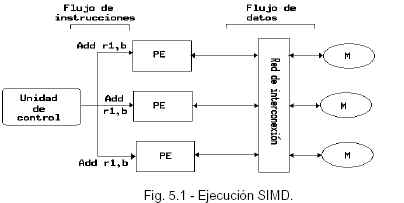
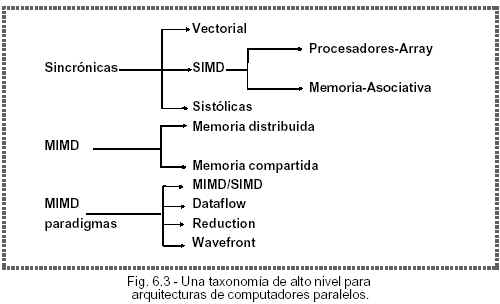
Paralelismo ALGORITHMS OF MASSIVE PARALELISM: El Proceso masivo en paralelo mediante redes neuronales artificiales. Permiten resolver problemas de forma adaptativa y no algorítmica. Adecuado para la resolución de problemas no estructurados: reconocimiento de voz, de patrones, corrección de errores, etc. Comienzan a aparecer neurocomputadores con coprocesadores asociados a ordenadores personales y estaciones de trabajo. También comienzan a estar disponibles lenguajes de alto nivel para la reconfiguración y redefinición de las redes neuronales. ARRAY PROCESORS: Es un grupo de unidades de cómputo cada una de las cuales realiza simultáneamente la misma operación sobre diferentes conjuntos de datos. Los procesadores array operan sobre vectores. Las instrucciones del computador vectorial son ejecutadas en serie (como en los computadores clásicos) pero trabajan en forma paralela sobre vectores de datos. Un array sincrónico de procesadores paralelos se denomina un Procesador Array, el cual consiste de múltiples Elementos de Procesamiento (PEs) bajo la supervisión de una unidad de control (CU). Un procesador array puede manejar un único flujo de instrucción y múltiples flujos de datos. En tal sentido los procesadores array son también conocidos como máquinas SIMD (Fig. 5.1). Los procesadores Array existen en dos organizaciones arquitecturales básicas:
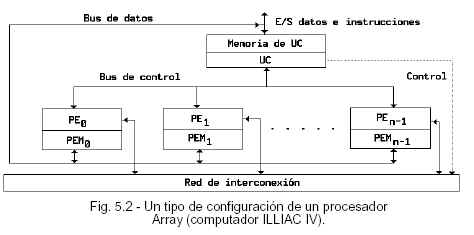
En general, un procesador array puede tener una de dos configuraciones ligeramente diferentes. Una ha sido implementada en la muy conocida computadora ILLIAC IV cuya esquematización puede verse en la Fig. 5.2. Esta computadora posee 256 PEs distribuidos en cuatro cuadrantes de 8 x 8 PEs.
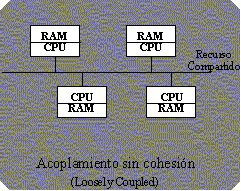
Los PEs de un cuadrante son controlados por una unidad de control común, como resultado de esto los PEs de dicho cuadrante pueden ejecutar la misma operación simultáneamente. Cada PE se comunica con su vecino, la mayor distancia entre dos PEs no vecinos es 8. La esquematización de la ILLIAC IV de la Fig. 5.2 está estructurada con N PEs sincronizados, los que se encuentran bajo el control de una CU. Cada PE es esencialmente una unidad aritmético y lógica (ALU) con registros de trabajo que le pertenecen y una memoria local (PEM) para el almacenamiento de los datos distribuidos. La CU cuenta también con una memoria propia para el almacenamiento de programas. En ella se cargan los programas del usuario desde el almacenamiento principal. La función de la CU es decodificar todas las instrucciones y determinar dónde deben ejecutarse las instrucciones decodificadas. Las instrucciones de control de tipos o las escalares se ejecutan directamente dentro de la CU. Las instrucciones vectoriales se envían a los PEs para una distribución de la ejecución a fin de alcanzar un paralelismo espacial. CLUSTERING: Clustering es el proceso de agrupar datos en clases o clusters de tal forma que los objetos de un cluster tengan una similaridad alta entre ellos, y baja (sean muy diferentes) con objetos de otros clusters. La medida de similaridad está basada en los atributos que describen a los objetos. Los grupos pueden ser exclusivos, con traslapes, probabilísticos, jerárquicos. Clustering puede ser aplicado, por ejemplo, para caracterizar clientes, formar taxonomías, clasificar documentos, etc. LOOSELY COUPLED: Es una de las tres arquitecturas básicas que permiten el multiprocesamiento:
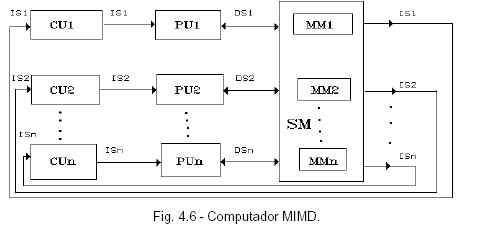
MIMD: MIMD o múltiples secuencias de instrucciones y datos (Multiple Instruction, Multiple Data): múltiples secuencias de instrucciones operan, simultáneamente, sobre múltiples secuencias de datos MIMD es el caso típico de un sistema de multiprocesamiento.Varias unidades de control, con varias unidades de ejecución. Es decir, se ejecutan muchas instrucciones con mucho datos, MIMD implica que múltiples procesadores ejecutan autónomamente diversas instruccionessobre diversos datos.
MULTIPROCESADORES (MIMD): Pueden clasificarse en esta categoría muchos sistemas multiprocesadores y sistemas multicomputadores. Un multiprocesador se define como una computadora que contiene dos o más unidades de procesamiento que trabajan sobre una memoria común bajo un control integrado. Si el sistema de multiprocesamiento posee procesadores de aproximadamente igual capacidad, estamos en presencia de multiprocesamiento simétrico; en el otro caso hablamos de multiprocesamiento asimétrico. Todos los procesadores deben poder acceder y usar la memoria principal. De acuerdo a esta definición se requiere que la memoria principal sea común y solamente existen pequeñas memorias locales en cada procesador. Si cada procesador posee una gran memoria local se lo puede considerar un sistema de multicomputadoras, el cual puede ser centralizado o distribuido. Todos los procesadores comparten el acceso a canales de E/S, unidades de control y dispositivos. Para el sistema de multiprocesamiento debe existir un sistema operativo integrado, el cual controla el hardware y el software y debe asegurar la interacción entre los procesadores y sus programas al nivel elemental de dato, conjunto de datos y trabajos. Una computadora MIMD intrínseca implica interacciones entre n procesadores debido a que todos los flujos de memoria se derivan del mismo espacio de datos compartido por todos los procesadores. Si los n flujos de datos provienen de subespacios disjuntos de memorias compartidas, entonces estamos en presencia del denominado operación SISD múltiple, que no es otra cosa que un conjunto de n monoprocesadores SISD. Una MIMD intrínseca está fuertemente acoplada si el grado de interacción entre los procesadores es alto. De otra manera consideramos el sistema como débilmente acoplado. Muchos sistemas comerciales son débilmente acoplados, a saber, la IBM 370/168, Univac 1100/80, IBM 3081/3084, etc.
PARADIGMAS BASADOS EN ARQUITECTURAS MIMD: Las arquitecturas híbridas MIMD/SIMD, las máquinas de Reducción, las arquitecturas Dataflow y los Wavefront array son arquitecturas igualmente difíciles de acomodar ordenadamente en una clasificación de las arquitecturas paralelas. Cada una de estas arquitecturas está basada en los principios de operación sincrónica y manejo concurrente de múltiples flujos de datos e instrucciones. Sin embargo cada una de ellas se basa, a su vez, en algún principio muy distintivo que se suma a las características propias de ser MIMD. Aún cuando la ejecución de los procesos en arquitecturas MIMD se sincroniza mediante el pasaje de mensajes por medio de una red de interconexión o accediendo a datos en unidades de memoria compartida, las arquitecturas MIMD son computadoras asincrónicas caracterizadas por un hardware de control descentralizado. La efectividad del costo de n Sistemas Procesadores respecto de n procesadores aislados alienta la experimentación en las MIMD. SISTEMAS DISTRIBUIDOS: Hemos dicho ya que los sistemas MIMD débilmente acoplados reciben también el nombre de Sistemas Distribuidos. Existen cuatro grandes razones para construir Sistemas Distribuidos, a saber:
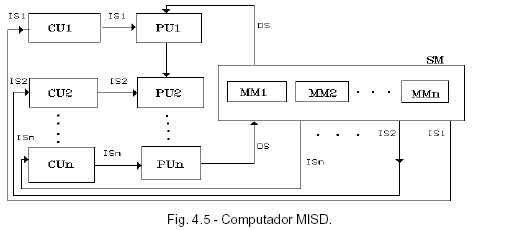
MISD: MISD o múltiples secuencias de instrucciones y única de datos (Multiple Instruction, Single Data): múltiples secuencias de instrucciones operan, simultáneamente, sobre una sola secuencia de datos (sin implementaciones útiles actualmente) Aquí se tienen varias unidades de control, con varias unidades de ejecución, existen distintos flujos de instrucciones y un único flujo de datos. MISD implica que muchos procesadores aplican diferentes instrucciones al mismo dato, esta posibilidad hipotética se considera generalmente impracticable.
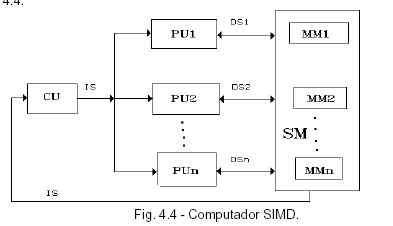
PIPELINE: Una pipeline es una serie de módulos que son capaces de ejecutar fases de instrucciones, si un procesador tiene dos pipelines puede ejecutar dos instrucciones en una sola fase en un momento dado, duplicando (otra vez en teoría) el rendimiento. En cada una de estas pipelines, Predication lanza cada uno de los dos flujos resultados de efectuar o no el salto. Al cabo de un momento, cuando ya se sabe el resultado, se anula el pipeline erróneo y el otro continúa. PROGRAMACION VECTORIAL Para mostrar los conceptos que se encuentran detrás de un procesador vectorial, vamos a presentar en primer lugar una breve muestra de cómo programar operaciones vectoriales sobre códigos FORTRAN. Un vector v, es una lista de elementos de la forma: v = (v1, v2, v3,..., vn)T La longitud del vector se define como el número de elementos en el vector, de forma que la longitud del vector v que acabamos de presentar es n. Cuando queremos representar un vector en un programa, se declara el vector como una matriz de una única dimensión. En FORTRAN, declararíamos el vector v mediante la expresión: DIMENSION V (N) En donde N es una variable entera que almacena el valor de la longitud del vector. Dos vectores se pueden sumar simplemente sumando cada una de sus componentes, es decir: s = x + y = (x1+ y1, x2+ y2, . . . , xn+yn) En FORTRAN, la suma de vectores se puede realizar utilizando el siguiente código: I=1, N DO S (I) = X(I) + Y (I) ENDDO Donde s es el vector en el que se almacena la suma final, y S, X, e Y han sido declarados como matrices de dimensión N. Elementos de la arquitectura vectorial Una computadora vectorial contiene un conjunto de unidades aritméticas especiales denominadas pipelines. Estas pipelines superponen la ejecución de las diferentes partes de una operación aritmética sobre los elementos del vector, produciendo una ejecución más eficiente de la operación aritmética que se está realizando. En muchos aspectos, una pipeline es similar a una cadena de montaje de una fábrica de coches, en la que los distintos pasos de la fase de montaje de un automóvil, por ejemplo, se realizan en distintas etapas de la cadena. Consideremos, por ejemplo, los pasos o etapas necesarias para realizar una suma en punto flotante en una máquina con hardware que emplee aritmética IEEE. Los pasos para realizar la operación s = x + y son: 1. Se comparan los exponentes de los dos números en punto flotante que se quieren sumar para encontrar cuál es el número de menor magnitud. 2. El punto decimal del número con menor magnitud se desplaza de forma que los exponentes de los dos números coincidan. 3. Se suman los dos números. 4. Se normaliza el resultado de la suma. 5. Se realizan los chequeos necesarios para comprobar si se ha producido algún tipo de excepción en punto flotante durante la suma, como un overflow. 6. Se realiza el redondeo. Registros vectoriales Algunas computadoras vectoriales, como el Cray Y-MP, contienen registros vectoriales. Un registro de propósito general o un registro de punto flotante contiene un único valor. Sin embargo, los registros vectoriales contienen en su interior muchos elementos de un vector al mismo tiempo. Por ejemplo, los registros vectoriales del Cray Y-MP contienen 64 elementos, mientras que los del Cray C90 contienen 128 elementos. Los contenidos de estos registros pueden ser enviados a (o recibidos por) una pipeline vectorial a razón de un elemento por paso temporal.. Registros escalares Los registros escalares se comportan de la misma forma que los registros de punto flotante, conteniendo un único valor. Sin embargo, estos registros se configuran de tal forma que pueden ser utilizados por una pipeline vectorial. En este caso, el valor del registro se lee una vez cada t unidades de tiempo y se introduce en el pipeline, de la misma forma que cada elemento de un vector se introduce en cada paso en la pipeline vectorial. Esto permite que los elementos de un vector puedan realizar operaciones con elementos escalares. Por ejemplo, para calcular el resultado de la operación y = 2.5x, el valor 2.5 se almacena en un registro escalar y se introduce en la pipeline de multiplicación cada t unidades de tiempo para ser multiplicado por cada uno de los elementos de x y así obtener el resultado en el vector y. Operaciones de dispersión y agrupamiento Algunas veces sólo son necesarios algunos de los elementos de un vector para realizar un cálculo. La mayoría de los procesadores vectoriales están equipados para poder recoger los elementos necesarios de un vector (una operación de recogida) y colocarlos juntos en un vector o en un registro vectorial. Si los elementos que se utilizan presentan un patrón de espaciado regular, el espaciado entre los elementos que se van a recoger se denomina desplazamiento o stride. Por ejemplo, si se quieren extraer los elementos: x1,x5,x9,x13 ,..., x4(n-1)+1 del vector (x1, x2, x3, x4, x5, x6,...,xn) para realizar algún tipo de operación vectorial, se dice entonces que el desplazamiento es igual a 4. Una operación de dispersión reformatea el vector resultante para que los elementos se encuentren espaciados correctamente. Las operaciones de dispersión y recogida también se pueden utilizar con datos que no se encuentran regularmente espaciados. Procesadores vectoriales de registro vectorial Si un procesador vectorial posee registros vectoriales, los elementos del vector que se van a procesar se cargan desde la memoria directamente en el registro vectorial utilizando una operación de carga vectorial. El vector que se obtiene a partir de una operación vectorial se introduce en un registro vectorial antes de que se pueda almacenar de nuevo en la memoria mediante una operación de almacenamiento vectorial. Esto permite que se pueda utilizar en otra operación sin necesidad de volver a leer el vector, y también permite que el almacenamiento se pueda solapar con otro tipo de operaciones. En este tipo de computadoras, todas las operaciones aritméticas ó lógicas vectoriales son operaciones registro a registro, es decir, sólo se realizan operaciones vectoriales sobre vectores que ya se encuentran almacenados en los registros vectoriales. Por este motivo, a estas computadoras se les conoce como procesadores vectoriales de registro vectorial. La figura 3 muestra la arquitectura de registros y pipelines de una computadora vectorial de registro vectorial. El número de etapas de cada pipeline se muestra entre paréntesis dentro de cada pipeline. Procesadores vectoriales memoria a memoria Otro tipo de procesadores vectoriales permite que las operaciones realizadas con vectores se alimenten directamente de datos procedentes de la memoria hasta los pipelines vectoriales y que los resultados se escriban directamente en la memoria. Este tipo de procesadores se conocen con el nombre de procesadores vectoriales memoria a memoria. Dado que los elementos del vector necesitan venir de la memoria en lugar de proceder de un registro, se requiere más tiempo para conseguir que la operación vectorial comience a realizarse. Esto es debido en parte al coste del acceso a la memoria. Un ejemplo de procesador vectorial memoria a memoria era el CDC Cyber 205. Debido a la capacidad de superponer el acceso a la memoria y la posible reutilización de los vectores ya utilizados, los procesadores vectoriales de registro vectorial suelen ser más eficientes que los procesadores vectoriales memoria a memoria. Sin embargo, a medida que la longitud de los vectores utilizados para un cálculo se incrementa, esta diferencia en el rendimiento entre los dos tipos de arquitecturas tiende a desaparecer. De hecho, los procesadores vectoriales memoria a memoria pueden llegar a ser más eficientes si la longitud de los vectores es lo suficientemente grande. Sin embargo, la experiencia ha demostrado que la longitud de los vectores suele ser mucho más corta de la necesaria para que esta situación llegue a producirse. Bancos de memoria entrelazados Para permitir un acceso más rápido a los elementos vectoriales que se encuentran almacenados en la memoria, las memorias de los procesadores vectoriales se suelen dividir en bancos de memoria. Los bancos de memoria entrelazados asocian de forma sucesiva las direcciones de memoria con bancos sucesivos de forma cíclica. De esta forma, la palabra 0 se almacena en el banco 0, la palabra 1 se almacena en el banco 1, ..., la palabra n-1 se almacena en el banco n-1, la palabra n en el banco 0, la palabra n+1 en el banco 1,..., etc., en donde n es el número de bancos de memoria. Como sucede con muchas otras características de arquitectura de computadoras, n es normalmente una potencia de 2: n= 2k, donde k = 1, 2, 3 ó 4. Un acceso a memoria (carga o almacenamiento) de un valor de datos en un banco necesita varios ciclos de reloj para llegar a completarse. Cada banco de memoria permite sólo que se lea o almacene un valor de los datos por cada acceso a memoria, mientras que se puede acceder a varios bancos de memoria de forma simultánea. Cuando los elementos de un vector que se almacena en una memoria entrelazada se trasladan al registro vectorial, las lecturas se reparten entre los bancos de memoria, de forma que un elemento vectorial es leído en cada banco por cada ciclo de reloj. Si un acceso a memoria precisa de n ciclos de reloj, entonces n elementos de un vector pueden ser leídos con el mismo coste del que sería necesario para un único acceso a memoria. Este procedimientos es n veces más rápido que el necesario para realizar el mismo número de accesos a memoria sobre un único banco. SIMD: SIMD o secuencia única de instrucciones y múltiple de datos (Single Instruction, Multiple Data): una sola secuencia de instrucciones opera, simultáneamente, sobre múltiples secuencias de datos (array processors). Este es el esquema más básico, de lo que comúnmente se conoce como un procesador vectorial. Que es capaz de tomar un vector o matriz, y simultáneamente, hacer muchas operaciones sobre él. SIMD implica que múltiples procesadores ejecutan simultáneamente la misma instrucción sobre diferentes datos.
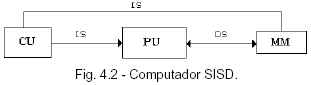
En una arquitectura SIMD el paralelismo se logra por múltiples unidades de proceso llamadas Elementos de Procesamiento (PEs), cada una de las cuales es capaz de ejecutar una operación especializada autónomamente. La arquitectura de los Array Processor y de los Procesadores Vectoriales SIMD se caracteriza por el hecho de que la misma operación es realizada en un momento dado sobre un gran conjunto de datos en todos los PEs. Las computadoras SIMD están especialmente diseñadas para realizar cómputos vectoriales sobre matrices o arrays de datos. Pueden utilizarse indistintamente los términos Procesadores Array, Procesadores Paralelos, y computadoras SIMD. SISD: Se refiere a las computadoras convencionales de Von Neuman. Ejemplo: PC’s. En la categoría SISD están la gran mayoría de las computadoras existentes. Son equipos con un solo procesador que trabaja sobre un solo dato a la vez. A estos equipos se les llama también computadoras secuenciales. SISD o secuencia única de instrucciones y datos (Single Instruction, Single Data): una sola secuencia de instrucciones opera sobre una sola secuencia de datos (caso típico de los ordenadores personales).
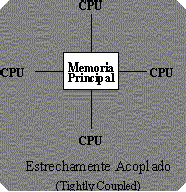
TIGHTLY COUPLED: Es una de las tres arquitecturas básicas que permiten el multiprocesamiento:
El Multiprocesamiento simétrico (symmetric multiprocessing / SMP) tiene un diseño simple pero aún así efectivo. En SMP, multiples procesadores comparten la memoria RAM y el bus del sistema. Este diseño es también conocido como estrechamente acoplado (tightly coupled), o todo compartido (shared everything). El multiprocesamiento simétrico (SMP) es una arquitectura computacional paralela en la cual los procesadores múltiples hacen funcionar una sola copia del sistema operativo y comparten la memoria con otros recursos de una computadora. Todos los procesadores tienen el mismo acceso a la memoria, entradas y salidas e interrupciones externas. CONCLUSIONES: A mi punto de vista lo relevante es la clasificación de los sistemas de procesadores y sus funciones en sistemas paralelos. A demás se me hace muy interesante la aplicacion del procesamiento masivo en paralelo para la neurocomputacion o sistemas neuronales. REFERENCIA: Pag: Materias del Departamento de Computación http://www.dc.uba.ar/people/materias/so/datos/ Ultima actualización: Marzo de 2000. Romo Proaño Marcelo “ARQUITECTURAS PARA MULTIPROCESAMIENTO” http://www.espe.edu.ec/websites/sistemas/tema/paralelo1.htm Pag: Sistema de Informacion de la Defensa Nacional http://www.mindefensa.gov.co/nuevoweb/GuiasEstudios/Informatica/Tecnologias/HW-ETMDN-SR-T.doc e-mail: [email protected] Ultima Actualizacion: 19 de Febrero de 2002. “Sistemas de Proceso en Paralelo” |