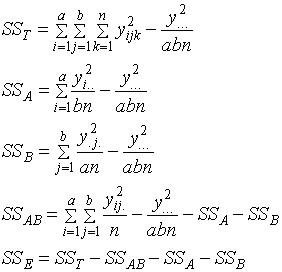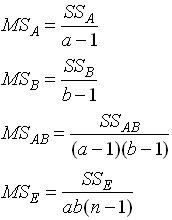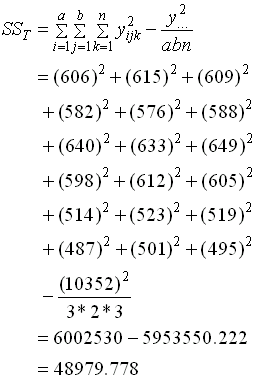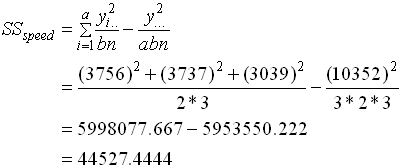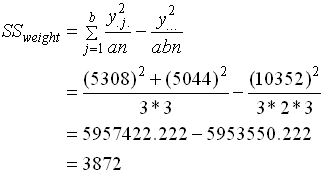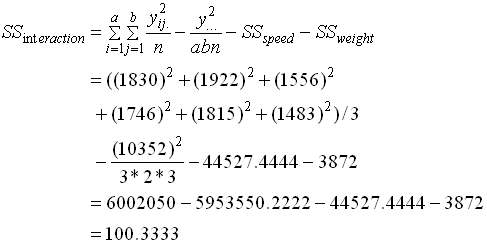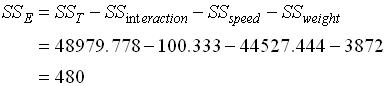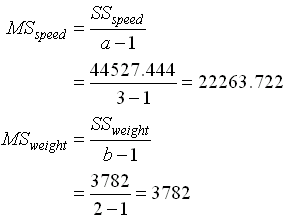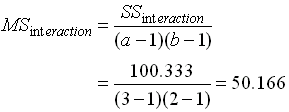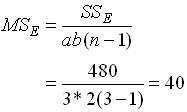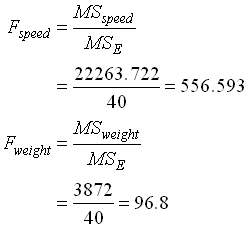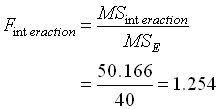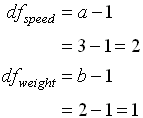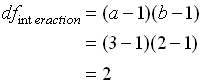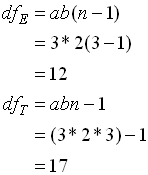|
Two-Factors ANOVA ( Two-way ANOVA) จากที่ผู้เขียนได้เริ่มต้นในเรื่อง ANOVA ไว้แล้วว่าสามารถ วิเคราะห์ได้พร้อมกันมากกว่า 1 Factor ตามตัวอย่างง่ายๆ เรื่องการทดลองเรื่องการขับรถด้วยความเร็วที่แตกต่างกัน นอกจากนั้น ANOVA ที่ยังสามารถวิเคราะห์ให้เห็นผลกระทบซึ่งกันและกัน ของปัจจัย (Facters ' Interaction) ได้ด้วยนั้น เพื่อให้เห็นภาพดังกล่าว ในหัวข้อนี้จะชี้ให้เห็นความเหมือนและความแตกต่างของ ANOVA เมื่อใช้วิเคราะห์ข้อมูลการทดลองจาก 1 Factor กับ หลาย Factor โดยยกตัวอย่าง 2 Factor เป็นตัวอย่าง โดยที่แท้จริงแล้ว ANOVA สามารถใช้วิเคราะห์กรณี 3 , 4 ,5 Factors หรือมากกว่า ก็ได้ แต่ด้วยเหตุความยุ่งยากในการวิเคราะห์ จึงอาจจะหาได้ยากที่จะวิเคราะห์ ANOVA ที่มากกว่า 2 Factors ในการทำงานทั่วๆไป ซึ่งอาจมีสาเหตุมาจากความยุ่งยากในการออกแบบการทดลอง การเก็บข้อมูลและการคำนวณหรือการวิเคราะห์ ถ้าหากมีมากกว่า 2 Factors แล้วก็หลีกเลี่ยงไม่ได้ที่ผู้วิเคราะห์จะต้องอาศัย โปรแกรมคอมพิวเตอร์ช่วยในการวิเคราะห์ ดังนั้นทุกๆคนจะคุ้นเคยกับ ANOVA ที่มีไม่เกิน 2 Factors ใน ANOVA นั้นเราจะกล่าวถึง ค่า Sum sqaure (SS) หรือ Variation นั่นเอง ถ้ามี 2 Factor ลักษณะการอธิบาย Variation คือ
เมื่อ T : Total A : Factor A B : Factor B AB : Interaction of Factor A and B E: Error a : Number of levels of factor A b : Number of levels of factor B n : Number of replication per cell ( หมายความว่า การเก็บข้อมูลมีการทำซ้ำ หรือ Repeat กี่ครั้ง )
หาค่า Mean of square ได้จาก
ทั้งนี้ Two-Factors ANOVA สามารถเขียนสรุปในรูป ตาราง ANOVA ได้ดังนี้
ตัวอย่าง ในบทที่ผ่านมา ผู้ทำการทดลองต้องการทราบว่า ถ้าเขาบรรทุกน้ำหนักด้วย อัตราการกินน้ำมันในช่วงแต่ละความเร็วจะเปลี่ยนแปลงเป็นอย่างไร เขาจึงกำหนดการทดลองขึ้นมาใหม่ โดยมีปัจจัย เรื่องน้ำหนักบรรทุกเข้ามาเกี่ยวข้อง Speed 70,90,110 Km/Hr Total Kilometers Weight 60, 200 Kg เมื่อทำการทดลองเสร็จแล้ว ได้ข้อมูลดังนี้ ( ผู้เขียนมีวัตถุประสงค์จะให้เข้าใจง่าย และคำนวณด้วยมือได้ง่าย จึงใช้ขนาดตัวอย่างเพียง 3 ตัวอย่างต่อ 1 ชุดการทดลอง ในชีวิตจริงการทดลองใดๆ คงจะใช้ตัวอย่างมากกว่านี้ )
ขั้นตอนการวิเคราะห์ 1. ตั้งสมมติฐาน หลักในการตั้งสมมติฐานของ 2 Way ANOVA จะคล้ายกับ กรณี 1 Way ANOVA เพียงแต่สมมติฐานนั้นเราจะตั้งสำหรับ Factor เดียวเท่านั้น หมายความว่า ในกรณีวิเคราะห์ 2 Factors เช่นโจทย์นี้ เราจะต้องตั้งสมมติฐานแยกกันระหว่างปัจจัย Speed , Weight รวมทั้ง Interaction ด้วย แต่สมมติฐานจะเหมือนกันทุกอย่าง ในความเป็นจริงแล้วเราเขียนสมมติฐานเพียงแค่อย่างเดียว เพียงแต่เมื่อเราได้ผลการวิเคราะห์โดยตาราง ANOVA แล้ว เราจะสรุปทีละปัจจัย รวมทั้ง Interaction ของปัจจัยเหล่านั้นด้วย โดยดูที่ค่า F-Statistic หรือ P-Value ของแต่ละตัวแปร Ho : ค่าเฉลี่ยกิโลเมตรที่ได้ ไม่แตกต่างกัน Ha : ค่าเฉลี่ยกิโลเมตรที่ได้ แตกต่างกัน อย่างน้อย 1 คู่ โดยเขียนเป็นภาษา Statistics ได้ดังนี้ Ho : m1=m2=m3=m4=m5 Ha : At least two m's are different
2. กำหนดระดับนัยสำคัญ (Significant level ) กำหนด a = 0.05 3. ทำการวิเคราะห์ ในตัวอย่างนี้ผู้เขียนจะใช้โปรแกรม MS Excel ช่วยในการคำนวณ แต่จะใช้หลักการเหมือนคำนวณด้วยมือ เพียงแต่จะประยุกต์ใช้ Work sheet ของ Excel มาช่วยเท่านั้น
หาค่า F-Critical จากตารางจะได้ ( Denominator คือ Error ) F-Critical for factor speed = 3.89 ( f0.05 , 2,12 ) F-Critical for factor weight = 4.75 ( f0.05 , 1,12 ) F-Critical for interaction = 3.89 ( f0.05 , 2,12 ) ทั้งหมดนี้สรุปเป็น ANOVA Table ได้ดังนี้
4. วิเคราะห์ผลตามตาราง ANOVA - สิ่งที่เราต้องพิจารณาอันดับแรก คือ อัตราส่วนระหว่าง Error กับ Total โดยดูผ่านค่า SS ( Error ) เทียบกับ SS ( Total ) จากตาราง ANOVA ค่า SS(Error) = 480 ค่า SS(Total) = 48979.78 ค่า SS(Error) จะมีค่าเพียงน้อยนิด เมื่อเทียบกับ SS(Total) แสดงว่าในการทดลองครั้งนี้มีการควบคุมผลกระทบจากตัวแปรภายนอกอื่นๆทำได้ดีมาก ค่า Variation ที่เห็นส่วนมากจึงเกิดจากการเปลี่ยนค่าของ Factor ในการทดลองเอง ในทางตรงกันข้าม สมมติว่า SS(Error) มีค่ามากอาจจะซัก 1/5 ขึ้นไปเมื่อเทียบกับ SS(Total) ก็จะแปลว่าการทดลองครั้งนี้มีความผิดพลาดอันเนื่องมาจากผลกระทบจากตัวแปรภายนอกอื่นๆ ที่เราควบคุมไม่ดี Model หรือผลลัพธ์ ที่เราได้จากการวิเคราะห์นั้น ย่อมมีความคลาดเคลื่อนสูง จนอาจจะยอรับไม่ได้ ผู้ทำการทดลองอาจจะต้องทำการทดลองใหม่ และต้องควบคุมผลกระทบอื่นๆให้ดีกว่าเก่า การเปรียบเทียบดังกล่าวถือเป็น Data qualify ซึ่งจะต้องผ่านก่อนจึงจะสรุปผลการทดสอบสมมุติฐานได้ หากเงื่อนไขดังที่กล่าวมาแล้วถูกละเลย และด่วนสรุปผลการทดสอบสมมติฐานเลย ก็จะนำไปสู่การได้ข้อสรุปที่มีข้อผิดพลาดในภายหลัง - พิจารณา SS ของ Factor Speed จะเห็นว่ามีค่ามากกว่า Weight มาก ความหมายก็คือ เมื่อเปลี่ยนแปลงค่าของ Speed โดยสนใจ Weight เท่าเดิม ขณะทดลอง จะเกิดผลกระทบต่อ Output (Total KM) มากกว่าการเปลี่ยนแปลงค่า Weight เมื่อ Speed เท่าเดิม
5. สรุปผลการทดสอบสมมติฐาน จากการตั้งสมมติฐานที่ผ่านมา Ho : ค่าเฉลี่ยกิโลเมตรที่ได้ ไม่แตกต่างกัน Ha : ค่าเฉลี่ยกิโลเมตรที่ได้ แตกต่างกัน อย่างน้อย 1 คู่ จากตาราง ANOVA เราสรุปได้ว่า ทั้ง Speed และ Weight ต่างก็มีผลทำให้ค่าระยะทางรวมที่วิ่งได้ เมื่อใช้น้ำมันเต็มถังแตกต่างกัน เพราะ ค่า F ที่คำนวณได้มีค่ามากกว่า F-Critical หมายความว่า การใช้ความเร็วเฉลี่ย มากหรือน้อย ก็ทำให้รถยนต์กินน้ำมันมากหรือน้อยตามไปด้วย เช่นเดียวกัน ถ้ามีการบรรทุกน้ำหนักไปด้วย ก็จะมีส่วนทำให้รถกินน้ำมันมากขึ้นไปอีกได้เหมือนกัน ในขณะที่ Interaction ระหว่าง Speed กับ Weight กลับไม่มีผลต่อระยะทางรวมที่ได้หรือไม่มีผลทำให้การกินน้ำมันของรถเปลี่ยนแปลงไป ที่เป็นเช่นนี้ก็เพราะทั้ง Speed และ Weight ต่างก็มีผลต่อ ระยะทางรวม ไปในทิศทางเดียวกัน จึงไม่เกิดจุดตัดกัน หรือ Interaction นั่นเอง
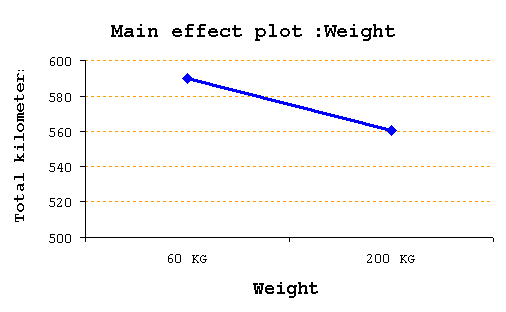
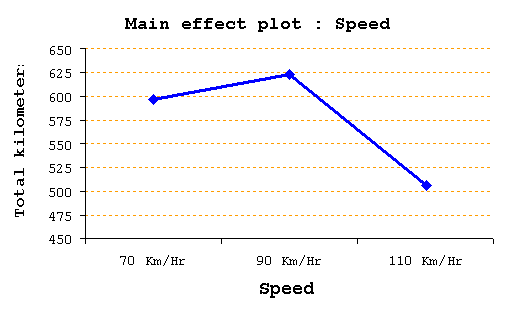
การวิเคราะห์ Main Effect เมื่อเราสรุปผลการทดสอบสมมติฐานนั้น จะเห็นว่าเราค่อนข้างจะมองเห็นภาพหรือผลกระทบจากแต่ละ Factor ยาก การวิเคราะห์ Main Effect จะสามารถทำให้เรามองเห็นภาพดังกล่าวได้ง่ายขึ้น เมื่อเราทำการวิเคราะห์ Main effect : Weight เราก็จะถือว่า Speed ซึ่งเป็นอีก Factor หนึ่งเป็น Random variation ให้เฉลี่ยค่าที่เกิดจากทุก Speed factor ที่แต่ละค่าของ Main Effect : Weight ที่เรากำลังสนใจ ในทางกลับกัน เมื่อเราทำการวิเคราะห์ Main effect : Speed เราก็จะถือว่า Weight ซึ่งเป็นอีก Factor หนึ่งเป็น Random variation ให้เฉลี่ยค่าที่เกิดจากทุก Weight factor ที่แต่ละค่าของ Main Effect : Speed นั้น เช่นกัน Main Effect : Weight คือ 60 Kg Effect = ( 606+615+609+640+633+649+514+523+519 ) / 9 = 589.778 Km 200 Kg Effect = ( 582+576+588+598+612+605+487+501+495 ) / 9 = 560.444 Km Main Effect : Speed คือ 70 Km / Hr Effect = ( 606 +615 +609+582+576+588) / 6 = 596 Km 90 Km / Hr Effect = ( 640+633+649+598+612+605 ) / 6 = 622.833 Km 110 Km / Hr Effect = ( 514+523+519+487+501+495 ) / 6 = 506.5 Km
ตรงนี้ผู้วิเคราะห์ จะได้อะไร? คำตอบคือ ทำให้เห็นว่า ผลที่เกิดจากการเปลี่ยนความเร็วรถ มีผล ( Effect ) ต่ออัตราการใช้น้ำมัน มากกว่า การเปลี่ยนแปลงค่าน้ำหนักบรรทุกนั่นเอง นอกจากนั้น เมื่อเราทำการพล้อต Main effect ก็จะเห็นว่าผลกระทบ ระหว่างปัจจัย Speed กับ Weight จะมีผลต่อ ต่ออัตราการใช้น้ำมัน ในทิศทางเดียวกันคือ ความเร็วเพิ่มขึ้น ก็จะวิ่งได้ระยะทางรวมน้อยลง เช่นเดียวกัน Weight เพิ่มขึ้นก็จะวิ่งได้ระยะทางรวมน้อยลง เมื่อวิเคราะห์ตัวอย่างนี้ด้วย MS Excel จะได้ดังนี้ ( อ่านวิธีการใช้ MS Excel สำหรับ 2-Way ANOVA ได้ที่นี่ )
ตารางส่วนแรกที่ MS Excel แสดงออกมาคือ การวิเคราะห์เชิงตัวเลขชนิดต่างๆ เช่น Main effect , Average และ Total ซึ่งถ้าดูเทียบกับการวิเคราะห์ด้วยมือ ที่ผ่านมานั้นก็จะสามารถมองเห็นได้ว่า ค่าอะไร คืออะไร ตรงนี้ผู้เขียนคงไม่อธิบายเพิ่มมากกว่านี้
ANOVA TABLE
ในส่วน ANOVA TABLE นั้น MS Excel จะแทน Speed ด้วยคำว่า Sample และ Weight ด้วยคำว่า Columns นั่นเพราะเวลาเรานำข้อมูลใส่เราต้องทำตาราง ที่ Weight อยู่ในแนว Column และ Speed เป็นแนว Row ซึ่ง MS Excel จะใช้คำว่า Sample สำหรับข้อมูลในแนว Row เสมอ
การ สรุปผลการวิเคราะห์ ANOVA จาก MS Excel จะมี 2 วิธี คือ 1. เปรียบเทียบ F หาก F-Calculate มากกว่า F-Critical ก็สรุปว่า ปฏิเสธสมมติฐานหลัก ( Ho) จากตาราง Factor Sample (Speed) มี F-Calculate 556.593 มากกว่า F-Critical 3.885 จึงสรุปว่า การเปลี่ยนความเร็วในการขับ มีผลต่ออัตราการกินน้ำมันของรถยนต์ ในขณะที่ Factor Column(Weight) มี F-Calculate 96.8 มากกว่า F-Critical 4.747 จึงสรุปว่าขนาดน้ำหนักบรรทุกมีผลต่ออัตราการกินน้ำมัน ของรถยนต์เช่นเดียวกัน และ Interaction ของทั้งสอง Factor ไม่มีผลใดๆ เพราะ F-Calculated มีค่าน้อยกว่า F-Critical 2. เปรียบเที่ยบ P-Value กับค่า Significant level (a) หาก P-Value น้อยกว่า ก็ให้ปฏิเสธสมมติฐานหลัก (Ho) เช่นเดียวกัน
โจทย์ข้อนี้หากวิเคราะห์โดยใช้ โปรแกรม Minitab จะให้ผลดังนี้ Analysis of Variance for KM Source DF SS MS F P Speed 2 44527.4 22263.7 556.59 0.000 Weight 1 3872.0 3872.0 96.80 0.000 Interaction 2 100.3 50.2 1.25 0.320 Error 12 480.0 40.0 Total 17 48979.8
โปรแกรม Minitab จะให้ผลออกมาเป็น ANOVA Table ซึ่งจะให้ค่า P-Value เป็นเกณฑ์ในการตัดสินใจ การสรุปผลก็เหมือนกับการใช้ MS Excel หรือการคำนวณด้วยมือทุกประการ การวิเคราะห์ FIT & Resisdual การใช้ ANOVA นั้นนอกจากเราจะทำการ Qualify ผลโดยใช้การเปรียบเทียบ Error กับ Total แล้วเรายังจำเป็นต้องวิเคราะห์ให้ลึกลงไปถึงระดับข้อมูลทุกตัว โดยผ่านค่าที่เราเรียกว่า Fit และ Residual หลายท่านอาจจะแปลกใจกับศัพท์ 2 คำนี้ แต่ที่จริงมันก็เหมือนกับคำว่า Mean และ Variation นั่นเอง
ตารางสรุป FIT & Residual ของตัวอย่างข้อนี้
หลักการหา FIT&Residual เราจะยึด หลักที่ว่า Factor ทั้งสอง มีค่าเดิมเราถือว่า ใช้ FIT ร่วมกัน ส่วน Residual คือผลต่างระหว่างค่า Y ใดๆ กับค่า FIT ของกลุ่มที่ค่า Y นั้นเป็นสมาชิกอยู่ ขอยกตัวอย่างวิธีการหา FIT & Residual ง่ายๆ ดังนี้ Weight : 60 KG และ Speed : 70 KM/Hr
Weight : 60 KG และ Speed : 90 KM/Hr
เราใช้ทำอะไรได้บ้าง ผู้เขียนจะนำเสนอในรูปแบบของกราฟแสดงความสัมพันธ์ ดังต่อไปนี้
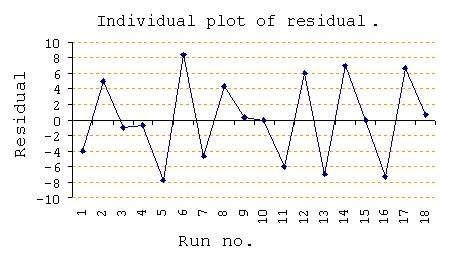
Individual plot of residual : เป็นการนำค่า Residual แต่ละค่ามา Plot เป็นกราฟ ลักษณะของกราฟจะเป็นตัวบ่งบอกว่าข้อมูลที่เราได้ทำการวิเคราะห์นั้น เป็น Randomly data (ข้อมูลที่ได้จากการสุ่มที่ถูกต้องหรือไม่) หากเป็น Randomly เราจะได้กราฟ ที่ไม่สามารถคาดเดาค่าในอนาคตได้ ไม่มีแนวโน้มขึ้น หรือลงอย่างเดียว (เงื่อนไขเหมือนกับ SPC)
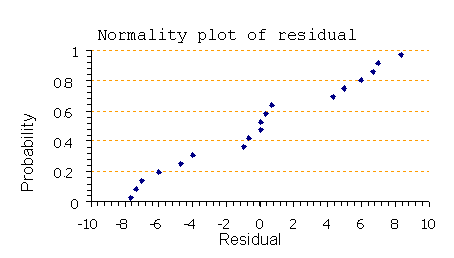
Normality plot of residual: เป็นการพลอตค่า Residual กับค่า Probability หลักการเช่นเดียวกับการทำ Normality test เพื่อทำการ Qualify ข้อมูลที่เรากำลังจะวิเคราะห์โดย ANOVA หากไม่ผ่านเงื่อนไข Normality test ก็ถือว่าข้อมูลนี้ไม่ Qualified เช่นกัน
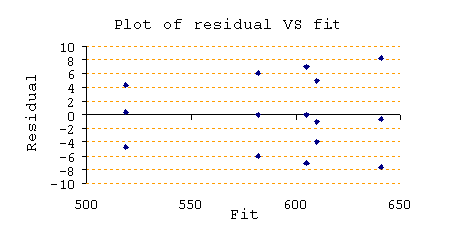
Plot of residual VS Fit : เพื่อทำการตรวจสอบว่า Variation ของข้อมูลนั้นแตกต่างกันหรือไม่ ถ้าแตกต่างกัน จะเห็นว่าบาง Fit จะมีจุด Residual อยู่ห่างจาก 0 มากกว่าจุดอื่นๆ อย่างผิดปกติ ลักษณะอย่างกราฟข้างบนแสดงให้เห็นลักษณะที่ Variation ไม่แตกต่างกัน ในแต่ละ Fit
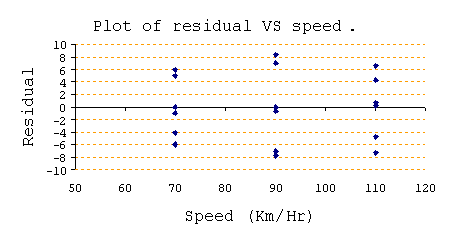
Plot of residual VS speed: เป็นการพลอต Residual เปรียบเทียบระหว่างค่า ของ Factor จะให้ผลสรุปเช่นเดียวกับ Plot of residual VS Fit นอกจากนั้นเรายังสามารถพบเห็นความไม่ปกติ บางอย่างตัวอย่างเช่น จากกราฟข้างบน แต่ละค่า Speed จะเห็น Residual มีแนวโน้มเกาะกันเป็นคู่ๆ ซึ่งถ้ารู้สึกผิดปกติมากเกินไปก็แสดงว่าข้อมูลไม่ qualified ได้เช่นกัน
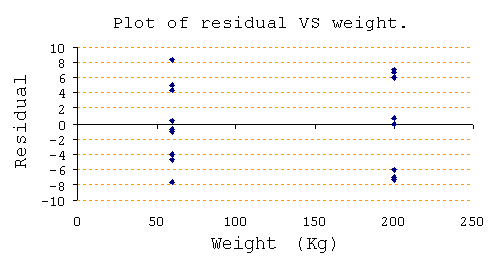
Plot of residual VS weight: เป็นการพลอต Residual เปรียบเทียบระหว่างค่า ของ Factor จะให้ผลสรุปเช่นเดียวกับ Plot of residual VS Fit นอกจากนั้นเรายังสามารถพบเห็นความไม่ปกติ บางอย่างตัวอย่างเช่น จากกราฟข้างบน แต่ละค่า weight จะเห็น Residual มีแนวโน้มเกาะกันเป็นคู่ๆ ซึ่งถ้ารู้สึกผิดปกติมากเกินไปก็แสดงว่าข้อมูลไม่ qualify ได้เช่นกัน (หากท่านผู้อ่านท่านใด ต้องการ Excel file ที่ผู้เขียน ใช้ในเรื่องนี้กรุณาติดต่อขอรับได้ทาง E-mail )
|