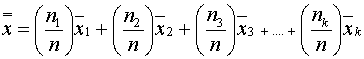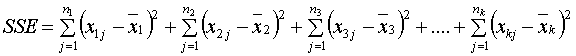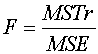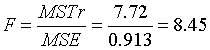|
Single –Factor ANOVA
(One-Way ANOVA) จากตัวอย่างเรื่อง ความเร็วในการขับขี่รถ และระยะทางที่ขับได้เมื่อเติมน้ำมันเต็มหนึ่งถัง ที่ผ่านมานั้นเป็นตัวอย่างของ Single factor ANOVA ดังนั้นความหมายของ Single-Factor ANOVA คือการวิเคราะห์ ข้อมูลเมื่อการทดลองนั้นมีเพียงปัจจัย (Factor) เดียวเท่านั้นที่ถูกควบคุม (Treat) คือ อัตราเร็วต่อชั่วโมง (Speed) บางครั้งก็จะเรียกว่า Treatmented factor ในขณะที่แต่ละค่าของ Speed ในการทดลองนั้น เราจะเรียกว่า Level หรือ Treatment levels ด้วยเช่นเดียวกัน ส่วนปัจจัยอื่นจะปล่อยให้คงเดิม ไม่ได้มีการควบคุมหรือสนใจ คำ¨ÓˇŃ´¤ÇŇÁµčҧćăą ANOVA
คำว่า Grand average คือค่าเฉลี่ยของค่าเฉลี่ย อีกที ซึ่งก็คือการให้ค่าน้ำหนักหรืออัตราส่วนของ Sample size เทียบกับ Total sample size และค่าเฉลี่ยแต่ละค่า ตามสมการนี้
เราสามารถหาค่า Between-samples variation จากสมการ
เนื่องจากสมการเป็นการบวกกันของพจน์กำลังสอง
จึงเรียกอีกอย่างว่า
“ Treatment sum of squares” และเราสามารถหาค่า Within-samples variation จากสมการ
ซึ่งสมการนี้สุดท้าย ก็จะมีค่าเท่ากับĘมการต่อไปนี้
เนื่องจากในการใช้ ANOVA นั้น ค่า Variation จะเป็นค่าที่แสดงถึงขนาดของความคลาดเคลื่อนออกจากค่าเฉลี่ย ของบรรดาข้อมูลใดๆ เราจึงเรียกว่า Error แทนคำว่า Variation และจากสมการข้างบนนั้นเป็นการหาค่าผลบวกของพจน์กำลังสองของ Variation (Error) เราจึงเรียกค่านี้ว่า " Sum square of error " และเมื่อนำ SSTr มารวมกันกับ SSE เราจึงเรียกว่า Sum square total จากคำว่า Between-samples หรือ Within-sample นั้น Sample จะหมายถึง Level หรือ Treatment นั่นเอง ถ้า Between ก็จะหมาย ระหว่าง Level(Treatment ) ส่วน Within ก็จะหมายถึง ระหว่างข้อมูล ในแต่ละ Level (Treatment ) กรุณาดูในตัวอย่างที่จะกล่าวถึง เราสามารถหาค่า Degree of freedom ได้ดังนี้ เมื่อ SST คือ ผลรวมทั้งหมด ดังนั้น df = n-1 โดยที่ n คือผลรวม ของจำนวนตัวอย่าง(ข้อมูล) ทั้งหมดจาก ทุกๆ Level นั่นเอง และ SSTr คือผลรวม ระหว่าง Level ดังนั้น df = k-1 โดยที่ k คือจำนวน Level นั่นเอง และ SSE คือผลรวมที่เกิดจาก ทุกๆข้อมูลของทุก Level ดังนั้น df = n-k จุดประสงค์ที่เราต้องหาค่า Degree of freedom ก็เพราะเราต้องการหาค่า เฉลี่ยของแต่ละพจน์ในสมการ
MSTr : Mean square for treatments (Between-sample) MSE : Mean square error (Within-sample) อัตราส่วนระหว่าง MSTr กับ MSE คือค่า สถิติที่ใช้ทดสอบ ANOVA ( Test statistic) ซึ่งเราเรียกย่อๆ ว่า F
มีมากมายหลายสมการและหลายค่าจริง เพื่อให้มองเห็นภาพรวมของ ANOVA จึงได้มีการสรุปในรูปตาราง ซึ่งเรียกว่า ANOVA Table ดังนี้
ตัวอย่างที่ 1 วิศวกรที่ทำหน้าที่ควบคุมคุณภาพของบริษัทผลิต Harddisk แห่งหนึ่งต้องการทดสอบ Bearing จาก Supplier 5 บริษัท เพื่อคัดเลือกว่า Bearing จากบริษัท (Brand) ใด ที่เมื่อประกอบเข้ากับชุด มอเตอร์ขับแล้วเกิดการสั่นสะเทือน (Vibration) น้อยที่สุด เนื่องจากปัจจัยที่สำคัญของคุณภาพ Harddisk คือการสั่นสะเทือน หรือ Noise ขณะทำงานของ Harddisk เขาจึงได้ออกแบบการทดลองโดยมีการสุ่มตัวอย่างมอเตอร์มา 30 ตัว และแบ่งออกเป็น 5 กลุ่มๆละ 6 ตัว โดยแต่ละกลุ่มก็ใช้กับ Bearing ตัวอย่างจากบริษัทเดียวกัน เมื่อประกอบเข้ากับมอเตอร์และเริ่มทำงานแล้ว เขาได้ทำการการวัดความสั่นสะเทือนของมอเตอร์ และได้ค่าออกมาดังตาราง ให้ทำการทดสอบว่า Bearing จากทั้ง 5 บริษัท (Brand) นั้นให้ผลการสั่นสะเทือนต่างกันหรือไม่
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Unit : Micro inch ตาราง ค่าความสั่นสะเทือนของมอเตอร์ เมื่อใช้ Bearing จากแต่ละบริษัท (Brand) เมื่อข้อมูลเป็นลักษณะนี้ ก็แน่นอนว่าผู้ทดลองจะต้องวิเคราะห์โดยใช้ ANOVA แน่นอน จึงจำเป็นต้องตรวจสอบข้อมูลก่อนทำการวิเคราะห์ เพื่อให้มั่นใจว่า ทุกอย่างตรงตามเงื่อนไขที่สำคัญของ ANOVA เมื่อดูจากขั้นตอนการทดลองจะเห็นว่าเงื่อนไขการสุ่มตัวอย่างก็ถูกต้อง โดยที่มอเตอร์ที่ใช้ทดสอบนั้นก็เป็นมอเตอร์ Brand เดียวกัน และเป็นชนิดที่ใช้ในการผลิตทั่วไป สมมติว่าเมื่อทดสอบความเป็นการแจกแจงแบบปกติแล้วก็ผ่านทั้ง 5 กลุ่มข้อมูล และค่า Standard deviation ก็ถือว่าไม่มีความแตกต่างกันอย่างมีนัยสำคัญ ถ้ากำหนดให้ค่าระดับนัยสำคัญ (Significant level ) a = 0.05 ให้ทำการวิเคราะห์ว่า Bearing ทั้ง 5 Brand ดังกล่าวให้ค่าระดับความสั่นสะเทือนแตกต่างกันหรือไม่ ขั้นตอนการวิเคราะห์ข้อมูล 1. ตั้งสมมติฐาน Ho : ค่าเฉลี่ยความสั่นสะเทือนของมอเตอร์อันเนื่องมาจากการใช้ Bearing ต่าง Brand ทั้ง 5 Brand ไม่แตกต่างกัน Ha : ค่าเฉลี่ยความสั่นสะเทือนของมอเตอร์อันเนื่องมาจากการใช้ Bearing ต่าง Brand ทั้ง 5 Brand แตกต่างกัน อย่างąéอยคู่หนึ่ง ถ้าเขียนเป็นภาษา Statistic จะได้ดังนี้ Ho : m1=m2=m3=m4=m5 Ha : At least two m's are different 2. หาค่า Grand average จาก
3. หาค่า SSTr และ SSE
4. หาค่า MSTr และค่า MSE
เมื่อ n คือ จำนวนข้อมูลรวมทั้งหมด k คือ จำนวนกลุ่มข้อมูล (จากโจย์ข้อนี้ คือจำนวน Brand นั่นเอง )
5. หาค่า F Statistic จาก
6. สรุปในรูป Anova Table ได้ดังนี้
7. หาค่า F Critical จากตาราง ( F-Table) ที่ Fn1=4,n2=25,a =0.05 F-Critical จากตารางได้ = 2.76
8. สรุปสมมติฐาน เมื่อ F ที่คำนวนได้ (Calculated ) มากกว่า F-Critical เราจึงปฏิเสธสมมติฐานหลัก ที่ว่า " ค่าเฉลี่ยความสั่นสะเทือนของมอเตอร์อันเนื่องมาจากการใช้ Bearing ต่าง Brand ทั้ง 5 Brand ไม่แตกต่างกัน " นั่นก็แปลว่า Bearing จาก 5 Brand ที่ทำการทดลองนั้น ให้ค่าความสั่นสะเทือนของมอเตอร์แตกต่างกันอย่างมีนัยสำคัญ
หากโจทย์ข้อนี้ ใช้ ฟังก์ชันของ MS-Excel ในการวิเคราะห์จะให้ผลดังนี้
MS-Excel จะให้ตารางสรุป (Summary )พร้อมด้วย Anova Table ซึ่งวิธีการแปลความหมายจากตารางเราสามารถตัดสินใจได้ 2 วิธีคือ 1. เปรียบเทียบค่า F- calculated (ในตารางจะเป็น F ) กับค่า F-critical (ในตารางจะเป็น F crit ) ถ้าค่า F-calculated มากกว่า ก็ให้ปฏเสธสมมติฐานหลัก (Ho) ในทางตรงกันข้าม เราจะยอมรับสมมติฐานหลัก (Ho) ถ้าหาก F-critical มากกว่า 2. เปรียบเทียบค่า P-Value กับค่าระดับนัยสำคัญ (a) ถ้า P-Value น้อยกว่าก็ให้ปฏเสธสมมติฐานหลัก (Ho) ในทางตรงกันข้าม เราจะยอมรับสมมติฐานหลัก (Ho) ถ้าหาก P-Value มากกว่า ซึ่งทั้งสองวิธี จะให้ผลตรงกันเสมอ ดังนั้น หากเราทำการวิเคราะห์ด้วยมือ เราก็เลือกใช้วิธีที่ 1 โดยหาค่า F-critical ได้จากตาราง แต่ถ้าใช้โปรแกรมคอมพิวเตอร์ช่วยในการวิเคราะห์ ก็สามารถเลือกใช้วิธีที่ 2 ก็ได้เช่นกัน
หากโจทย์ข้อนี้เราวิเคราะห์โดยใช้โปรแกรม Minitab จะให้ผลดังนี้ One-way ANOVA: Brand 1, Brand 2, Brand 3, Brand 4, Brand 5 Analysis of Variance Source DF SS MS F P Factor 4 30.855 7.714 8.44 0.000 Error 25 22.838 0.914 Total 29 53.694
Individual 95% CIs For Mean Based on Pooled StDev Level N Mean StDev ---------+---------+---------+------- ฺฺ Brand 1 6 13.683 1.194 (----*-----) Brand 2 6 15.950 1.167 (----*-----) Brand 3 6 13.667 0.816 (----*----) Brand 4 6 14.733 0.940 (----*-----) Brand 5 6 13.083 0.479 (----*-----) ---------+---------+---------+------- Pooled StDev = 0.956 13.5 15.0 16.5
จากผลการวิเคราะห์ จะห็นว่า Minitab จะให้ผลเป็น Anova Table และ ให้ตัดสินใจโดยค่า P-Value เท่านั้น นอกจากนั้นแล้ว Minitab ยังให้ผลการวิเคราะห์ในเชิงคุณภาพ ด้วยโดยจะแสดง Confidence interval ของแต่ละกลุ่มข้อมูลให้ด้วย ซึ่งเราก็สามารถตัดสินใจโดยใช้ กราฟ Confidence Interval นี้ได้ด้วย โดยถ้าหาก Interval อันใดอันหนึ่ง ไม่คาบเกี่ยว หรือซ้อนทับกันเลยกับอีกอันหนึ่งหรือกลุ่มอื่นๆ เราก็สามารถสรุปได้เช่นกันว่า เราปฏิเสธสมมติฐานหลัก จากตัวอย่าง Confidence Interval ข้างบน - Brand 1,3,5 ไม่ทับซ้อนกันเลยกับ Brand 2 - Brand 5 ไม่ทับซ้อนกันเลยกับ Brand 2,4
เนื่องจาก Anova ให้ข้อสรุปแค่ว่า ให้ปฏิเสธหรือยอมรับสมมติฐานหลัก (Ho) เท่านั้น ไม่ได้สรุปว่าอะไรดีกว่าอะไร ดังผู้ทำการทดลองจำเป็นต้องวิเคราะห์ต่อ ซึ่งก็มีหลายวิธี ตัวอย่างเช่น - ดูจากกราฟ Confidence Interval เราก็พอจะเห็นว่า Brand 1,3,5 นั้นให้ค่าความสั่นสะเทือนใกล้เคียงกัน ส่วน Brand 2,4 นั้นก็ใกล้เคียงกัน แต่สูงกว่า Brand 1,3,5 หากต้องเลือกใช้ ก็ควรเลือก Brand 1,3,5 ดังกล่าว หรืออาจจะนำ ทั้ง 3 Brand ดังกล่าว ไปทำการทดลองในเรื่องอื่นๆ เช่น อายุการใช้งาน ราคา หรือ ปริมาณของเสีย เมื่อใช้ในสายการผลิต เพื่อให้ได้ Brand ที่ดีที่สุดจริงๆ
|