|
Regression Analysis ท่านผู้อ่านหลายท่านคงจะเคยได้อ่านคำแปลภาษาไทยของคำนี้ว่า "การวิเคราะห์การถดถอย" ถึงแม้คำแปลนี้จะเป็นที่รับรู้ในภาษาไทยมานานแล้ว แต่โดยส่วนตัวแล้วผมคิดว่าเป็นคำแปลที่ทำให้ผู้อ่านรู้สึกหดหู่พิกล แต่ผู้เขียนก็ไม่ได้บอกว่าคำที่ใช้ในปัจจุบันไม่ถูกต้อง และที่ถูกต้องควรจะใช้คำว่าอะไร เพียงแต่อยากให้ท่านผู้อ่านลองอ่านเนื้อหาเบื้องต้นดูก่อน แล้วจะทราบว่า คำว่า Regess นั้นที่ถูกแล้วภาษาไทยเราควรจะใช้คำว่า " ถดถอย" หรือไม่ ท่านผู้อ่านเคยมีคำถามในใจคล้ายๆกับคำถามต่อไปนี้บ้างหรือไม่ 1. เปิดเครื่องปรับอากาศ วันละ 5 ชั่วโมง เดือนนี้จ่ายค่าไฟ 560 บาท ถ้าอยากจ่ายเดือนละ 450 บาท หรือน้อยกว่าควรจะเปิดวันละกี่ชั่วโมง (อุปกรณ์อย่างอื่นใช้เหมือนปกติ) 2. ถ้าขับรถด้วยความเร็วเฉลี่ย 90 กิโลเมตรต่อชั่วโมง เติมน้ำมันเต็มถังจะวิ่งรถได้รวม 560 กิโลเมตร ถ้าขับที่ความเร็วเฉลี่ย 110 กิโลเมตรต่อชั่วโมง จะวิ่งได้กี่ กิโลเมตร แล้วถ้าเป็น 130 กิโลเมตรต่อชั่วโมง จะได้กี่กิโลเมตร ถ้าเติมน้ำมันเต็มถังเหมือนกัน 3. ถ้าตั้งอุณหภูมิหม้อต้มน้ำที่ 100 องศาเซลเซียส จะสามารถฆ่าเชื้อแบคทีเรียได้ ร้อยละ 85 ภายใน 1 นาที อยากทราบว่าถ้าต้องการให้ฆ่าได้ ร้อยละ 90 ในเวลาเท่าเดิม จะต้องใช้อุณหภูมิเท่าใด และถ้าต้องการให้ฆ่าได้ หมด ร้อยละร้อย จะต้องใช้อุณหภูมิ เท่าใด โจทย์ตัวอย่างทั้งสามข้อนั้น กำลังชี้ให้ท่านเห็นถึงความสัมพันธ์ ของตัวแปรสองตัว หากให้ท่านเลือกว่าจะใช้เครื่องมือทางคณิตศาสตร์อะไรในการแก้ปัญหาโจทย์ลักษณะนี้ ผมเชื่อว่าหลายท่านคงกำลังนึกถึง บัญญัติไตรยางศ์ ที่เราเคยเรียนมาตั้งแต่สมัยชั้นประถม ซึ่งผมกำลังจะบอกว่าท่านนึกถึงเฉยๆนะได้ แต่มาใช้กับโจทย์ในลักษณะนี้ไม่ได้นะครับ ผมมีเหตุผลที่จะบอกท่านอย่างนี้ครับ 1. บัญญัติไตรยางศ์ จะใช้ได้ก็ต่อเมื่อตัวแปรทั้งสอง เป็นตัวแปรที่ค่า ไม่มีความคลาดเคลื่อน เช่น ขนมกล่องนี้ราคา 10 บาท ถ้าซื้อ 10 กล่อง ต้องจ่าย 100 บาท ตัวแปรที่ว่าคือ ราคาต่อกล่องก็คงที่ คือ 10 บาท ตัวแปรอีกตัวคือจำนวนที่จะซื้อ คือ 10 กล่อง ก็ไม่มีความคลาดเคลื่อนเลย 2. โจทย์หรือคำถามสามข้อที่ผมกล่าวถึง ที่ผ่านมานั้น ท่านลองสังเกตดีๆ จะเห็นว่า ถึงจะเป็นโจทย์ที่กล่าวถึงความสัมพันธ์กันของสองตัวแปร แต่จะมีเพียงหนึ่งตัวแปรเท่านั้นที่จะไม่มีความคลาดเคลื่อนเลย แต่อีกตัวแปรที่เหลือนั้น โดยธรรมชาติของมันจะมีค่าคลาดเคลื่อนตลอดเวลา ไม่มากก็น้อย เช่น ตั้งอุณหภูมิ 100 องศา แล้วฆ่าเชื้อแบคทีเรียได้ ร้อยละ 85 ถ้าทำการทดลองอีกที ภายใต้สถานการณ์เหมือนเดิมแท้ๆ อาจจะฆ่าได้ถึงร้อยละ 87 ทำซ้ำอีกรอบเหมือนเดิม อาจจะฆ่าได้เพียงร้อยละ 83 ไม่ใช่ทดลองไม่ดี แต่นี่เป็นความคลาดเคลื่อนที่เป็นธรรมชาติ เป็นเหตุสุดวิสัยที่จะไปควบคุมให้ได้ค่าเดิมทุกครั้งได้ (ถ้าใครทำได้แปลว่าท่านต้องทำอะไรสักอย่างไม่ดีแน่ๆ) ด้วยเหตุผล 2 ข้อดังกล่าว การวิเคราะห์ถึงความสัมพันธ์ของตัวแปรสองฝั่งจึงต้องใช้เทคนิคทางคณิตศาสตร์ที่พิเศษกว่าบัญญัติไตรยางศ์ ซึ่งก็คือ " Regression Analysis " และแทนที่เราจะเรียกว่าการวิเคราะห์หาความสัมพันธ์ เราก็จะเรียกว่า การประมาณการ (Prediction) แทน เมื่อเป็นเช่นนี้ ตัวแปรฝั่งที่ไม่มีค่าคลาดเคลื่อน เราจะเรียกว่าตัวประมาณการ (Predictor) โดยใช้ สัญลักษณ์แทนคือ X ตัวแปรที่มีความคลาดเคลื่อน เราก็จะเรียกว่า ตัวตอบสนอง (Response) สัญลักษณ์แทนคือ Y โดยที่ Y = F(X) ผลการวิเคราะห์ที่ได้ เราจะได้สมการหรือฟังก์ชันคณิตศาสตร์ที่แสดงถึงความสัมพันธ์กันของทั้งสองตัวแปร เช่น % Bacteria killed (Y) = 67.45 + 0.214* Temperature(X) ความสัมพันธ์ที่เขียนแทนด้วยฟังก์ชันคณิตศาสตร์ดังกล่าวเราจะเรียกว่า Model หรือ Mathematical Model และฟังก์ชันคณิตศาสตร์ที่ได้ จะสามารถนำไปประมาณการ ตัวแปรฝั่งที่มีค่าคลาดเคลื่อนได้ โดยใช้ค่าของตัวแปรฝั่งที่มีค่าไม่คลาดเคลื่อน แปลว่าเมื่อเรารู้ค่าตัวแปรที่ค่าไม่คลาดเคลื่อน และรู้ฟังก์ชั่นคณิตศาสตร์แสดงความสัมพันธ์ แล้วเราก็สามารถรู้ค่าตัวแปรฝั่งที่มีค่าคลาดเคลื่อนได้ Mathematical Model ดังกล่าวจึงเรียกว่า Transfer function ในที่สุด มาถึงตรงนี้ท่านผู้อ่านอย่าสับสนนะครับ โปรดจำไว้ว่า ไม่จำเป็นที่ Mathematical Model ทุกอันต้องเป็น Transfer function เฉพาะที่เกี่ยวข้องกับสองตัวแปรหรือมากกว่าขึ้นไปที่สามารถอธิบายความสัมพันธ์ในลักษณะใช้ฝั่งหนึ่งประมาณการ อีกฝั่งหนึ่งได้เท่านั้นจึงจะเรียกว่า Transfer function ในการศึกษา ถึงความสัมพันธ์ของตัวแปรสองฝั่งโดยใช้ Regression analysis นั้นสามารถที่จะใช้ได้กับหลายลักษณะความสัมพันธ์ และปริมาณตัวแปร เช่น 1. Simple linear regression analysis : ชื่อก็บ่งบอกว่าใช้ได้เมื่อใด ก็คือจะใช้เมื่อเราต้องการวิเคราะห์ความสัมพันธ์ระหว่าง สองตัวแปร และความสัมพันธ์ระหว่างสองตัวแปรดังกล่าวจะต้องเป็นในลักษณะเชิงเส้น ดังตัวอย่างง่ายๆ % Bacteria killed (Y) = 67.45 + 0.214* Temperature(X) 2. Multiple linear regression analysis : จะใช้เมื่อเราต้องการวิเคราะห์ความสัมพันธ์ เมื่อมีตัวแปรที่เป็น Predictor มากกว่า 1 ตัวขึ้นไป แต่ความสัมพันธ์ของตัวแปรทั้งสองฝั่ง ยังคงเป็นแบบเชิงเส้นตรง ยกตัวอย่าง ในกรณีคำถามที่ 3 ที่ผ่านมานั้น นอกจากอุณหภูมิจะมีผลต่อจำนวนเชื้อแบคทีเรียที่ถูกฆ่าแล้ว เวลาที่แช่ภาชนะเพาะเชื้อแบคทีเรียในน้ำรอน ก็เป็นตัวแปร ที่มีผลด้วยเช่นกัน เพราะถ้าอุณหภูมิเท่าเดิม การใช้เวลา 1 นาที กับ 2 นาทีสามารถฆ่าเชื้อแบคที่เรียได้จำนวนแตกต่างกัน ด้วย สมมติว่าความสัมพันธ์เป็นเชิงเสิ้นตรง ตัวอย่าง Mathemical model จะเป็นดังนี้ % Bacteria killed (Y ) = 36.415 + 0.412* Temperature(X1 ) + 4.85*Time( X2 ) 3. Polynomial regrssion analysis : จะใช้เมื่อเราต้องการวิเคราะห์ถึงความสัมพันธ์ที่ไม่เป็นเชิงเส้นตรง รวมถึงกรณีมีตัวแปร Predictor มากกว่า 1 ด้วย ยกตัวอย่างเช่น ถ้ากรณีเปิดเครื่องปรับอากาศนั้น นอกจากจำนวนชั่วโมงที่เปิดจะมีผลต่อจำนวนหน่วยไฟฟ้าที่ใช้แล้ว อุณหภูมินอกห้อง ก็ส่งผลด้วยเหมือนกันและไม่เป็นเส้นตรงด้วย การวิเคราะห์ก็จะยิ่งซับซ้อน และยุ่งยากมากขึ้นไปอีก Mathemical Model จะเป็นดังตัวอย่างต่อไปนี้ Power consumtion (Unit) = 1.542 + 0.859 * Time + 0.587*( External Temperature )2 ในเมื่อลักษณะความสัมพันธ์ของตัวแปร มีทั้งแบบเชิงเส้นและแบบไม่เชิงเส้น (Polynomial) หลายท่านอาจจะสงสัยว่า เราจะรู้ได้อย่างไรว่าความสัมพันธ์ของตัวแปรเป็นเชิงเส้นหรือ ไม่เป็นเชิงเส้น คำตอบคือท่านจะต้องใช้การทำ Scatter plot เข้าช่วยอย่างหลีกเลี่ยงไม่ได้ ดังนั้นการวิเคราะห์ความสัมพันธ์โดยใช้ Regression analysis ท่านจำเป็นต้องทำกราฟแสดงจุดตัดของตัวแปรทั้งสองฝั่งให้ได้ และ Scatter plot คือเทคนิคที่ช่วยท่านได้ดีทีเดียว ให้ท่านผู้อ่านย้อนกลับไปอ่านการทำ Scatter plot โดยใช้ MS Excel เพื่อความเข้าใจ 4. Logistic regression analysis กรณีที่ Y มีค่าเพียงสองสถานะ เช่น No ,Yes เป็นต้น แต่ X เป็นค่าแบบต่อเนื่องปกติ
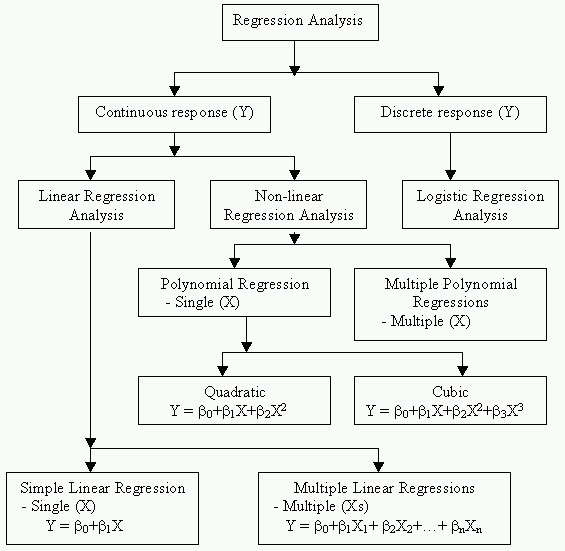
ภาพโดยรวมของการวิเคราะห์ข้อมูลโดย Regression Analysis Regression Analysis ถือเป็นเครื่องมือทางสถิติที่มีการประยุกต์ใช้ในการประมวลผลข้อมูลในงานวิจัยค่อนข้างมาก นักสถิติยุคก่อนได้คิดค้นทฤษฎีเกี่ยวกับ Regression เอาไว้มากมาย ภาพต่อไปนี้แสดงให้เห็นว่าท่านควรจะเลือกใช้เครื่องมือวิเคราะห์แบบใด ถึงจะเหมาะและตรงกับข้อมูลที่ท่านมีอยู่
ภาพ แสดงการจัดแบ่ง Regression Analysis ตามชนิดของข้อมูลที่ต้องการจะวิเคราะห์
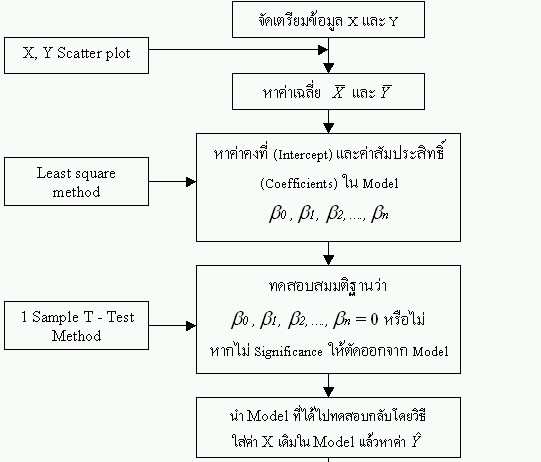
ลำดับขั้นตอนของการวิเคราะห์ข้อมูลโดย Regression Analysis เมื่อท่านตัดสินใจแล้วว่า จะต้องใช้ Regression Analysis ในการวิเคราะห์ข้อมูลของท่านแล้ว ขั้นตอนและลำดับการวิเคราะห์จะเป็นดังแผนภาพต่อไปนี้ (เหมาะกับ Simple linear regression และ Multiple linear regression ที่ผู้เขียนคิดว่า ผู้อ่านหรือผู้ที่จะทำการวิเคราะห์ข้อมูล จะเลือกใช้มากกว่า วิธีอื่นๆ )
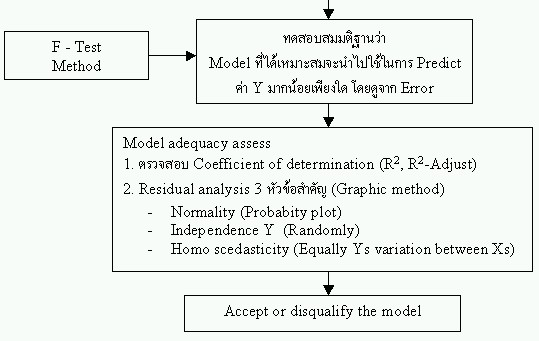
ภาพ แสดงลำดับการวิเคราะห์ข้อมูลโดยใช้ Regression Analysis การทดสอบนัยสำคัญทางสถิติ (Statistical significance) 1. T-Statisitic เมื่อเราได้ Model มาแล้วจะต้องพิสูจน์ทางสถิติ ค่าคงที่ (b0)และสัมประสิทธิ์ของตัวแปรอิสระทุกค่า (b1,b2,....,bn) ว่ามีนัยสำคัญต่อ Model หรือไม่ โดยตั้งสมมติฐาน ถ้าเราต้อง Accept H0 โดยดูจากค่า T ที่คำนวณได้ถ้าน้อยกว่าค่า T-critical ก็แปลว่า ค่าคงที่หรือสัมประสิทธิ์ของตัวแปรอิสระตัวนั้นๆไม่มีนัยสำคัญต่อ Model ก็ตัดออกได้ โดยจะไม่ทำให้ Model นั้นเกิดความแตกต่างแต่อย่างใด ในทางตรงกันข้ามเราต้อง Reject H0 เมื่อ T ที่คำนวณได้มากกว่า T-critical ก็แปลว่าค่าคงที่หรือสัมประสิทธิ์ของตัวแปรอิสระตัวนั้นๆมีนัยสำคัญต่อ Model ไม่สามารถตัดออกได้ นี่เองที่ทำให้ Regression analysis ต้องมี T-test หรือมีค่า t ปรากฏในตารางผลการวิเคราะห์ 2. F-Statistic
สุดท้ายเราได้ Model
ที่ถือว่าดีที่สุดเท่าที่จะหาได้
แต่ก็ใช่ว่า Model
ดังกล่าวจะใช้ในการ Predict ค่า Y
ได้ถูกต้อง
เราจำเป็นต้องพิสูจน์ทราบว่า
Model ที่ได้นั้นเมื่อนำไป Predict
ค่า Y
แล้วจะมีความคลาดเคลื่อนมากแค่ไหน
หรือก็คือ มี Error ระหว่าง Y และ
H0: Error ที่เกิดขึ้นที่ (Y) เกือบทั้งหมดมาจากตัวแปรอิสระ Ha: Error ที่เกิดขึ้นที่ (Y) ส่วนน้อยเท่านั้นที่มาจากตัวแปรอิสระ หากผลการทดสอบด้วย F-Test พบว่า Accept Ho หรือ F-Statistic ที่ได้มีค่าต่ำกว่าค่า F-critical ก็ให้ถือว่า Model นั้นมีความผิดพลาดสูง จนไม่อาจยอมรับให้นำไปใช้ต่อไปได้ ก็ถือว่าอย่างอื่นก็ไม่ต้องวิเคราะห์ต่อ ในทางตรงกันข้ามหากผลการทดสอบด้วย F-Test พบว่า Reject Ho หรือ F-Statistic ที่ได้มีค่ามากกว่าค่า F-critical ก็ให้ถือว่า Model นั้น เมื่อนำไป Predict ค่า Y แล้วมีความผิดพลาดน้อยสามารถยอมรับได้ จึงเป็นเหตุให้ Regression analysis ต้องมี ANOVA เพราะใน ANOVA มี F-Test อยู่นั่นเอง 3. Coefficient of determination ใช้พี่สูจน์ว่า Model ที่ได้นั้นมีที่มาที่ดีพอจะใช้ Model จากผลการวิเคราะห์ ไป Prdedict ค่า Y ในอนาคตได้หรือไม่ แม้ว่า F-Test จะบอกว่า Model มีความผิดพลาดต่ำแค่ไหนก็ตาม แต่หากที่มาของการเก็บข้อมูลก่อนการวิเคราะห์ ไม่เหมาะสม ก็ยังถือว่า Model นั้นที่ดีได้เพราะเหตุบังเอิญ - R2 เป็นค่าที่บ่งบอกว่าข้อมูลดิบของการวิเคราะห์นั้น เหมาะสมหรือไม่ จะมีค่าระหว่าง 0 - 1 ยิ่งเข้าใกล้ 1 ก็ยิ่งดี โดยทั่วไปควรมีค่า 0.6 ขึ้นไป แต่ก็ไม่ได้มีกฏเกณฑ์แน่นอนตายตัว - R2-Adjust เป็นค่าที่บ่งบอกว่า R2 ที่ได้นั้นเหมาะสมจริงไหม โดยจะทำการลด Sample (N) ลง 1 ตัว แล้วหาค่า R2 ใหม่อีกครั้ง เลยเรียกว่า Adjust หากมีค่าต่ำกว่า R2 มากผิดปกติ ก็ให้สรุปว่า Sample size ต่ำเกินไป หรือ R2 มี Sensitivity ต่อการเปลี่ยนแปลง N มากเกินไป มีโอกาสที่ Model จะผิดพลาดก็สูงทีเดียว ที่เหมาะสม ค่า R2-Adjust จะต้องต่ำกว่า R2 เพียงเล็กน้อยเท่านั้น จึงจะถือว่าการทดลองครั้งนี้ เก็บข้อมูลมาดี Sample size เหมาะสม หากท่านกำลังใช้ Regression analysis แล้ว ค่า R2 และ R2-Adjust นี้สามารถจะทำให้ Model ที่ได้นั้น ไม่อาจจะยอมรับให้ใช้ได้ ต้องกลับไปดำเนินการเก็บข้อมูลเพิ่มและเริ่มทำารวิเคราะห์ใหม่อีกครั้งหนึ่ง แม้ว่า F-test จะปรากฏผลว่า Model นั้นมีค่าความคลาดเคลื่อนต่ำก็ตาม ท่านผู้อ่านอาจจะสงสัยว่าทำไมต้อง Proof หลายชั้นเหลือเกิน จริงครับ การวิเคราะห์ไม่ใช่เรื่องยากแต่การจะ Proof ว่าผลการวิเคราะห์นั้น ใช้ได้ไหม นี่เป็นเรื่องยากกว่าเยอะ เนื้อหาเฉพาะของ Regression analysis จะนำเสนอในหัวข้อต่อไป
|