
CLASSIFICATION AND TABULATION
2.1 Introduction
In any statistical investigation, the collection of the numerical data is the first and the most important matter to be attended. Often a person investigating, will have to collect the data from the actual field of inquiry. For this he may issue suitable questionnaires to get necessary information or he may take actual interviews; personal interviews are more effective than questionnaires, which may not evoke an adequate response. Another method of collecting data may be available in publications of Government bodies or other public or private organizations.
Sometimes the data may be available in publications of Government bodies or other public or private organizations. Such data, however, is often so numerous that one’s mind can hardly comprehend its significance in the form that it is shown. Therefore it becomes, very necessary to tabulate and summarize the data to an easily manageable form. In doing so we may overlook its details. But this is not a serious loss because Statistics is not interested in an individual but in the properties of aggregates. For a layman, presentation of the raw data in the form of tables or diagrams is always more effective.
2.2 Tabulation
It is the process of condensation of the data for convenience, in statistical processing, presentation and interpretation of the information.
A good table is one which has the following requirements :
1. It should present the data clearly, highlighting important details.
2.3 Classification
"Classified and arranged facts speak of themselves, and narrated they are as dead as mutton" This quote is given by J.R. Hicks.
The process of dividing the data into different groups ( viz. classes) which are homogeneous within but heterogeneous between themselves, is called a classification.
It helps in understanding the salient features of the data and also the comparison with similar data. For a final analysis it is the best friend of a statistician.
2.4 Methods Of Classification
The data is classified in the following ways :
1. According to attributes or qualities this is divided into two parts :
(A) Simple classification
(B) Multiple classification.
Qualitative Classification : When facts are grouped according to the qualities (attributes) like religion, literacy, business etc., the classification is called as qualitative classification.
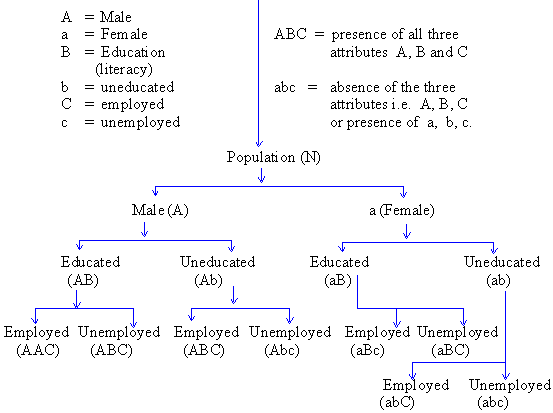
(A) Simple Classification : It is also known as classification according to Dichotomy. When data (facts) are divided into groups according to their qualities, the classification is called as 'Simple Classification'. Qualities are denoted by capital letters (A, B, C, D ......) while the absence of these qualities are denoted by lower case letters (a, b, c, d, .... etc.) For example ,
(B) Manifold or multiple classification : In this method data is classified using one or more qualities. First, the data is divided into two groups (classes) using one of the qualities. Then using the remaining qualities, the data is divided into different subgroups. For example, the population of a country is classified using three attributes: sex, literacy and business as,
Classification according to class intervals or variables : The data which is expressed in numbers (quantitative data), is classified according to class-intervals. While forming class-intervals one should bear in mind that each and every item must be covered. After finding the least value of an item and the highest value of an item, classify these items into different class-intervals. For example if in any data the age of 100 persons ranging from 2 years to 47 years, is given, then the classification of this data can be done in this way:.
Table - 1

In deciding on the grouping of the data into classes, for the purpose of reducing it to a manageable form, we observe that the number of classes should not be too large. If it were so then the object of summarization would be defeated. The number of classes should also not be too small because then we will miss a great deal of detail available and get a distorted picture. As a rule one should have between 10 and 25 classes, the actual number depending on the total frequency. Further, classes should be exhaustive; they should not be overlapping, so that no observed value falls in more than one class. Apart from exceptions, all classes should have the same length.
According to the class-intervals in classification the following terms are used :
i) Class-limits : A class is formed within the two values. These values are known as the class-limits of that class. The lower value is called the lower limit and is denoted by l1 while the higher value is called the upper limit of the class and is denoted by l2. In the example given above, the first class-interval has l1 = 0 and l2 = 10.
ii) Magnitude of the class-intervals : The difference between the upper and lower limits of a class is called the magnitude or length or width of a class and is denoted by ' i ' or ' c '. Thus i º ( l2 - l1).
iii) Mid-value or class-mark : The arithmetical average of the two class limits (i.e. the lower limit and the upper limit ) is called the mid-value or the class mark of that class-interval. For example, the mid-value of the class-interval ( 0 - 10 ) is
![]() and
so on.
and
so on.
iv) Class frequency : The units of the data belong to any one of the groups or classes. The total number of these units is known as the frequency of that class and is denoted by fi or simply f. In the above example, the frequencies of the classes in the given order are 5, 9, 32, 34 and 40 respectively.
Classification is of two types according to the class-intervals - (i) Exclusive Method (ii) Inclusive Method.
i) Exclusive Method : In this method the upper limit of a class becomes the lower limit of the next class. It is called ' Exclusive ' as we do not put any item that is equal to the upper limit of a class in the same class; we put it in the next class, i.e. the upper limits of classes are excluded from them. For example, a person of age 20 years will not be included in the class-interval ( 10 - 20 ) but taken in the next class ( 20 - 30 ), since in the class interval ( 10 - 20 ) only units ranging from 10 - 19 are included. The exclusive-types of class-intervals can also be expressed as :
0 and below 10 or 0 - 9.9
10 and below 20 or 10 - 19.9
20 and below 30 or 20 - 29.9 and so on.
ii) Inclusive Method : In this method the upper limit of any class interval is kept in the same class-interval. In this method the upper limit of a previous class is less by 1 from the lower limit of the next class interval. In short this method allows a class-interval to include both its lower and upper limits within it. For example :
Table - 2

Class boundaries : Weights are recorded to the nearest Kg The class-intervals 60 - 62 includes all measurements from 59.50000... to 62.50000 ... Kg ; the variable being a continuous one. These numbers, indicated briefly by the exact numbers 59.5 and 62.5, are called class-boundaries or true class limits. The smaller number 59.5 is the lower class boundary and the larger one 62.5 is the upper class boundary.
In any problem if the class-intervals are given as the inclusive type, then they should first be converted into the exclusive-type . For this we require a correction factor.
Correction factor = ![]() (
the upper limit of a class - the lower limit of the next class) which is
generally 0.5.
(
the upper limit of a class - the lower limit of the next class) which is
generally 0.5.
Now you subtract it from the lower limits and add it to the upper limits of the class-intervals given in the inclusive-method. The class-intervals given above can be written after correction as :

To obtain class-intervals when their mid-values are given, use the following formulae :
Lower limit (l1 ) = m - i/2 and upper limit (l2 ) = m + i/2
where m = mid-value and i = class-length.
For example, we are given some mid-values as 72, 77, 82, 87, .... Now, consider the first mid-value 72 and also the differences between successive mid-values.
We have 77 - 72 = 5, 82 - 77 = 5, 87 - 82 = 5 ....
which gives the class-length i = 5.
For the first class-interval, l1 = m - i/2 = 72 - 5/2 = 69.5
and l2 = 72 + 5/2 = 74.5.
Thus the first class-interval is 69.5 - 74.5
and other class-intervals then are 74.5 - 79.5, 79.5 - 84.5, 84.5 - 89.5 ....
Open-end Class Intervals : In any question when the lower limit of the first class-inteval or the upper limit of the last class-interval, are not given then subtract the class length of the next immediate class-interval from the upper limit. This will give us the lower limit of the first class-interval. Similarly add the same class length to the lower limit of the last class-interval. But always notice that the lower limit of the first class ( i.e. the lowest class) must not be negative or less than 0. For example :
Table - 3

2.5 Relative Frequency Distribution
The relative frequency of a class is the frequency of the class divided by the total number of frequencies of the class and is generally expresses as a percentage.
Example The weight of 100 persons were given as under :

Solution :
Table - 4

Note : The word frequency of a class means, the number of times the class is repeated in the data or the total number of items or observations of the data belongs to that class.
2.6 Cumulative Frequency
Many a times the frequencies of different classes are not given. Only their cumulative frequencies are given. The total frequency of all values less than or equal to the upper class boundary of a given class-interval is called the cumulative frequency up to and including that class interval. In this situation both the limits of a class-interval are not written; either lower or upper limit is written. These cumulative frequencies are called less than or more than cumulative frequencies. For example ,

Table - 5

Preparation Of Frequency Distribution
We shall now study how to classify the raw data in a tabular form. Consider the data collected by one of the surveyors, interviewing about 50 people. This is as follows :
Size of the shoes : 2, 5, 6, 8, 2, 5, 6, 7, 6, 8, 7, 4, 3, .. This is called the raw data. Here some values repeat themselves. For instance the size 5 is repeated 10 times in 50 people. We say that the value of 5 of the variate has the frequency of 10. Frequency means the number of times a value of the variate or an attribute, as the case may be, is repeated in the data. A table which shows each value of the characteristic with its corresponding frequency, is known as a Frequency Distribution. The procedure of preparing such a table is explained as below :
Discrete variate : Consider the raw data which gives the size of shoes of 30 persons
2, 5, 6, 4, 5,
7, 4, 4, 6, 2
3, 5, 5, 4, 5, 6, 5, 4, 3, 2
4, 4, 5, 4, 5, 5, 3, 2, 4, 4
The least value is 2 and the highest is 7. All sizes are integers between 2 and 7 ( both inclusive ). We can prepare a frequency distribution table as follows :
Table - 6

In this example the size difference from 2 to 7 is very small. If the range of a variate is very large, it is inconvenient to prepare a frequency distribution for each value of the variate. In such a case we divide the variate into convenient groups and prepare a table showing the groups and their corresponding frequencies. Such a table is called a grouped frequency distribution.
Consider the marks (out of 100 ) of 50 students as below :
40, 39, 43,
62, 30, 47, 33, 31, 17, 28
36, 29, 40, 32, 39, 24, 57, 42, 15, 30
50, 52, 47, 65, 31, 07, 37, 47, 17, 20
25, 53, 65, 85, 89, 56, 55, 41, 43, 10
44, 40, 69, 22, 40, 65, 39, 36, 71, 12
The range of the variate (marks) is very large. Also we are eager to know the performance of the students. The passing limit is 35 and above. Marks between 35 and 44 form the third class ( or grade). Marks ranging between 45 - 59 are considered as second class and 60 - 100 form the first class. Thus we have a grouped frequency distribution as:
Table - 7

CHAPTER 3 : DIAGRAMMATIC AND GRAPHIC DISPLAYS
3.1 Introduction
In the last chapter we have seen how to condense the mass of data by the method of classification and tabulation. It is not always easy for a layman to understand figures, nor is it is interesting for him. Apart from that too many figures are often confusing. One of the most convincing and appealing ways in which statistical results may be represented is through graphs and diagrams. It is for this reason that diagrams are often used by businessmen, newspapers, magazines, journals, government agencies and also for advertising and educating people.
Bar Diagrams
1) Simple 'Bar diagram':- It represents only one variable. For example sales, production, population figures etc. for various years may be shown by simple bar charts. Since these are of the same width and vary only in heights ( or lengths ), it becomes very easy for readers to study the relationship. Simple bar diagrams are very popular in practice. A bar chart can be either vertical or horizontal; vertical bars are more popular.
Illustration :- The following table gives the birth rate per thousand of different countries over a certain period of time.
|
Country |
Birth rate |
Country |
Birth rate |
|
India Germany U. K. |
33 |
China New Zealand Sweden |
40 |
Represent the above data by a suitable diagram.

Comparing the size of bars, you can easily see that China's birth rate is the highest while Germany and Sweden equal in the lowest positions. Such diagrams are also known as component bar diagrams.
2) Sub - divided Bar Diagram:- While constructing such a diagram, the various components in each bar should be kept in the same order. A common and helpful arrangement is that of presenting each bar in the order of magnitude with the largest component at the bottom and the smallest at the top. The components are shown with different shades or colors with a proper index.
Illustration:- During 1968 - 71, the number of students in University ' X ' are as follows. Represent the data by a similar diagram.
|
Year |
Arts |
Science |
Law |
Total |
|
1968 - 69 |
20,000 |
10,000 |
5,000 |
35,000 |

3) Multiple Bar Diagram:- This method can be used for data which is made up of two or more components. In this method the components are shown as separate adjoining bars. The height of each bar represents the actual value of the component. The components are shown by different shades or colors. Where changes in actual values of component figures only are required, multiple bar charts are used.
Illustration:- The table below gives data relating to the exports and imports of a certain country X ( in thousands of dollars ) during the four years ending in 1930 - 31.
Year Export Import
1927 - 28 319 250
1928 - 29 339 263
1929 - 30 345 258
1930 - 31 308 206
Represent the data by a suitable diagram

4) Deviation Bar Charts:- Deviation bars are used to represent net quantities - excess or deficit i.e. net profit, net loss, net exports or imports, swings in voting etc. Such bars have both positive and negative values. Positive values lie above the base line and negative values lie below it.
Illustration:-
|
Years |
Sales |
Net profits |
|
1985 - 86 |
10% |
50% |
Present the above data by a suitable diagram showing the sales and net profits of private industrial companies.

3.6 Pie Chart
i) Geometrically it can be seen that the area of a sector of a circle taken radially, is proportional to the angle at its center. It is therefore sufficient to draw angles at the center, proportional to the original figures. This will make the areas of the sector proportional to the basic figures.
For example, let the total be 1000 and one of the component be 200, then the angle will be
![]()
In general, angle of sector at the center corresponding to a component
![]()
ii) When a statistical phenomenon is composed of different components which are numerous (say four or more components), bar charts are not suitable to represent them because, under this situation, they become very complex and their visual impressions are questioned. A pie diagram is suitable for such situations. It is a circular diagram which is a circle (pie) divided by the radii, into sectors ( like slices of a cake or pie ). The area of a sector is proportional to the size of each component.
iii) As an example consider the yearly expenditure of a Mr. Ted, a college undergraduate.
|
Tuition fees $ 6000 Books and lab. $ 2000 Clothes / cleaning $ 2000 Room and boarding $ 12000 Transportation $ 3000 Insurance $ 1000 Sundry expenses $ 4000 |
| Total expenditure = $ 30000 |
Now as explained above, we calculate the angles corresponding to various items (components).
Tuition fees = ![]()
Book and lab = ![]()
Clothes / cleaning = ![]()
Room and boarding = ![]()
Transportation = ![]()
Insurance = ![]()
Sundry expenses = ![]()

Uses:- A pie diagram is useful when we want to show relative positions ( proportions ) of the figures which make the total. It is also useful when the components are many in number.
Note:- The sectors of the circle ( i.e. of a pie diagram) are ordered from largest to the smallest for easier interpretation of the data and they must be drawn in the counter-clockwise direction.
3.7 Graphs
A graph is a visual representation of data by a continuous curve on a squared ( graph ) paper. Like diagrams, graphs are also attractive, and eye-catching, giving a bird's eye-view of data and revealing their inner pattern.
Graphs of Frequency Distributions:-
The methods used to represent a grouped data are :-
1. Histogram
2. Frequency Polygon
3. Frequency Curve
4. Ogive or Cumulative Frequency Curve
1. Histogram :- It is defined as a pictorial representation of a grouped frequency distribution by means of adjacent rectangles, whose areas are proportional to the frequencies.
To construct a Histogram, the class intervals are plotted along the x-axis and corresponding frequencies are plotted along the y - axis. The rectangles are constructed such that the height of each rectangle is proportional to the frequency of the that class and width is equal to the length of the class. If all the classes have equal width, then all the rectangles stand on the equal width. In case of classes having unequal widths, rectangles too stand on unequal widths (bases). For open-classes, Histogram is constructed after making certain assumptions. As the rectangles are adjacent leaving no gaps, the class-intervals become of the inclusive type, adjustment is necessary for end points only.
For example, in a book sale, you want to determine which books were most popular, the high priced books, the low priced books, books most neglected etc. Let us say you sold a total 31 books at this book-fair at the following prices.
$ ....2, $ 1, $ 2, $ 2, $ 3, $ 5, $ 6, $ 17, $ 17, $ 7, $ 15, $ 7, $ 7, $ 18, $ 8, $ 10, $ 10, $ 9, $ 13, $ 11, $ 12, $ 12, $ 12, $ 14, $ 16, $ 18, $ 20, $ 24, $ 21, $ 22, $ 25.
The books are ranging from $1 to $25. Divide this range into number of groups, class intervals. Typically, there should not be fewer than 5 and more than 20 class-intervals are best for a frequency Histogram.
Our first class-interval includes the lowest price of the data and, the last-interval of course includes, the highest price. Also make sure that overlapping is avoided, so that, no one price falls into two class-intervals. For example you have class intervals as 0-5, 5-10, 10-15 and so on, then the price $10 falls in both 5-10 and 10-15. Instead if we use $1 - $5, $6=$10, the class-intervals will be mutually exclusive.
Therefore now we have distribution of books at a book-fair
|
Class-interval |
Frequency |
|
$ 1- $ 5 $6 - $10 $11 - $15 $16 - $20 $21 - $25 |
6 8 10 3 4 |
|
Total |
n = S fi = 31 |
Note that each class-interval is of equal width i.e. $5 inclusive. Now we draw the frequency Histogram as under.

Relative Frequency Histogram:- It uses the same data. The only difference is that it compares each class-interval with the total number of items i.e. instead of the frequency of each class-interval, their relative frequencies are used. Naturally the vertical axis (i.e. y-axis) uses the relative frequencies in places of frequencies.
In the above case we have
| Class-interval | Frequency | Relative frequency |
|
$ 1 - $ 5 |
6 |
6/31 |
The Histogram is same as in above case.
Construction of Histogram when class-intervals are unequal:- In a Histogram, a rectangle is proportional to the frequency of the concern class-interval. Naturally, if the class-intervals are of unequal widths, we have to adjust the heights of the rectangle accordingly. We know that the area of a rectangle = l. h. Now suppose the width ( l ) of a class is double that of a normal class interval, its height and thus the corresponding frequency must be halved. After this precaution has been taken, the construction of the Histogram of classes of unequal intervals is the same as before.
Note :- The smallest class-interval should be assumed to be " NORMAL "
Illustration:- Represent the following data by means of Histogram.
Classes : 11-14 16-19 21-24 26-29 31-39 41-59 61-79
Frequencies : 7 19 27 15 12 12 8
Solution: Note that class-intervals are unequal and also they
are of inclusive type.
We have to make them equal and of the exclusive
type.
Correct factor = ( 16 - 14 ) / 2 = 1. Using it we
have
Classes : 10-15 15-20 20-25 25-30 30-40 40-60 60-80
Frequencies : 7 19 27 15 12 12 8
Adjusted Heights : 7 19 27 15 12/2 12/4 12/4
(Frequencies) = 6 = 3 = 3

2) Frequency Polygon:- Here the frequencies are plotted against the mid-points of the class-intervals and the points thus obtained are joined by line segments.
Example
Height in cm. 150 - 154 154 - 158 158 - 162 162 - 166 166 - 170
No. of children 10 15 20 12 8
The polygon is closed at the base by extending it on both its sides ( ends ) to the midpoints of two hypothetical classes, at the extremes of the distribution, with zero frequencies.

On comparing the Histogram and a frequency polygon, you will notice that, in frequency polygons the points replace the bars ( rectangles ). Also, when several distributions are to be compared on the same graph paper, frequency polygons are better than Histograms.
3) Frequency Distribution (Curve):- Frequency distribution curves are like frequency polygons. In frequency distribution, instead of using straight line segments, a smooth curve is used to connect the points. The frequency curve for the above data is shown as:

4) Ogives or Cumulative Frequency Curves:- When frequencies are added, they are called cumulative frequencies. The curve obtained by plotting cumulating frequencies is called a cumulative frequency curve or an ogive ( pronounced ojive ).
To construct an Ogive:-
1) Add up the progressive totals of frequencies, class by
class, to get the cumulative frequencies.
2) Plot classes on the horizontal ( x-axis ) and cumulative
frequencies on the vertical ( y-axis).
3) Join the points by a smooth curve. Note that Ogives start
at (i) zero on the vertical axis, and (ii) outside class limit
of the last class. In most of the cases it looks like 'S'.
Note that cumulative frequencies are plotted against the
'limits' of the classes to which they refer.
(A) Less than Ogive:- To plot a less than ogive, the data is arranged in ascending order of magnitude and the frequencies are cumulated starting from the top. It starts from zero on the y-axis and the lower limit of the lowest class interval on the x-axis.
(B) Greater than Ogive:- To plot this ogive, the data are arranged in the ascending order of magnitude and frequencies are cumulated from the bottom. This curve ends at zero on the the y-axis and the upper limit of the highest class interval on the x-axis.
Illustrations:- On a graph paper, draw the two ogives for the data given below of the I.Q. of 160 students.
Class -intervals :60 - 70 70 - 80 80 - 90 90 - 100 100 - 110
No. of students : 2 7 12 28 42
110 - 120 120 - 130 130 - 140 140 - 150 150 - 160
36 18 10 4 1


Uses :- Certain values like median, quartiles, deciles, quartile deviation, coefficient of skewness etc. can be located using ogives. it can be used to find the percentage of items having values less than or greater than certain value. Ogives are helpful in the comparison of the two distributions.
3.8 Box and Whiskers
It is one step further to stem-and-leaf. It displays a number of statistics like, median, lower quartile (Q1), upper quartile (Q3), Inter-quartile range (IQR). It tells us about the symmetry of the distribution and also gives us the idea about the highest and the lowest values.
Example Verbal GMAT scores of 12 students 10, 22, 24, 27, 31, 33, 39, 40, 42, 43, 44, 45
Solution: The scores is arranged in the ascending order. 10, 22, 24, 27, 31, 33, 39, 40, 42, 43, 44, 45
1) Since n = 12 ( total items )
The two middle scores are ![]() =
6th and
=
6th and ![]() =
7th.
=
7th.
i.e. 33 and 39 respectively.
Therefore the average of the two is the median
i.e. Median =![]()
2) The quartile (Q1) is the median of the bottom half. i.e.
25th percentile.
Thus ![]()
3) The upper quartile (Q3) is the median of the top half. i.e.
75th percentile.
Thus![]()
Now the box-plot is constructed as follows:-
i) The line inside the box indicates the median.
ii) The left side of this box indicates the lower quartile (Q1).
iii) The right side of this box indicates the upper quartile
(Q3).
iv) A straight line is then drawn from the lowest value of this
distribution through the box to the highest value of this
distribution. This horizontal straight line is called the
"Whiskers".
Then the above GMAT score in box-plot will look like this:
0 10 20 30 40 50 60

CHAPTER 4 : MEASURES OF CENTRAL TENDENCY
4.1 Introduction
In the previous chapter, we have studied how to collect raw data, its classification and tabulation in a useful form, which contributes in solving many problems of statistical concern. Yet, this is not sufficient, for in practical purposes, there is need for further condensation, particularly when we want to compare two or more different distributions. We may reduce the entire distribution to one number which represents the distribution.
A single value which can be considered as typical or representative of a set of observations and around which the observations can be considered as Centered is called an ’Average’ (or average value) or a Center of location. Since such typical values tends to lie centrally within a set of observations when arranged according to magnitudes, averages are called measures of central tendency.
In fact the distribution have a typical value (average) about which, the observations are more or less symmetrically distributed. This is of great importance, both theoretically and practically. Dr. A.L. Bowley correctly stated, "Statistics may rightly be called the science of averages."
The word average is commonly used in day-to-day conversations. For example, we may say that Abert is an average boy of my class; we may talk of an average American, average income, etc. When it is said, "Abert is an average student," it means is that he is neither very good nor very bad, but a mediocre student. However, in statistics the term average has a different meaning.
The fundamental measures of tendencies are:
(1) Arithmetic mean
(2) Median
(3) Mode
(4) Geometric mean
(5) Harmonic mean
(6) Weighted averages
However the most common measures of central tendencies or Locations are Arithmetic mean, median and mode. We therefore, consider the Arithmetic mean
4.2 Arithmetic Mean
This is the most commonly used average which you have also studied and used in lower grades. Here are two definitions given by two great masters of statistics.
Horace Sacrist : Arithmetic mean is the amount secured by dividing the sum of values of the items in a series by their number.
W.I. King : The arithmetic average may be defined as the sum of aggregate of a series of items divided by their number.
Thus, the students should add all observations (values of all items) together and divide this sum by the number of observations (or items).
Ungrouped Data
Suppose, we have 'n' observations (or measures) x1 , x2
, x3, ......., xn then the Arithmetic mean is obviously ![]()
We shall use the symbol x (pronounced as x bar) to denote the Arithmetic
mean. Since we have to write the sum of observations very frequently, we use the
usual symbol ' S ' (pronounced as
sigma) to denote the sum. The symbol xi will be used to denote, in
general the 'i' th observation. Then the sum, x1 + x2 + x3
+ .......+ xn will be represented by ![]() or
or ![]() simply
simply
Therefore the Arithmetic mean of the set x1 + x2 + x3 + .......+ xn is given by,
![]()
This method is known as the ''Direct Method".
Example A variable takes the values as given below. Calculate the arithmetic mean of 110, 117, 129, 195, 95, 100, 100, 175, 250 and 750.
Solution: Arithmetic mean = ![]()
![]() =
110 + 117 + 129 +195 + 95 +100 +100 +175 +250 + 750 = 2021
=
110 + 117 + 129 +195 + 95 +100 +100 +175 +250 + 750 = 2021
and n = 10
Indirect Method (Assumed Mean Method)
![]()
A = Assumed Mean = ![]()
Calculations:
Let A = 175 then
Sui = -65, -58, -46, +20, -80, -75,-75, +0, + 75, +575
= 670 - 399
= 271/10 = 27.1
\ ![]()
= 175 + 27.1
= 202.1
Example M.N. Elhance’s earnings for the past week were:
Monday $ 450
Tuesday $ 375
Wednesday $ 500
Thursday $ 350
Friday $ 270
Find his average earning per day.
Solution:
![]()
n = 5
\ Arithmetic mean = ![]()
Therefore, Elhance’s average earning per day is $389.
Short-cut Method :
Sometimes the values of x are very big and in that case, to simplify the calculation the short-cut method is used. For this, first you assume a mean (called as the assumed mean). Let it be A. Now find the deviations of all the values of x from A. We now get a new variable ui = xi - A
Now find
![]() then
then ![]()
Example The expenditure of ten families in dollars are given below :
Family : A B C D E F G H I J
Expenditure : 300 700 100 750 500 80 120 250 100 370
(in dollars).
Calculate the Arithmetic mean.
Solution: Let the assumed mean be $ 500. (as. = assume)

Calculations :

Discrete Series : There is a difference in the methods for finding the
arithmetic means of the individual series and a discrete series. In the discrete
series, every term (i.e. value of x) is multiplied by its corresponding
frequency (fixi) and then their total (sum) is found ![]() .
The arithmetic mean is then obtained by dividing the total frequency
.
The arithmetic mean is then obtained by dividing the total frequency ![]() by
the above sum so obtained
by
the above sum so obtained ![]() .
.
Therefore, if the observations x1 + x2 + x3 + .......+ xn are repeated f1 + f2 + f3 + ......+ fn times, then we have :
Arithmetic mean 
The formulae for Arithmetic mean by direct method and by the short-cut methods are as follows:
Direct method Short-cut method

![]()
and u = xi - A
Therefore, ![]()
Example Find the mean of the following 50 observations.
19, 19, 20, 20, 20, 19, 20, 18, 21, 19,
20, 20, 19, 19, 20, 19, 21, 19, 19, 21,
18, 20, 18, 18, 17, 20, 20, 22, 20, 20,
20, 20, 20, 21, 20, 17, 23, 18, 17, 21,
20, 21, 20, 20, 20, 18, 21, 19, 20, 19
Solution: We may tabulate the given observations as follows.

The arithmetic mean is ![]()
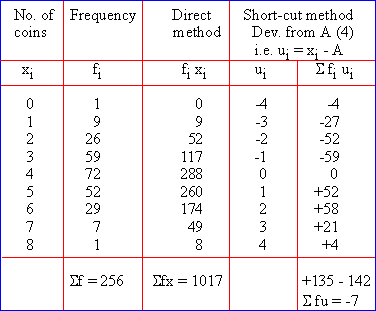
Example Eight coins were tossed together and the number of times they fell on the side of heads was observed. The activity was performed 256 times and the frequency obtained for different values of x, (the number of times it fell on heads) is shown in the following table. Calculate then mean by:
i) Direct method ii) Short-cut method
x : 0 1 2 3 4 5 6 7 8
f : 1 9 26 59 72 52 29 7 1
Solution:
Mean for Grouped data
Continuous series: The procedure of finding the arithmetic mean in this series, is the same as we have used in the discrete series. The only difference is that in this series, we are given class-intervals, whose mid-values (class-marks) are to be calculated first.
Formula, Arithmetic mean 
where x = mid-value
Example The weights (in gms) of 30 articles are given below :
14, 16, 16, 14, 22, 13, 15, 24, 23, 14, 20, 17, 21, 18, 18, 19, 20, 17, 16, 15, 11, 22, 21, 20, 17, 18, 19, 22, 23.
Form a grouped frequency table, by dividing the variate range into intervals of equal width, one class being 11-13 and then compute the arithmetic mean.
Solution:


Example Find the arithmetic mean for the following :
Marks below : 10 20 30 40 50 60 70 80
No. of students : 15 35 60 84 96 127 198 250
Solution:
First, we have to convert the cumulative frequencies into frequencies of the respective classes.
|
Marks |
Mid-values xi |
Frequencies c.f. f. |
U = X -A A = 45 |
fiui |
| 0 - 10 |
5 |
15 15 |
- 40 |
- 600 |
| 10 -20 |
15 |
35 20 |
- 30 |
- 600 |
| 20 - 30 |
25 |
60 25 |
- 20 |
- 500 |
| 30 - 40 |
35 |
84 24 |
- 10 |
- 240 |
| 40 - 50 |
45 Þ A |
96 12 |
0 |
0 |
| 50 - 60 |
55 |
127 31 |
+10 |
+310 |
| 60 - 70 |
65 |
198 71 |
+20 |
+1420 |
| 70 - 80 |
75 |
250 52 |
+30 |
+1560 |
| Total |
|
|
|
|

Step-Deviation Method
Here all class intervals are of the same width say 'c'. This method is employed in place of the Short-cut method. We measure all the class-marks (mid values) from some convenient value, say 'A', which generally should be taken as the class-mark of a class of maximum frequency or of a class which is the middle one. All the class marks happen to be multiples of c, since all class intervals are equal. We consider class frequencies as if they are centered at the corresponding class-marks.
Theorem If x1, x2 , x3, ......, xn
are n values of the class marks with frequencies f1, f2
, f3, ......fn respectively and if each xi is expressed in
terms of the new variable ui by the relation xi = A + cui then, with
the usual notation, we have ![]()
where ![]() and
and ![]()
This method is also known as the "Coding method."
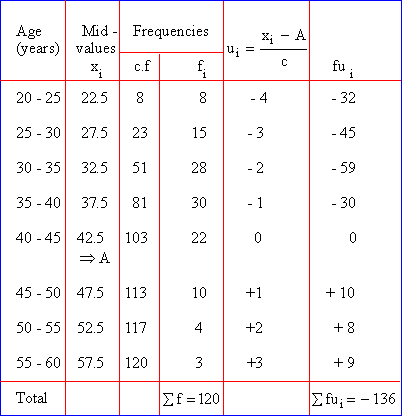
Example Calculate the arithmetic mean from the following data :
Age (years) below : 25 30 35 40 45 50 55 60
No. of employees : 8 23 51 81 103 113 117 120
Solution :

Example From the following data, of the calculation of arithmetic mean, find the missing item.
wages in : 110 112 113 117 ? 125 129 130
No. of
workers 25 17 13 15 14 8 7 2
Mean wage $ 115.86
Solution:
|
Wages in $ |
Number of workers |
fixi |
|
110 |
25 |
2750 |
|
112 |
17 |
1904 |
|
113 |
13 |
1496 |
|
117 |
15 |
1755 |
|
x |
14 |
14x |
|
125 |
8 |
1000 |
|
128 |
6 |
768 |
|
130 |
2 |
260 |
| Total |
|
|

4.3 Properties Of Arithmetic Mean
1. The sum of the deviations, of all the values of x, from their arithmetic mean, is zero.
Justification : ![]()
Since ![]() is
a constant,
is
a constant, ![]()
Justification : ![]()
or ![]()
![]()
This formula can be extended for still more groups or samples.
![]()
Justification : ![]() =
total of the observations of the first sample
=
total of the observations of the first sample
Similarly ![]() =
total of the observations of the first sample
=
total of the observations of the first sample
The combined mean of the two samples
= ![]()
![]() =
= ![]()
Example The average marks of three batches of students having 70, 50 and 30 students respectively are 50, 55 and 45. Find the average marks of all the 150 students, taken together.
Solution :
Let x be the average marks of all 150 students taken together.
Batch - I Batch - II Batch - III
![]()
![]()
![]()
A. marks : = 50 = 55 = 45
No. of students n1 = 70 n2 = 50 n3 = 30

![]()
![]()
![]()
Example The mean of a certain number of observations is 40. If two or more items with values 50 and 64 are added to this data, the mean rises to 42. Find the number of items in the original data.
Solution:
Let 'n' be the number of observations whose mean ![]() =
40.
=
40.
![]() total
of n values.
total
of n values.
Two more items of values 50 and 64 are added therefore, total of (n + 2) values :

Now new mean is 42.
\ New ![]()
\ ![]()
\ 42n + 84 = 40n + 114
\ 2n = 30
\ n = 15
Therefore, the number of items in the original data = 15.
Example The sum of deviations of a certain numbers of observations measured from 4 is 72 and the sum of deviations of observations measured from 7 is -3. Find the number of observations and their mean.
Solution:
Let 'n' be the required number of observations ![]() ,
therefore,
,
therefore, ![]()
......Note ![]() and
and ![]() therefore,
therefore,
![]() Subtracting
the two equations we get,
Subtracting
the two equations we get,
![]()
![]()
(-) (+) (+)
3n=75
\ n = 25
Putting n = 25 in ![]() ,
we get
,
we get
![]()
![]()
![]()
Now Mean is given by ![]()
Example The mean weight of 98 students is found to be 50 lbs. It is later discovered that the frequency of the class interval (30- 40) was wrongly taken as 8 instead of 10. Calculate the correct mean.
Solution:
Incorrect mean ![]()
\ Incorrect ![]()
50 = ![]()
Therefore, Incorrect ![]()
Now correct
![]()
Note that the class-mark of class interval (30 - 40) is 35 and for the calculation of the mean we consider class marks.
\The correct ![]()
Also the correct ![]()
Therefore, the correct mean

Example The sum of the deviations of 'n' observation values of a variate from a
constant 'a', is S. Show that the arithmetic mean is ![]() .
.
Solution:

Dividing by n to get the mean

Merits
1. It is rigidly defined. Its value is always definite.
2. It is easy to calculate and easy to understand. Hence it is very popular.
3. It is based on all the observations; so that it becomes a good representative.
4. It can be easily used for comparison.
5. It is capable of further algebraic treatment such as finding the sum of the values of the observations, if the mean and the total number of the observations are given; finding the combined arithmetic mean when different groups are given etc.
6. It is not affected much by sampling fluctuations.
Demerits
1.
It is affected by outliers or extreme values. For example, the average
(A.) mean of 10, 15, 25 and 500 is ![]()
Now observe first three values whose A.mean is ![]()
Due to the outlier 500 the A. mean of the four numbers is raised to 137.5. In such a case A. mean is not a good representative of the given data.
2. It is a value which may not be present in the given data.
3. Many a times it gives absurd results like 4.4 children per family.
4. It is not possible to take out the averages of ratios and percentages.
5. We cannot calculate it when open-end class intervals are present in the data.
Newspaper : Punch, Quoted by Moroney
|"The figure of 2.2 children per adult female was felt to be in some respect absurd and the Royal Commission suggested that the middle class is paid money to increase the average to a rounder and more convenient number."
4.4 Median
It is the value of the size of the central item of the arranged data (data arranged in the ascending or the descending order). Thus, it is the value of the middle item and divides the series in to equal parts.
In Connor’s words - "The median is that value of the variable which divides the group into two equal parts, one part comprising all values greater and the other all values lesser than the median." For example, the daily wages of 7 workers are 5, 7, 9, 11, 12, 14 and 15 dollars. This series contains 7 terms. The fourth term i.e. $11 is the median.
Median In Individual Series (ungrouped Data)
1. Set the individual series either in the ascending (increasing) or in the descending (decreasing) order, of the size of its items or observations.
2. If the total number of observations be 'n' then
A. If 'n' is odd,
The median = size of  observation
observation
B. If 'n' is even, the median
= 
Example The following figures represent the number of books issued at the counter of a Statistics library on 11 different days. 96, 180, 98, 75, 270, 80, 102, 100, 94, 75 and 200. Calculate the median.
Solution:
Arrange the data in the ascending order as 75, 75, 80, 94, 96, 98, 100, 102,180, 200, 270.
Now the total number of items 'n'= 11 (odd)
Therefore, the median = size of item
= size of  item
item
= size of 5th item
= 98 books per day
Example The population (in thousands) of 36 metropolitan cities are as follows :
2468, 591, 437, 20, 213, 143, 1490, 407, 284, 176, 263, 19, 181, 777, 387, 302, 213, 204, 153, 733, 391, 176 178, 122, 532, 360, 65, 260, 193, 92, 672, 258, 239, 160, 147, 151. Calculate the median.
Solution:
Arranging the terms in the ascending order as :
20, 65, 92, 131, 142, 143, 147, 151, 153, 160, 169, 176, 178, 181, 193, 204, (213, 39), 258, 263, 260, 384, 302, 360, 387, 391, 407, 437, 522, 591, 672, 733, 777, 1490, 2488.
Since total number of items n = 36 (Even).
the median
= 

Median In Discrete Series
Steps :
1. Arrange the data in ascending or descending order of magnitude.
2. Find the cumulative frequencies.
3. Apply the formula :
A.
If 'n' = ![]() (odd)
then,
(odd)
then,
Median = size of item
B.
If 'n' = ![]() (even)
then,
(even)
then,
Median = 
Example Locate the median in the following distribution.
Size : 8 10 12 14 16 18 20
Frequency : 7 7 12 28 10 9 6
Solution:

Therefore, the median = 
= 
= size of 38th item
In the order of the cumulative frequency, the 38th term is present in the 50th cumulative frequency, whose size is 14.
Therefore, the median = 14
Median In Continuous Series (grouped Data)
Steps :
1.
Determine the particular class in which the value of the median lies. Use ![]() as
the rank of the median and not
as
the rank of the median and not ![]()
2. After ascertaining the class in which median lies, the following formula is used for determining the exact value of the median.
Median = ![]()
where,![]() = lower limit of the median class, the class in which the middle item of the
distribution lies.
= lower limit of the median class, the class in which the middle item of the
distribution lies.
![]() =
upper limit of the median class
=
upper limit of the median class
c.f = cumulative frequency of the class preceding the median class
f = sample frequency of the median class
It should be noted that while interpolating the median value of frequency distribution it is assumed that the variable is continuous and that there is an orderly and even distribution of items within each class.
Example Calculate the median for the following and verify it graphically.
Age (years) : 20-25 25-30 30-35 35-40 40-45
No. of person : 70 80 180 150 20
Solution:


Median = ![]()
Here ![]() =
30,
=
30, ![]() =
35,
=
35, ![]() =
250, c.f. = 150 and f = 180
=
250, c.f. = 150 and f = 180
Therefore, Median

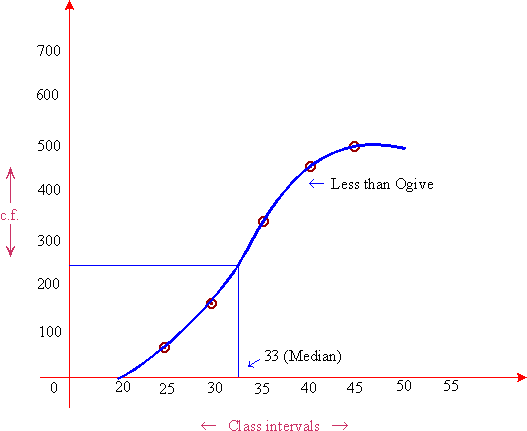
Sometimes the series is given in the descending order of magnitude. In this situation convert the series in the ascending order of magnitude and then using the regular formula, the median can be calculated or the series can be put in the descending order of the magnitude and an alternative formula be used to calculate the median.
Example Marks : 40 -50 30- 40 20-30 10-20 0 -10
No. of students : 10 12 40 30 8
Solution :


By interpolation
![]()

| Aliter |
Arranging the series in the descending order (as it is given)

Median = size of ![]() item
= size of 50th item which lies in (20 -30) class-interval.
item
= size of 50th item which lies in (20 -30) class-interval.
Alternative formula :
Median

Note that, while calculating the median of a series, it must be put in the 'exclusive class-interval' form. If the original series is in inclusive type, first convert it into the exclusive type and then find its median.
Example The following distribution represents the number of minutes spent by a group of teenagers in watching movies. What is the median ?
Minutes/Weeks:0-99 100-199 200-299 300-399 400 - 499 500 - 599 600 & more
No. of teenagers : 27 32 65 78 58 32 8
Solution:


By using interpolation

Merits Of Median
1. It is rigidly defined.
2. It is easy to calculate and understand.
3. It is not affected by extreme values like the arithmetic mean. For example, 5 persons have their incomes $2000, $2500, $2600, $3000, $5000. The median would be $2600 while the arithmetic mean would be $3020.
4. It can be found by mere inspection.
5. It is fully representative and can be computed easily.
6. It can be used for qualitative studies.
7. Even if the extreme values are unknown, median can be calculated if one knows the number of items.
8. It can be obtained graphically.
Demerits Of Median
1. It may not be representative if the distribution is irregular and abnormal.
2. It is not capable of further algebraic treatment.
3. It is not based on all observations.
4. It is affected by sample fluctuations.
5. The arrangement of the data in the order of magnitude is absolutely necessary.
4.5 Mode
It is the size of that item which possesses the maximum frequency. According to Professor Kenney and Keeping, the value of the variable which occurs most frequently in a distribution is called the mode.
It is the most common value. It is the point of maximum density.
Ungrouped Data
Individual series : The mode of this series can be obtained by mere inspection. The number which occurs most often is the mode.
Example Locate mode in the data 7, 12, 8, 5, 9, 6, 10, 9, 4, 9, 9
Solution : On inspection, it is observed that the number 9 has maximum frequency. Therefore 9 is the mode.
Note that if in any series, two or more numbers have the maximum frequency, then the mode will be difficult to calculate. Such series are called as Bi-modal, Tri-modal or Multi-modal series.
Grouped Data
Steps :
1. Determine the modal class which as the maximum frequency.
2. By interpolation the value of the mode can be calculated as -
Mode = 
where

Example Calculate the modal wages.
Daily wages in $ : 20 -25 25-30 30-35 35-40 40-45 45-50
No. of workers : 1 3 8 12 7 5
Verify it graphically.
Solution:
Here the maximum frequency is 12, corresponding to the class interval (35 - 40) which is the modal class.
Therefore ![]()
By interpolation
Mode =

Modal wages is $37.22

MERITS OF MODE
1. It is simple to calculate.
2. In individual or discrete distribution it can be located by mere inspection.
3. It is easy to understand. Everyone is used to the idea of average size of a garment, an average American etc.
4. It is not isolated like the median as it is the most common item.
5. Like the Average mean, it is not a value which cannot be found in the series.
6. It is not necessary to know all the items. What we need the point of maximum density frequency.
7. It is not affected by sampling fluctuations.
DEMERITS
1. It is ill defined.
2. It is not based on all observations.
3. It is not capable of further algebraic treatment.
4. It is not a good representative of the data.
5. Sometimes there are more than one values of mode.
CHAPTER 5 : MEASURES OF DISPERSION
5.1 Introduction
The measures of central tendencies (i.e. means) indicate the general magnitude of the data and locate only the center of a distribution of measures. They do not establish the degree of variability or the spread out or scatter of the individual items and their deviation from (or the difference with) the means.
i) According to Nciswanger, "Two distributions of statistical data may be symmetrical and have common means, medians and modes and identical frequencies in the modal class. Yet with these points in common they may differ widely in the scatter or in their values about the measures of central tendencies."
ii) Simpson and Kafka said, "An average alone does not tell the full story. It is hardly fully representative of a mass, unless we know the manner in which the individual item. Scatter around it .... a further description of a series is necessary, if we are to gauge how representative the average is."
From this discussion we now focus our attention on the scatter or variability which is known as dispersion. Let us take the following three sets.
|
Students |
Group X |
Group Y |
Group Z |
|
1 |
50 |
45 |
30 |
|
2 |
50 |
50 |
45 |
|
3 |
50 |
55 |
75 |
|
\ mean |
50 |
50 |
50 |
Thus, the three groups have same mean i.e. 50. In fact the median of group X and Y are also equal. Now if one would say that the students from the three groups are of equal capabilities, it is totally a wrong conclusion then. Close examination reveals that in group X students have equal marks as the mean, students from group Y are very close to the mean but in the third group Z, the marks are widely scattered. It is thus clear that the measures of the central tendency is alone not sufficient to describe the data.
Definition of dispersion : The arithmetic mean of the deviations of the values of the individual items from the measure of a particular central tendency used. Thus the ’dispersion’ is also known as the "average of the second degree." Prof. Griffin and Dr. Bowley said the same about the dispersion.
In measuring dispersion, it is imperative to know the amount of variation (absolute measure) and the degree of variation (relative measure). In the former case we consider the range, mean deviation, standard deviation etc. In the latter case we consider the coefficient of range, the coefficient mean deviation, the coefficient of variation etc.
5.2 Methods Of Computing Dispersion
(I) Method of limits:
(1) The range (2) Inter-quatrile range (3) Percentile range
(II) Method of Averages:
(1) Quartile deviation (2) Mean deviation
(3) Standard Deviation and (4) Other measures.
Note that, we are going to study some of these and not all.
5.3 Range
In any statistical series, the difference between the largest and the smallest values is called as the range.
Thus Range (R) = L - S 
Coefficient of Range :
The relative measure of the range. It is used in the comparative study of the
dispersion co-efficient of Range = ![]()
Example ( Individual series ) Find the range and the co-efficient of the range of the following items :
110, 117, 129, 197, 190, 100, 100, 178, 255, 790.
Solution: R = L - S = 790 - 100 = 690
Co-efficient of Range = ![]()
Example (Continuous series ) Find the range and its co-efficient from the following data.
![]()
Solution: R = L - S = 100 - 10 = 90
Co-efficient of range = ![]()
5.4 Mean Deviation
Average deviations ( mean deviation ) is the average amount of variations (scatter) of the items in a distribution from either the mean or the median or the mode, ignoring the signs of these deviations by Clark and Senkade.
Individual Series
Steps : (1) Find the mean or median or mode of the given series.
(2) Using and one of three, find the deviations ( differences ) of the items of the series from them.
i.e. xi - x, xi - Me and xi - Mo.
Me = Median and Mo = Mode.
(3) Find the absolute values of these deviations i.e. ignore there positive (+) and negative (-) signs.
i.e. | xi - x | , | xi - Me | and xi - Mo |.
(4) Find the sum of these absolute deviations.
i.e. S | xi - x | + , S | xi - Me | , and S | xi - Mo | .
(5) Find the mean deviation using the following formula.

Note that :
(i) generally M. D. obtained from the median is the best for the practical purpose.
(ii) co-efficient of M. D. = ![]()
Example Calculate Mean deviation and its co-efficient for the following salaries:
$ 1030, $ 500, $ 680, $ 1100, $ 1080, $ 1740. $ 1050, $ 1000, $ 2000, $ 2250, $ 3500 and $ 1030.


Calculations :
i) Median (Me) = Size of 
= Size of 11th item.
Therefore, Median ( Me) = 8
ii) M. D. = ![]()
Example ( Continuous series ) Calculate the mean deviation and the coefficient of mean deviation from the following data using the mean.
Difference in ages between boys and girls of a class.
|
Diff. in years: |
No.of students: |
|
0 - 5 |
449 |
|
5 - 10 |
705 |
|
10 - 15 |
507 |
|
15 - 20 |
281 |
|
20 - 25 |
109 |
|
25 - 30 |
52 |
|
30 - 35 |
16 |
|
35 - 40 |
4 |

Calculation:
1) X ![]()
2) M. D. ![]()
3) co
-
efficient of M. D. ![]()
5.5 Variance
The term variance was used to describe the square of the standard deviation R.A. Fisher in 1913. The concept of variance is of great importance in advanced work where it is possible to split the total into several parts, each attributable to one of the factors causing variations in their original series. Variance is defined as follows:
Variance = ![]()
Standard Deviation (s. d.)
It is the square root of the arithmetic mean of the square deviations of various values from their arithmetic mean. it is denoted by s.d. or s.
Thus, s.d. ( sx )
= 
= 
where n = S fi
Merits : (1) It is rigidly defined and based on all observations.
(2) It is amenable to further algebraic treatment.
(3) It is not affected by sampling fluctuations.
(4) It is less erratic.
Demerits : (1) It is difficult to understand and calculate.
(2) It gives greater weight to extreme values.
Note that variance V(x) =
and s. d. ( sx )
=  and
and 
Then V ( x ) = ![]()
5.6 Co-efficient Of Variation ( C. V. )
To compare the variations ( dispersion ) of two different series, relative measures of standard deviation must be calculated. This is known as co-efficient of variation or the co-efficient of s. d. Its formula is
C. V. = ![]()
Thus it is defined as the ratio s. d. to its mean.
Remark: It is given as a percentage and is used to compare the consistency or variability of two more series. The higher the C. V. , the higher the variability and lower the C. V., the higher is the consistency of the data.
Example Calculate the standard deviation and its co-efficient from the following data.
|
A |
10 |
|
B |
12 |
|
C |
16 |
|
D |
8 |
|
E |
25 |
|
F |
30 |
|
G |
14 |
|
H |
11 |
|
I |
13 |
|
J |
11 |
Solution :
|
No No. |
xi |
(xi - x) |
( xi - x )2 |
|
A |
10 |
-5 |
25 |
|
B |
12 |
-3 |
9 |
|
C |
16 |
+1 |
1 |
|
D |
8 |
-7 |
49 |
|
E |
25 |
+10 |
100 |
|
F |
30 |
+15 |
225 |
|
G |
14 |
-1 |
1 |
|
H |
11 |
-5 |
16 |
|
I |
13 |
-2 |
4 |
|
J |
11 |
-4 |
16 |
|
n= 10 |
S xi = 150 |
|
S |xi - x |2 = 446 |
Calculations :
i) ![]()
ii) 
iii) ![]()

Example Calculate s.d. of the marks of 100 students.
|
Marks |
No. of students (fi) |
Mid-values (xi) |
fi xi |
fi xi2 |
|
0-2 |
10 |
1 |
10 |
10 |
|
2-4 |
20 |
3 |
60 |
180 |
|
4-6 |
35 |
5 |
175 |
875 |
|
6-8 |
30 |
7 |
210 |
1470 |
|
8-10 |
5 |
9 |
45 |
405 |
|
|
n = 100 |
|
Sfi xi = 500 |
Sfi xi2 = 2940 |
Solution
1) ![]()
2) 
Example Calculate s.d. of the marks of 100 students.
|
Marks |
No. of students (fi) |
Mid-values (xi) |
fi xi |
fi xi2 |
|
0-2 |
10 |
1 |
10 |
10 |
|
2-4 |
20 |
3 |
60 |
180 |
|
4-6 |
35 |
5 |
175 |
875 |
|
6-8 |
30 |
7 |
210 |
1470 |
|
8-10 |
5 |
9 |
45 |
405 |
|
|
n = 100 |
|
Sfi xi = 500 |
Sfi xi2 = 2940 |
Solution
1)
![]()
2)

Combined Standard deviation : If two sets containing n1 and n2 items having means x1 and x2 and standard deviations s1 and s2 respectively are taken together then,
(1) Mean of the combined data is ![]()
(2) s.d. of the combined set is 
![]()


Example The score of two teams A and B in 10 matches are as:
| A : | B: |
| 40 | 21 |
| 32 | 14 |
| 0 | 29 |
| 40 | 13 |
| 30 | 5 |
| 7 | 12 |
| 13 | 10 |
| 25 | 13 |
| 14 | 30 |
| 5 | 0 |
Find the variance for both the series. Which team is more consistent ?



5.7 Percentile
The nth percentile is that value ( or size ) such that n% of values of the whole data lies below it. For example, a score of 7% from the topmost score would be 93 the percentile as it is above 93% of the other scores.

Percentile Range
it is used as one of the measure of dispersion. it is a set of data and is defined as = P90 - P10 where P90 and P10 are the 90th and 10th percentile respectively. The semi - percentile range,
i.e. ![]() can
also be used but it is not common in use
can
also be used but it is not common in use
5.8 Quartiles And Interquartile Range
If we concentrate on two extreme values ( as in the case of range ), we don’t get any idea about the scatter of the data within the range ( i.e. the two extreme values ). If we discard these two values the limited range thus available might be more informative. For this reason the concept of interquartile range is developed. It is the range which includes middle 50% of the distribution. Here 1/4 ( one quarter of the lower end and 1/4 ( one quarter ) of the upper end of the observations are excluded.

Now the lower quartile ( Q1 ) is the 25th percentile and the upper quartile ( Q3 ) is the 75th percentile. It is interesting to note that the 50th percentile is the middle quartile ( Q2 ) which is in fact what you have studied under the title ’ Median ". Thus symbolically
Inter quartile range = Q3 - Q1
If we divide ( Q3 - Q1 ) by 2 we get what is known as Semi-Iinter quartile range.
i.e. ![]() .
It is known as Quartile deviation ( Q. D or SI QR ).
.
It is known as Quartile deviation ( Q. D or SI QR ).
Therefore Q. D. ( SI QR ) = ![]()
