|
Fractional Factorial Designs ความหมายและหลักการ หมายถึงวิธีที่ผู้ทำการทดลองไม่ต้องทำการทดลองให้ครบทุกเงื่อนไขการเปลี่ยนแปลงค่าของทุกปัจจัย เนื่องจากจะมีจำนวน Run มากจนเกินไปจนไม่สามารถดำเนินการได้ เนื่องจากมีข้อจำกัดบางประการ แน่นอนว่าความแม่นยำของผลก็ไม่เท่ากับ Full factorial ในเชิงทฤษฏี แต่ในทางปฏิบัติถึงเราจะสามารถดำเนินการทดลองด้วยวิธี Full factorial แต่อาจจะได้ผลที่แย่กว่า Fractional factorial ก็ได้ เนื่องจากยิ่งมาก Factor ยิ่งมาก Run เราก็ยิ่งควบคุมการทดลองได้ยาก ความผิดพลาดก็จะยิ่งเพิ่มมากขึ้น ดังนั้นจึงไม่มีประโยชน์ที่เราจะคงยืนยันใช้การทดลองแบบ Full factorial เมื่อเรามี Factor หลายตัว นักสถิติประยุกต์ในยุคแรกๆ ได้ค้นพบว่าในความเป็นจริงเมื่อเราดำเนินการทดลองจะมีเพียงบาง Main effects และบาง Interaction เท่านั้นที่มีความสำคัญ ยิ่งลำดับของ Interaction สูงขึ้นก็ยิ่งมีโอกาสจะมีนัยสำคัญน้อยลง จึงได้นำเอาหลักการนี้ไปใช้ประโยชน์เพื่อลดขนาดของการทดลองลง
ตารางที่ 1 อัตราส่วนของผลจาก Main effects ต่อจำนวน Effects รวมทั้งหมดในการทดลอง จากตารางที่ 1 จะพบว่าสัดส่วนของ Main effects ต่อ Effects ทั้งหมดจะยิ่งลดลงเรื่อยๆ เมื่อการทดลองนั้นมี Factor มากขึ้น เช่น หากการทดลองนั้นมี 6 Factor สัดสวนผลที่มาจาก Main effects จะมีเพียงแค่ 9.5% ของจำนวน effects รวม ที่เหลืออีก 90.5% เป็น Interaction effects ซึ่งส่วนใหญ่ก็ไม่มีนัยสำคัญเชิงสถิติต่อการทดลองนั้นด้วย วิธีการสร้าง Fractional factorial แบบ 2k-1 design ความหมายคือ เมื่อออกแบบเสร็จจะได้จำนวน Run เท่ากับ Full factorial design ของการออกแบบเมื่อจำนวน Factor น้อยกว่าอยู่ 1 ตัว (k-1) หรือจำนวน Run จะเท่ากับครึ่งหนึ่งของการออกแบบการทดลองแบบ Full factorial design นั่นเอง เราเอาหลักการที่ว่ายิ่งอันดับ Interaction สูงเท่าใดก็จะมีความสำคัญน้อยเท่านั้น และจะเอา Main effects บางตัวเข้าแทนที่ Interaction ดังกล่าว ตัวอย่างที่ 1 มี Factor 4 ตัวคือ A,B,C,D ถ้าออกแบบโดยใช้วิธี 2k Full factorial จะมีจำนวนรอบการทดลองหรือ Run ทั้งหมด 16 Run ดังตารางที่ 2
ตารางที่ 2 Full factorial ของ 4 Factor เมื่อเราต้องการทำการทดลองแบบ Fractional factorial โดยให้เหลือจำนวน 8 Run เท่ากับจำนวน Run ของ 3 ปัจจัย เราเริ่มด้วยการ เขียน 3 main effecs และ Interaction ทั้งหมดในตาราง เราจะเรียก 3 main effects นี้ว่าตัวให้กำเนิด (generator) ของ Factor D
ตารางที่ 3 Main effecs และ Interaction ของ 3 Factor จากนั้นให้ใช้ค่าของ Interaction ที่มีอันดับสูงสุด เป็นค่าของ Main effect ตัวที่เหลือ จากตารางที่ 3 Interaction ที่มีอันดับสูงสุดคือ ABC เราจะใช้เป็นค่าของ D จึงได้ตาราง Fractional factorial design ของ 4 Factor ตามตารางที่ 4
ตารางที่ 4 Fractional factorial ของ 4 Factor จากตารางที่ 4 เมื่อเทียบกับตารางที่ 2 ก็คือแถวที่พื้นสีเหลืองนั่นเอง วิธีการออกแบบเช่นนี้ จะได้จำนวน Run ครึ่งหนึ่งของ Full factorial เสมอหรือ 1/2 Fraction เราจึงเรียกวิธีการออกแบบการทดลองนี้ว่า Half factorial design ซึ่งบางครั้งก็เรียกว่า 2k-1 design เมื่อเราทำการทดลองตามที่ออกแบบนี้ ก็จะเรียกว่า Half factorial experiment ด้วยเช่นกัน Alias / Confound เมื่อเราเลือกใช้วิธี Fractional factorial design ประโยชน์ที่เราได้คือจำนวน Run ที่ลดลงได้อย่างน้อยก็ครึ่งหนึ่ง แต่ก็ต้องแลกด้วยความสงสัยที่ว่าความถูกต้องจะเหมือนกับ Full factorial design หรือไม่ อีกสิ่งหนึ่งที่เราจะต้องสูญเสียไปคือ ความสามารถในการแยกแยะผลกระทบของ Effects ที่ตอนนี้มีบางตัวที่แยกแยะกันไม่ออก จากตารางที่ 4 เราทราบแล้วว่าตอนนี้ D=ABC นั่นคือถ้าสมมติเราพบว่า D เป็น Mian effects ที่มีนัยสำคัญทางสถิติหลังจากการวิเคราะห์แล้ว คำถามอยู่ที่ว่า เป็น Interaction ของตัวปัจจัย ABC หรือว่า D กันแน่ กรณีเช่นนี้เราเรียกว่า D มี Alias คือ ABC หรืออีกนัยหนึ่ง ABC คือ Alias ของ D ได้เช่นกัน กรณีเช่นนี้เราจะเรียกว่า D และ ABC เกิด Confound กันด้วยเช่นกัน ใช่เพียงแค่นี้หากเราทำการทดลองตามตารางที่ 4 แล้ว จะมี Alias เกิดขึ้นหลายคู่ ดังตารางที่ 5 (ขออภัยผู้อ่านอาจจะลายตาจากสีที่หลากหลาย โปรดดูตามสีเดียวกัน) นี่คือคู่ Alias ที่เกิดขึ้น ลักษณะเช่นนี้เราจะเรียกว่า Alias structure
ตารางที่ 5 Alias structure ของ 4 Factor เราอาจจะเขียน Alias structure ได้ดังนี้
Defining word ถ้าเราเอารหัสของแต่ละ Column คูณตัวเอง(ยกกำลังสอง) จะได้รหัสที่เท่ากับ (+1) ทุกตัวเสมอ เราจะเรียก Column ที่ได้ใหม่นี้ว่า Identity หรือ I จากตารางที่ 4 เมื่อ D = ABC ดังนั้น ถ้าเอา D คูณทั้งสองฝั่ง จะได้เป็น DD = ABCD หรือ I = ABCD เราจะเรียก I=ABCD นี้ว่า Defining relation ซึ่งเราสามารถนำไปใช้ในการหา Alias ได้ โดยนำ Effect ที่เราอยากทราบ Alias คูณทั้งสองฝั่งของสมการ Defining relation เช่น ถ้าอยากทราบว่า AB จากตารางที่ 4 Alias อยู่กับ Effect อะไร ก็หาได้จาก I(AB) = ABCD(AB) AB = A2B2CD AB = IICD = CD นั่นคือ AB alias อยู่กับ CD นั่นเอง Vertical Balance หมายถึงการทดสอบความเท่ากันของจำนวน Code (+1)และ (-1) ของแต่ละ Column ทั้งของ main effects และ interaction effects ในตารางหลังจากการออกแบบการทดลอง โดยเงื่อนไขคือผลรวมของแต่ละ Column จะต้องเท่ากับ 0 นั่นหมายความว่าเรามีการเปลี่ยนแปลงค่าของ Factor นั้นให้เป็น Highและ Low ในจำนวนครั้งที่เท่ากัน ผู้ออกแบบจะต้องทำการทดสอบทุกครั้ง Orthogonal เมื่อนำ Code (+1) หรือ (-1) ของ 2 Column ที่อยู่ติดกัน และอยู่แนว Row เดียวกัน คูณกันทุกๆ Row ของ 2 Column ดังกล่าว แล้วนำผลลัพธ์ดังกล่าวรวมกัน จะต้องได้เท่ากับ 0 เสมอ นั่นหมายความว่าเมื่อเราทำการวิเคราะห์ผลการทดลองแล้ว จะไม่ปรากฏเหตุการณ์ที่ Factor หนึ่งแปรเปลี่ยนตามอีก Factor หนึ่ง (Dependency test) ถ้าสมมติว่า ไม่เป็น orthogonal แล้ว เป็นไปได้ว่า เราจะต้องเปลี่ยนค่าของ Factor มากกว่า 1 ตัว เป็น High หรือ Low พร้อมกันอาจจะส่งผลให้เราตีความผิดพลาดแยกแยะไม่ออกว่า Response แปรค่าตาม Factor ใดกันแน่ การออกแบบที่ดีจะต้องได้ตารางเป็น Orthogonal ผู้ออกแบบจะต้องทำการทดสอบทุกครั้งเช่นเดียวกับ Vertical balance และทำให้ครบทุก Column แต่ครั้งละ 1 คู่เท่านั้น วิธีการสร้าง Fractional factorial แบบ 2k-p design เมื่อเรามี Factor อยู่ 3-5 ตัว เราอาจจะสามารถใช้วิธี Half factorial design หรือ 2k-1 design ได้ แต่ถ้าจำนวน Factor เพิ่มมากขึ้นกว่านั้นอีก ก็ยากที่เราจะสามารถทำการทดลองตามแบบที่ออกแบบไว้ได้ เพราะจำนวน Run ก็จะยังเยอะเกินกว่าจะทำตามได้
ตารางที่ 6 จำนวน Run เทียบกับจำนวน Factor ของแต่ละ Design จากตารางที่ 6 จะพบว่าผู้ออกแบบการทดลองจำเป็นต้อง ใช้ค่า p ที่มากกว่า 1 ในการออกแบบเมื่อมี Factor ตั้งแต่ 6 ตัวขึ้นไป โดยข้อกำหนดง่ายๆ คือ เมื่อมีการออกแบบ ควรจะให้จำนวน Run เริ่มต้นที่ 8 และไม่ควรเกิน 32 (ความคิดเห็นส่วนตัวของผู้เขียนเอง) ตัวอย่าง 2 มี Factor ทั้งหมด 7 ตัว (A,B,C,D,E,F,G) และในการทดลองแต่ละ Factor ปรับได้ 2 ค่า (Level) จากตารางที่ 6 หากเราออกแบบโดยใช้วิธี Full factorial จะมีจำนวน Run เท่ากับ 27=128 ซึ่งเป็นไปไม่ได้เลยที่เราจะทำการทดลองให้ได้ตามนั้น แม้แต่ Half factorial design ก็ยังมีถึง 64 Run ซึ่งก็ยังถือว่ามากอยู่ดี ถ้าต้องการออกแบบการทดลองโดยให้เหลือจำนวน Run เพียง 16 เท่ากับ Full factorial ของ 4 factor นั่นคือ 7-p = 4 ดังนั้น p=3 นั่นคือเราเลือกการออกแบบ 27-3 นั่นเอง ขั้นตอนก็คล้ายกับวิธี 2k-1 เริ่มจากการเขียน Full factorial design ของ Main effect A,B,C,D และใช้เป็นตัวกำเนิด Main effect E,F,G ที่เหลือ โดยเราจะเลือก E=ABC , F=BCD, G=ABD
ตารางที่ 7 ผลการออกแบบโดยวิธี 27-3 ทำไมเราถึงต้องเลือก E=ABC , F=BCD, G=ABD จะเป็น E=AB , F=BC, G=CD ได้หรือไม่ เนื่องจากข้อสมมติฐานที่ว่า Interaction ระดับที่สูงกว่า มีโอกาสมีนัยสำคัญทางสถิติน้อยกว่า Interaction ที่มีระดับต่ำกว่า นั่นคือ Interaction ของ 3 Main effect ย่อมมีโอกาสมีนัยสำคัญทางสถิติน้อยกว่า Interaction ของ 2 main effects. เมื่อเวลาวิเคราะห์โอกาสตีความ Confounding ก็จะผิดน้อยลง จึงต้องเลือก 3 Main effect แทนตัว Factor ที่เหลือ ถ้าเหตุผลเป็นเช่นนี้ก็ควรใช้ 4 main effect แทนน่าจะดีที่สุด แต่ที่ไม่ใช้เพราะ 4 Main effect ในการออกแบบด้วยวิธี 27-3 มีเพียง 1 เดียวเท่านั้น ไม่พอที่จะใช้แทน 3 Main effect ที่เหลือได้ โดยที่ข้อกำหนดพื้นฐานคือต้องใช้ ระดับ Interaction เดียวกันแทน main effects ที่เหลือทุกตัว จากการที่เราต้องใช้ E=ABC , F=BCD, G=ABD ในการออกแบบ ถ้าเอาตัว main effect คูณทั้งสองด้านจะได้ EE = I = ABCE FF = I = BCDF GG = I = ABDG นั่นคือเราจะได้ Defining word เริ่มต้น 3 ตัวคือ I = ABCE = BCDF = ABDG เมื่อนำ Defining word มาคูณกันเอง ทีละคู่และคูณกันเองทั้งหมดจะได้เป็น I2 = ABCE(BCDF) จะได้เป็น I = AB2C2DEF หรือ I = ADEF I2 = ABCE(ABDG) จะได้เป็น I = A2B2CDEG หรือ I = CDEG I2 = ABDG(BCDF) จะได้เป็น I = AB2D2CFG หรือ I = ACFG I3 = (ABCE)(ABDG)(BCDF) จะได้เป็น I = A2B3D2C2EFG หรือ I = BEFG ดังนั้น Defining word ทั้งหมดคือ I = ABCE=BCDF=ABDG=ADEF=CDEG=ACFG=BEFG เราสามารถหา Alias ทั้งหมดได้โดยการนำ Effect ที่เราต้องการทราบว่า มี Alias อะไรบ้างคูณเข้ากับ Defining word ดังตัวอย่างต่อไปนี้ Alias ของ A หาได้จาก I(A) = ABCE(A)=BCDF(A)=ABDG(A)=ADEF(A)=CDEG(A)=ACFG(A)=BEFG(A) A=BCE=ABCDF=BDG=DEF=ACDEG=CFG=ABEFG Alias ของ BCD หาได้จาก I(BCD) = ABCE(BCD)=BCDF(BCD)=ABDG(BCD)=ADEF(BCD)=CDEG(BCD)=ACFG(BCD)=BEFG(BCD) BCD = ADE = F = ACG = ABCEF = BEG = ABDFG = CDEFG Resolution (R) คือระดับความละเอียดในผลลัพธ์ที่ได้จากการวิเคราะห์ หาได้จากความยาวของ Alias ที่สั้นที่สุดจาก Defining relation หมายความว่าผลการวิเคราะห์ที่ได้มีความน่าเชื่อถือมากแค่ไหน โดยมีค่าอยู่ระหว่าง 2 (RII) จนถึง 5 (RV) เช่นตัวอย่าง I = ACG = ABCEF = BEG = ABDFG = CDEFG ได้ RIII เพราะ Alias สั้นที่สุด คือ 3 Main effect interaction I = ABCEG = BCDF = ABDG ได้ RIV เพราะ Alias สั้นที่สุด คือ 4 Resolution มากกว่า ย่อมให้ความน่าเชื่อถือของผลลัพธ์มากกว่า นั่นเพราะเราได้เฉพาะ Interaction ระดับสูงๆแทน Main effect ในการออกแบบ ทำให้โอกาสที่ Confond ที่พบในการวิเคราะห์มีโอกาสเป็นของ Main effect มากกว่า Interaction นั่นเอง การเลือกระดับ Resolution ต่ำหมายความว่าคนออกแบบใช้ค่า p ที่มาก เข้าใกล้ k มาก ทำให้ลดจำนวน Run ลงได้มาก และต้องใช้ Interaction ระดับต่ำในการแทน Main effects บางตัว (RIII) เป็นระดับที่ต่ำที่สุดที่คนออกแบบจะเลือกใช้ เหมาะสำหรับการเริ่มต้น (Screenning) กรณีที่มีจำนวน Factor มากๆ ไม่ควรนำ Model ใดๆ ที่ได้จากการวิเคราะห์ไปใช้ และจะต้องมีการคัดกรองเอา Main effect ที่ไม่มีนัยสำคัญทางสถิติบางตัวออก และควรมีการออกแบบการทดลองอีกรอบ ที่มี Resolution มากกว่า RIII (RIV) เป็นระดับที่ดีปานกลางที่คนออกแบบควรจะเลือกใช้ สามารถนำ Model ที่ได้จากการวิเคราะห์ไปใช้ในการพยากรณ์ หรือเปลี่ยนแปลงกระบวนการตามผลการวิเคราะห์ได้ (RV) เป็นระดับที่ดีที่สุดที่คนออกแบบควรจะเลือกใช้ แต่ก็ต้องใช้ทรัพยากรมากกว่าระดับอื่นๆ ทั้งนี้เพราะ จะมีจำนวน Run มาก นั่นเอง
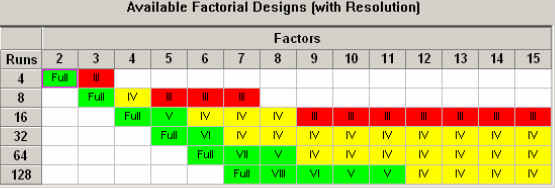
ตารางที่ 8 ระดับ Resolution ที่เป็นไปได้ เมื่อกำหนด Run และจำนวน Factor
|