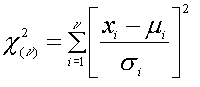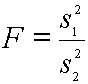|
การกระจายตัวของค่าตัวอย่าง ( Sampling Distributions ) ืถือเป็นพื้นฐานสำคัญสำหรับผู้ที่จะศึกษาในเรื่องสถิติเชิงอนุมาน ( Inferential Statistics) เพราะหัวใจสำคัญอยู่ที่ว่า ทำอย่างไรเรา จะใช้สาระที่เราได้จาก การศึกษากลุ่มตัวอย่าง แล้วเราสามารถที่จะสรุปหรืออธิบายถึงประชากรได้อย่างถูกต้องหรือใกล้เคียงที่สุด การกระจายตัวของค่ากลางของตัวอย่าง ( Sampling Distributions of the Mean ) ในหัวข้อนี้เราจะให้ความสำคัญกับการใช้ค่าเฉลี่ยของตัวอย่าง ( X ) เพื่อพยากรณ์ค่ากลางของประชากร ( m ) ซึ่งเราไม่สามารถรู้ค่า ที่แท้จริงได้ ที่สำคัญคือ เราจะรู้ได้อย่างไรว่า ( X ) พยากรณ์ค่ากลางของประชากร ( m ) ได้ถูกต้องแค่ไหน ถ้าเราให้ ( X ) คือค่าเฉลี่ย ของตัวอย่าง X1 , X2 , X3 ,...... , Xn ที่สุ่มเก็บมาจากประชากรหรือกระบวนการ ที่มีค่ากลางคือ ( m ) และมีค่าเบี่ยงเบนมาตรฐาน (s ) เช่นเดียวกับการ กระจายชนิดอื่น การกระจายของค่ากลางของตัวอย่าง ก็จะมีค่ากลางและค่าเบี่ยงเบนมาตรฐาน เฉพาะเหมือนกัน โดยที่ค่ากลางจะประมาณเท่ากับค่ากลางของประชากรแม่ ตามสมการ
โดยธรรมชาติแล้ว การกระจายของประชากรแม่ ย่อมมีการกระจายที่กว้างกว่าการกระจายของค่าตัวอย่าง หรือพูดง่ายๆคือ ค่า ( s ) การกระจายของประชากรจะโตกว่าของตัวอย่าง โดยประมาณเป็นไปตามสมการต่อไปนี้
โดยที่ sx : ค่า Standard deviation ของการกระจายของค่าเฉลี่ยของตัวอย่าง s : ค่า Standard deviation ของการกระจายของประชากร n : จำนวน ( X ) ตัวอย่าง นั่นแปลว่า เมื่อจำนวน ( X ) ตัวอย่าง เพิ่มขึ้น ค่าเบี่ยงเบนมาตรฐานจะยิ่งเล็กลง T-Distribution ( Student's t Distribution )เมื่อเริ่มแรก ได้มีการใช้ Z- Distribution หรือ Standard Normal Distribution อย่างกว้างขวาง ในประเทศยุโรป จนกระทั่งมีวิศวกร ชาวไอร์แลนด์ คนหนึ่งที่ทำงานในโรงงานผลิตเบียร์ ได้สังเกตเห็นว่า การที่เขาเก็บตัวอย่างมาแค่จำนวนวนไม่มากนั้น ทำให้เขาได้ Distribution ที่ไม่ตรงกับ Standard normal distribution เสมอ และถ้าเขาเพิ่มหรือลดจำนวนตัวอย่างที่สุ่มมา Distribution ก็จะแปรเปลี่ยนไป ดังนั้น จำนวนตัวอย่างจึงมีผลต่อ t-Distribution ด้วยนอกจาก ค่ากลางและค่าเบี่ยงเบนมาตรฐาน แต่เมื่อต้องการอธิบายถึงจำนวนตัวอย่าง เราจะเรียกว่า Degree of freedom แทน เขาได้ทำการทดลองเขียนรายงานและตีพิมพ์ผลสรุปว่า การที่สุ่มตัวอย่างมาแค่จำนวนหนึ่ง หากใช้ Standard normal distribution ในการวิเคราะห์จะให้ผลไม่ถูกต้อง แต่ด้วยข้อกำหนดทางสังคม ในยุคที่ อังกฤษ ปกครองไอร์แลนด์อย่างเข้มงวด เขาจึงไม่อยากแสดงตัวเองว่าเป็นผู้เขียนรายงาน จึงได้ใช้นามแฝงว่า Student's t ต่อมาทฤษฎีนี้ ได้รับการยอมรับเป็นอย่างมาก จึงได้เรียก Distribution ที่ได้จากการสุ่มตัวอย่าง ว่า Student's t distribution หรือ เรียกย่อๆ ว่า t - Distribution มาจนถึงบัดนี้ เช่นเดียวกับ Z-Score เมื่อเราเก็บตัวอย่างมา เราก็จะหา T-Score โดยใช้สูตร ดังต่อไปนี้ คุณสมบัติของ t-Distribution จะเหมือนกันกับ Standard normal distribution เกือบทุกประการ เพียงแต่ส่วนปลาย (Tail) ของ t-Distribution จะมีค่า Probability ที่สูงกว่า เมื่อเทียบจุดที่ห่างจากค่ากลางที่เท่ากัน แต่เมื่อ degree of freedom เข้าหา Infinite นั้น t-Distribution จะมีคุณสมบัติเข้าใกล้ Standard normal distribution เช่นกัน
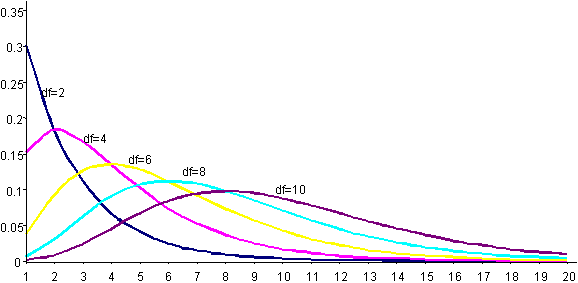
รูป t-Distribution เพื่อให้มองเห็นภาพ ผลของ degree of freedom และข้อแตกต่าง ของปลาย (Tail)
ดังนั้นเมื่อเราทำการศึกษาตัวอย่าง ค่าที่เราจำเป็นจะต้องรู้ จึงเป็นค่า t ไม่ใช่ Z อีกต่อไป เช่นเดียวกับ Z-Distribution จะมีตาราง T-Table สำหรับ t-Distribution เหมือนกัน เวลาเราเขียน ค่า t เราจึงจำเป็นต้องระบุ a และ degree of freedom ด้วยเสมอ โดยแทนด้วย ( k ) เช่น ta,k เนื่องจาก t-Distribution จะมีลักษณะสมมาตรรอบๆ ศูนย์ ( 0 ) ดังนั้น ค่า t1-a จึงเท่ากับ -ta t-Distribution ได้ถูกนำไปใช้เป็นเครื่องมือในการ ทดสอบสมมติฐาน ความแตกต่างของค่ากลางของตัวอย่าง ด้วย เราจึงเรียก วิธีที่เรานำไปใช้ดังกล่าวตามชื่อ t-Distribution ด้วยเช่นกันว่า t-test เป็นต้นว่า 1-Sample t-test หมายถึงการทดสอบค่ากลางของตัวอย่างเพียงกลุ่มเดียวกับค่าที่กำหนด หรือ 2-Sample t-test หมายถึง การทดสอบความแตกต่างของค่ากลาง ของตัวอย่างสองกลุ่ม Chi-square Distribution ไคสแคว์ (Chi-square) ถือได้ว่าเป็น Sampling distribution ที่ถูกนำไปประยุกต์ใช้ในการทดสอบสมมติฐานมากที่สุดอีกชนิดหนึ่ง พื้นฐานของ Chi-square มีสมการดังต่อไปนี้
เมื่อ xi คื่อค่าใดๆ โดยที่ i = 1,2,3...u และเป็นข้อมูลที่มีการกระจายแบบ Normal distribution และค่าแต่ละค่าต้องเป็นอิสระต่อกันด้วย ซึ่งจากสมการค่า Chi-square ก็เท่ากับ Z2 นั่นเอง ซึ่ง u หมายถึง Degree of freedom ของ Chi-square ดังนั้นจึงเป็นพารามิเตอร์ที่สำคัญของ Chi-square distribution ด้วย โดยที่ m = u และ s2 = 2u
แกน Y คือ ค่าฟังก์ชันของ X หรือ f(X) ส่วนในแกน X คือค่า Chi-square จากรูป แสดงให้เห็นถึงความสัมพันธ์กันระหว่าง Degree of freedom กับลักษณะของ Distribution แต่ลักษณะของ Chi-square distribution ที่สำคัญคือ กราฟจะต้องเบ้ขวาเสมอ แต่เมื่อใดก็ตามที่เพิ่มจำนวน Degree of freedom ความเบ้นี้จะลดลงเรื่อย และจะเข้าหา Normal distribution ในที่สุด ลักษณะพื้นที่ใต้กราฟของ Chi-square distribution จะถูกนำไปเป็นค่าทดสอบ สำหรับข้อมูลทางสถิติประเภทที่สามารถจัดเป็นหมวดหมู่ได้ (Attribute data ) และใช้ทดสอบค่าความแปรปรวนแบบประชากรเดี่ยว (One-variation test) ดังนั้นจึงจัดได้ว่า มีความจำเป็นที่เราจะต้องเข้าใจถึงคุณสมบัติของ Chi-square อย่างดี ก่อนนำไปใช้เป็นตัวทดสอบ
F-Distribution เป็น Sampling distribution อีกชนิดหนึ่งที่มีการประยุกต์ใช้ค่อนข้างมากในการทดสอบค่าความแปรปรวนแบบสองประชากร (Two-variation test) พื้นฐานของ F-Distribution คือเป็นสัดส่วนของค่าความผันแปรของสองข้อมูล โดยมีสมการพื้นฐานดังนี้
โดยที่ s1 > s2 เมื่อสมการพื้นฐานของ F-distribution เกิดจากประชากรสองตัว ดังนั้นตัวแปรที่สำคัญคือ Degree of freedom (u) จึงต้องคิดของทั้งสองประชากร ดังนั้น u1 = n1-1 และ u2 = n2-1
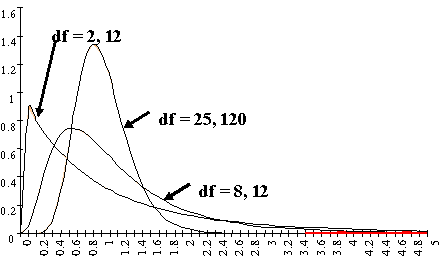
แกน Y คือ ค่าฟังก์ชันของ X หรือ f(X) ส่วนในแกน X คือค่า F จากกราฟลักษณะการกระจายตัวของ F จะเป็นกราฟเบ้ขวาตลอด ซึ่งเป็นลักษณะเดียวกันกับ Chi-square distribution และค่า Degree of freedom มีผลต่อลักษณะการกระจายตัว F
|