
El presente documento fue elaborado para fines docentes, muestra ejemplos
de aplicación sencilla que se utilizarán en el Laboratorio
de Estadística No. 2 por los alumnos de primer año de la
Facultad de Odontología de la Universidad de San Carlos de Guatemala.
Las marcas Kwikstat, DOS, Windows y Dbase son marcas registradas, se hace
referencia a las mismas sólo a manera de orientación. El
Kwikstat para DOS que se describe es una versión no registrada tomada
a manera de ejemplo bajo el concepto de Shareware, la Facultad de Odontología
o el Depto. de Estadística no poseen la versión registrada
de Kwikstat y no se utiliza para investigación institucional.
1. Introducción, Kwikstat y el concepto de Shareware.
2. Pantalla de introducción
3. Pantalla de inicio
4. Trabajando con bases de datos
5. Tipos de bases de datos
6. Ingreso de datos
7. Análisis de datos
8. Selección del grupo a analizar
9. Diagrama de Tallo y hojas
10. Selección de otro grupo a analizar
11. Estadística descriptiva
El Kwikstat es un programa para análisis estadístico basado en el sistema operativo DOS, que se distribuye a través del sistema de "Shareware", esto significa que es perfectamente válido instalar el programa para su evaluación en una computadora hasta por 30 dias, si el programa cumple con nuestras espectativas estamos obligados a pagar el precio de la licencia y generalmente con este pago se recibe una versión mejorada del programa, un manual impreso y asesoría telefónica sobre su instalación y desempeño.
Aunque el sistema DOS, se encuentra en la actualidad en desuso, puede ser ejecutado desde un ambiente "Windows", con la limitante de que en algunas computadoras no será posible imprimir desde el programa, sino que habrá que salvar los resultados a un programa de windows, para poder imprimirlo.
En el curso de estadística básica en la Facultad de Odontología de la Universidad de San Carlos de Guatemala, se optó por utilizar esta versión no registrada de Kwikstat para darle a los alumnos una aproximación sobre el trabajo con un paquete de análisis estadístico, por el coste que implica la implementación de un laboratorio con versiones registradas de windows y un paquete estadístico para ambiente windows. La intención del uso de este programa no es lucrativa ni para investigaciones institucionales.
Las pantallas del programa que se reproducen en el presente manual básico son del propio programa, reproducidas para docencia, en ningun momento este manual busca suplir el manual original del programa, y si alguna persona se encuentra interesada en la versión registrada de Kwikstat debe ponerse en contacto directamente con TexaSoft, que es la compañia que produce el programa a la dirección que se muestra en la figura 1.
La Facultad de Odontología y el Depto. de Estadística NO poseen la versión registrada de Kwikstat y pueden proporcionar a quien esté interesado únicamente la versión de evaluación bajo el concepto de "Shareware" y la obligación de desinstalar la misma en un plazo máximo de 30 dias.
Al iniciar el programa nos presenta una pantalla de introducción donde se especifíca que el programa se distribuye a través del sistema de "Shareware" y la dirección a donde podemos comunicarnos para obtener una versión registrada o de ambiente windows. Para iniciar nuestro trabajo en el programa debemos oprimir [ENTER] una vez.
Fig. 1
Esta es la pantalla de inicio, desde donde seleccionamos una base de datos ya existente, o crear una base de datos nueva.
El Kwikstat, a pesar de ser un programa de DOS, no utiliza códigos que deben memorizarse, sino que utiliza un desplazamiento por medio de menus, y apoya el uso de punteros como el mouse, por lo que resulta muy similar a la manera de desplazarse en un programa de Windows.
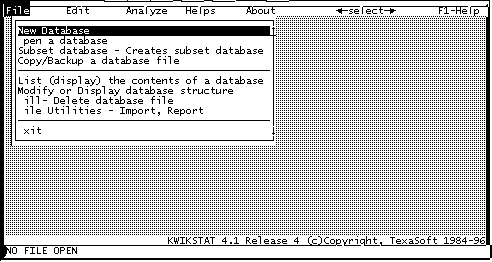
Fig. 2
Los tres menús principales son:
"Edit", en donde modificamos la estructura de una base de datos con la que estemos trabajando, modificar campos (fields), eliminar registros, etc.
"Analyze", donde tenemos todas las opciones de análisis estadístico del que dispone el programa, este menú se expone más adelante.
Una base de datos no es mas que un archivo donde se almacenan los registros individuales de una serie de observaciones en espacios específicos que se denominan campos (fields).
Si se desea iniciar una base de datos nueva, debemos seleccionar la primera opción del menu "File", que es "New database" (Fig. 2).
El siguiente paso es nombrar nuestro archivo de la base de datos. Para colocarle nombre se deben respetar las limitantes que impone el sistema operativo, debe usarse un nombre con un máximo de 8 letras o caractéres que se utilicen en el idioma inglés, no debe tener espacios entre las letras ni signos especiales, de preferencia no debe iniciar con un número y no es conveniente usar letras tildadas o ñ. (Fig.3)
El programa automáticamente agregara un punto y una extensión que consiste en tres letras ".DBF", que identifica al archivo como compatible con DBASE, que es una base de datos muy difundida en el ambiente DOS. Esta extensión no debe modificarse, o el programa será incapaz de reconocer el archivo.
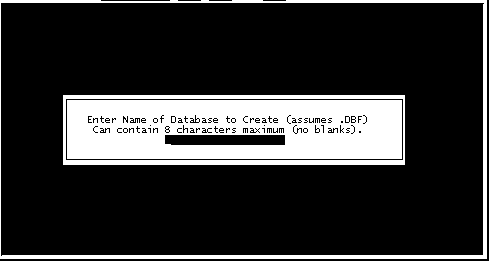
Fig. 3
Una vez nombrado el archivo de la base de datos, debemos especificar que tipo de base de datos vamos a utilizar, el programa Kwikstat incluye una serie de tipos preestablecidos en los cuales podemos buscar el que más se ajuste a nuestras necesidades (Fig. 4.), o fabricar uno "a la medida" de nuestras necesidades (Create a customized database).
Si nosotros iniciamos un archivo adaptado a nuestras necesidades (customized), el programa nos permite nombrar los campos vamos a utilizar (fields), y definir el tipo de variables que ubicaremos en ellos, si son variables númericas (numeric), cardinales u ordinales, o si son variables nominales (Char/Text), generalmente para agrupación de valores. (Fig. 4, 5 y 6)

Fig. 4
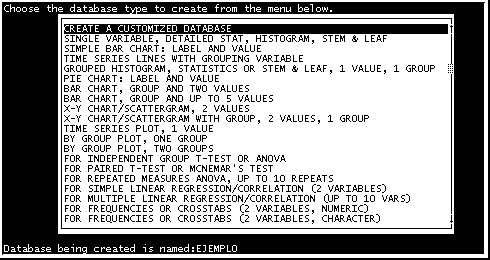
Fig. 5
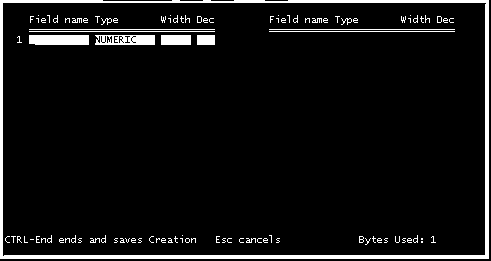
Fig. 6
El nombre del campo (Field name), sigue las mismas limitaciones que los nombres de los archivos en DOS (Ver "Trabajando con base de datos), para seleccionar el tipo de campo (Type), escribimos una "N" para una variable numérica (Numeric), o una "C" para una variable nominal (Char/text). El tamaño del campo (Width), determina el número de dígitos o caracteres (letras) que se pueden ubicar en el mismo. Si el campo es numérico, tambien debe definirse el número de decimales que se trabajaran (Dec), generalmente se ubican 2, pero esto depende de la exactitud de la medición, si no existen decimales puede escribirse el 0 o dejar el espacio en blanco. Siempre es recomendable el dejar un espacio más al que se estima será nuestro máximo, ya que modificar la estructura de la base de datos resulta un proceso un poco complicado, por lo que si trabajaremos con números enteros y el máximo esperado es 999, siempre es recomendable el dejar un tamaño del campo de 4.
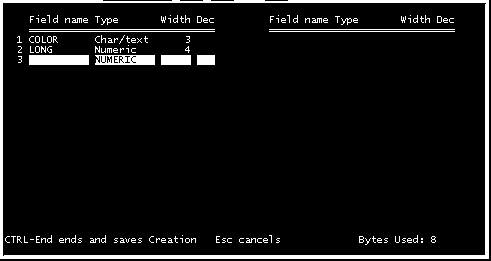
Fig. 7.
Una vez que definimos los campos a utilizar, debemos iniciar el ingreso de los registros. Simplemente nos ubicamos en el primer campo, ingresamos el dato que corresponde al mismo y oprimimos enter, luego lo repetimos en el segundo campo y así sucesivamente hasta ingresar el último de los registros que tenemos.
En la Figura 8, se muestra un ejemplo de dos variables, una nominal (color Blanco) que se identifica con una B y una numérica (longitud). Para finalizar el ingreso de los datos oprimimos [F7], dentro de las teclas de función que se encuentran en la parte superior del teclado, o seleccionamos "7 Exit" con el mouse en la parte inferior de la pantalla.

Fig. 8.
Una vez que hemos ingresado todos los registros en nuestra base de datos, utilizamos el menu "Analyze" para el análisis de los datos. (Fig. 9).
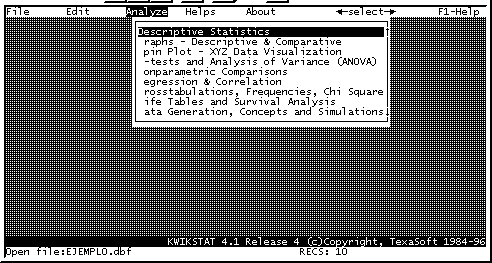
Fig. 9
Si la variable a analizar es solamente una, entramos directamente a Estadística Descriptiva ( Descriptive Statistics). Si, como es más común, la variable que queremos analizar se encuentra asociada a otra variable, como por ejemplo grupo, color o sexo, debemos filtrar que grupo vamos a analizar. Esto lo hacemos editando los registros de la base de datos (Modify/Edit database records) (Fig. 10).
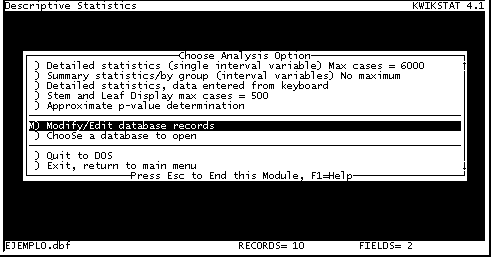 Fig. 10
Fig. 10
Para analizar un grupo debemos primero marcar el resto de los grupos, para que el programe los ignore al momento de realizar los cálculos de estadística descriptiva.
Así nos ubicamos en el grupo que vamos a ignorar en el análisis. En la Figura 11 se muestra un ejemplo de dos grupos (grupo 1 y grupo 2), se desea analizar el grupo 1, por lo que nos ubicamos sobre el primer registro del grupo 2 y marcamos este grupo para ignorarlo. Esto se hace a través de la opción "borrar" (Delete), [F3] o seleccionando con el mouse en la pantalla sobre " 3Delete".
Aunque la opción se llame borrar, esta es una infortunada herencia de la forma como funcionaba DBASE, sin embargo los datos no son borrados, sino únicamente ignorados, por lo que no hay que preocuparse por perder información
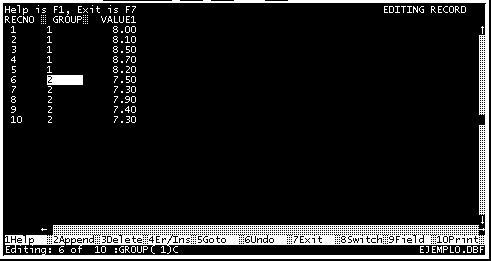 Fig. 11
Fig. 11
Al oprimir [F3] o "3Delete" se abre un submenu como se muestra en la Figura No. 12.
En este submenu escogemos la opción, "Marque todos los registros para borrado donde el grupo =2" (Mark all records for delete where GROUP=2). Aquí GROUP es el nombre del campo y "2" es el valor del registro en donde se encuentre ubicado el cursor al momento de oprimir el [F3], cuando se trabaje en otra base de datos apareceran los valores correspondientes del campo y el registro. Por ejemplo "COLOR = B".
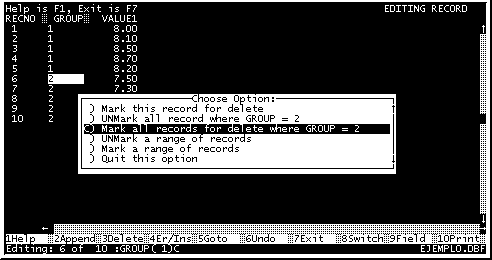
Fig. 12
Los registros marcados para ser ignorados, se identifican por un asterísco colocado al lado izquierdo de los mismos. Solo se analizarán los registros que no estén marcados. (Fig. 13)
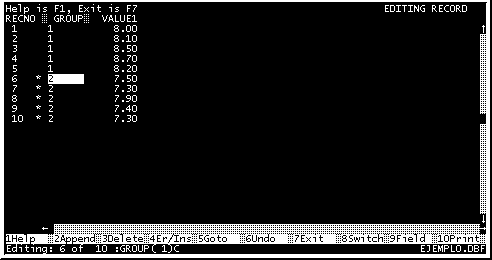
Fig. 13.
Para elaborar un diagrama de tallo y hojas en el grupo 1, que no está marcado para ser ignorado (Fig. 13), debemos regresar al menú de Estadística Descriptiva (Descriptive Statistics), oprimiendo la tecla [F7] o seleccionando "7 Exit" con el mouse.
Luego seleccionamos Diagrama de Tallo y Hojas (Stem and Leaf Display) (Figura 14).
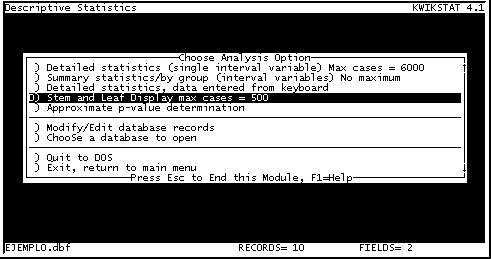
Fig. 14
Esto nos lleva a la pantalla del Diagrama de Tallo y Hojas (Figura 15). Aquí nos preguntará el programa si queremos modificar el límite máximo o mínimo de los datos, en el caso de que existiera algun valor extremo que perjudicara el diagrama. Por lo general no modificamos los límites y sólo oprimimos ENTER para aceptar los valores por omisión.
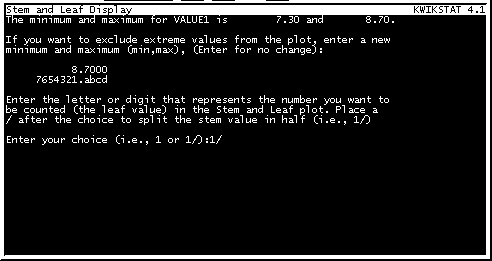
Fig. 15
El programa tambien nos pregunta si deseamos hacer el diagrama con los intervalos completos, o con los intervalos divididos en dos (como se realizaron en el diagrama 1 y 2 del laboratorio No. 1, respectivamente). Esto lo seleccionamos colocando un "1", para que tome los intervalos según la unidad, es decir sin dividir, o colocando un "1/" para que nos divida los intervalos en dos partes. Lo general es que los hagamos con el intervalo dividido en dos por lo que seleccionamos la opción " 1/ ". El programa elaborará el diagrama de Tallo y Hojas, en donde podemos ver la frecuencia individual de los datos y calcular la moda. Un ejemplo se muestra en la Figura No.16.
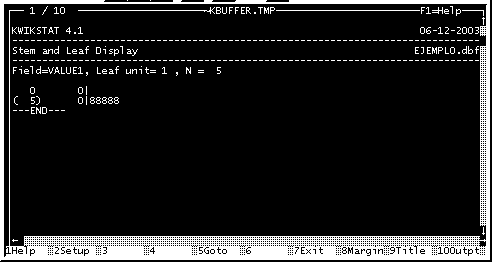 Fig. 16
Fig. 16
10. Selección de otro grupo a analizar
Si nosotros desearamos el diagrama de Tallo y Hojas en el grupo No.2, primero debemos "deseleccionar" o desmarcar el grupo que se está ignorando y luego marcar el grupo que se analizó con anterioridad, es decir en el ejemplo, desmarcar el grupo 2 y marcar el grupo 1.
Para hacer esto regresamos a la pantalla de edición de los registros de la base de datos (Modify/Edit database records) (Fig. 10).
Nos posicionamos sobre el primer registro del grupo marcado y oprimimos [F3] o con el mouse "3Delete", (Fig. 17).
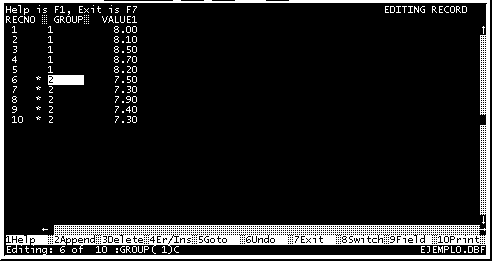 Fig. 17
Fig. 17
Luego en el submenu de borrado de registro, seleccionamos la opción "Desmarcar todos los registros donde grupo=2" (UNMark all record where GROUP = 2) , recuerde que "GROUP" y "2" dependen de la base de datos que se esté trabajando. (Fig. 18).
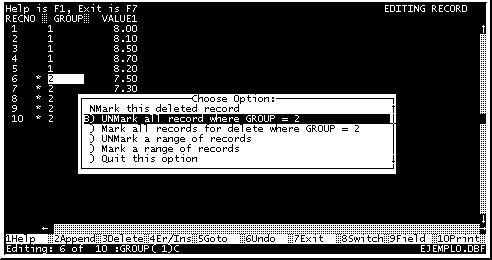
Fig. 18
Una vez que desmarcamos los registros que deseamos analizar, marcamos todos los otros (en este caso el grupo 1) para que no sean analizados como se describió anteriormente (Figuras del 10 al 13) y se repite el proceso para elaborar el Diagrama de Tallo y Hojas.
Para calcular las estadísticas descriptivas del grupo seleccionado, procedemos al menu de Análisis (Analize) y en el submenu de Estadística Descriptiva (Descriptive Statistics), aquí nos aparece otra serie de opciones de las cuales escogemos la primera, Estadística detallada (Detailed statistics), (Fig.19).
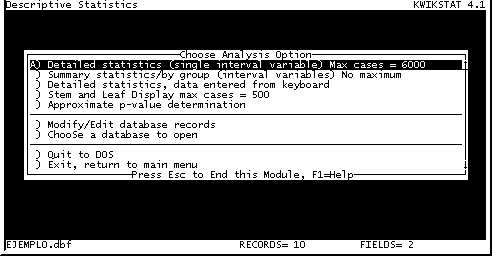
Fig. 19
El programa nos pide que seleccionemos una variable a analizar, únicamente se pueden analizar las variables numéricas, las variables nominales son variables de agrupación. En este ejemplo la variable a analizar se llama "VALUE1", (Fig. 20).
Fig. 20
El programa corre todas las estadísticas descriptivas para la variable y presenta un desplegado similar al que se presenta en la Figura 21.
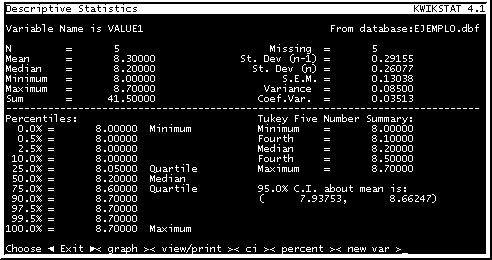
Fig. 21
En el desplegado se presenta, en orden descendente:
N : El número de datos que se está analizando.
Mean : Media Aritmética.
Median: Mediana de los datos.
Minimum y Maximum: Límite inferior y Límite superior.
Sum: La sumatoria de los datos.
Missing: Datos no tomados para análisis.
St. Dev (n-1): Estadístico de la Desviación estándar (muestra).
St. Dev (n): Parámetro de la Desviación estándar (población).
S.E.M.: Error estándar de la muestra.
Variance: Varianza calculada en base al estadístico (n-1).
Coef.Var. : Coeficiente de variación.
En la parte inferior, se presentan los percentiles y cuartiles, los números de Tukey, para el diagrama de Tukey y los intervalos de confianza al 95%.
El menú inferior se utiliza para: "Exit" para salir de la pantalla; "graph" para elaborar una grafica y estimar sesgo y curtosis; "view/print" para imprimir los resultados; "ci" para especificar los límites de los intervalos de confianza; "percent" para el cálculo de percentiles específicos y "new var" para seleccionar una nueva variable.
Al seleccionar la opción "graph" para elaborar la gráfica de la distribución, oprimiendo la tecla "g" o seleccionando con el mouse, se presenta un histograma similar al presentado en la Figura No.22
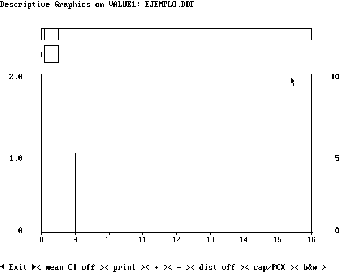
Fig. 22
En este desplegado tenemos las opciones "< mean CI off >", que dibuja una curva con la estimación del comportamiento del grupo, en la que podemos darnos una idea general de la asimetría y la curtosis. La opción "< print >" para imprimir el resultado. "< + >" para aumentar el número de intervalos, "< - >" para disminuir el número de intervalos. "<dist.off>", nos oculta el histograma y nos presenta una gráfica de frecuencias acumuladas. "< cap/PCX >", captura la imagen en un formato PCX, que puede ser importado a otro programa en ambiente windows. "< b&w >", elimina los colores y nos presenta la gráfica en blanco y negro, para facilitar su impresión.
El programa tiene muchas más características y funciones, la cuales se utilizan en la misma forma que la descrita en estos ejemplos. Para una revisión más detallada de todas las capacidades del programa, puede consultarse la ayuda del programa desde el menú principal, en donde se detallan los procedimientos a utilizar en las distintas funciones (en inglés). El programa también cuenta con un "tutorial" para introducirnos en el manejo del programa.