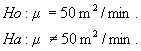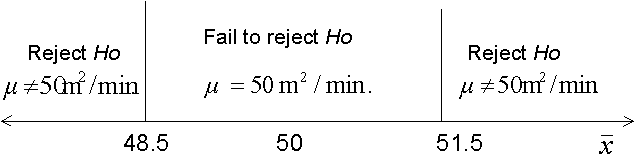|
สมมติฐานทางสถิติ (Statistical Hypothesis) หัวข้อนี้ จะกล่าวถึงพื้นฐานการตั้งสมมติฐานทางสถิติ การทดสอบสมมติฐานดังกล่าว และการสรุปผลการทดสอบสมมติฐาน โดยทั่วไปเมื่อเราเกิดข้อปัญหา หรือข้อสงสัยใดๆแล้ว ก่อนอื่นเราจะต้องเริ่มต้นด้วยการตั้งข้อสงสัยกับปัญหาดังกล่าวเสียก่อน แล้วค่อยนำข้อสงสัยดังกล่าว มาพิสูจน์ว่า ที่เราสงสัยดังกล่าวเป็นจริงหรือไม่ ซึ่งในวิชาสถิติ เราเรียกข้อสงสัยดังกล่าวว่า สมมติฐาน และการพิสูจน์ข้อสงสัยเราก็เรียกว่า การทดสอบสมมติฐาน เช่นเดียวกัน การที่เราสามารถใช้ข้อมูลจากตัวอย่างเพื่อประมาณค่าพารามิเตอร์ของประชากรได้นั้น ไม่ได้แปรว่าเรารู้พฤติกรรม ของประชากรได้ทั้งหมด เพราะยังมีปัญหาทางวิศวกรรมอีกมากมาย ที่ต้องการการตัดสินใจ ในทางปฏิบัติผู้ใช้สถิติจะนำ เอาปัญหาดังกล่าวมาตั้งเป็นสมมุติฐาน แล้วก็ทำการทดลอง เก็บข้อมูล แล้ววิเคราะห์ทางคณิตศาสตร์ และตัดสินใจที่จะยอมรับหรือปฏิเสธสมมติฐาน โดยอ้างอิงตามผลการวิเคราะห์ดังกล่าว ซึ่งเราเรียกกระบวนการทั้งหมดนี้ว่า การทดสอบสมมติฐาน (Hypothesis Testing) ซึ่งจัดว่าเป็นการประยุกต์ใช้หลักวิชาสถิติ ที่สำคัญ ตัวอย่าง วิศวกรกำลังศึกษาเรื่องอัตราการไหลของน้ำหล่อเย็นในเครื่องกำเนิดไฟฟ้าเครื่องหนึ่ง โดยข้อกำหนดบ่งบอกไว้ว่า อัตราการไหลของน้ำหล่อเย็นนี้จะต้องเท่ากับ 50 ลูกบาตรเมตรต่อนาที แต่ปรากฏว่าเกิดปัญหาเรื่องความร้อนขึ้นเสมอๆ โดยวิศวกรสงสัยว่าอัตราไหลของน้ำหล่อเย็นอาจจะไม่ตรงตามข้อกำหนดก็ได้ จึงต้องการพิสูจน์ทราบปัญหาดังกล่าว โดยต้องการตัดสินใจว่า อัตราการไหลของน้ำหล่อเย็น เท่ากับ 50 ลูกบาตรเมตรต่อนาที หรือไม่เท่ากับ 50 ลูกบาตรเมตรต่อนาที
( เขียนเป็นภาษามนุษย์) Ho : อัตราการไหลของน้ำหล่อเย็นเท่ากับ 50 ลูกบาตรเมตรต่อนาที ( เขียนเป็นภาษาทางวิชาสถิติ ) Ho : m = 50 m2/min.
- ถ้าตัวอย่างนี้ต้องการพิสูจน์์ว่า เท่าหรือไม่เท่า ก็จะเขียนสมมติฐานทางเลือกได้ดังนี้ ( เขียนเป็นภาษามนุษย์) Ha : อัตราการไหลของน้ำหล่อเย็นไม่เท่ากับ 50 ลูกบาตรเมตรต่อนาที
( เขียนเป็นภาษาทางวิชาสถิติ )
ในกรณีนี้ เท่ากับว่า Alternative hypothesis จะเป็นจริงถ้าค่า น้อยกว่า หรือมากกว่า 50 m2/min. เราจึงเรียกกรณีนี้ว่า Two-side alternative hypothesis - บางกรณีเราต้องการพิสูจน์ว่า จะมากหรือน้อยกว่า 50 m2/min. ก็จะเขียนสมมติฐานทางเลือกได้ดังนี้ ( เขียนเป็นภาษามนุษย์) Ha : อัตราการไหลของน้ำหล่อเย็นน้อยกว่า 50 ลูกบาตรเมตรต่อนาที ( เขียนเป็นภาษาทางวิชาสถิติ ) Ha : m < 50 m2/min.
หรือ Ha : อัตราการไหลของน้ำหล่อเย็นน้อยกว่า 50 ลูกบาตรเมตรต่อนาที Ha : m > 50 m2/min. ในกรณีแรก Alternative hypothesis จะเป็นจริงถ้าค่า น้อยกว่า 50 m2/min. และในกรณีที่สอง Alternative hypothesis จะเป็นจริงถ้าค่ามากกว่า 50 m2/min. เราจึงเรียกทั้งสองกรณีนี้ว่า One-side alternative hypothesis การตั้งสมมติฐานเราจะกล่าวถึงประชากรเท่านั้น ไม่ใช่ตัวอย่างที่เราเก็บมา ค่าคงที่ที่เรานำมาใช้ตั้งสมมติฐานหลักนั้นจะมีที่มาได้ 3 ทางดังนี้
การทดสอบสมมติฐานทางสถิติ (Tests of Statistical Hypotheses.) จากโจทย์ตัวอย่าง สมมติฐานหลักที่เราต้องการทดสอบคืออัตราการไหลของน้ำหล่อเย็น 50 ลูกบาตรเมตรต่อนาที ซึ่งเป็นค่าโดยเฉลี่ย และหากเราตั้งสมมติฐานรองว่า อัตราการไหลของน้ำหล่อเย็นไม่เท่ากับ 50 ลูกบาตรเมตรต่อนาที เราจึงเขียนสมมติฐานที่ต้องการทดสอบ ได้ดังนี้
วิศวกรเริ่มบันทึกค่าอัตราการไหลของน้ำ โดยวัดค่ามาจำนวน 20 ค่า โดยเลือกบันทึกค่าในช่วงเวลาที่มีปัญหาเรื่องความร้อน ดังที่เป็นปัญหาตามที่กล่าวตั้งแต่แรก และการบันทึกค่าแต่ละครั้งก็ให้มีช่วงห่างกันอย่างต่ำหนึ่งชั่วโมง เมื่อเริ่มทำการทดสอบสมมติฐาน จะต้องนำข้อมูลตัวอย่าง ทั้ง 20 ค่านี้มาหาค่าเฉลี่ย ( X ) ซึ่งก็คือค่า ประมาณการของค่ากลางของประชากร ( m ) นั่นเอง เราจะยอมรับสมมติฐานหลัก ถ้าค่า ( X ) อยู่ใกล้เคียงกับค่า 50 m2/min ในทางตรงกันข้ามเราจะปฏิเสธสมมติฐานหลักถ้าค่าไม่ใกล้เคียง 50 m2/min และยอมรับ สมมติฐานทางเลือกแทน เราจึงเรียกค่าเฉลี่ยของตัวอย่าง (
X ) ว่า ตัวสถิติในการทดสอบ ( Test statistic )
แต่ในทางปฏิบัติ
สมมติเก็บค่าตัวอย่าง 20
ตัวอย่างใหม่เป็นรอบที่สองหรือสาม
หรือหลายๆรอบ เมื่อหาค่าเฉลี่ยของตัวอย่างแต่ละรอบ
ก็จะได้แตกต่างกัน
ทั้งมากหรือน้อยกว่า 50 m2/min
ดังนั้นจะยอมรับหรือปฏิเสธ
สมมติฐานหลักจึงต้องใช้ทฤษฎี
Confidence Interval เข้ามาสนับสนุน ถ้าหากในการเก็บตัวอย่างครั้งนี้
เราได้ค่าย่านความเชื่อมั่น (
Confidence interval ) อยู่ที่
ค่าตั้งแต่ 48.5 จนถึง 51.5 เราถือว่าเป็นย่านที่ยอมรับ Ho หรือ ไม่สามารถปฏิเสธ Ho ได้ เราเรียกว่า Acceptance region ค่า 48.5 และ 51.5 ซึ่งเป็นจุดแบ่งระหว่างการยอมรับและปฏิเสธ Ho เราเรียกว่าค่าวิกฤติ ( Critical values ) ย่านที่ค่าน้อยกว่า 48.5 และมากกว่า 51.5 เราถือว่าเป็นย่านที่ปฏิเสธ Ho หรือเรียกว่า Critical region แต่ในบางครั้งเราก็อาจจะปฏิเสธสมมติฐานหลัก หรือ Reject Ho ทั้งๆที่จริงๆแล้วค่าเฉลี่ย m (ของประชากร) ยังเท่ากับ 50 m2/min อยู่ แต่ด้วยเป็นเพราะค่าตัวอย่างที่เราไปสุ่มมามีโอกาสที่จะได้เกาะกลุ่มกันอยู่ค่าที่เมื่อหาค่าเฉลี่ยแล้ว ตกอยู่ในย่านปฏิเสธ Ho แสดงว่าเราตัดสินใจผิด เราเรียกเหตุการณ์กรณีนี้ว่า ความผิดพลาดประเภทที่ 1 ( Type I error) ในทางตรงกันข้ามบางครั้งเราก็ยอมรับสมมติฐานหลักว่าค่า m ยังเท่ากับ 50 m2/min อยู่ ทั้งๆที่ ค่าเฉลี่ยของประชากร ( m ) จริงๆเปลี่ยนไปแล้วและไปอยู่ในย่านปฏิเสธ Ho แล้ว แต่ด้วยการสุ่มเก็บค่าตัวอย่างทำให้ค่าเฉลี่ยของตัวอย่าง ( X ) ตกอยู่ในย่านยอมรับ Ho แสดงว่าเกิดการตัดสินใจผิดพลาด เราเรียกเหตุการณ์กรณีนี้ว่า ความผิดพลาดประเภทที่ 2 ( Type II error)
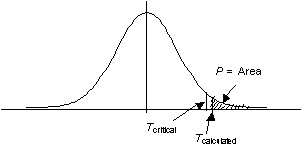
ค่าระดับนัยสำคัญ ( Level of significance ) หมายถึงค่าโอกาสที่เราจะตัดสินใจผิดพลาด โดยธรรมชาติกรณีความผิดพลาดประเภทที่ 1 ( Type I error ) นั้น ระดับความรุนแรงหรือความซีเรียส จะมากกว่ากรณีความผิดพลาดประเภทที่ 2 ( Type II error ) เช่น กรณีที่ศาลตัดสินให้ผู้บริสุทธิ์ เป็นผู้มีความผิด เราจะถือว่าไม่น่าให้เกิดบ่อยๆ แต่ถ้าตัดสินว่าผู้กระทำความผิด ไม่ต้องได้รับโทษ อันเนื่องมาจากหลักฐานยังไม่เพียงพอ ยังมีความรุนแรงหรือซีเรียสน้อยกว่า ในวิชาสถิติเรามีความจำเป็นที่จะต้องลดระดับความเสี่ยงในการตัดสินใจผิดให้ต่ำที่สุด หรืออีกนัยหนึ่งก็คือเราจะต้องให้มีเกิดความผิดพลาดในการตัดสินใจให้น้อยที่สุด เราเรียกว่า ระดับนัยสำคัญ กรณี Type I error เราใช้สัญลักษณ์ a ( Alpha) โดยทั่วไป เราจะยอมรับให้มีค่าในช่วง 0.01 ถึง 0.1 หรือให้เกิดการตัดสินใจผิดพลาดประเภทที่ 1 ได้ 1% ถึง 10% นั่นแปลว่าระดับความมั่นใจ ที่ตัดสินใจถูกต้องที่ยอมรับได้จะอยู่ที่ 0.99 ถึง 0.90 หรือ 90% ถึง 99% ในกรณี Type II error เราใช้สัญลักษณ์ b ( Beta) โดยทั่วไป เราจะยอมรับให้มีค่าในช่วง 0.1 ถึง 0.3 หรือให้เกิดการตัดสินใจผิดพลาดประเภทที่ 2 ได้ 10% ถึง 30% นั่นแปลว่าระดับความมั่นใจ ที่ตัดสินใจถูกต้องที่ยอมรับได้จะอยู่ที่ 0.90 ถึง 0.70 หรือ 70% ถึง 90% แต่ทั้งนี้ทั้งนั้น การที่เราจะเลือกค่านัยสำคัญทั้งสองนี้ เท่าใด ก็ขึ้นอยู่กับความรุนแรงหรือซีเรียส ถ้าหากมีการตัดสินใจผิดพลาด ไม่ได้มีสูตรตายตัวหรือข้อกำหนดตายตัว ขึ้นอยู่กับสถานะการ P-Value โดยทั่วไป เมื่อเราต้องการสรุปผลการทดสอบสมมติฐานนั้น เราจะสนใจว่า สมมติฐานหลัก (Null hypothesis) ถูกยอมรับหรือปฏิเสธ ถ้าถูกยอมรับ นั่นก็แปลว่า สมมติฐานเป็นจริง หรือแปลว่าสมมติฐานนั้นไม่เป็นจริง ถ้าถูกปฏิเสธ จึงมีการกำหนดค่าระดับนัยสำคัญ เพื่อที่จะบอกยอมรับหรือปฏิเสธ Null hypothesis เราเรียกว่า Probability Value ( P-Value ) ค่า P - Value นี้จะอ้างอิงอยู่กับ a โดยที่ P-Value คือค่า Actual ของ probability ซึงได้จากการคำนวณ ส่วน a คือเส้นกำหนด หรือจุดแบ่งระหว่างการยอมรับ หรือปฏิเสธสมมติฐานหลัก ซึ่งก็คือ Probability เหมือนกัน เราจะยอมรับสมมติฐานหลัก ถ้า P-Value มากกว่า a และปฏิเสธ ถ้า P-Value เท่าหรือน้อยกว่า การคำนวณหาค่า P-Value มีทั้งหมด 3 กรณี ตามการกำหนดรูปแบบการทดสอบสมมติฐาน คือ กรณีการทดสอบมากกว่า ( Upper-tailed test) ค่า P-value จะเท่ากับพื้นที่ด้านขวามือของค่า Z หรือ t ที่คำนวณได้ ( Tcalculated) ในกรณีนี้ a ก็จะเท่ากับพื้นที่ตั้งแต่ขวามือของค่า Tcritical ไปจนสุดขอบ
P-Value = Area in upper tail
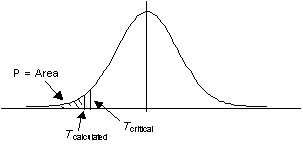
กรณีการทดสอบน้อยกว่า ( Lower-tailed test) ค่า P-value จะเท่ากับพื้นที่ด้านซ้ายมือของค่า -Z หรือ -t ที่คำนวณได้( Tcalculated) ในกรณีนี้ a ก็จะเท่ากับพื้นที่ตั้งแต่ซ้ายมือของค่า Tcritical ไปจนสุดขอบ
P-Value = Area in lower tail
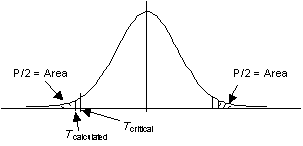
กรณีการทดสอบไม่เท่ากับ (Two-tailed test) ค่า P-value จะเท่ากับผลรวมของพื้นที่ด้านซ้ายมือของค่า -Z หรือ -t และทางขวามือของ ค่า Z หรือ t ที่คำนวณได้ ในกรณีนี้ a ก็จะเท่ากับสองเท่าของพื้นที่ตั้งแต่ซ้ายมือของค่า Tcritical หรือ -Tcriticalไปจนสุดขอบ
P-Value = Sum of area in two tails
ดังนั้น a คือ พื้นที่ใต้กราฟ เมื่อใช้ค่า Z หรือ T- Critical ซึ่งก็คือเกณฑ์ หรือ Limit นั่นเอง ส่วน P-Value คือพื้นที่ใต้กราฟ เมื่อใช้ค่า Z หรือ T- Calculated ซึ่งก็คือค่า Actual ที่ได้จากการ วิเคราะห์ จากข้อมูลจริง
|