|
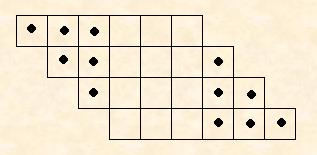
Pipelining Es una técnica avanzada que utilizan los microprocesadores donde el orden de ejecución de las instrucciones es de la siguiente manera: Se comienza con la ejecución de la segunda instrucción antes de que se termine de ejecutar por completo la primera instrucción. Muchas de estas instrucciones están en el mismo PIPELINE de forma simultanea, pero en una fase de proceso diferente. El PIPELINE está dividido en segmentos y cada uno de ellos puede ejecutar sus operaciones concurrentemente con otros segmentos. Cuando un segmento completa su operación envía el resultado al siguiente segmento dentro del PIPELINE y saca la siguiente operación del segmento que le precede. El resultado final de cada instrucción emerge al final de cada PIPELINE en una rápida sucesión. Aunque de manera formal el uso de PIPELINE es solo procesadores alto-desarrollo y RISC, también es muy común encontrarlos en microprocesadores utilizados en PC’s. Por ejemplo el Pentium usa PIPELINING para ejecutar hasta 6 instrucciones de manera simultanea. PIPELINING también conocido como PROCESO PIPELINE Una técnica similar utilizada en DRAM, en la cual la memoria carga los requerimientos de memoria dentro del CACHE compuesto del SRAM e inmediatamente comienza a sacar el contenido de la memoria siguiente. Esto crea 2 fases PIPELINE, cuando los datos son leídos desde o escritos en SRAM, cuando los datos son leídos desde o escritos en memoria. DRAM PIPELINING usualmente es combinado con otras técnicas de desarrollo llamadas “Burst mode”. Estas 2 técnicas combinadas son llamadas PIPELINE BURST CACHE.Significa poder dividir un algoritmo en fases. cada fase está diseñada para poder ser ejecutada en un tiempo promedio. El flujo es dividido en "k" fases distintas. La salida de la fase "j" se vuelve en la entrada de la fase "j+1". PIPELINING se ilustra a continuación:
El PIPELINING se vuelve eficiente cuando es requerida más de una entrada. Para muchos algoritmos no es posible subdibidir en "k" fases iguales creadas en el pipeline.
El problema de la ruta
más corta y el problema de flujo máximo son los dos tipos de problemas
de flujos en redes.
Una red de comunicaciones involucra un conjunto de computadoras (nodos) conectadas mediante enlaces de comunicación (arcos), que transfiere paquetes (grupos de bits) desde determinados nodos origen a otros nodos destino. La forma más común para seleccionar la trayectoria (o ruta) de dichos paquetes, se basa en la formulación de la ruta más corta. En particular a cada enlace de comunicación se le asigna un escalar positivo el cual se puede ver como su longitud. Un algoritmo de ruteo de trayectoria más corta, rutea cada paquete a lo largo de la trayectoria de longitud mínima (ruta más corta) entre los nodos origen y destino del paquete. Hay varias formas posibles de seleccionar la longitud de los enlaces.
Dentro de este contexto, el algoritmo de ruta más corta para ruteo opera continuamente, determinando la trayectoria más corta con longitudes que varían en el tiempo. Una característica peculiar de los algoritmos de ruteo de trayectoria más corta es que con frecuencia utilizan comunicación y computación asíncrona y distribuida. En particular, cada nodo de la red de comunicación:
La comunicación y computación asíncrona y distribuida, acarrea problemas de sincronización por lo que se requiere del uso de técnicas de descripción (o especificación) formal, de las cuales las más utilizadas son las redes de Petri, (o PN por sus siglas en inglés: Petri Nets). En A continuación se presentan los
algoritmos de rutas más cortas que son empleados por los algoritmos de
ruteo, que es la parte fina de dichos algoritmos.
Alternativas de Solución del Problema de Rutas Más Cortas Si bien es cierto que la Programación Lineal (PL) resulta útil para ciertas aplicaciones prácticas, no hay que olvidar que PL es de complejidad exponencial, de esta manera, no se puede tener confianza en ella para casos de redes con un gran número de nodos. Por esta razón, se requiere de algoritmos que exploten la estructura en red del problema de ruta más corta. Entre estos algoritmos se tienen dos tipos: a) Algoritmos de
Programación Dinámica y Existen varios algoritmos de etiquetado, dentro de los cuales, los más conocidos y utilizados son los métodos de Dijsktra.
Algoritmos de Dijkstra Para Ruta Más Corta Estos son algoritmos de etiquetado, los cuales, en términos generales, encuentran la ruta más corta entre dos nodos, inicial a y final z, de la siguiente manera:
Los algoritmos de Dijkstra renumeran los
nodos, de manera que cuando el nodo z tiene una etiqueta permanente, se
ha obtenido la solución final. Algoritmos Heurísticos Como se puede ver, el algoritmo para
encontrar la red multipunto óptima, con restricciones, puede Los algoritmos de Esau-Williams, el de Prim y el de Kruskal producen un árbol de expansión mínima cuando se eliminan las restricciones. Estos algoritmos difieren en sus requerimientos de tiempo de corrida (su complejidad computacional). En el problema de diseño multipunto con restricciones que hemos estado viendo, también se producen diseños algo diferentes. La experiencia ha mostrado que el algoritmo de Esau-Williams generalmente proporciona diseños de red que están más cerca del óptimo, aunque el algoritmo unificado de Kershenbaum-Chou puede ser modificado para obtener aún mejores resultados. El algoritmo Esau-Williams, esencialmente busca los nodos que están más alejados del centro (en el sentido de costo) y los conecta a nodos vecinos que proveen el mayor beneficio en costo. El algoritmo de Prim hace lo inverso: inicialmente selecciona el nodo más cerca del centro (en el sentido de costo), después conecta los nodos que están más cerca a aquellos que ya están en la red. El algoritmo de Kruskal simplemente conecta los enlaces de menor costo, uno a la vez. Para aplicación al problema multipunto, las restricciones deben verificarse conforme se hace una posible conexión. Kershenbaum y Chou han demostrado que
estos tres algoritmos heurísticos, pueden ser considerados casos
especiales de un algoritmo unificado apropiado para resolver el problema
de la conexión multipunto. El algoritmo es esencialmente una forma
modificada del algoritmo de Kruskal, donde en lugar de conectar
sucesivamente enlaces más y más costosos, un factor de peso es usado
como medida de comparación. PROCESO PARALELO Proceso: Es
un programa en ejecución.
Las ventajas de la computación distribuida es que :
HIPERCUBO: Se puede pensar de Hipercubos como series de n-dimensiónales. El tamaño del cubo es el producto Cartesiano del número de niveles en cada dimensión. El tipo de la serie es de número entero. Cuando dos o más dimensiones son inter-dependientes, se gastaría mucho espacio si la codificación especial no fuera empleado. Un cubo de dimensión Euclidiana n, o n-cubo, se puede formar a partir de dos cubos paralelos de dimensión Euclidiana n-1, unidos en sus vértices por vectores ortogonales de la magnitud de una arista del cubo n-1. Un punto tiene dimensión Euclidiana 0. Si se unen dos puntos, se obtiene una línea, de dimensión Euclidiana 1. Si se unen dos líneas por sus vértices, se obtiene un cuadrado, de dimensión Euclidiana 2. Si se unen dos cuadrados por sus vértices, se obtiene un cubo, de dimensión Euclidiana 3. Si se unen dos cubos por sus vértices, se obtiene un hipercubo, de dimensión Euclidiana 4. Si se unen dos hipercubos por sus vértices, se obtiene un cubo de 5 dimensiones, y así ad infinitum. Una forma de identificar fácilmente la dimensión de un cubo es contar las aristas que salen de cada vértice, ya que el numero de aristas será igual a la dimensión. Líneas y Planos Cíclicos Si se toma un segmento de recta y se dobla, de tal forma que se unan sus extremos, se obtendrá un círculo. Este es una línea cíclica, ya que si uno recorre la línea, al llegar al final de esta, se encontrará de nuevo con el principio. Al tomar un plano y unir sus dos extremos opuestos, se obtiene un cilindro. Si se unen los extremos del cilindro, se obtiene un toroide. Un toroide es un plano cíclico. En tres dimensiones tiene una forma de dona. Si uno, al moverse en él, llega al extremo superior y sigue subiendo, saldrá por el extremo inferior. Lo mismo para los extremos derecho e izquierdo. El toroide ya ha sido ampliamente estudiado y tiene numerosas aplicaciones. Por ejemplo, en un Juego de la Vida bidimensional, se puede aplicar un toroide para que las "células" no tengan limitaciones de espacio. O también en el clásico Pac-Man. Se sale por un lado y se regresa por el otro. La estructura de un menú, visto como listas cíclicas, hasta cierto punto, se podría decir, que tiene las propiedades de un toroide.
Espacios y Tiempos Cíclicos Ahora, si se toma un cubo y se le aplica el mismo método para unir sus lados opuestos, se tendrá un espacio cíclico. El criterio para hacer cubos cíclicos es el de reducir todos los vértices del cubo, de n-dimensiones, a un sólo punto. El número de vértices de un cubo en dimensión n es 2^n. Primero, unimos la cara superior con la inferior. Se obtiene una especie de "rueda de troncomóvil". Después se unen los discos laterales de la rueda. Se obtienen dos toroides, uno adentro de otro. Sólo falta unir la cara interna del toroide interno con la cara externa del toroide exterior. Esto no se puede hacer en tres dimensiones, así es que al unirlas, se obtiene una figura de cuatro dimensiones. Simplemente se unen las superficies por medio de otra dimensión. Si uno "volara" adentro de ese hipertoroide, si uno fuera de frente, regresaría al mismo punto por atrás. Si uno fuera hacia la derecha, por la izquierda; hacia arriba, por abajo. Grafiqué una representación en Â3 (tres dimensiones) de este hipertoroide con el archivo TORUS.MTH para Derive.
Hipertoroide Cabe mencionar que las líneas que unen al toroide exterior con el interior representan el espacio de cuatro dimensiones que en realidad los une. Ahora, ¿qué sucede si se "cicla" un hipercubo? Se obtiene una representación gráfica de un espacio de cuatro dimensiones cíclico. Si consideramos al tiempo como una cuarta dimensión, hasta cierto punto, el hipercubo ciclado se podría decir que es un tiempo cíclico.
Victoroide Para construirla, se hacen los mismos pasos que con las figuras anteriores: se van uniendo las caras del hipercubo hasta que sus 16 vértices queden reducidos a un punto. Las líneas que se salen por arriba, se juntan con las que salen por abajo, lo cual no fue posible graficar por las limitaciones del manejo de memoria de Derive.
Aplicaciones Un espacio cíclico se podría aplicar a un Juego de la Vida en tres dimensiones, para aumentar las posibilidades de interacción entre las "células". En el programa LIFE3D.EXE, hecho en Turbo Pascal, se puede apreciar esta característica, ya que se puede activar o desactivar la opción de hipertoroide, lo cual reduce las probabilidades de encontrar un "ser" estable, más o menos en un 40%. Una representación de un tiempo cíclico se puede apreciar en el programa VICTOROI.EXE, hecho en Turbo Pascal. En la pantalla aparece un cubo con una pequeña esfera móvil en él. Cuando la esfera toca un extremo del cubo, aparece por el contrario. El tiempo es tomado como vector, pero con movimiento constante y uniforme. El tiempo también es cíclico, pues al llegar a 10 segundos, el cronómetro se reinicializa. En sí, la pequeña esfera está viajando por un victoroide. En graficación estas herramientas resultan muy útiles, ya que simplifican mucho los métodos convencionales y mejoran la calidad de las imágenes, con variedades u otras figuras topológicas. Para poder hacer cualquier simulador de física, matemáticas, biología, química o áreas afines, es necesario tener en cuenta estas características, ya que en muchos casos optimiza el funcionamiento del simulador. Ahorra muchos recursos de la máquina utilizar estos métodos, que tratar de emplear un espacio mucho mayor para tener cierta libertad al simular. La Topología, aunque tiene poco tiempo de existir, tiene muchas más aplicaciones y usos que los explicados, lo cual dificulta su explicación completa, ya que estos son muy complicados y requieren de conocimientos matemáticos avanzados. Haciendo este trabajo accesible a la mayor cantidad de gente posible, me limito a estas aplicaciones, ya que estas son de lo más variadas. Investigando estos datos, me encontré con esta fascinante idea: Un hipercubo dentro del ámbito de sistemas de información y bases de datos, significa un objeto multidimensional, en el que cada dimensión representa una variable, de forma que en este objeto se obtienen los valores relacionados de todas variables, asociadas a las dimensiones, simultáneamente. CONCLUSIONES: Esta tarea proporciona un visión mucho mas amplia de lo que es la estructura de datos, muestra diferentes usos y aplicaciones de las estructuras de dato.
BIBLIOGRAFÍA: PABLO GIL, Actualidad OLAP, Febrero 28 1998 http://sie.efpol.ua.es/webolap/glo.htm Webopedia http://www.webopedia.com/TERM/P/pipelining.html
|