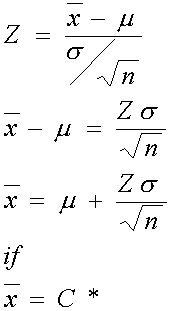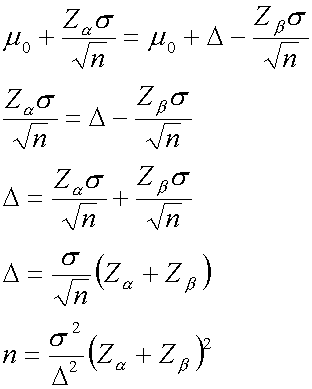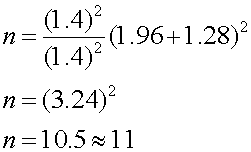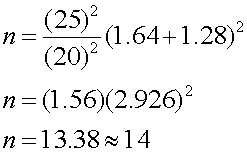|
การกำหนดขนาดของสิ่งตัวอย่าง Sample size selection (n) การที่เราต้องทำการทดลอง ในเรื่องอะไรก็ตาม เพื่อให้ได้ข้อมูลมาทำการวิเคราะห์ มีคำถามที่หลายคนคงจะตั้งคำถามกับตัวเอง เช่นตัวอย่างคำถามต่อไปนี้ “ จะใช้จำนวนตัวอย่างเท่าไหร่ ถึงจะมั่นใจ” “ จำนวนข้อมูลที่เก็บมา มากพอหรือเปล่า” “ จะเก็บข้อมูลเพิ่มอีกดีกว่าไหม จะได้มั่นใจ” หลายคนอาจจะตอบว่า ไม่เห็นจะยากเลย ก็เอาตัวอย่างให้เยอะที่สุด ไปเลย มั่นใจได้แน่นอน แต่เมื่อท่านได้ทราบข้อจำกัดดังตัวอย่างต่อไปนี้ท่านอาจจะเข้าใจมากขึ้นว่า ทำไม ถึงทำอย่างนั้นไม่ได้
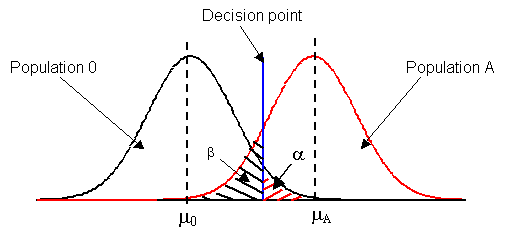
องค์ประกอบในการกำหนดขนาดจำนวนสิ่งตัวอย่าง a หรือ a-Risk คือระดับความเสี่ยงที่จะสรุปผิด โดยสรุปว่าข้อมูลของสองประชากรนั้น มีความแตกต่างกัน มากกว่าค่าวิกฤต (Critical difference) ทั้งๆที่จริงๆ แล้วไม่ได้มีความแตกต่างจนถือว่า มีนัยสำคัญหรือ Type I Error ซึ่งโดยปกติการใช้ข้อมูลทางสถิติในการพยากรณ์อะไรก็ตาม ย่อมต้องมีความผิดพลาดเสมอ เมื่อเราไม่อาจหลีกเลี่ยงได้ จึงต้องจำกัดความเสี่ยงนี้ให้น้อยที่สุด โดยมาตรฐาน จะอยู่ที่ 5% แต่บางกรณีอาจจะมากหรือน้อยกว่าก็ได้ ยกตัวอย่างเช่น การทำการทดลองค้นคว้าหาสิ่งใหม่ๆ ค่าความเสี่ยงนี้อาจจะยอมรับได้ถึง 30% เพื่อให้เกิดการค้นพบความรู้ใหม่ๆ หรือในทางตรงกันข้ามอะไรที่มีอันตรายมาก เช่น ปริมาณการให้ยาแก่ผู้ป่วย ค่าความเสี่ยงอาจจะต้องน้อย เป็น 1%
Power of the test = 1-b ค่า Power of the test ก็คือระดับความมั่นใจ ว่าจำนวนตัวอย่างที่เราเลือกนั้น มีสูงแค่ไหน โดยทั่วไป จะอยู่ที่ 80% – 95% ด้วยเช่นกัน ซึ่งในการคำนวณหาขนาดสิ่งตัวอย่างนั้น ค่านี้ จะบ่งบอกความสามารถที่จะเห็น ความแตกต่าง ของข้อมูล 2 ข้อมูล
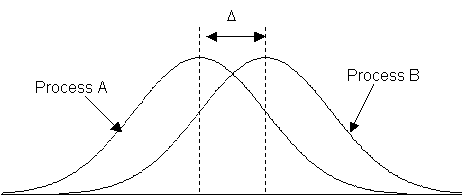
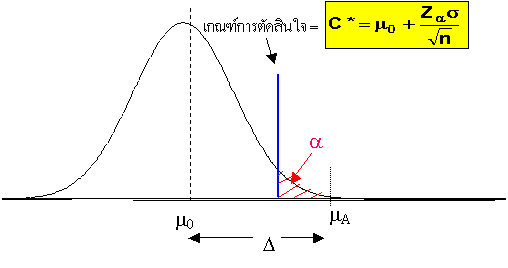
เพื่อให้มองเห็นภาพของคำว่าความเสี่ยง ของทั้งสองแบบ รูปข้างล่างนี้จะอธิบายได้ดีขึ้น ในทางตรงกันข้าม บริเวณ b ที่จริงแล้วข้อมูลที่เก็บมาได้เป็นข้อมูลของ Population A แล้ว แต่เนื่องจากเป็นส่วนปลายๆ ของ Population A และเป็นส่วนคาบเกี่ยวของทั้งสองประชากร ทำให้ไม่แน่ใจ เลยทำให้สรุปว่า เป็นส่วนของ Population 0 อยู่ รูปอธิบาย ความแตกต่างวิกฤตของสองประชากร ( d หรือ D )
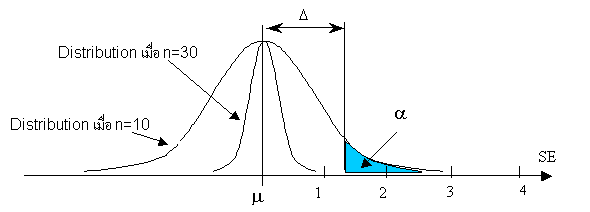
ความแตกต่างวิกฤต (Critical difference) เป็นความแตกต่างเชิงปฏิบัติที่ผู้ทำการทดลองต้องการจะตรวจสอบพบ ด้วยความน่าจะเป็นที่สูง โดยทั่วไปแล้วผู้ทดสอบจะกำหนดให้มีโอกาสตามความคลาดเคลื่อน Type II error (b) ที่จะพลาด โดยตรวจไม่พบว่ามีความแตกต่าง ความสัมพันธ์ระหว่าง n , D และ s เมื่อขนาดสิ่งตัวอย่างเพิ่มมากขึ้น การประมาณค่า Parameter ของประชากรที่แท้จริงยิ่งจะมีความถูกต้องมากขึ้น ในทางทฤษฎีแล้วค่าเบี่ยงเบนมาตรฐานของค่าเฉลี่ย (SE) รูปข้างล่างนี้จะช่วยให้มองเห็นภาพ ได้ง่ายขึ้น
ในทางตรงกันข้ามเมื่อเราใช้จำนวนสิ่งตัวอย่างมากขึ้น โอกาสที่เราจะสรุปผิดพลาดว่าสองประชากรนั้นมีความมีความแตกต่างกันอย่างมีนัยสำคัญ ทั้งๆ จริงๆแล้วไม่แตกต่างกัน (Type I Error) ก็มีน้อยลง แม้ว่าค่าความแตกต่างวิกฤต (D) จะเท่าเดิมอยู่ก็ตาม
รูปกรณีที่ n = 30
ดังนั้นถ้าหากเราต้องการบอกให้ได้ว่าทั้งสองข้อมูลมีความแตกต่างกันจริง โดยที่ค่าความแตกต่างวิกฤต (d) ขนาดเล็ก เราจะต้องใช้จำนวนสิ่งตัวอย่างมากขึ้น เช่นกัน โดยสรุปความสัมพันธ์ระหว่าง n , D และ s เป็นดังนี้
เลือกค่า
a , b
และ
D การจะเลือกค่า
a,b
และ
D
ที่ถูกต้องนั้นถือเป็นภาระที่ยากมากที่สุดประการหนึ่งของผู้ทำการทดลอง
เกณฑ์ในการเลือกก็ไม่มีกฎหรือสูตรตายตัว
แต่ปัจจัยที่ต้องคำนึงถึงและใช้ในการกำหนดขนาดของสิ่งตัวอย่าง
มีต่อไปนี้
การคำนวณหาขนาดของสิ่งตัวอย่าง เราจำเป็นต้องกำหนดเกณฑ์การตัดสินใจ C* โดยอ้างอิงกับทฤษฎี Confidence Interval โดยที่
โปรดดูรูปประกอบเพื่อความเข้าใจ
เกณฑ์การตัดสินใจเมื่อพิจารณาด้าน
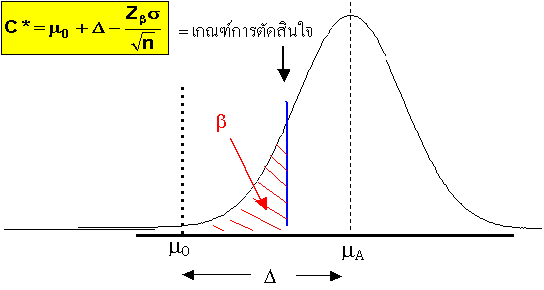
เกณฑ์การตัดสินใจเมื่อพิจารณาด้าน
b
จากสมการ เราจะเห็นว่าอัตราส่วนระหว่าง s/D เป็นค่าความแตกต่างวิกฤตที่เราต้องการตรวจพบ ที่อยู่ในรูปค่าความเบี่ยงเบนมาตรฐานของประชากร ถ้าอัตราส่วนนี้ต่ำเราก็จะตรวจพบความแตกต่างได้โดยง่าย แม้ว่าจะไม่ได้วิเคราะห์ด้วยหลักการทางสถิติก็ตาม ตรงกันข้ามถ้าความผันแปรสูงอัตราส่วนนี้จะสูง เป็นการยากมากที่เราจะสรุปได้ว่าความแตกต่างที่แท้จริงเป็นเท่าใด จำเป็นที่เราจะต้องเพิ่มจำนวนสิ่งตัวอย่างมากขึ้น เพื่อให้สามารถค้นพบค่าความแตกต่างที่แท้จริงได้ ความแตกต่างของการทดสอบด้านเดียว(One-sided test) และการทดสอบแบบสองด้าน (Two-sided test) จากสมการที่ได้ข้างบนนั้น
เป็นการทดสอบแบบด้านเดียว
เราจึงใช้ค่า Za
และ
Zb
แต่ถ้าเป็นการทดสอบแบบสองด้าน
เราจะใช้ Za/2
แทนในสมการ ตัวอย่าง 1 เครื่องจักรตัดแท่งโลหะเครื่องหนึ่ง ตัดแท่งโลหะแล้วมีค่าความยาวเฉลี่ย 30.05 เซนติเมตร และค่าความเบี่ยงเบนมาตรฐานที่ผ่านมาอยู่ที่ 1.40 เซนติเมตร เมื่อต้องทำการเปลี่ยนชิ้นส่วน นายช่างต้องการทดสอบสมมติฐานว่า ก่อนและหลังเปลี่ยนชิ้นส่วน ผลการตัดแท่งโลหะจะผิดเพี้ยนไปจากเดิมหรือไม่ โดยต้องการความเชื่อมั่นในการทดสอบ 95% และต้องการ Power of the test ที่ 90% ขึ้นไป โดยถ้าก่อนและหลังเปลี่ยนชิ้นส่วนอะไหล่ ยังตัดแท่งโลหะได้ความยาวเท่าเดิม หรือผิดพลาดไม่เกิน 1 เท่าของค่าความเบี่ยงบนมาตรฐาน จะถือว่าเครื่องจักรนั้นผ่านการทดสอบ หาสมมติฐานของโจทย์ ต้องการทดสอบความแตกต่างของค่าเฉลี่ย โดยเป็นการทดสอบแบบสองด้าน (2 Sided test) โดยผู้ทำการทดสอบจะต้องเก็บข้อมูลก่อนและหลังเปลี่ยนชิ้นส่วนอะไหล่ของเครื่องจักร ดังนั้น สมมติฐาน จะเป็น Ho: ความยาวแท่งโลหะ ก่อนและหลังเปลี่ยนชิ้นส่วนไม่แตกต่างกัน Ha: ความยาวแท่งโลหะ ก่อนและหลังเปลี่ยนชิ้นส่วนแตกต่างกัน จาก โจทย์เราทราบว่า 1*s = D a=0.05, a/2=0.025 จากตาราง Z0.025 = 1.96 b = 0.1 จากตาราง Z0.1 = 1.28
ดังนั้นขนาดของสิ่งตัวอย่าง หาได้จาก
นั่นคือ ผู้ทำการทดสอบจะต้องใช้จำนวนข้อมูลก่อนและหลังเปลี่ยนชิ้นส่วนอะไหล่ 11 ข้อมูล (ตัวอย่าง หรือ แท่งเหล็ก ) ตัวอย่าง 2 วิศวกรต้องการปรับปรุงเครื่องจักรที่ทำการบรรจุปูนซิเมนต์ชนิดถุง เพื่อให้สามารถได้ผลผลิตต่อชั่วโมง (Unit per hour) เพิ่มขึ้น โดยปกติที่ผ่านมาพบว่าเครื่องจักรเครื่องนี้สามารถผลิตได้ 410 ถุงต่อชั่วโมง โดยมีค่าความเบี่ยงเบนมาตรฐานอยู่ที่ 25 ถุงต่อชั่วโมง ผู้ผลิตชิ้นส่วนเจ้าหนึ่งอ้างว่า ถ้าเปลี่ยนมาใช้อะไหล่ของเขา จะทำให้ความสามารถของเครื่องจักร เพิ่มขึ้นอีก 20 ถุงต่อชั่วโมงเป็นอย่างต่ำ อยากทราบว่าจะต้องเก็บตัวอย่างก่อนและหลังปรับปรุงเครื่องจักรจำนวนเท่าใด ถึงจะเพียงพอ ถ้าต้องการความถูกต้อง 95% และ Power of the test 90% เพื่อจะตอบตกลงซื้อหรือไม่ซื้อชิ้นส่วนจากผู้ผลิตเจ้านี้ จากโจทย์ เราสามารถตั้งสมมติฐานได้ว่า Ho: Unit per hour ก่อนและหลังเปลี่ยนชิ้นส่วนไม่แตกต่างกัน Ha: Unit per hour หลังเปลี่ยนชิ้นส่วนมากกว่าก่อนเปลี่ยน เป็น
One-sided test จากโจทย์เราได้ s = 25 D = 20 a=0.05 , b = 0.1
หมายเหตุ
คำว่าสิ่งตัวอย่างตามโจทย์ตัวอย่างข้อนี้
ไม่ได้หมายถึงจำนวนถุงปูนซิเมนต์
แต่หมายถึงจำนวนครั้ง
ที่ได้ทำการเก็บข้อมูลปริมาณผลผลิต
ต่อชั่วโมง ของเครื่องจักร
|