 |
|
Introduzione alle reti neurali
| Le reti neurali (o neuronali) sono una
delle aree più interessanti della ricerca in
Intelligenza Artificiale. Nonostante la loro ideazione
risalga ai primi anni '60, solo di recente si sono avuti
notevoli risvolti applicativi e teorici. L'idea che sta alla base delle reti neurali è quella di "imitare" in funzionamento del cervello, utilizzando un certo numero di semplici elementi di calcolo fortemente interconnessi tra loro per elaborare dati. Gli elementi di calcolo semplici vengono chiamati neuroni. In una rete neurale alcuni neuroni sono utilizzati come ingressi, altri come uscite, altri ancora (non sempre presenti) non sono connessi con l'esterno e svolgono una funzione di "calcolo" e vengono chiamati neuroni "nascosti" (hidden). |
 |
La grande differenza rispetto ad
altri sistemi di calcolo consiste nel fatto che la rete non è
programmata per svolgere un determinato compito, ma viene "addestrata"
mostrandole degli esempi (sotto forma di coppie ingresso-uscita),
la rete impara così ad associare ad ogni ingresso un'uscita e
anche in una certa misura a generalizzare quello che ha imparato
per ingressi che non le erano stati presentati in fase di
addestramento. Così per ottenere l'uscita voluta è sufficiente
che l'ingresso "somigli" a quello originario. Questa
proprietà rende le reti neurali adatta a tutti i compiti che
hanno a che fare con il riconoscimento e classificazione di input
(caratteri, immagini, suoni...).
Le capacità della rete sono determinate sia dal numero di
neuroni, sia soprattutto dalla topologia (cioè da come sono
collegati tra loro i neuroni).
Esistono infinite topologie possibili, ma le più utilizzate si
possono schematizzare in due classi: le reti alimentate in avanti
(feed forward) e le reti ricorrenti (o ricorsive). Nelle
prime non esiste nessun collegamento che riporti in qualche modo
le uscite in ingresso, questo le rende abbastanza semplici da
studiare ed addestrare ma non gli permette di mantenere uno
"stato" interno, cioè una memoria di quello che è
successo nel passato. Questo tipo di rete è il più studiato ed
utilizzato.
Le reti ricorrenti hanno delle capacità più estese però non
sono state in generale ancora ben comprese e non si conosce
sempre un metodo adatto per addestrarle.
Percettrone multi livello (Multi
Layer Perceptron)
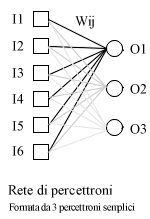
Una delle reti di più utilizzate è il cosiddetto "percettrone multi livello".
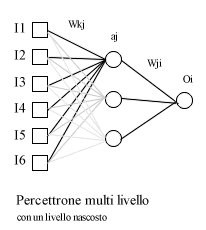 |
Questa rete ha uno strato di neuroni di ingresso, uno
strato di neuroni di uscita, e a volte uno o più strati
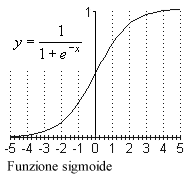
di neuroni nascosti. Per addestrare la rete si fanno variare i coefficienti associati a ciascun collegamento (è questo che rende possibile l'apprendimento nella rete). Ogni neurone riceve diversi ingressi ed ha una sola uscita (la cosiddetta "attivazione" del neurone) che è funzione degli ingressi. Per permettere alla rete di apprendere funzioni non lineari è necessario usare una funzione non lineare. Le funzioni più utilizzate sono la funzione "gradino", e la funzione "sigmoide" (nota anche come funzione di Fermi). La prima viene utilizzata quando è necessaria una risposta "digitale" (cioè di tipo on/off), la seconda quando invece l'uscita deve assumere valori continui compresi in un intervallo limitato. |
| Tipicamente l'argomento della funzione di attivazione
è la somma degli ingressi del neurone pesati ciascuno
col peso della connessione corrispondente. Le attivazioni dei neuroni d'ingresso sono gli input (vengono imposte dall'esterno, in un certo senso non sono quindi dei veri neuroni...), l'attivazione dei neuroni d'uscita rappresenta l'uscita della rete. Ottenere il valore dell'uscita dati gli ingressi si riduce a fare propagare in avanti il segnale, cioè a calcolare in successione tutte le varie attivazioni partendo dagli ingressi. |
 |
L'addestramento della rete risulta un pò più complesso: all'inizio
la rete non contiene nessuna informazione, si assegnano i valori
dei pesi in modo casuale (ad esempio con valori compresi tra -0.5
e 0.5), successivamente si presentano gli ingressi, si calcola l'uscita
della rete, si calcola l'errore, come differenza tra il valore
ottenuto e i valori che si volevano, e si aggiustano i pesi in
modo da fare diminuire l'errore.
Per aggiustare i pesi esistono diverse regole a seconda del tipo
di rete, per una rete senza strati nascosti si utilizzano la
formula seguente:
![]()
dove Wj è il peso del collegamento j-esimo, alfa
è una costante chiamata "velocità di apprendimento" (learning
rate), Ij è l'ingresso j-esimo, T è l'uscita i-esima desiderata
e O è l'uscita i-esima della rete. La costante alfa viene
utilizzata per diminuire la velocità di convergenza, in modo da
limitare oscillazioni attorno al minimo di errore (l'errore è
rappresentato da T-O).
Reti di questo tipo con funzioni di attivazione lineari (chiamate
adalines) vengono impiegate spesso nel riconoscimento
dei caratteri o nella costruzione di filtri adattivi.
Se la rete contiene strati di neuroni nascosti è
necessario utilizzare per l'addestramento la tecnica di "backpropagation",
grazie alla quale si riesce a suddividere l'errore all'uscita tra
i neuroni dei livelli nascosti e quindi a variare i pesi in modo
da minimizzare l'errore. Per maggiori informazioni consultare la
bibliografia o i links.
Nell'addestramento di una rete neurale è importante presentare tutte le coppie di ingresso-uscita diverse volte. Ciascuna presentazione viene chiamata "epoca" di addestramento. Se l'addestramento procede correttamente ad ogni epoca l'errore (quadratico) medio su tutte le uscite dovrebbe diminuire.
L'algoritmo di addestramento può essere schematizzato come segue:
Ripeti per n epoche
Per ogni esempio di addestramento
Presenta ingressi
Propaga in avanti
calcola errore (T-O)
Ritocca pesi
Fine ciclo esempi
Fine ciclo epoche
Per utilizzare una rete neurale nella risoluzione di un particolare problema è opportuno cercare di identificare gli ingressi e le uscite che riescano a caratterizzare bene il problema. Riguardo alla topologia della rete da usare non si può dire molto, in quanto non sono ancora disponibili teorie riguardo al numero ottimale di neuroni e collegamenti da utilizzare. Un risultato importante è che le reti con un solo livello nascosto riescono a rappresentare tutte le funzioni continue, mentre le reti con due livelli riescono a rappresentare anche quelle discontinue. Le prestazioni di tutte le reti neurali dipendono molto dal set di addestramento: più il set è rappresentativo del problema e più è completo più le prestazioni saranno migliori e la anche la capacità di generalizzare della rete sarà migliore.
Esempio. La rete della prima figura è un rete
che viene utilizzata di solito nel riconoscimento di caratteri.
In questo caso numero delle uscite sono tante quante i caratteri
da riconoscere (un neurone per ogni carattere). Gli ingressi
ricevono la luminosità media di un certo numero di aree dell'immagine
(normalmente disposte a griglia). Il neurone che ha attivazione
più alta in uscita viene considerato come risposta della rete.
Atri
tipi di reti neurali
Tra i numerosi tipi di reti neurali esistenti sono da ricordare
le reti di Hopfield e le self organizing nets di Kohonen.
Le prime sono delle reti ricorrenti formate da un solo strato di
neuroni. Ciascun uscita è collegata agli ingressi di tutti gli
altri neuroni. Questa rete viene addestrata utilizzando delle
particolari formule lineari e può funzionare come rete auto
associativa. Dopo la fase di allenamento la rete è in grado di
riconoscere una configurazione che ha imparato (anche se
parzialmente corrotta) e di presentare in uscita la versione
originale (quindi integra). La rete viene utilizzata ad esempio
per riconoscere immagini ad un solo bit colore. Un risultato
teorico interessante è che la rete può memorizzare in maniera
affidabile fino a 0.138N esempi, dove N è il numero di neuroni
della rete.
Le reti di Kohonen invece costituiscono un esempio di reti che
sono in grado di apprendere senza bisogno di supervisione, cioè
hanno la capacità di ricevere diverse configurazioni in ingresso
e di classificarle per somiglianza. Anche in questo caso le
formule usate nell'addestramento sono diverse da quelle usate per
i percettroni.
Interessa una libreria che implementa una rete neurale? Clicca quì!
Casa dolce casa! |