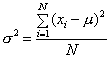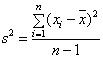|
ประชากรและตัวอย่าง (Population & Sample ) การศึกษาวิชาสถิติ (Statistics ) จำเป็นอย่างมากที่ผู้ศึกษาจะต้องเข้าใจ คำว่าประชากร และตัวอย่าง อย่างถ่องแท้เสียก่อน ในบทนี้จะขอกล่าวถึงสอง เรื่องนี้ เพื่อแสดงให้เห็นถึงความ เหมือน หรือ ความแตกต่างกัน ของประชากรและตัวอย่าง เพื่อเป็นพื้นฐานความเข้าใจสำหรับหัวข้ออื่นๆด้วย ประชากร (Population) ในที่นี้คำว่าประชากร ไม่ได้หมายถึง คนหรือประชาชน แต่หมายถึงสิ่งที่เราสนใจอยากรู้ข้อมูล เช่น. ส่วนสูงของคน คำว่าประชากรก็คือ ค่าส่วนสูงของคนหลายคนมากๆ ถ้าเป็นอุณหภูมิ คำว่าประชากรก็จะหมายถึงค่าที่ได้จากการวัดหลายๆครั้ง ในในช่วงเวลานานๆ เป็นต้น ถ้าในทางวิชาสถิติ สิ่งสำคัญที่สุดหรือเป้าหมายของคนที่ใช้ความรู้ทางสถิติก็คือ ต้องการทราบหรืออธิบายถึงคุณสมบัติ ต่างๆ ของประชากร แต่เนื่องจาก ในชีวิตจริงๆ ผู้ที่ใช้วิชาสถิติ ไม่มีวันที่จะเก็บข้อมูลของประชากรทั้งหมดได้หรอก ถ้าจะอธิบายคำว่าประชากรให้ได้ถูกต้องมากที่สุด ก็คงจะเป็นดังต่อไปนี้มีจำนวนมากจนไม่อาจจะเก็บข้อมูลได้หมด แน่นอนว่า หากเราสามารถเก็บข้อมูลได้หมด นั่นแปลว่าเราสามารถอธิบายประชากรได้ถูกต้อง 100% เช่น. การศึกษาเรื่องน้ำหนักแรกเกิดของทารกในประเทศไทย คำว่าประชากรในการศึกษาครั้งนี้ก็คือน้ำหนักของทารกแรกเกิดทุกคนในประเทศไทย แน่นอนว่าจะต้องไม่มีที่สิ้นสุด เพราะจะมีทารกแรกเกิด เกิดขึ้นทุกวันๆ อีกอย่างก็คือ เป็นไปไม่ได้ที่ผู้ทำการศึกษาจะสามารถเก็บรวบรวม ค่าน้ำหนักทารกแรกเกิดใหม่ ได้ทุกคน จะต้องมีข้อจำกัดมากมาย ทั้งต้นทุนในการดำเนินการ เวลา และทรัพยากรอื่นๆ หรือถ้ายกตัวอย่างในงานทางอุตสาหกรรม วิศวกรต้องการศึกษาเรื่องน้ำหนักบรรจุหนึ่งถุงของปูนซิเมนต์ คำว่าประชากรก็คือน้ำหนักบรรจุปูนซิเมนต์ทุกถุง ทั้งที่อยู่ในโกดังเก็บ ทั้งที่ส่งไปหาลูกค้าแล้ว ทั้งที่กำลังอยู่ในสายการผลิต จะเห็นได้ว่า ไม่มีวันที่วิศวกรจะเก็บข้อมูลได้ทุกถุงหรอก แต่ก็มีงานบางอย่างที่จำเป็นต้องเก็บข้อมูลของประชากรทั้งหมด เช่น. งานสัมมโนประชากร ซึ่งเป็นเรื่องที่ภาครัฐจำเป็นต้องมีข้อมูลของคนทุกคนในประเทศ แต่จะเห็นได้ว่ารัฐต้องใช้ บุคคลากร อุปกรณ์ เครื่องมือ เงิน รวมถึงทรัพยากร ต่างๆไปอย่างมากมายกว่าจะทำได้ ตัวอย่าง (Sample) เมื่อเราไม่อาจจะเก็บข้อมูลของประชากรทุกตัวได้ เราจึงมีวิธีที่จะเก็บเอาเพียงบางตัว บางส่วน บางช่วงเวลา ของประชากร เพื่อมาทำการวิเคราะห์ แล้วนำผลที่ได้กลับไปประมาณหรืออธิบายถึงประชากร อีกที สมาชิกของประชากรที่เราเก็บค่ามาดังกล่าวเรียกว่าตัวอย่าง แน่นอนว่าเมื่อเราทำการศึกษาผ่านตัวอย่างย่อมให้ผลลัพธ์ ที่ผิดพลาดไปจากค่าที่แท้จริงของประชากรบ้าง เราจึงต้องคำนึงถึง ระดับความเชื่อมั่นที่เราจะสามารถยอมรับความผิดพลาดดังกล่าว มีองค์ประ กอบหลายประการที่เกี่ยวข้องกับระดับความเชื่อมั่น เช่น. วิธีการเก็บตัวอย่างจากประชากร จำนวนตัวอย่างที่เก็บค่ามา แม้แต่เครื่องมือทางสถิติที่เราเลือกใช้ในการวิเคราะห์ เป็นต้น ดังนั้นจึงมีความจำเป็นที่จะ ต้องมีแบบแผนอย่างถูกต้องด้วยในการที่จะเก็บตัวอย่าง ที่ผู้ทำการศึกษาควรให้ความสนใจ ข้อเปรียบเทียบทางสถิติระหว่างประชากรและกลุ่มตัวอย่าง
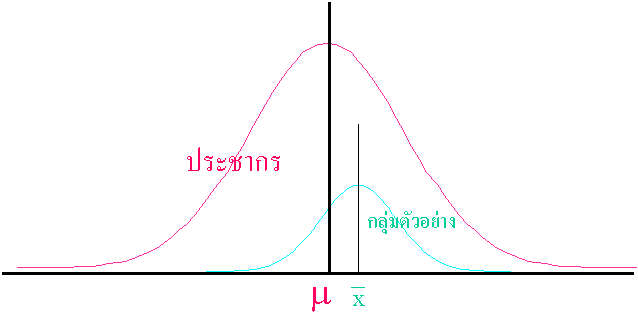
จากรูปข้างบนเป็นภาพอธิบายเปรียบเทียบ การกระจายของข้อมูลของประชากรและของกลุ่มตัวอย่าง เพื่อให้เห็นว่ากลุ่มตัวอย่าง จะมีความใกล้เคียงกับประชากร มาก ภายใต้เงื่อนไข การเก็บตัวอย่างที่ถูกต้อง สิ่งที่ใช้อธิบายประชากรเราจะเรียกว่า Population Parameter ส่วน ของกลุ่มตัวอย่างเราจะเรียกว่า Sample Statistics
ตัวประมาณการและค่าประมาณการ (Estimator and Estimated value ) เนื่องจากในความเป็นจริงทางวิชาสถิติเรามิอาจจะรู้ค่า Population Parameter ได้เลย สิ่งที่เราสามารถรู้ได้ก็คือ Sample Statistics เท่านั้น แต่เนื่องจาก ท้ายที่สุดแล้วเราต้องการรู้ Population parameter ต่างหาก เราจึงใช้ Sample Statistics มาประมาณค่า Population parameter เราจึงเรียก x ว่าตัวประมาณค่ากลาง (m ) ของประชากร ( Population mean estimator) นั่นหมายความว่า ค่าเฉลี่ยของตัวอย่าง ก็เป็นค่าโดยประมาณของค่ากลางของประชากร และเราเรียก s ว่าตัวประมาณการค่าเบี่ยงเบนมาตรฐาน (s) ของประชากร (Population standard deviation estimator ) นั่นหมายความ ค่าเบี่ยงเบนมาตรฐานของตัวอย่าง ก็เป็นค่าโดยประมาณของค่าเบี่ยงเบนมาตรฐาน ของประชากรด้วยเช่นกัน
ระดับองศาอิสระของข้อมูล (Degree of freedom ) แนวคิดเรื่อง Degree of freedom นี้มีหลากหลายแนวคิดมาก ผู้เขียนจำได้ว่า ในตอนที่เรียนวิชาสถิติในมหาวิทยาลัยนั้น คำอธิบายเกี่ยวกับคำๆ นี้ก็เป็นสิ่งที่ยังค้างคาใจอยู่มา จนปัจจุบันนี้ แต่เมื่อได้มีโอกาสกลับมาใช้วิชาสถิติประยุกต์ ในการทำงานแล้ว จึงเริ่มพอจะมีความเข้าใจมากขึ้น ที่ผู้เขียนเองอยากจะเสนอ แนวคิด ซึ่งอาจจะทำให้ท่านมีข้อโต้แย้งได้ และผู้เขียนมีความยินดีอย่างยิ่งที่รับฟัง โดยผู้เขียนจะขอนำเสนอแนวคิดดังต่อไปนี้1. Degree of freedom คือค่าที่ใช้เพื่อชดเชย ความผิดพลาดของตัวอย่าง (Sample) เมื่อนำมาคำนวนหาค่าสถิติ คือค่าการกระจายของข้อมูล (Standard deviation) เนื่องจากในความเป็นจริงแล้ว ค่าดังกล่าวนี้ จะเล็กกว่าค่า Population Parameter เสมอ เนื่องจากโดยส่วนมากแล้ว เรามิอาจหาตัวแทนของประชากรได้ ตรง 100% เมื่อเป็นดังนี้ เมื่อเรานำไปประมาณค่า Population Parameter เราก็จะได้ค่า Population Standard Deviation ที่เล็กกว่าความเป็นจริงเสมอ เพื่อแก้ไขข้อผิดพลาดดังกล่าว เราจึงลดตัวหาร ลง หนึ่งตัว เพื่อชดเชยปรากฎการณ์ดังกล่าว ดังนั้นสมการในการหาค่า Sample Standard Deviation ตัวหารหรือ Degree of freedom จึงเท่ากับจำนวนตัวอย่างลบด้วย 1 เสมอ แต่ถ้าหากว่าเรามิได้มีจุด ประสงค์จะนำค่า s ไปประมาณค่า (s) หรือพูดง่ายๆคือเราแค่อยากอธิบายข้อมูลของตัวอย่างที่เก็บมาเท่านั้นไม่ได้เอาไปคาดการณ์ค่า Population Parameter เราก็ไม่จำเป็น ต้องลดตัวหารลงแต่อย่างใด 2. เนื่องจากเราต้องการเอาค่า Sample Statistics ไปประมาณค่า Population parameter เราจึงใช้ x ประมาณค่ากลาง ( m ) ของประชากร เพราะเรามิอาจจะรู้ค่า (m ) ที่แท้จริงได้ และโดยธรรมชาติแล้วค่า x ใดๆ ที่เราเก็บมาจากการสุ่มตัวอย่างนั้น จะมีแนวโน้มเข้าหาค่า x ไม่ใช่เข้าหาค่า ( m ) เมื่อเราหาค่าเบี่ยงเบนมาตรฐาน Standard Deviation โดยยึดค่า x จึงทำให้ค่าที่ได้มานั้นผิดพลาดไปจากที่ควรจะเป็น เราจึงจำเป็นต้องชดเชยค่า s ให้เข้าใกล้ ( s ) ให้มากที่สุด ตัวหารในสมการจึงถูกลดลงไป หนึ่งตัวเสมอ 3. เมื่อไหร่ก็ตามที่มีการวิเคราะห์ หรือกระทำการทางคณิตศาสตร์ ระหว่างข้อมูลของ Sample สองกลุ่มหรือมากกว่า Degree of freedom ของแต่ละ Sample ก็ต้องถูกลดลง 1 เหมือนกัน อันส่งผลให้ Degree of freedom รวม จะลดลงมากกว่า 1 ตัว
|