This section will represent a method used by David Endler for BSM data reduction and analysis, and an introduction to general learning methods using LNKnet as an example. Notes and information for each main section of the paper will be located in the appropriate section.
In the context of this section, we will be looking at the Histogram Classifier methods of the LNKnet software to take preprocessed BSM (text) data and return a useful model. Analysis is done in two steps - preprocessing the raw BSM data, and then feeding it into the software.
We start with a collection of raw BSM data which looks similar to:
header,61,2,AUE_GETAUDIT,,Fri Jan 21 14:24:51 2000, + 760212035 msecWe then assosciate each of the signals with a descrete number (this can be done in the praudit itself, but it would make the above data less interesting to look at). Signals which have a failed return value have a constant added to them to distinguish failed from sucessful return codes. For example, if there are 20 audited system calls, data would be recorded as one of 40 members of the data vector. i.e.: {1,2, ... ,20}=good return on call number n, {(1+20),(2+20), ... , (20+20)}= error return on call n. This information is condensed into a collumn containing the timestamp and the appropriate code. For example:
subject,-2,root,root,root,root,236,0,0 0 0.0.0.0
return,success,0
header,86,2,AUE_su,,Fri Jan 21 14:24:51 2000, + 770214107 msec
subject,-2,root,root,root,root,236,0,0 0 0.0.0.0
text,success for user root
return,success,0
header,100,2,AUE_CREAT,,Fri Jan 21 14:24:52 2000, + 770221200 msec
path,/devices/pseudo/mm@0:null
subject,-2,root,other,root,other,237,0,0 0 0.0.0.0
return,success,3
header,144,2,AUE_FCNTL,,Fri Jan 21 14:24:52 2000, + 770221200 msec
argument,2,0x1,cmd
path,/usr/aset/reports/0121_14:24/env.rpt
attribute,100666,root,root,22282250,298523,0
subject,-2,root,other,root,other,237,0,0 0 0.0.0.0
return,success,0
header,124,2,AUE_FCNTL,,Fri Jan 21 14:24:52 2000, + 780226869 msec
argument,2,0x1,cmd
path,/tmp/tmppath.197
attribute,100666,root,root,1,234896081,4294967295
subject,-2,root,other,root,other,238,0,0 0 0.0.0.0
return,success,0
16:47:36 260At this point we need to introduce the idea of a feature vector. In this case it is a collection of events expressed in a kind of data structure. For all you dorks out there, the structure is little more than a simple array:
16:47:36 73
16:47:36 113
16:47:36 113
16:47:36 24
16:47:36 73
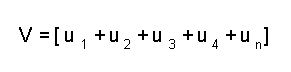
W1 = [ 260 73 113 113 24 ]With this window data, we create the vector that will be fed into the LNKnet software as training data. The individual feature vector (in this case V1), will similar to:
W2 = [ 73 113 113 24 73 ]
W3 = [ 113 113 24 73 112 ]
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0
Note that in this case I am copying the example from the Endler paper. Here there are 488 descrete states possible. With the current set of iEngineer data, this number will probibly be smaller since there is a trade off between .
The final thing to do to complete the feature vector, is classify the event pattern (ie the vector described in the mess of numbers above) as normal or abnormal systm behavior. This is done by prepending a 0 or 1 to the data listing.
All input features in the testing and training data were normalized to maintain stable and low output ranges for analysis. What data normalization means, is that the data vectors above are all made to a standard length. This is done by computing the length of the vector, and dividing each component by that length. For a little code showing how this works, look here.
The final training data file is then just a series of these feature vectors, which are normalized to allow for better data analysis.
Once the training file is created, LNKnet is used to build a histogram model whic h is representitive of a systems normal behavior. The testing data is then evaluated using the learned classifier model and the outputs for each pattern are extracted from the log file. Scatter plots are graphed with respect to time so that anomalous behavior patterns can be inferred from a low output value for the normal classifier.
A generic way to 'train' a system is to split your data up in to three working groups:
D. Endler. Intrusion detection: Applying machine learning to solaris audit data.
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
Useful notes, scripts and information
In a number of papers and books, there is not room enough to provide sample scripts, data and psudo-code. When ever possible, I will provide this information as I create it.
Related Links:
In Proceedings of the 1998 Annual Computer Security Applications Conference (ACSAC'98)
pages 268--279, Los Alamitos, CA, December 1998. IEEE Computer Society, IEEE Computer Society Press. Scottsdale, AZ.
PS version
James A. Anderson, An Introduction to Neural Networks.
The MIT Press, 1995.
LNKnet information, software and manuals can be found here.
Much newer paper on Adaptive Techniques for IDS from Sandia National Labs. Still reading, but good stuff. Look here for the PDF.