Speech Enhancement
ELE 498D Project Proposal
By Daniel Linnen
Problem: Noise exists all around us and when speech is recorded noise is also recorded along with it.
Goal: The goal of this project is to enhance speech through the reduction of noise by means of digital signals processing.
Abstract: The idea behind the enhancing of speech is a very basic one. If we record a voice we will also record the white noise that is in the room where the voice is being recorded. Although the person may be understood there is no guarantee that someone could not pick up the noise who is listening to the recording, and also there is a risk of amplifying the noise in the course of the use of the speech, such as in music applications where the speaker is singing. Similarly if a person speaking is talking into a microphone and wants to amplify and broadcast his or her voice through a speaker to an audience, the noise, if not eliminated, will be amplified so that the audience will hear it very well. The only action that can be taken to eliminate the problem caused by noise is to do some sort of adaptive filtering through the use of a digital signal processor (DSP) to reduce the noise and thus lower the signal to noise ratio (SNR).
Proposal: I. In what kind of applications does noise exist?
A. Music Recording
B. Concerts
C. Public Speaking
D. Radio
E. Voice over Internet Protocol (VoIP)
F. Telecommunications
G. Television
H. And any other application where sound is recorded, however the focus is on the actual human voice for this project.
II. Why is noise a problem?
A. When the recording is amplified the noise is amplified as well.
B. At some levels the noise can interfere with the signal itself.
C. The noise can be heard by some people, especially after amplification and therefore it will be an annoyance to them.
D. If you are trying to talk to someone on the phone and there is a lot of noise from something such as wind blowing on the phone or some other uncorrelated means then there will be a good chance that they will not be heard.
III. What are the key aspects of the human voice to be used in this project?
A. Voice is dependant upon frequencies.
B. The human voice ranges from »300Hz to »3400Hz while talking.
C. The human voice has five distinct frequency components.
D. The frequency of a person changes as they speak.
E. The power of a person’s voice is much greater than the power of noise under most conditions.
IV. What does each of the previous aspects of the human voice that will be considered in this project imply?
A. With
the human voice depending on frequency we can transform the values of the voice
can be transformed from a time domain to a frequency domain by means of a
Fourier transform ![]() or a Discrete Fourier
Transform (DFT)
or a Discrete Fourier
Transform (DFT) 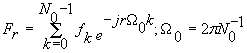 this will allow us to
completely transform our signal from time domain to frequency domain to allow
us to analyze it properly.
this will allow us to
completely transform our signal from time domain to frequency domain to allow
us to analyze it properly.
B. The frequency range implies that in most cases voice does not exist below 300Hz or above 3400Hz. This means that one can attenuate the frequencies beyond this range with a low pass filter and a high pass filter. However since working can be done in digital if one wanted to he or she could just “turn off” all frequencies outside of the range of voice, because they will be completely composed of noise. Although turning off the frequencies outside of the range of a person’s voice might be more cost effective to implement in digital it will take a processing cost and a delay, and that may be a delay and processing cost that should be sacrificed.
C. Because the human voice has five distinct frequencies one can know that after the Fast Fourier Transform (FFT) has been completed, analyzed, and attenuated or had noise eliminated that there will only be 5 frequencies present.
D. Since the frequency of a person’s voice varies with time there is a definite need for an adaptive filtering system or scheme (adaptive DSP) to eliminate the noise since the five frequencies associated with a person’s voice will not remain the same for too long.
E. Knowing that in general the power of a person’s voice is much greater than the power of noise means that one can arrange the power of the spectral components in terms of power from greatest to least. The first five greatest will be the actual signal. Then the rest can be denoted as noise and thus can be removed.
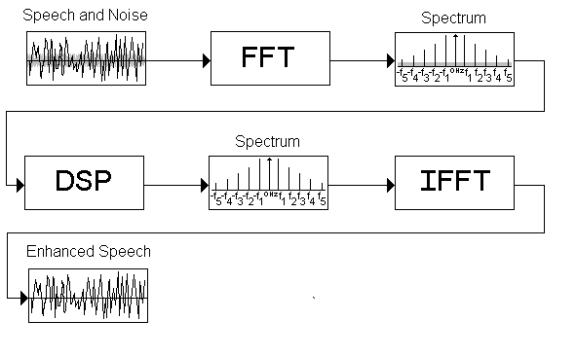
V. What could a general plan for the reducing the noise be?
A. First use a low pass filter to cut off the higher frequencies that are above 3400Hz.
B. Then use a high pass filter to cut off the frequencies that are below 300Hz.
C. Then use an FFT to transform the input signal from time domain into frequency domain.
D. Next perform DSP operations.
i. First conduct a measurement of power for each frequency bin.
ii. Second acquire the five largest power values and let those frequencies be stored as the frequencies at which the actual speech is occurring.
iii. Then remove the rest of the frequencies from the input signal.
E. Then use an IFFT to convert the output from the signal from frequency domain to time domain.
F.
This is a basic model of the system for the use of high and
low pass filters. 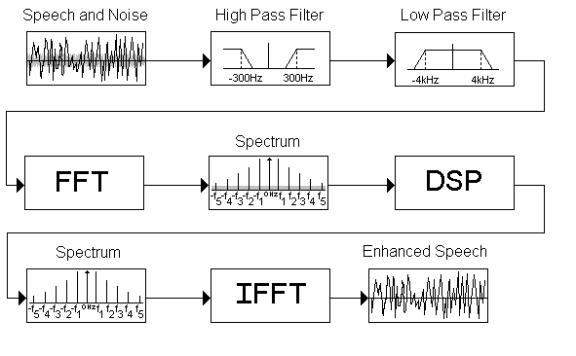
G. Below is a basic model of the implementation of the noise reduction without the filters, meaning that the DSP chip does all the dropping of frequencies.