarlo que es cuando menos cosas se pueden estar ejecutando.
- Se realizará una prueba para cada sistema o más de una según sistemas operativos que tengan
- Se comentará el resultado obtenido al final
IMPRESIÓN DE CARACTERES POR PANTALLA
En este caso vamos a imprimir 500000 veces el texto "HOLA MUNDO" por pantalla y así veremos qué tarjeta gráfica es más rápida ya que cuando mejor sea esta el tiempo en imprimir será menor.- El objetivo es ver cuánto se tarda en imprimir este texto
- La métrica es el tiempo en segundos que utilizando la librería time de C pero en vez de clock() usaré time(NULL) para controlar el tiempo dado que con la otra no funciona demasiado bien para este experimento.
- En este caso los elementos que van a influir sobre la medición son:
- Número de procesos que se arrancan en cada sistema operativo
- Características técnicas de la tarjeta gráfica como memoria dedicada, procesador, si es integrada o no,...
- Todas las pruebas se van a hacer con el sistema en baja carga, en este caso nada más arrancarlo que es cuando menos cosas se pueden estar ejecutando.
- Se realizará una prueba para cada sistema o más de una según sistemas operativos que tengan
- Se comentará el resultado obtenido al final
Nota: Para todos los experimentos cuanto menor sea el tiempo obtenido mejor será la máquina evaluada
Al final de esta práctica se va a presentar una tabla que recogerá los datos y una gráfica donde se presentarán los resultados obtenidos y la reflexión sobre lo obtenido.
Nota: Esta práctica puede plantearse de la forma que yo la presento o dado un tiempo límite ver el número de operaciones que pueden llegar a hacerse.
EQUIPOS DE PRUEBA Y CÓDIGO
En el apartado anterior he explicado cómo voy a tomar el tiempo y en qué va a consistir cada prueba. Partiremos del siguiente código C++ que reune todas las pruebas a realizar y lo ejecutaremos en cada una de las siguientes máquinas:Sistema 1,2
- Procesador: INTEL CORE2 DUO T2400 1.83GHz
- Caché L1:32KB (x2) L2: 2MB
- Memoria RAM: DDR2 2GB 667MHz
- Tarjeta gráfica: INTEL 945GM EXPRESS 64MB
- Disco duro: SAMSUNG HM100JI 100GB 4500rpm SATA
- Sistemas operativos: UBUNTU 8.10 EXT3, Windows XP Professional SP3 NTFS
Sistema 3
- Procesador: INTEL CORE2 DUO T8100 2.10GHz
- Caché L1: 32KB (x2) L2:3MB
- Memoria RAM: DDR2 3GB 800MHz
- Tarjeta gráfica: INTEL GMA 4500M HD 128MB
- Disco duro: TOSHIBA SATA 250GB 5400rpm
- Sistemas operativos: SUSE 11.0 EXT3
Sistema 4
- Procesador: INTEL CORE2 DUO T8100 2.10GHz
- Caché L1:64KB (x2) L2:3MB
- Memoria RAM: DDR2 3GB 800MHz
- Tarjeta gráfica: NVIDIA GeForce Go 9300 256MB
- Disco duro: SATA 250GB 5400rpm
- Sistemas operativos: Debian Squeeze EXT3
Sistema 5
- Procesador:MacBook Pro Unibody 2008 Core 2 Duo Montevina 2.4 GHz
- Caché L1: 64KB (x2) L2: 3MB
- Memoria RAM: DDR3 2GB 1067MHz
- Tarjeta gráfica: NVIDIA GeForce 9400 M 256MB (integrada) Tiene otra más
- Disco duro: SATA 250GB 5400rpm
- Sistemas operativos: MacOSX Leopard 10.5.7 HFS+
Sistema 6
- Procesador:Intel core2 T5500 1.66GHz
- Caché L1: 32KB (x2) L2: 2MB
- Memoria RAM: DDR SDRAM 2GB 667MHz
- Tarjeta gráfica: NVIDIA GeForce Go 7300 512MB
- Disco duro: Hitachi 120GB 5400rpm ATA
- Sistemas operativos: Windows XP Home Edition FAT32
Sistema 7 (prácticas ETSIIT)
- Procesador:Pentium III 1GHz
- Caché: 256KB
- Memoria RAM: 128MB
- Tarjeta gráfica: NVIDIA GeForce 2 MX/MX 400
- Disco duro: Seagate Barracuda 40GB ATA-100 7200rpm
- Sistemas operativos: Windows XP Professional SP1 NTFS
El código completo es el siguiente (benchmark.cpp):
Este código se encuentra en la carpeta archivos adjunta al index.html, puede verse aquí, y también está el binario generado en Windows con devcpp4.9.9.2 y en Linux con g++ -o benchmark benchmark.cpp.
Este código se ha probado tanto en Linux como en Windows y MACOSX y funciona correctamente. El único pero es que al tratarse de sistemas de archivos distintos y utilizar comandos diferentes no es posible eliminar el fichero que se genera con la prueba de disco, será el usuario el que tenga que eliminarlo después de la prueba. El motivo es que en Windows se eliminaría con la llamada al sistema del pero para Linux y Mac sería con rm y no hay una orden común.
ANÁLISIS
Una vez hemos compilado el código vamos a ejecutar el benchmark en cada uno de los equipos anteriores obteniendo los siguientes resultados:| SISTEMA 1 | SISTEMA 2 | SISTEMA 3 | SISTEMA 4 | SISTEMA 5 | SISTEMA 6 | SISTEMA 7 | |
|---|---|---|---|---|---|---|---|
| CPU | 44.75 | 46.875 | 28.52 | 30.3 | 28.77 | 125.11 | 180.20 |
| MEMORIA | 4.78 | 7 | 3.39 | 3.64 | 6.60 | 19.19 | 190.343 |
| DISCO | 13.84 | 21.922 | 9.79 | 10.32 | 14.56 | 59.58 | 97.29 |
| GRÁFICA | 23.15 | 55.22 | 20.12 | 18.58 | 8.64 | 25.34 | 31 |
La gráfica comparativa viendo estos datos es la siguiente:
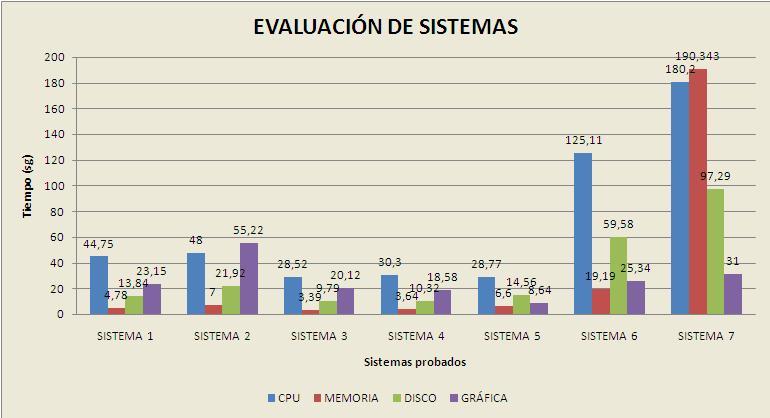
De aquí puede verse la importancia de tener un sistema de base dado que en algunas pruebas puede tener un ordenador mejores resultados que otro. Esto puede verse en el caso del MAC (Sistema 5) que en teoría tenía que ser el mejor de todos pero resulta estar en la media por el motivo comentado arriba. Otra posibilidad de ver esto es el caso de que la CPU ofrezca malos resultados pero en cambio se haya colocado una gráfica de última generación y de muy buenos resultados en los test de gráfica. Es por ello que necesitamos considerar un sistema base y comparar los resultados obtenidos con este.
A la vista de los resultados obtenidos, se aprecia cuáles son los 2 peores pero cuesta averiguar cuál es el mejor entre los sistemas 3, 4, 5 y esto se obtendrá realizando la normalización de esta tabla respecto al sistema base.
Como sistema base podría considerar cualquiera de los equipos analizados pero voy a considerar el que peor resultados ha dado a la vista de las pruebas.
Si nos detenemos en los sistemas 1 y 2 que tienen la misma arquitectura pero se ha ejecutado el benchmark bajo sistemas operativos distintos vemos que el sistema 1 ofrece mejores prestaciones que el sistema 2. De nuevo Linux le gana la partida a Windows y podemos decir que una máquina de bajas prestaciones se puede explotar mucho mejor bajo Linux que en Windows debido a las exigencias del sistema operativo y la cantidad de procesos que se están ejecutando constantemente en la máquina que lo que hace es ralentizar la máquina. Hay que decir que entre los sistemas evaluados varios están en Linux y otros en Windows, no cabe la menor duda de que el sistema en Linux obtendría peores mediciones con Windows mirando ese ejemplo.
Vamos a generar la tabla normalizada:
| SISTEMA 1 | SISTEMA 2 | SISTEMA 3 | SISTEMA 4 | SISTEMA 5 | SISTEMA 6 | SISTEMA 7 | |
|---|---|---|---|---|---|---|---|
| CPU | 4,026815642 | 4 | 6,318373072 | 5,947194719 | 6,263468891 | 1,440332507 | 1 |
| MEMORIA | 39,8207113 | 27,19185714 | 56,14837758 | 52,29203297 | 28,83984848 | 9,918863992 | 1 |
| DISCO | 7,029624277 | 4,438412409 | 9,937691522 | 9,427325581 | 6,682005495 | 1,632930514 | 1 |
| GRÁFICA | 1,339092873 | 0,5613908 | 1,540755467 | 1,66846071 | 18,90243902 | 1,223362273 | 1 |
| MEDIA | 13,05406102 | 8,990580918 | 18,48629941 | 17,33375349 | 15,17194047 | 3,553872321 | 1 |
GRÁFICA
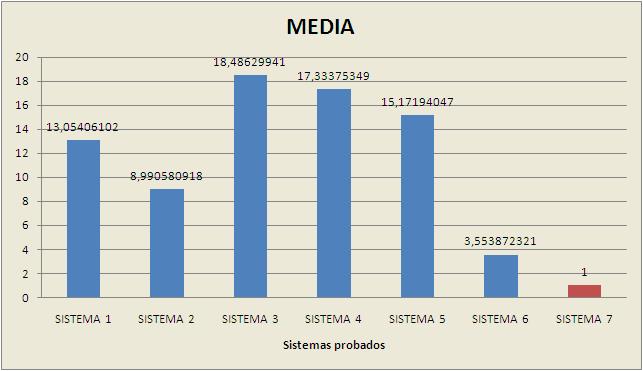
Se aprecia que el mejor es el sistema 3 ya que tiene un valor medio mayor que el resto. También puede apreciarse más claro el análisis hecho arriba entre el sistema Linux y Windows, es casi 1.5 veces mejor.
CONCLUSIONES
En esta práctica se ha aprendido a evaluar varios sistemas bajo un mismo programa de prueba de CPU, MEMORIA, DISCO y GRÁFICA respecto a un sistema base. En esta práctica se ha visto que la arquitectura hace que un sistema esté por encima de otro cuanto más moderno es, como es natural, pero tambien se ve que no podemos decir que un ordenador es mejor que otro por la descripción del sistema, depende del entorno de trabajo y para lo que esté diseńado. Esto va por los resultados obtenidos del MAC respecto al restoCon la programación de benchmark hay que tener cuidado con lo que se mide y cómo se mide ya que un sistema diseńado para cálculo intensivo va a a obtener muy buenos resultados para CPU y puede que muy malos para DISCO,es por esto que no podemos pararnos a ver una media concreta, debemos evaluar varios sistemas compararlos y obtener un parámetro que identifique a todas las medidas de forma representativa, como la media aritmética en mi caso, y así poder hacer reflexiones y obtener el resultado final.
Yo veo una gran utilidad en los benchmark para poder evaluar distintos componentes antes de ir a comprarlos (siempre que sean legales con las medidas claro). Estudiando los componentes podremos comprar un sistema mucho mejor que si nos decantamos por la marca o por ciertas características. Un ejemplo de esto es el análisis que le hice a un VAIO VGN-FW21Z que para ser el mejor en teoría ofrecía resultados todavía peores que el ordenador de prácticas, cosa que me impactó mucho y por eso no está entre los datos, la única explicación que le he encontrado es el alto consumo de recursos de Vista, otra explicación no le veo.