|
Estructura
de Datos y
Algoritmos.
BÚSQUEDA: Los sistemas informáticos se utilizan a menudo para salvar cantidades grandes de datos de los cuales los expedientes individuales se deban extraer según un cierto criterio de la búsqueda. Así el almacenaje eficiente de los datos a facilitar rápidamente el buscar es una edición importante.
BÚSQUEDAS SECUÉNCIALES: Examinemos cuánto tiempo nos llevará el hallazgo un item que corresponda a una clave de la colección que hemos discutido hasta ahora. Nos interesa :
Sin embargo, generalmente estaremos mas interesados en el peor de los tiempos como los cálculos basados en épocas a lo peor pueden conducir a las predicciones garantizadas del funcionamiento. Convenientemente, el peor de los tiempos es mas facil de calcular que el tiempo promedio. Si hay "n" item's en nuestra colección entonces es obvio que en peor caso, cuando no hay item en la colección con "llave", después n comparaciones la llave de llave de los item's en la colección debe de ser creada. Para simplificar el análisis y la comparación de algoritmos, buscamos una operación dominante y contamos el número de tiempo que la operación dominante tiene que ser realizada. En el caso de buscar, la operación dominante es la comparación, puesto que la búsqueda requiere comparaciones de "n" en el peor caso, nosotros decimos que esto es un algoritmo de O(n) (pronuncado " big-Oh-n " o el " Oh-n-n "). El mejor caso - el cuál vuelve la primera comparación un emparejamiento - requiere una sola comparación y es O(1). El tiempo promedio depende de la probabilidad de que la "llave" será encontrada en la colección . Así en este caso, como en la mayoría del otros, la valoración del tiempo medio está poco utilizada. Si el funcionamiento del sistema es vital, es decir es parte de un sistema vida-crítico, entonces nosotros debemos utilizar el peor caso en nuestros cálculos del diseño pues representa el mejor avance.
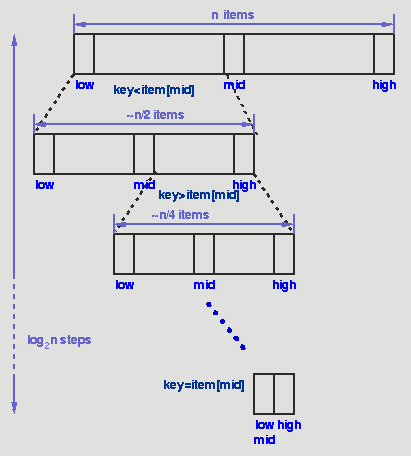
BÚSQUEDAS BINARIAS: Si ponemos nuestros items en un arreglo y los clasificamos en orden ascendente o descendente en el primer dominante, entonces podemos obtener un funcionamiento mucho mejor con un algoritmo llamado búsqueda binaria. En la búsqueda binaria, primero comparamos la llave con el item en la posición media del arreglo. Si hay un emparejamiento, podemos volver inmediatamente. Si la llave es menos que la lleve promedio, entonces el item buscado debe estar en la mitad inferior del arreglo, si es mayor entonces el item buscado debe esta en la mitad superior del arreglo. Repetimos el procedimiento en la mitad más baja (o el alta)del arreglo. Función de FindInCollection :: static void *bin_search( collection c, int low, int high, void *key ) { int mid; /* Termination check * / if (low > high) return NULL; mid = (high+low)/2; switch (memcmp(ItemKey(c->items[mid]),key,c->size)) { /* Match, return item found */ case 0: return c->items[mid]; /* key is less than mid, search lower half */ case -1: return bin_search( c, low, mid-1, key); /* key is greater than mid, search upper half */ case 1: return bin_search( c, mid+1, high, key ); default : return NULL; } } void *FindInCollection( collection c, void *key ) { /* Find an item in a collection Pre-condition: c is a collection created by ConsCollection c is sorted in ascending order of the key key != NULL Post-condition: returns an item identified by key if one exists, otherwise returns NULL */ int low, high; low = 0; high = c->item_cnt-1; return bin_search( c, low, high, key ); }
Puntos : a) La busqueda binaria es recursiva: se determina si la clave de búsqueda miente en el más bajo o la mitad superior del arreglo, entonces se llama en la mitad apropiada. b) Hay una condición terminal
c) Sumar al arreglo necesitará ser modificado para asegurarse de que cada item agregado está puesto en su lugar correcto en el arreglo. El procedimiento es simple:
d) La busqueda binaria es declarada estatica. Es una función local y no se utiliza fuera de esta clase: si no fuera declarada estatica, sería exportado y estar disponible a todas las partes del programa.
ANÁLISIS:
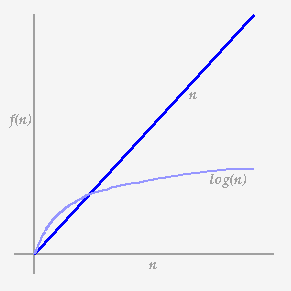
Cada paso del algoritmo divide el bloque en items que son buscados por la mitad. Podemos dividir un conjunto de items de "n" por la mitad en la mayoría de las veces de log2 n. Así el tiempo en marcha de una búsqueda binaria es proporcional al log n y decimos que esto es un algoritmo de O(log n). La búsqueda binaria requiere de un programa más complejo que nuestra búsqueda original y para una "n" pequeña este puede ejecutarse más lento que la búsqueda lineal simple. Así en "n" grande, el registro n es mucho más pequeño que n, por lo tanto un algoritmo de O(log n) es mucho más rápida que un O(n) uno.
Primero, veamos lo que podemos hacer sobre la operación de la inserción (AddToCollection). En el peor de los casos , la inserción puede requerir de "n" operaciones para insertar en una lista clasificada. Podemos encontrar el lugar en la lista en donde pertenece el nuevo item con búsqueda binaria en las operaciones de O(log n). Sin embargo, tenemos que mezclar todos los puntos siguientes encima de un lugar para hacer espacio para el nuevo. En el peor de los casos, el nuevo item es el primer en la lista, requiriendo "n" movimiento de operaciones para el acomodo. Un análisis similar mostrará que la eliminacion es también una operación de O(n). Si nuestra colección es estática, por ejemplo: que no cambia muy a menudo - si en todos - entonces podemos no ser referidos al tiempo requerido para cambiar su contenido: podemos estar preparados para la estructura inicial de la colección y de la inserción y de la cancelacíon ocasionales para tomar una cierta hora. Por otro lado podremos utilizar una estructura de datos simple (un arreglo) que tenga pocos gastos indirectos de la memoria. Sin embargo, si nuestra colección es grande y dinámica, por ejemplo: los items se están agregando y se están suprimiendo continuamente, después podemos obtener un funcionamiento considerablemente mejor usando una estructura de datos llamada un árbol.
CONCLUSIONES: Despues de ver los tipos de busqueda que existen(binaria y lineal) es importantes señalar cual de ellas es mas rapida,como funciona cada una,los algoritmos utilizados,que en este caso fue lenguaje C y ver que relacion tiene con formulas de recurrencia,en donde dependiendo el manejo de bits es el tamaño y tiempo de duracion de la busqueda.
BIBLIOGRAFÍA: John Morris, 1998 http://swww.ee.uwa.edu.au/~plsd210/ds/searching.html
|