|
การทดสอบความเป็นการกระจายแบบปกติ ( Normality Test ) เมื่อมีการสุ่มตัวอย่างจำนวนหนึ่งออกมาจากประชากรแม่ที่มีการกระจายแบบปกติ (Normal Distribution) โดยปกติกลุ่มตัวอย่างดังกล่าวก็จะมีการกระจายเป็นแบบปกติ ตามประชากรแม่ด้วยเช่นกัน แต่นั่นก็ไม่ใช่กฏตายตัว เป็นไปได้ที่ตัวอย่างที่สุ่มออกมาจะมีการกระจายตัวไม่เป็นแบบปกติ (Non-normal distribution ) ซึ่งนั่นก็ไม่ใช่ประเด็นปัญหาหากว่าเราไม่ได้นำข้อมูลไปทำการอนุมานกลับไปหาประชากรแม่อีกที เมื่อใดก็ตามที่ต้องการนำข้อมูลของสิ่งตัวอย่างไปทำการอนุมานถึงประชากรแม่ เราจะต้องแน่ใจว่าข้อมูลดังกล่าว มีการกระจายตัวเป็นแบบปกติเสมอ หากไม่เช่นนั่นการทดสอบสมมติฐาน หรือการอนุมาน ด้วยเครื่องมือทางสถิติ อื่นๆ ก็จะให้ผลคลาดเคลื่อน ตั้งแต่น้อย จนถึงไม่อาจยอมรับได้ ขึ้นอยู่กับลักษณะความไม่เป็นการกระจายแบบปกติ เมื่อเป็นเช่นนี้การทดสอบว่าข้อมูลของสิ่งตัวอย่างที่ได้มานั้นมีการกระจายแบบปกติหรือไม่ จึงเป็นสิ่งที่ไม่อาจหลีกเลี่ยงได้ การทดสอบความเป็นการกระจายแบบปกติมีหลายวิธีได้แก่ Normal Quantile Plot คือการพล้อตจุดตัดระหว่างค่า Z quantiles กับข้อมูลใดๆ ที่เก็บตัวอย่างมา โดยสมมุติฐานคือ ข้อมูลที่เก็บมาจากประชากรที่มีการกระจายเป็นแบบ Normal distribution ก็น่าที่จะ ได้การกระจายของค่าตัวอย่างเป็น Normal distribution ด้วยเช่นกัน หากเป็นตามสมมุติฐานดังกล่าว กราฟความสัมพันธ์ระหว่าง ค่าตัวอย่างกับค่า Z จะใกล้เคียงเส้นตรง ที่มีความชัน (Slope) เท่ากับ s และจุดตัดบนแกน Y (Intercept) จะเท่ากับ m นั่นแปลว่าจุดตัดของแนวเส้นบนแกน Y คือค่าเฉลี่ยของค่าตัวอย่างนั้นด้วย สมมุติว่า i = 1, 2 ......n เป็นค่าอันดับของข้อมูล หลังจากเรียงลำดับค่าจากน้อยไปมากแล้ว ค่า quantiles ของข้อมูลหาได้จากสมการ ( i - 0.5 ) / n ขั้นตอนการทำ Normal quantile plot 1. เรียงอันดับข้อมูลที่มีอยู่จากน้อยไปหามาก (Sort the data) 2. คำนวณหาค่า Sample quantiles จากสมการ ( i - 0.5 ) / n 3. ค่า Sample quantile ที่ได้ตามข้อ 2 นี้คือ ค่าพื้นที่ใต้กราฟของ Z-Distribution หรือ Standard Normal Distribution นั่นเอง นำค่า Sample quantiles ดังกล่าวไปหาค่า Z โดยสามารถใช้ Z-Table หรือ หาโดยใช้โปรแกรมคอมพิวเตอร์ที่ใช้งานเกี่ยวกับสถิติ โดยเลือกโหมด Inverse Cumulative Probability ซึ่งจะได้ค่าต่างๆดังตารางต่อไปนี้ (ตัวอย่าง)
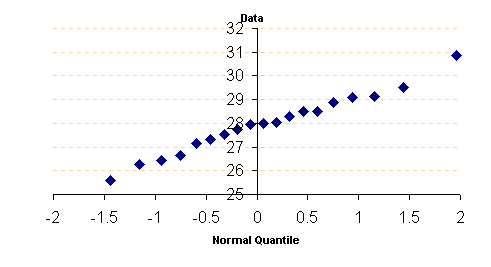
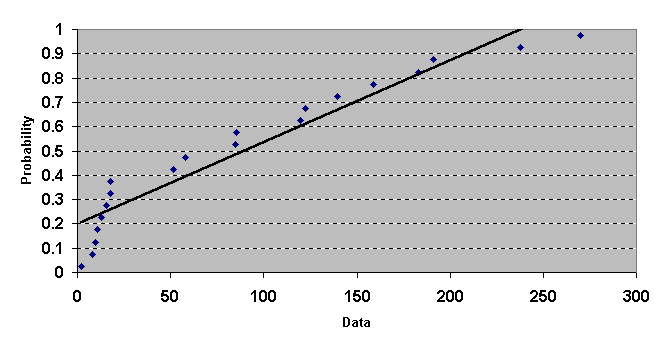
4. ใช้ Scatter plot เพื่อแสดงจุดตัด ของค่า Data (แกน Y) กับ Z percentiles (แกน X) จะได้ดังนี้
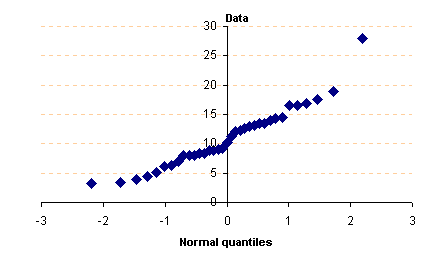
จากกราฟ ลักษณะการเรียงตัวของจุดตัดเป็นเส้นตรง แสดงว่าข้อมูล (Data) เป็น Normal distribution การทดสอบข้อมูลตัวอย่างที่เก็บมาจากประชากรว่า มีการกระจายเป็นแบบ Normal distribution หรือไม่ นับว่ามีความสำคัญเป็นอย่างยิ่ง ด้วยเพราะถ้าข้อมูลไม่เป็น Normal distribution แล้ว เราไม่สามารถ ใช้ค่า s และ m ในการวิเคราะห์ทางคณิตศาสตร์ได้ เพราะถือว่าผิดข้อกำหนดของ Normal Distribution กรณีที่ข้อมูลตัวอย่างไม่เป็น Normal distribution ลักษณะของกราฟที่ได้จะเป็นดังตัวอย่างต่อไปนี้ โดยมีข้อสังเกตคือ แนวของจุดตัดจะไม่เป็นเส้นตรง นั่นเอง
Probability Plot เป็นวิธีที่คล้ายกับ Normal Quantile Plot ต่างกันคือไม่มีการ Plot เปรียบเทียบกับค่า Z มีขั้นตอนการทำดังนี้ 1. เมื่อได้ข้อมูลมาจะต้องทำการเรียงลำดับของค่าข้อมูลจากน้อยไปหามาก 2. ใส่หมายเลขกำกับ ( Rank : i ) ตั้งแต่ 1,2,3......n 3. คำนวณหาค่า Probability ตามสูตร p= (i-0.5)/n ดังตารางตัวอย่างต่อไปนี้
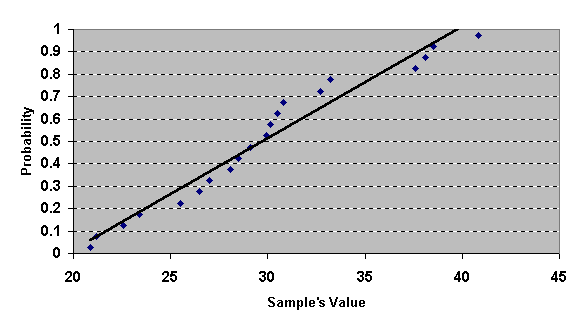
4. ใช้ Scatter Plot เพื่อทำการ Plot จุดตัดระหว่าง Probability และ Data ที่ได้เรียงอันดับเรียบร้อยแล้ว โดยให้แสดงเส้นตรงด้วย
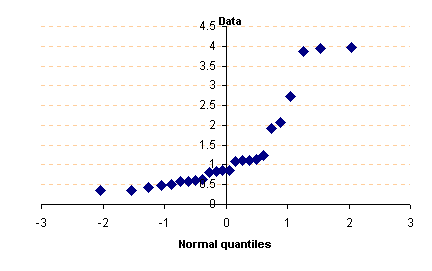
5. แปลความหมาย โดยมีหลักว่า ถ้า Data มีการกระจายแบบปกติ ( Normal Distribution ) แล้ว จุดตัดจะเรียงตัวกันเป็นแนวเส้นตรง และลักษณะการเกิดจุดจะต้องไม่กระจุกเป็นกลุ่มๆ และความห่างระหว่างจุดแต่ละจุดต้องใกล้เคียงกันเป็นส่วนใหญ่ แต่แน่นอนว่าค่าจะมีการอยู่ห่างจากเส้น มากน้อย แตกต่างกันไปบ้าง แล้วเท่าไหร่ถึงจะถือว่าไม่สามารถยอมรับได้ว่าเป็นการกระจายแบบปกติ ก็ให้ทำการประมาณการตามสมควร อย่างในตัวอย่างข้างบนนี้ ก็พอจะประมาณว่าเป็นการกระจายแบบ Normal distribution ได้ ตัวอย่างผลที่ได้เมื่อ Data ไม่เป็นการกระจายแบบปกติ
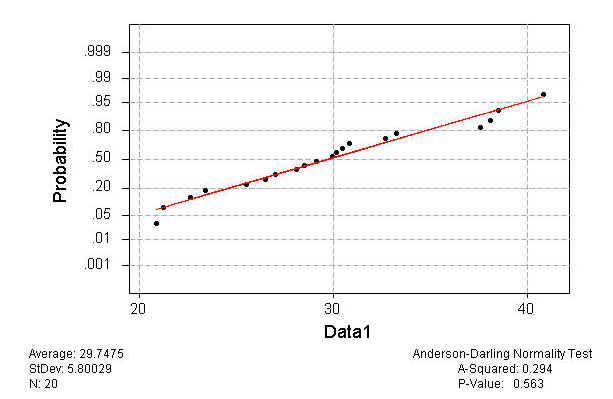
จะเห็นได้ว่า วิธีการทดสอบ Normality ที่แสดงผลโดยใช้ Scatter สามารถช่วยให้เราตัดสินใจได้ว่า Data ที่เราเก็บตัวอย่างมี จะมีการกระจายแบบปกติหรือไม่ เราเรียกการตัดสินใจด้วยผลแสดงด้วยกราฟว่า เชิงคุณภาพ ( Qualitative ) ซึ่งก็ให้ผลที่ถูกต้องได้เช่นกัน แต่บางครั้งการตัดสินใจต้องการความแม่นยำ เราจำเป็นต้องเห็นข้อมูลเชิงปริมาณ ช่วยในการตัดสินใจ เราจำเป็นต้องใช้โปรแกรมที่ออกแบบมาใช้สำหรับการวิเคราะห์ทางสถิติโดยตรง ดังตัวอย่างที่ผ่านมา หากใช้โปรแกรม Minitab จะให้ผลดังนี้
โปรแกรม Minitab จะให้ค่า P-Value ซึ่งเป็นการสรุปผลการทดสอบสมมติฐานที่ว่า H0 : Data is normal distributed. Ha : Data isn't normal distributed. ถ้าเรายอมรับความผิดพลาดที่ 5 % (a=0.05) เมื่อ P-Value >a เราจึงยอมรับสมมติฐาน H0: Data is normal distributed.
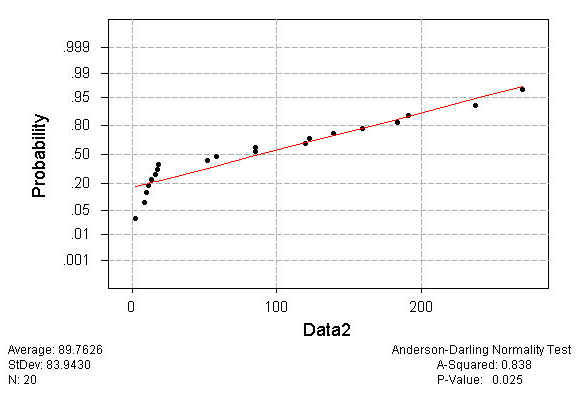
ใช้โปรแกรม Minitab กับ ข้อมูลที่สองตามตัวอย่างข้างบน จะได้ดังนี้
ถ้าเรายอมรับความผิดพลาดที่ 5 % (a=0.05) เมื่อ P-Value < a เราจึงปฏิเสธสมมติฐาน H0: Data is normal distributed. จะเห็นว่าโปรแกรม Minitab จะเพิ่มส่วนที่เป็นการวิเคราะห์หรือพิสูจน์ในเชิงปริมาณหรือตัวเลข เพิ่มขึ้นมา เพื่อให้ง่ายในการตัดสินใจ แต่ถึงอย่างไรก็ตาม การที่เราจะทำการ Qualify ข้อมูล เราจะต้องวิเคราะห์ข้อมูลด้วยเชิงคุณภาพด้วย เช่น ตัวอย่าง Data2 คำถามมีว่าที่ไม่เป็น Normal distribution แล้ว เพราะอะไร หากดูใน Probability plot เราจะเห็นว่า เพราะข้อมูลส่วนใหญ่ กระจุกตัวอยู่ด้านค่าต่ำ ซึ่งน่าจะเป็น Exponential Distribution ก็เป็นได้ ทำให้เราสามารถที่จะย้อนกลับมาดูว่า เราจะต้องแก้ไขวิธีเก็บข้อมูล หรือจะทำอย่างไรถึงจะได้ข้อมูลที่เป็น Normal distribution Distribution Plot เนื่องจากข้อจำกัดของวิธี Quantile plot และ Probability plot คือจะใช้ไม่ได้ผลกรณีที่ขนาดของข้อมูลมีจำนวนมาก ( ระดับมากกว่า 100-300 จำนวน ขึ้นไป ) ดังนั้น เราจำเป็นต้องหลีกเลี่ยงวิธีดังกล่าว แต่เราสามารถที่จะใช้วิธีการ Distribution Plot แทนได้ ดังตัวอย่างต่อไปนี้
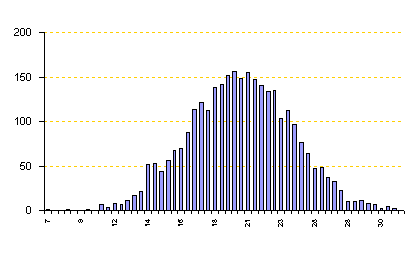
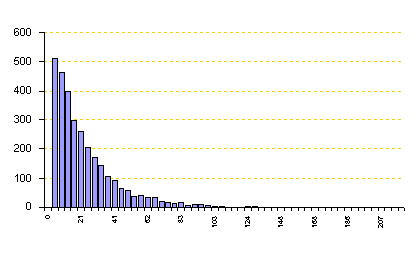
จากรูป เป็นกรณีที่มีจำนวนข้อมูล 3000 จำนวน เมื่อเรานำมาทำ Distribution plot โดยใช้ Histrogram เราจะพบว่าข้อมูลมีลักษณะการกระจายเข้าข่ายเป็น Normal distribution เราก็สามารถสรุปได้ทันทีว่าข้อมูลนี้ ผ่าน Normality test แล้วและสามารถใช้ Tool ต่างๆ ที่มีข้อกำหนดว่า ข้อมูลต้องเป็น Normal distribution ในการวิเคราะห์ข้อมูลได้ ในกรณีเช่นนี้ เราไม่จำเป็นต้องตัดสินโดยใช้ค่า Alpha (a) แต่อย่างใด เมื่อเราดูลักษณะของกราฟแล้ว เราก็สามารถใช้ประมาณการณ์ได้เลย
จากรูป เมื่อเราดู Distribution ก็สรุปได้ว่าไม่ใช่ Normal distribution แน่นอน ทำให้เราไม่สามารถใช้ Tool ที่ต้องการข้อมูลที่เป็น Normal distribution ได้เลย กล่าวโดยสรุปคือ ถ้ามีข้อมูลจำนวนมากเกินไป เราก็จะใช้วิธีดู Distribution ผ่านทาง Histogram ซึ่งโดยทั่วไป Software ที่เราใช้ในการวิเคราะห์ ทางสถิติ ก็จะมีความสามารถ ในการทำ Histogram อยู่แล้ว หรือแม้แต่ Excel เราก็สามารถใช้ ทำ Distribution plot ได้
|