

ELABORADO POR: Rosanna Medina
Adriana Fraga
Blanca Brito
Betsy Arguelles
Gerardo Durante
![]()
ALCANCE DEL TRABAJO:
Análisis
Bivariable Lineal
2. Modelos de regresión bivariable
lineal
3. Estimación de parámetros de
regresión
4. Varianza de la regresión de la
muestra
5.
Inferencias acerca de los coeficientes de
regresión de la población
6.
Predicción y Pronosticación
8.
Coeficiente de correlación de la muestra
9.
Coeficiente de determinación y análisis
de varianza en regresión lineal
11. Coeficiente de
correlación por calificación
12. Conclusiones
1.
Asociación entre Variables:
Analizar
las relaciones entre variables
Si dos variables evolucionan modo tal
que en alguna medida se siguen entre ellas, podemos decir que existe una asociación
o covarianza estadística entre
ellas. Por ejemplo, la altura y peso de la gente están estadísticamente
asociadas: aunque el peso de nadie esté causado por su altura ni la altura por
el peso es, no obstante, habitual que las personas altas pesen más que las
personas bajas. Por otro lado los datos habitualmente incluyen también
excepciones, lo que significa que una asociación estadística es inherentemente estocástica.
La ciencia de la estadística ofrece
numerosos métodos para revelar y presentar las asociaciones entre dos y hasta
más variables. Los medios más simples son los medios de presentación gráfica y
tabulación. La intensidad de la asociación entre variables puede también
describirse como una estadística especial, como el coeficiente de contingencia y una correlación para lo que hay varios métodos de
análisis disponibles.
Si, al analizar
los datos, se descubre alguna asociación entre las variables, el investigador
quisiera a menudo saber la razón de esta asociación en el mundo empírico, es
decir él quisiera explicar esta asociación. Los tipos usuales de explicación
se enumeran en la página Descripción y Explicación. Común a todos es
que dan la causa
del fenómeno se está estudiando que. Cuando las medidas se han hecho de una
serie de estos fenómenos, es usual que una serie de medidas, llamada variable independiente,
se hace así de la causa presumida, y una otra serie de medidas, la variable dependiente,
del efecto presumido en el fenómeno.
Nota que no hay métodos en el
análisis estadístico para la tarea de descubrir la explicación causal para una
asociación estadística. Una fuerte correlación entre, digamos, A y B, puede
deberse a cuatro razones alternativas:
- A es la causa de B.
- B es la causa de A.
- Tanto A como B son causadas por C.
- A y B no tienen nada que ver con uno al otro. Su asociación en los
datos analizados está una coincidencia.
Se debe encontrar así la causalidad o la
otra explicación para la asociación de las variables en alguna otra parte que
en las medidas. En muchos casos, la teoría original del investigador puede
proporcionar una explicación; si no, el investigador debe usar su sentido común
para clarificar la causa.
A continuación mencionamos algunos
métodos usuales de análisis estadístico que pueden usarse al estudiar la
interdependencia entre una o más variables. Los métodos han sido dispuestos
siguiendo a qué escala de medición corresponden la mayor parte
de las variables.
|
Presentar datos y su estructura a grandes rasgos |
||||
|
Medir la fuerza de la asociación entre dos variables |
||||
|
- |
||||
|
- |
- |
|||
|
Encontrar qué variables entre varios son asociadas: |
Calcular contingencias o correlaciones para todos los pares de
variables ; análisis factorial |
|||
|
Transcribir una asociación estadística en una función
matemática: |
- |
- |
||

2.
Modelos de Regresión Bivariable Lineal
Consideremos la variable bidimensional (X,Y) , y sea E(Y/X) la regresión del
promedio de Y sobre X , cuya forma dependerá de la relación existente entre las
variables. En este capítulo nos limitaremos a las funciones de regresión que
son lineales en los parámetros (o coeficientes).
Si la distribución de (X,Y) es Normal bivariada, entonces
las funciones condicionales de probabilidad son también normales; es decir:
dado un valor fijo X=x , la variable Y
se distribuye en forma normal con media
E(Y/X) = ![]() + b.X y con
variancia V(Y/X) = constante, lo que significa, que no depende
del valor X=x.
+ b.X y con
variancia V(Y/X) = constante, lo que significa, que no depende
del valor X=x.
La diferencia que existe entre el valor que toma la variable
Y (dado que X=x) y la esperanza
condicional E(Y/x) se denomina residuo , desvío o error , y representa la parte aleatoria . En otras palabras, si (xi , yi )
es el valor que asume la variable bidimensional (X,Y), el residuo será ![]() = yi -
E(Y/xi ) , y por lo tanto yi = E(Y/xi )
+
= yi -
E(Y/xi ) , y por lo tanto yi = E(Y/xi )
+ ![]() i .
i .
Considerando una relación lineal entre las variables, esto significa que yi= ![]() + b.xi + ei
+ b.xi + ei
Donde ![]() + b.xi = E(Y/xi ) es la parte sistemática o
determinística (sólo depende del valor x ), y
+ b.xi = E(Y/xi ) es la parte sistemática o
determinística (sólo depende del valor x ), y ![]() es la parte aleatoria sobre la cual se
establecerán condiciones o restricciones que determinan el comportamiento de la
variable Y. Este modelo supone que para cada valor fijo x , existe una distribución de valores de la
variable Y .
es la parte aleatoria sobre la cual se
establecerán condiciones o restricciones que determinan el comportamiento de la
variable Y. Este modelo supone que para cada valor fijo x , existe una distribución de valores de la
variable Y .
En este modelo identificamos las siguientes componentes:
a y b: parámetros poblacionales
X: variable
"explicativa"
Y: variable
"explicada"
e: Error residual
Este residuo ei se compone esencialmente de
errores casuales, debida a la propia aleatoriedad de cada individuo, pudiendo
incluir errores de medición como también deficiencias del modelo debidas, por
ejemplo, a variables no consideradas en dicho modelo. En otras palabras, ei es la parte de yi que no está explicada por la regresión lineal
de Y
sobre xi. Este modelo supone una
distribución Normal de los errores o residuos, con media E(ei) = 0 y variancia constante V(ei) = s2 , e independencia
entre los errores.
Estos supuestos sobre los errores implican supuestos sobre el
modelo de regresión:
ü
La variable
"explicativa" X toma valores predeterminados por el
investigador.
ü
Para cada valor
fijo de X , la variable Y se
distribuye en forma normal .
ü
La relación entre
las variables X e Y es lineal , es decir, la regresión del promedio
es lineal Simbólicamente : E(Y/X) = ![]() + b.X , ya que E(e) = 0
+ b.X , ya que E(e) = 0
ü
Homocedasticidad,
o sea: V(Y/X) = s2 = constante, no depende del valor de X , ya que la variancia de los errores
es constante.
La violación de supuestos se refiere
a:
ü
Auto correlación
entre los errores o dependencia
entre los errores.
ü
Heterocedasticidad,
lo que significa que la variancia del
error o residuo depende del valor de x , y trae como consecuencia que la
variancia de Y condicionada a un valor
de X tampoco es constante sino que depende de dicho valor. O sea: V (Y/x) =
H(x) =
V (e/x).
ü
Distribución no
normal de los errores o residuos.
ü
X es variable aleatoria , lo que significa que
no han
sido predeterminados los valores de
X
La hipótesis de distribución normal de los errores y la de homocedasticidad traen como
consecuencia inmediata la distribución
normal de la variable Y condicionada a un valor fijo X = x.
La inferencia estadística se ocupa de estimar los
parámetros de la población bivariada (como así también los de la recta de
regresión) en base a los resultados obtenidos a través de una muestra
aleatoria.
3.
Estimación de
parámetros de regresión
Estimación de los parámetros de
la recta de regresión. El primer
problema a abordar es obtener los estimadores de los parámetros de la recta de regresión, partiendo de una
muestra de tamaño n, es decir, n pares (x1, Y1), (x2,
Y2),..., (xn, Yn); que representan
nuestra intención de extraer para cada xi un individuo de la
población o variable Yi.
Una vez realizada
la muestra, se dispondrá de n pares de valores o puntos del plano (x1,
y1), (x2, y2),..., (xn,
yn). El método de estimación aplicable en regresión, denominado
de los mínimos cuadrados, permite esencialmente determinar la recta que
"mejor" se ajuste o mejor se adapte a la nube de n puntos. Las
estimaciones de los parámetros de la recta de regresión obtenidas con
este procedimiento son:
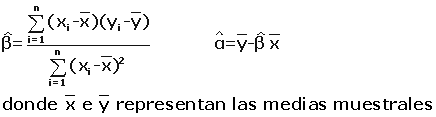
Por tanto la recta
de regresión estimada será:
![]()
Un ejemplo. La recta de
regresión representada corresponde a la estimación obtenida a partir de 20
pares de observaciones: x representa la temperatura fijada en un recinto
cerrado e Y el ritmo cardíaco de un vertebrado.
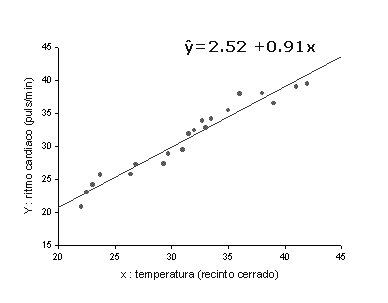
Estimación de los parámetros del modelo.
En el modelo de regresión lineal simple hay tres
parámetros que se deben estimar: los coeficientes de la recta de regresión, ![]() 0 y
0 y ![]() 1; y la varianza de la
distribución normal,
1; y la varianza de la
distribución normal, ![]() 2.
2.
El cálculo de estimadores para estos parámetros puede
hacerse por diferentes métodos, siendo los más utilizados el método de máxima verosimilitud y el
método de mínimos cuadrados.
Método de máxima verosimilitud.
Conocida una muestra de tamaño n, ![]() ,
de la hipótesis de normalidad se sigue
que la densidad condicionada en yi es
,
de la hipótesis de normalidad se sigue
que la densidad condicionada en yi es
![]()
y, por tanto, la función de densidad conjunta de la
muestra es,
![]()
Una vez tomada la muestra y, por tanto, que se conocen los
valores de ![]() i = 1n,
se define la función
de verosimilitud asociada a la muestra como sigue
i = 1n,
se define la función
de verosimilitud asociada a la muestra como sigue
esta función (con
variables 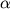 0, 1 y
0, 1 y 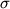 2) mide la verosimilitud de
los posibles valores de estas variables en base a la
muestra recogida.
2) mide la verosimilitud de
los posibles valores de estas variables en base a la
muestra recogida.
El método de máxima
verosimilitud se basa en calcular los valores de 0, 1 y 2 que maximizan la función
(9.3) y, por tanto, hacen máxima la probabilidad
de ocurrencia de la muestra obtenida. Por ser la función
de verosimilitud una función creciente, el problema es más sencillo si se toman
logaritmos y se maximiza la función resultante, denominada función soporte,
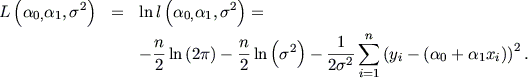
Maximizando
la anterior se obtienen los siguientes estimadores máximo verosímiles,
![]()
![]()
![]()
donde se ha
denotado 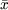 e
e
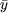 a
las medias muéstrales de X e
Y, respectivamente; sx2 es la varianza muestral
de X y sXY es la
covarianza muestral entre X e
Y. Estos valores se
calculan de la siguiente forma:
a
las medias muéstrales de X e
Y, respectivamente; sx2 es la varianza muestral
de X y sXY es la
covarianza muestral entre X e
Y. Estos valores se
calculan de la siguiente forma:
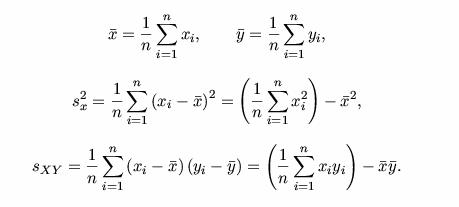
Método de
mínimos cuadrados.
A partir de los estimadores: ![]() 0
y
0
y ![]() 1,
se pueden calcular las predicciones para las observaciones muestrales,
dadas por,
1,
se pueden calcular las predicciones para las observaciones muestrales,
dadas por,
![]()
o, en
forma matricial,
![]()
donde ![]() t
=
t
= ![]() .
Ahora se definen los residuos como
.
Ahora se definen los residuos como
|
ei |
= yi - |
|
Residuo |
= Valor observado -Valor previsto,
|
en forma matricial,
![]()
Los estimadores por mínimos cuadrados se obtienen minimizando la
suma de los cuadrados de los residuos, ésto es, minimizando la siguiente
función,
derivando e igualando a cero se obtienen las siguientes
ecuaciones, denominadas ecuaciones canónicas,
![]()
![]()
De donde
se deducen los siguientes estimadores mínimo cuadráticos de los
parámetros de la recta de regresión
![]()
![]()
Se observa que los estimadores por máxima verosimilitud y
los estimadores mínimos cuadráticos de ![]() 0 y
0 y ![]() 1 son iguales. Esto es debido a la hipótesis de
normalidad y, en adelante, se denota
1 son iguales. Esto es debido a la hipótesis de
normalidad y, en adelante, se denota ![]() 0 =
0 = ![]() 0,MV =
0,MV =
![]() 0,mc y
0,mc y ![]() 1 =
1 = ![]() 1,MV =
1,MV =
![]() 1,mc.
1,mc.
4.
Varianza de
la regresión de la muestra
Es un modo alternativo de hacer
contrastes sobre el coeficiente 1. Consiste en descomponer
la variación de la variable Y de dos componentes: uno la variación de Y
alrededor de los valores predichos por la regresión y otro con la variación de
los valores predichos alrededor de la media. Si no existe correlación ambos
estimadores estimarían la varianza de Y y si la hay, no. Comparando
ambos estimadores con la prueba de
Esta técnica, permite no sólo analizar los datos sino
también para planificar los experimentos, es un procedimiento estadístico para
dividir la variabilidad observada en componentes independientes que pueden
atribuirse a diferentes causas de interés.
Función
lineal
|
Se llama función lineal de una variable, a una función de la
forma |
|
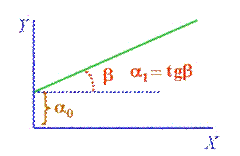
Son modelos estadísticos que
explican la dependencia de una variable dependiente “Y” respecto de una o
varias variables cuantitativas “X”.
Para obtener los
estimadores de los parámetros desconocidos del modelo así como para realizar
contrastes de hipótesis y la verificación del modelo,
Objetivos de los modelos de regresión
1) predictivo en el que el
interés del investigador es predecir lo mejor posible la variable dependiente,
usando un conjunto de variables independientes y
2) estimativo en el que el
interés se centra en estimar la relación de una o más variables independientes
con la variable dependiente.
Modelo de
regresión lineal La regresión lineal es un modelo
matemático mediante el cual es posible inferir datos acerca de una población.
Se conoce como regresión lineal ya que usa parámetros lineales (potencia
1).Sirve para poner en evidencia las relaciones que existen entre diversas
variables
Regresión Lineal Simple:
Dado el modelo de esta en
particular regresión simple, si se calcula la esperanza (valor esperado) del
valor Y, se obtiene - considerando los supuestos para los errores:
![]()
![]()
Es un modelo de regresión lineal entre
dos variables
![]()
es un modelo probabilística, que
también se puede escribir
![]()
A la variable Y se la denomina
variable dependiente y a X independiente.
Modelo de regresión lineal se asume que
|
|
|
Para calcular los parámetros
debe tomarse en cuenta que se está refiriendo a matrices:
![]()
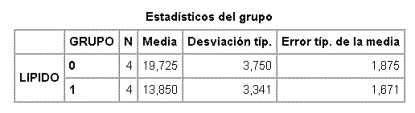
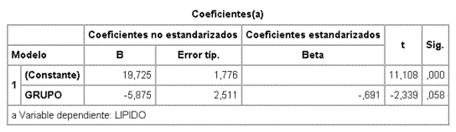
Ejemplo: Se quiere investigar el
efecto de la ingestión masiva de vitamina C sobre el hígado de las cobayas. Se
eligen dos grupos de 4 cobayas, a uno se le administra y al otro no. Se
sacrifica a los animales y se mide la concentración de lípidos en el hígado.
|
Grupo control (=0) |
Tratado (=1) |
|
23,8 |
13,8 |
|
15,4 |
9,3 |
|
21,7 |
17,2 |
|
18,0 |
15,1 |
¿Hay diferencia entre ambos grupos?
Se podría plantear un contraste sobre
medias con la t de Student.
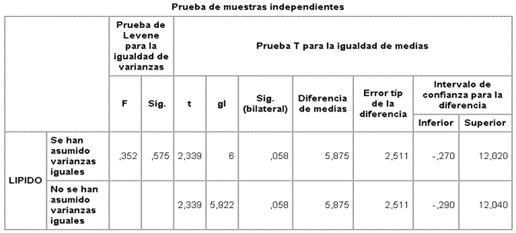
También se puede plantear un modelo
de regresión entre la variable grupo (X=0 control y X=1 tratado) y la variable
lípido (Y)
Ejemplo: Diferentes nubes de puntos y
modelos de regresión para ella

5.
Inferencias acerca
de los coeficientes de regresión de la población:
La inferencia estadística, que se
dedica a la generación de los modelos, inferencias y predicciones asociadas a
los fenómenos en cuestión teniendo en cuenta lo aleatorio e incertidumbre en
las observaciones. Se usa para modelar patrones en los datos y extraer
inferencias acerca de la población de estudio.
A veces interesa hacer inferencias
sobre la propia regresión, es decir sobre Y|xi para
cualquier valor de xi. Si a los valores xi de la muestra
se les aplica la ecuación estimada, se obtiene una estimación de Y|xi
![]()
cuya distribución muestral también es
conocida. A veces se representan los intervalos de confianza para la regresión
en la denominada banda de confianza de la regresión. En
la figura se presenta la banda de confianza para los datos del
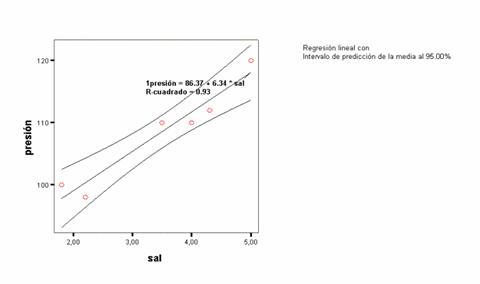
Ejemplo: Una muestra produce los siguientes datos:
|
X (sal) |
Y (Presión) |
|
1,8 |
100 |
|
2,2 |
98 |
|
3,5 |
110 |
|
4,0 |
110 |
|
4,3 |
112 |
|
5,0 |
120 |
La
"salida" de un paquete estadístico es:
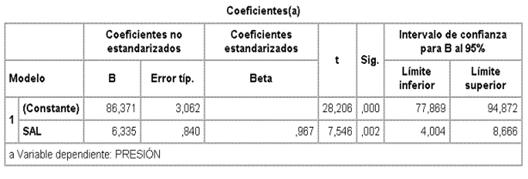
86,371 presión arterial media sin
nada de sal.
6,335 aumento de presión por cada gr de sal; como es distinto de 0 indica
correlación. La pregunta es ¿podría ser 0 en la población? En términos de
contrastes de hipótesis
H0 : 1 = 0
H1 :1 0
según iii)
|
|
aquí t=7,546 con un valor p=0,002 |
se rechaza H0.
Para hacer estimación por intervalos
de la fuerza de la asociación o el efecto
![]()
en este ejemplo para 1
al 95%
6,335 2,776x0,840 = (4,004
8,666)
y del mismo modo, tiene menos
interés, para 0
6.
Predicción y
Pronosticación
- Predicción: Es una afirmación acerca de un suceso futuro, asignando
confianza a diferentes variables para conocer qué es lo que puede pasar,
es importante tener datos de referencia confiables y certeros. Generalmente se refiere a la estimación
de series temporales o datos instantáneos.
- Pronosticación: Es el proceso de estimación en escenarios de
incertidumbre. Se utilizan datos históricos como base para estimar
resultados futuros. Se asume que la demanda es en función del tiempo,
donde se encuentran involucrados
los siguientes componentes: tendencias, ciclos, irregularidades y
estacionalidades.
- Probabilidad: Se define como la cualidad de probable, que podría
llegar a suceder. En un proceso aleatorio, razón entre el número de casos
favorables y el número de casos posibles. Se aplican las técnicas de
probabilidad para llegar a una predicción o pronóstico.
Las Predicciones se podrían agrupar en:
Predicciones
categóricas: Consisten en afirmaciones que indican que algunos eventos o
valores de variables en específico puedan ocurrir o no. Las predicciones se
indican sin cualidades, por ejemplo: mañana va a llover o la temperatura
llegara el fin de semana hasta 30°
centígrados.
Predicciones
probabilísticas. Consisten en afirmaciones sobre la probabilidad de que ocurra
una situación o evento. Por ejemplo, mañana hay un 60% de probabilidad que
llueva.
Tipos de Predicción:
·
Tomando en cuenta su horizonte o proyección
en el tiempo: A corto, medio o largo plazo y según su longitud.
·
Según el tipo de preguntas realizadas, se
basan generalmente en encuestas: resultados de un acontecimiento, estudios de
opinión o evaluación de clientes.
·
Momento de un acontecimiento, generalmente
se basan en indicadores adelantados: Fecha de unas elecciones, fechas de una
temporada comercial de ventas.
·
Predicciones de series temporales, uso del
pasado histórico de una variable, como por ejemplo tendencias de los precios
del petróleo, cantidad de nacimientos en el país para el año entrante.
Ejemplos de Predicciones:
·
Cantidad de ventas realizadas en una empresa para comprobar los niveles de
inventario.
·
Factibilidad de un proyecto económico para
determinar si éste es rentable y genera ganancias.
·
Conocer las ventas de un nuevo producto
para decidir sus niveles de producción y distribución en el mercado.
·
Determinar los efectos de una medida
económica gubernamental en la sociedad.
·
Conocer la población estudiantil dentro de
10 años para planificar la construcción de institutos educativos.
7.
Análisis de correlación
Para realizar el
análisis de correlación definimos los siguientes conceptos y fórmulas:
·
Análisis de Correlación: Es el conjunto de
técnicas estadísticas empleadas con el objetivo de medir y determinar la
intensidad de la asociación entre dos variables. Normalmente, el primer paso es
mostrar los datos en un diagrama de dispersión.
·
Diagrama de Dispersión: Es el gráfico que
representa la relación entre dos variables específicas.
·
Variable Dependiente: Es la variable a la
cual se le realizara la predicción o cálculos, su representación es Y.
·
Variable Independiente: Es la variable que
proporciona las bases para el calculo, su representación es: X1,X2,X3.......
·
Coeficiente de Correlación: Es la medida que
describe la intensidad de la relación lineal entre dos variables. El valor del
coeficiente de correlación puede tomar valores desde menos uno hasta uno,
indicando que mientras más cercano a uno sea su valor en cualquier dirección,
más fuerte será la asociación lineal entre las dos variables. Mientras más
cercano a cero sea el coeficiente de correlación denotará una asociación débil entre ambas variables.
Si el valor del coeficiente es cero se determina que no existe ninguna relación
lineal entre ambas variables.
·
Análisis de regresión: Es la técnica que se
realiza para desarrollar la ecuación y generar las estimaciones.
·
Ecuación de Regresión: Es una ecuación que
representa la asociación lineal entre dos variables.
·
Ecuación de regresión Lineal: Y’ = a + Bx
·
Ecuación de regresión Lineal Múltiple: Y’ = a
+ b1X1 + b2X2 + b3X3...
·
Principio de Mínimos Cuadrados: Es la
técnica necesaria para obtener la ecuación de regresión, minimizando la suma de
los cuadrados de las distancias verticales entre los valores reales de Y y los
valores pronosticados Y.
·
Análisis de regresión y Correlación
Múltiple: Este análisis consiste en calcular una variable dependiente, a través
del uso de dos o más variables independientes.
·
Ecuación de regresión Múltiple: La
representación general de la ecuación de regresión múltiple con dos variables
independientes es:
Y' = a
+ b1X1 + b2X2
Donde
X1, X2:
son las variables Independientes
a: es
la ordenada del punto de intersección con el eje Y
b1: es el
coeficiente de regresión (es la variación neta en Y por cada unidad de
variación en X1.)
b2: es el
coeficiente de regresión (es el cambio neto en Y para cada cambio unitario en
X2)
·
Prueba Global: Esta prueba investiga
básicamente si es posible que todas las variables independientes tengan
coeficientes de regresión netos iguales a 0.
8.
El coeficiente de
correlación de la muestra
El coeficiente de
correlación de la muestra es un indicador numérico que describe una relación
lineal entre las variables X y Y, es
representado a través de la siguiente fórmula:
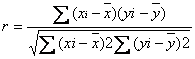
Se asume que el
denominador es diferente de cero. Una fórmula alternativa para calcular el
coeficiente de correlación es la siguiente:
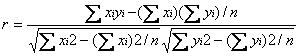
El coeficiente de
correlación presenta las siguientes propiedades:
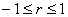 o
equivalentemente
o
equivalentemente 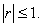
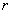 es
positivo o negativo de acuerdo a si
es
positivo o negativo de acuerdo a si 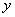 tiende
a incrementarse o decrementarse cuando
tiende
a incrementarse o decrementarse cuando 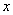 se
incrementa.
se
incrementa.- Entre más cercano esté
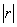 de
1 más fuerte será la asociación lineal entre y
de
1 más fuerte será la asociación lineal entre y 
La covarianza de la
muestra de ![]() y
y ![]() se
representa a través de la siguiente formula:
se
representa a través de la siguiente formula:
![]()
Utilizando la
covarianza de la muestra, la fórmula del coeficiente de correlación se puede
representar de una manera compacta:
![]()
donde ![]() y
y ![]() son la
desviación estándar de
son la
desviación estándar de ![]() y
y ![]() respectivamente.
respectivamente.
9.
Coeficiente de
determinación y análisis de varianza en regresión lineal
Es la principal forma en que podemos medir la extensión o fuerza de la asociación que existe entre 2
variables, X y Y.
Como hemos usado una muestra
de puntos para desarrollar líneas de regresión, nos referiremos a esta medida
como el coeficiente de determinación de muestra.
Se desarrolla de la relación entre 2 tipos de variación:
La variación de los valores Y en un conjunto de datos alrededor de:
1.
La línea de
regresión ajustada = Σ(Y-Y)²
2.
Su propia media =
Σ(Y-Y)²
El coeficiente de determinación se simboliza:
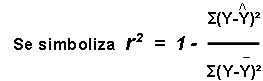
Una interpretación
intuitiva de r²
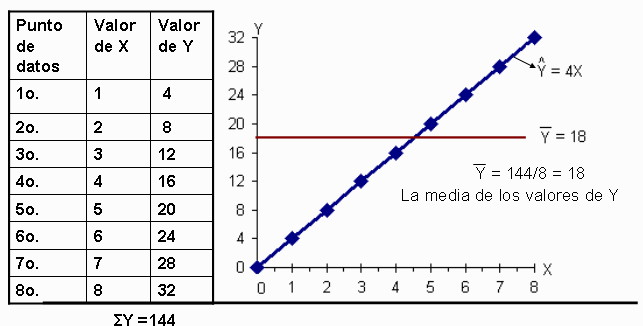
Revisaremos las 2 formas extremas en las que las variables X y Y
pueden relacionarse. En este ejemplo cada valor
observado de Y cae en la línea de estimación, como se ve en la tabla esta es
una correlación perfecta.
La ecuación de
estimación apropiada para este caso es fácil de determinar. Puesto que la línea
de regresión pasa a través del origen, sabemos que la intersección Y es cero; y
puesto que Y se incrementa en 4 cada vez que X se incrementa en 1, la pendiente
debe ser igual a 4.
La línea de
regresión es: ![]()
Para determinar
el coeficiente de determinación de muestra para la línea de regresión, primero
calculamos el numerador de la fracción en la ecuación de r².
Variación de los valores
de Y alrededor de la línea de regresión =![]()
Como cada valor
de Y está sobre la línea de regresión la diferencia es 0 Σ(0)² = 0

Sustituimos los
valores en la fórmula encontramos que el coeficiente de determinación de
muestra es igual a + 1
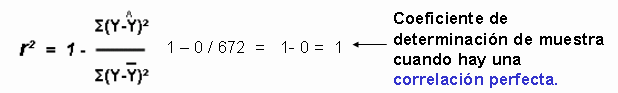
De hecho r² es
igual a +1 siempre que la línea de regresión sea un estimador perfecto.
Una segunda forma extrema en la que las variables X y Y pueden relacionarse es aquella
en que los puntos podrían caer a distancias iguales en ambos lados de una línea
de regresión horizontal. A continuación mostramos la gráfica:
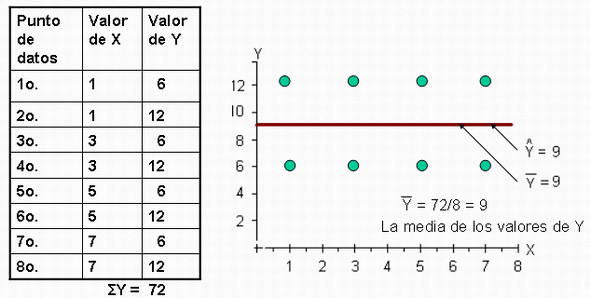


Sustituimos los valores en
la fórmula encontramos que el coeficiente de determinación de muestra es igual a 0

Por lo tanto el valor de
r² es cero cuando no hay correlación.
Un r² cercano a 1
indica una fuerte correlación entre X y Y.
Un r² cercano a 0
indica que existe poca correlación entre X y Y.
Se debe subrayar fuertemente que r² mide solo la fuerza de una relación lineal entre 2
variables. Por ejemplo, si tuviéramos muchos
puntos X y Y y todos cayeran en la circunferencia de un círculo, aunque
dispersos aleatoriamente, claramente habría una relación entre estos puntos. (Todos
caen en el mismo círculo),
Pero si
calculamos r² resultaría estar cerca de 0, porque los puntos no tienen una relación
lineal entre sí.
Para evitar estos cálculos, los estadísticos han desarrollado
una versión de atajo, usando los valores
que habríamos determinado de antemano en el análisis
de regresión.
La fórmula es:

Para ver que esta fórmula es un atajo, la aplicaremos a nuestra
anterior regresión que relaciona los gastos
de inversión y desarrollo con las ganancias. Recuerde que cuando encontramos los
valores para a y b la línea de regresión para este problema es:
![]()



3,600 + 2,000 –
5,400
=
-------------------------------
5,642 – 5,400
200
= ------ = 0.826 Coeficiente
de determinación de muestra
242
Por tanto, podemos concluir que la variación en los gastos de investigación y desarrollo (la variable
independiente X) explica 82.6 % de la variación en las ganancias anuales (la
variable dependiente Y)
Es la segunda
medida que podemos usar para describir que tan bien una variable es explicada
por otra.
Cuando tratamos
con muestras el coeficiente de correlación de muestra se denota como r y es la
raíz cuadrada del coeficiente de determinación de muestra: r = √r²
Cuando la
pendiente de la ecuación de estimación es positiva, r es la raíz cuadrada
positiva, pero si b es negativa, r es la √ negativa.
El signo de r indica la dirección
de la relación entre las dos variables X y Y.
Diversas
características de r, el coeficiente de correlación de muestra

En el problema
anterior encontramos que el Coeficiente de determinación de muestra es r² =
0.826, para encontrar r sustituimos este valor en la ecuación:
r = √r²
= √0.826
= 0.909
Coeficiente de correlación de muestra
La relación entre
las dos variables es directa y la pendiente es positiva, por tanto el signo de
r es positivo.
Supongamos que la cantidad gastada en boletos de cine correlaciona 0.6 con el ingreso familiar.
A primera vista, 0.6 parece ser una correlación bastante fuerte ya que esta más
cerca de 1 que de 0. Pero esto explica sólo el 36% (0.6 x 0.6 = 0.36) de la
variación en la cantidad de dinero que
las familias gastan en películas. Esto sugiere que una estrategia de comercialización
diseñada para atraer familias con altos ingresos
pasaría por alto una gran cantidad de clientes
potenciales.
Análisis de varianza
En estadística, análisis
de varianza (ANOVA, según terminología inglesa) es una colección de modelos estadísticos
y sus procedimientos asociados. El análisis de varianza sirve para comparar si
los valores de un conjunto de datos numéricos son significativamente distintos
a los valores de otro o más conjuntos de datos. El procedimiento para comparar
estos valores está basado en la varianza global observada en los grupos de
datos numéricos a comparar. Típicamente, el análisis de varianza se utiliza
para asociar una probabilidad a la conclusión de que la media de un grupo de
puntuaciones es distinta de la media de otro grupo de puntuaciones.
Supuestos previos
El ANOVA parte de algunos supuestos que han de cumplirse:
·
La variable dependiente
debe medirse al menos a nivel de intervalo.
·
Independencia de
las observaciones.
·
La distribución
de la variable dependiente debe ser normal.
·
Homocedasticidad: homogeneidad de las
varianzas.
Visión general
Existen tres tipos de modelos:
- El
modelo de efectos fijos asume que el experimentador ha considerado
para el factor todos los posibles valores que éste puede tomar. Ejemplo:
Si el género del individuo es un factor, y el experimentador ha incluido
tantos individuos masculinos como femeninos, el género es un factor fijo
en el experimento.
- Los
modelos de efectos aleatorios asumen que en un factor se ha
considerado tan sólo una muestra de los posibles valores que éste puede
tomar. Ejemplo: Si el método de enseñanza es analizado como un factor que
puede influir sobre el nivel de aprendizaje y se ha considerado en el
experimento sólo tres de los muchos más métodos posibles, el método de
enseñanza es un factor aleatorio en el experimento.
- Los
modelos mixtos describen situaciones donde están presentes ambos tipos de
factores: fijos y aleatorios.
La técnica fundamental consiste en la separación de la suma de
cuadrados (SS, 'sum of squares') en componentes relativos a los factores
contemplados en el modelo. Como ejemplo, mostramos el modelo para un ANOVA
simplificado con un tipo de factores en diferentes niveles. (Si los niveles son
cuantitativos y los efectos son lineales, puede resultar apropiado un análisis
de regresión lineal)
SSTotal = SSError + SSFactores
El número de grados de libertad (gl) puede separarse de forma
similar y se corresponde con la forma en que la distribución chi-cuadrado describe la suma
de cuadrados asociada.
glTotal = glError + glFactores
Modelo de efectos fijos
El modelo de efectos fijos de análisis de la varianza se
aplica a situaciones en las que el experimentador ha sometido al grupo o
material analizado a varios factores, cada uno de los cuales le afecta sólo a
la media, permaneciendo la "variable respuesta" con una distribución
normal.
Modelo de efectos aleatorios
Los modelos de efectos aleatorios se usan para describir
situaciones en que ocurren diferencias incomparables en el material o grupo
experimental. El ejemplo más simple es el de estimar la media desconocida de
una población compuesta de individuos diferentes y en el que esas diferencias
se mezclan con los errores del instrumento de medición.
Grados de libertad
Por grados de libertad "degrees of freedom"
entendemos el número efectivo de observaciones que contribuyen a la suma de
cuadrados en un ANOVA, es decir, el número total de observaciones menos el
número de datos que sean combinación lineal de otros.
Pruebas de significación
El análisis de varianza lleva a la realización de pruebas de
significación estadística, usando la denominada distribución F de Snedecor.
Análisis de regresión lineal
Los problemas de la causalidad en
Ciencias sociales
Por el momento no existe técnica que sea capaz de probar los
enunciados causales empíricamente. Lo que se puede hacer es comprobar si las
inferencias causales que formula un investigador son consistentes con los datos
disponibles.
Definiremos modelo como conjunto de relaciones que se usan para
representar de forma sencilla una porción de la realidad empírica.
Cuando un investigador elabora un modelo y posteriormente se
comprueba que el modelo no se ajusta a los datos, se pueden tomar dos
decisiones: modificar el modelo o abandonarlo. Pero si el modelo es consistente
con los datos, esto nunca prueba los efectos causales. La consistencia entre
los datos y el modelo no implica la consistencia entre el modelo y la realidad.
Lo único que se puede afirmar es que los supuestos del investigador no son
contradictorios y por lo tanto pueden ser válidos. Pero el "ser
válidos", no quiere decir que sean la única explicación del fenómeno
objeto de estudio, ya que es posible que otros modelos también se adapten a los
mismos datos.
Asociación no implica causalidad: Que exista una fuerte asociación entre dos variables no es
suficiente para sacar conclusiones
sobre las relaciones causa - efecto.
Ejemplo: existe fuerte correlación entre el número de bomberos
que actúan en un incendio y la importancia del daño ocasionado por el mismo.
El modelo de la regresión lineal
múltiple
El objetivo del análisis de la regresión lineal es analizar un
modelo que pretende explicar el comportamiento de una variable (Variable
endógena, explicada o dependiente), que denotaremos por Y, utilizando la información proporcionada por los valores tomados
por un conjunto de variables (explicativas, exógenas o independientes), que
denotaremos por X1 , X2
, ....., X n
Las variables del modelo de regresión deben ser cuantitativas.
Pero dada la robustez[1]
de la regresión es frecuente encontrar incluidas en el modelo como variables
independientes a variables ordinales e incluso nominales transformadas en
variables ficticias. Pero la variable dependiente debe ser cuantitativa. Para
una variable dependiente binaria de emplea la regresión logística.
El modelo lineal viene dado por la ecuación lineal:
Y = b0 + b1
X1 + b2 X2 + ... b
k X k + u
Los coeficientes (parámetros)
b1 , b2 , ... , b k denotan la magnitud del efecto de las
variables explicativas (exógenas o independientes), esto es, representan los
pesos de la regresión o de la combinación lineal de las predictoras X1 , X2 , ... X k sobre la variable explicada (endógena o
dependiente) Y. El coeficiente b0 se denomina término constante (o independiente)
del modelo. Y al término u se le
llama término de error del modelo o componente de Y no explicada por las variables predictoras.
Si disponemos de T observaciones para cada variable, el modelo
de expresa así:
Y t = b0 + b1
X1 t + b2 X2 t + ... b k X k t + u t t = 1, 2 , 3 ,.... T
El problema fundamental que se aborda es el siguiente:
suponiendo que la relación entre la variable Y y el conjunto de variables X1
, X2 , ... X k es como se ha descrito en
el modelo, y que se dispone de un conjunto de T observaciones para cada una de
las variables ¿cómo pueden asignarse valores numéricos a los parámetros b0 , b1 , b2
, ... b k basándonos en la información muestral?
Estos valores son la estimación de los parámetros llamados
coeficientes de regresión. Representan las unidades de cambio en la variable
dependiente por unidad de cambio en la variable independiente correspondiente.
En el caso de que sólo haya una variable dependiente se llega a la ecuación de
una recta donde b0 es la ordenada en el origen y b1 la pendiente de la recta.
Una vez encontradas las
estimaciones de los parámetros del modelo, podremos hacer predicciones sobre el
comportamiento de la variable Y en
la población.
El análisis de regresión sirve tanto
para EXPLORAR datos como para CONFIRMAR teorías.
Si el análisis de regresión se realiza con variables tipificadas
los coeficientes b, pasan a denominarse β (coeficientes de regresión
estandarizados) β i
= b i (Desv.
Típica Xi /Desv. Típica Y)
Al coeficiente de correlación R elevado al cuadrado se le llama
coeficiente de determinación y es una medida de la bondad del ajuste del modelo
ya que da la proporción de variación de Y explicada por el modelo.
Se suele emplear R2 ajustado, que es una corrección
de R2 para ajustar mejor el
modelo a la población objeto de estudio.
Supuestos del modelo de regresión
El modelo lineal se formula bajo los
siguientes supuestos:
- Tamaño adecuado de la
muestra: se recomienda n= 20 x nº de variables predictoras.
- Las variables X1 , X2 , ...
X k son deterministas (no son variables aleatorias) ya
que sus valores vienen de la muestra tomada.
- Se supone que todas las
variables X relevantes para la explicación de Y
están incluidas en la definición del modelo lineal.
- Las variables X1
, X2 , ... X k son linealmente
independientes (no se puede poner a una de ellas como combinación lineal
de las otras). Esta es la hipótesis de independencia y cuando no se cumple
se dice que el modelo presenta multicolinealidad. O sea: Ninguna v. Independiente da un R2 = 1 con las otras v.i.
- Linealidad de las
relaciones: la v. Independiente presenta relación lineal con cada una de
las dependientes. Se comprueba con los gráficos de regresión parcial. Su
incumplimiento se arregla mediante transformaciones de los datos
- Los residuos siguen una distribución
Normal N(0, σ 2) , no están correlacionados con ninguna de
la variables independientes, ni están autocorrelacionados. Hay homocedasticidad:
la varianza del error es constante para los distintos valores de las
variables independientes.
El primer objetivo es el de obtener estimaciones, es decir,
valores numéricos de los coeficientes b0
, b1 , b2 , ... b k (coeficientes de regresión parcial) en
función de la información muestral. Las estimaciones de los parámetros se
suelen hacer por el método de los mínimos cuadrados que consiste en minimizar
la suma de los cuadrados de los residuos, también llamada suma residual
Análisis de la varianza: Introduciremos los siguientes conceptos
Suma total (ST) es la varianza muestral de la variable dependiente y es por lo
tanto una medida del tamaño de las fluctuaciones experimentadas por dicha
variable alrededor de su valor medio.
Suma explicada (SE) es la fluctuación de estimador de la variable Y ( Ŷt
) alrededor de la media de Y . Por tanto, la suma explicada es el nivel de
fluctuación de la variable Yt que el modelo es capaz de explicar.
Suma residual (SR) es un indicador del nivel de error del modelo.
Suma total = Suma explicada
+ Suma residual
También se define el coeficiente
de determinación R2 como
una medida descriptiva del ajuste global del modelo cuyo valor es el cociente
entre la suma explicada y la suma total. (da la proporción de varianza
explicada por el modelo) R2 = V.
Explicada / V. Total
Se define el coeficiente
de correlación múltiple R como la raíz cuadrada del coeficiente
de determinación y mide la correlación entre la variable dependiente y las
independientes.
El Coeficiente de
correlación parcial entre X i e Y mide la correlación entre
estas variables cuando se han eliminado los efectos lineales de las otras
variables en X i e Y.
Coeficiente de correlación
semiparcial entre X i e Y es
la correlación entre estas variables cuando se han eliminado los efectos
lineales de las otras variables en Y.
• La variable u (término de error o residuo) es una variable
aleatoria con media nula y matriz de covarianzas constante y diagonal. O sea
para todo t , la variable u t tiene
una media igual a cero y una varianza no dependiente de t ( hipótesis de homocedasticidad) y además
Cov ( ui , uj
)= 0, pata todo i distinto de j
(hipótesis de no autocorrelación) y tampoco están correlacionados con las
variables independientes.
SPSS
(regresión múltiple)
Lo fundamental de la regresión consiste en encontrar una función
lineal de las variables independientes que permita predecir la variable
dependiente
Y = b0 + b1
X1 + b2 X2 + ... b
k X k + u
Con el fichero de datos del CIS que estamos usando, ya en
sesiones anteriores hemos definido un
conjunto de variables relacionadas con el problema de la INMIGRACIÓN. Y de
ese conjunto usaremos las variables que cumplan los supuestos de la regresión
(solo variables cuantitativas y si son cualitativas definir las variables
ficticias correspondientes (dummy)).
Siguiendo la idea del Libro de Mª Angeles Cea (Análisis
multivariable. Ed. Síntesis) vamos a tomar como variable dependiente "simpatía hacia los norteafricanos
(p401)" y trataremos de ajustar un modelo de regresión con variables
independientes como: "simpatía latinoamericano (p410)" "casar
con marroquí (p506)", "vecino marroquí (p706)" "sexo ,
p32" "p33 edad" P29 izquierda-derecha, etc. etc.
Para las primeras pruebas se recomienda no usar muchas
variables, para que los ficheros de resultados no resulten demasiado grandes.
Analizar -> Regresión -> lineal
Llevar al rectángulo correspondiente la variable dependiente y
las independientes del modelo.
En Método: Hay cuatro
posibles: introducir, pasos sucesivos, eliminar, hacia atrás, hacia delante
(leer la explicación en la ayuda del SPSS). Si estamos en fase exploratoria y
no tenemos una idea del modelo justificada por alguna teoría que queramos
comprobar, se recomienda usar el método de hacia delante. Con él, el SPSS
introducirá como primera v. Independiente la que satisfaga los criterios de
entrada y que presente mayor correlación con la v. dependiente, luego
introducirá en el modelo otra v. Independiente que será la siguiente en cuanto
a mayor magnitud de la correlación con la v. Independiente y así sucesivamente.
En opciones elegir el
tratamiento que queramos dar a los casos perdidos (Se recomienda
encarecidamente repasar lo explicado en clases teóricas así como leer las ayudas del SPSS, que se obtienen llevando
el cursor al elemento que no entendemos y pulsando el botón derecho del ratón)
En estadísticos señalar aquellos que queramos conocer.
Guardar permite archivar como nuevas variables los resultados de los
cálculos que se han ido haciendo en el proceso de la regresión.
En los resultados de la matriz de correlaciones obtenemos para
cada pareja de variables el coeficiente de correlación de Pearson, su significación y el tamaño de la muestra
con el que se ha calculado ese coeficiente. Son tres tablas que aparecen una a
continuación de la otra.
Los números de la segunda tabla son los p-valores asociados al
estadístico R. Para poder contrastar si el estadístico coeficiente de
correlación es estadísticamente significativo. La Hipótesis nula es que R=0, Si
se obtiene un valor inferior a una significación prefijada (por ejemplo 0,05)
indica que hay que rechazar la Hipótesis nula de inexistencia de correlación y
concluir que el R obtenido es estadísticamente significativo.
Notar que la matriz de correlaciones es simétrica
Luego aparece una tabla con las variables que han ido entrando
en el modelo. Y a continuación otra tabla con información de los coeficientes R
y R2 para cada modelo.
Otra tabla con los cambios en R2 y en F por la que podemos saber la
proporción de varianza que explica cada uno de los modelos. También aparece en
esta tabla el estadístico de Durbin Watson que ya se mencionó. Si es próximo a
dos los residuos no están autocorrelacionados.
También obtenemos un análisis de la varianza en el que vemos los
valores de la suma de cuadrados total, explicado por la regresión y residual
(repasar la teoría)
La tabla COEFICIENTES nos da la información para escribir las
ecuaciones lineales de los modelos de regresión, (con una v. Independiente, con
dos, con tres, etc.).
A continuación tenemos una tabla con los coeficientes de
correlación de orden cero, parcial y semiparcial así como los estadísticos de
colinealidad.
Por último aparece un estudio de las variables que se han
excluido del modelo.
También da una tabla de diagnósticos por caso que nos informa de
los casos que el modelo predice peor
(residuo tipificado mayor que 3) y que tal vez habría que estudiar en la matriz de datos.
10.
Prueba F Sobre
Beta
El modelo de regresión lineal
- La
relación se puede representar gráficamente mediante una línea recta.
Se supone que el error sigue una distribución normal con media
cero y varianza sigma2.
- El
modelo de regresión completo es
Y es el valor de la variable dependiente
A o alfa es el intercepto, donde cruza el eje Y
B o beta es la pendiente
o inclinación
- Prueba
de Ho: beta=0, mediante la
estadística F
- Si
beta es igual a cero,
se concluye que:
- La
relación es lineal y de fuerza para justificar el uso de ecuaciones de
regresión simple para predecir y estimar Y para valores dados de X.
- El
modelo lineal proporciona un buen ajuste para los datos, pero un modelo
curvilíneo podría proporcionar un mejor ajuste.
Correlación simple
- Es
una extensión de la regresión simple.
- Mide
la calidad del ajuste de una línea
- r
es el coeficiente de correlación
- r2
es el coeficiente de determinación
Prueba de hipótesis
- Prueba
de Ho: r=0, mediante la estadística F
- Si
r es igual a cero, se concluye que no existe correlación entre las
variables
11.
Coeficiente de Correlación
Por Calificación
Coeficiente r de Pearson
Puede variar de –1 a +1
- -1
correlación negativa perfecta
- -0.9
correlación negativa muy fuerte
- -0.75
correlación negativa considerable
- -0.5
correlación negativa media
- -0.1
correlación negativa débil
- 0.0
no existe correlación entre las variables
Los programas reportan el valor de p del coeficiente para
evaluar el significado de la correlación
Correlación de Spearman
- Son
medidas de correlación para dos variables, por lo menos una de ellas es ordinal.
- Los
individuos u objetos se ordenan por rangos (jerarquías).
Ej: correlación de Spearman
Objetivo. Conocer si el desarrollo mental de 8 niños esta
asociado a la educación formal de su madre.
Hipótesis.
Ho. No habrá una correlación significativa en el desarrollo
mental de 8 niños dependiendo de la educación formal de la madre
H1. Habrá una correlación significativa en el desarrollo mental
de 8 niños dependiendo de la educación formal de la madre.
Ej.: correlación de Spearman
Escolaridad Desarrollo Rango educ. Rango
desarr. Dif. Dif al cuadrado
1o.
Sec
90
5
7
-2 p;
4
1o.
Prim
87
4
2
2
4
Profesional
89
8
6
2
4
6o.
Prim.
80
2
5
-3 p;
9
3o.
Sec.
85
6
4
2
4
3
Prim.
84
3
3
0
0
Analf.
75
1
1
0
0
Preparatoria
91
7
8
-1 p;
1
N =
8
26
rsc = 0.69, rst = 0.714, rsc < rst no se rechaza Ho
Conclusión: No hay una correlación significativa en el
desarrollo mental de 8 niños dependiendo de la educación formal de la
madre.
Caso: correlación de Spearman
Cumplimiento de estándares de calidad en la atención del parto
institucional y nivel de satisfacción de usuarias
Autor: Oliver Alarco Cadillo y col.
Universidad Nacional Mayor de San Marcos. Lima, Perú
Resumen
Objetivos: Determinar la
correlación entre el nivel de satisfacción de usuarias y el nivel de
cumplimiento de índices estandarizados de atención del parto en 58
establecimientos de Salud el Perú.
Caso: correlación de
Spearman
Material y Método: Se realizó un
estudio transversal y comparativo aplicado a una población de 21 departamentos
del Perú realizada en forma aleatoria (37 hospitales y 21 Centros de Salud
Cabeceras de Red). Se utilizaron dos instrumentos: Encuesta de satisfacción del
establecimiento de salud a puérperas usuarias de los establecimientos y la
Lista de chequeo para la medición de procesos de calidad de atención en
servicios materno perinatales. Para el análisis de los datos se realizó un
análisis bivariado y se utilizó el coeficiente de correlación de Spearman.
Resultados: El coeficiente de
correlación de Spearman entre el "Grado de Satisfacción de la usuaria de
los servicios de atención de parto" y el "Porcentaje de Cumplimiento
del Protocolo de Atención del Parto" resultó de 0.027, lo que revela la no
existencia de relación directa entre dichas variables.
Conclusiones: Se demuestra la falta de correlación entre el nivel de satisfacción de usuarias y el nivel de cumplimiento de índices estandarizados de atención del parto en los Centros Hospitalarios.
12.
Conclusiones
La investigación cuya finalidad es: el análisis o
experimentación de situaciones para el descubrimiento de nuevos hechos, la
revisión o establecimiento de teorías y las aplicaciones prácticas de las
mismas, se basa en los principios de Observación y Razonamiento y necesita en
su carácter científico el análisis técnico de Datos para obtener de ellos
información confiable y oportuna. Este análisis de Datos requiere de la
Estadística como una de sus principales herramientas, por lo que los
investigadores de profesión y las personas que de una y otra forma la realizan
requieren además de los conocimientos especializados en su campo de
actividades, del manejo eficiente de los conceptos, técnicas y procedimientos
estadísticos.
El análisis estadístico bivariable es aquel análisis que opera
con datos referentes a dos variables y pretende descubrir y estudiar sus
propiedades estadísticas.
El análisis estadístico bivariable se orienta fundamentalmente a la normalización
de los valores o frecuencias ce los datos brutos, determina la existencia, dirección
y grado de la variación conjunta entre las dos variables, lo que se realiza
mediante él calculo de los coeficientes de correlación pertinentes, calcula la
covarianza o producto
de las desviaciones de las dos variables en relación a sus medias respectivas y
por ultimo establece la naturaleza
y forma de la asociación entre las dos variables en el caso de las variables de
intervalo.
13.
Infografía Y
Bibliografía
Infografía:
http://www.monografias.com/trabajos30/regresion-correlacion/regresion-correlacion.shtml
desarrollare el grado de relación entre dos
o mas variables
en lo que llamaremos análisis de correlación, Para representar esta relación
utilizaremos una representación gráfica llamada diagrama de dispersión, estudiaremos un
modelo
matemático para estimar el valor
de una variable basándonos en el valor de otra, en lo que llamaremos análisis de
regresión.
http://www.udc.es/dep/mate/estadistica2/sec6_3.html
El modelo de regresión más sencillo es el Modelo de
Regresión Lineal Simple que estudia la relación lineal entre la variable respuesta ![]() y
la variable regresora
y
la variable regresora ![]() ,
a partir de una muestra
,
a partir de una muestra ![]() i = 1n .
i = 1n .
Analisis de Varianza es.wikipedia.org/wiki/Análisis_de_varianza
- 23k
Tipos, ejemplos
y características de la predicción.
http://www.um.es/econometria/tecpre/teoria/introduccion.pdf
Definición de
pronóstico y descripción de sus métodos.
http://es.wikipedia.org/wiki/Pron%C3%B3stico_de_demanda
Análisis de
correlación, marco teórico y ejercicios.
http://www.monografias.com/trabajos30/regresion-correlacion/regresion-correlacion.shtml
Medidas de
dispersión, coeficiente de correlación de la muestra, formulas y propiedades.
http://www.micromegas.com.mx/papeleria/formulario12.htm
Bibliografía
En esta página se publican los
"apuntes" usados en los distintos cursos de
http://www.hrc.es/bioest/Reglin_11.html
Análisis de la varianza de la regresión
Análisis de la varianza de la
regresión. Es un modo alternativo de hacer contrastes sobre el coeficiente a1.
Consiste en descomponer la variación de la ...
www.hrc.es/bioest/Reglin_6.html
Silva Ayçaguer L.C., Barroso Utra
I.M. Selección algorítmica de modelos en las aplicaciones biomédicas de la
regresión múltiple. Medicina Clínica. 2001;116:741-745.
cuftb Acceso: Alejandría BE 4.7.1.7r
Inferencias acerca de los coeficientes de regresión de la
población. - Predicción y
pronosticación. - Análisis de correlación. ...
www.cuft.tec.ve/cgi-win/be_alex.exe?Acceso=T062500001133/0&Nombrebd=cuftb
Éste texto es la versión electrónica del manual de
Bioéstadística: Métodos y Aplicaciones
U.D. Bioestadística. Facultad de Medicina. Universidad de Málaga.
ISBN: 847496-653-1
http://virtual.uptc.edu.co/ova/estadistica/docs/libros/ftp.bioestadistica.uma.es/libro/node42.htm
