Estudios virtuales (Pregrado)
Licenciatura en Información y Documentación
Estadística Descriptiva (HID032072
082) – Prof. Sandi Quintero
Elaborado por:
Adriana Fraga
Betsy Arguelles
Blanca Brito
Gerardo Duarte
Rosanna Medina
![]()
Trabajo 2
1. Introducción a la estadística descriptiva.
Conceptos. Tipos de variables. Clasificación de variables.
2. Distribución de frecuencias. Concepto.
Formulas. Ejemplos.
3. Distribución de frecuencias agrupadas.
Concepto. Formulas. Ejemplos.
4. Medidas de posición central. Concepto.
Tipos. Formulas. Principales medidas. Ejemplos.
5. Medidas de posición no central. Concepto.
Tipos. Formulas. Principales medidas. Ejemplos.
6. Medidas de dispersión. Concepto. Tipos.
Formulas. Principales medidas. Ejemplos.
7. Medidas de forma: grado de concentración.
Concepto. Tipos. Formulas. Principales medidas. Ejemplos.
8. Medidas de forma: Coeficiente de Asimetría.
Concepto. Tipos. Formulas. Principales medidas. Curvas. Ejemplos.
9. Medidas de forma: Coeficiente de Curtosis.
Concepto. Tipos de distribuciones. Formulas. Curvas. Ejemplos.
10.
Distribuciones Bidimensionales. Concepto. Representación de los datos.
Formulas. Ejemplos.
11.
Distribuciones marginales. Concepto. Tipos. Formulas. Ejemplos.
12.
Conclusiones
13. Infografía
y Bibliografía.
1.- Estadística: la ciencia
estadística, considerada en su sentido teórico, esta constituida por un cuerpo
de principios, axiomas y desarrollos cuantitativos mediante los cuales los
matemáticos han llegado a construir métodos y técnicas especificas, aplicables
al procesamiento de la información dada por diversos tipos de datos,
procedimientos y técnicas empleadas para recolectar, organizar y analizar
datos, los cuales sirven de base para tomar decisiones en las situaciones de
incertidumbre que plantean las ciencias sociales o naturales.
Estadística descriptiva:
el objetivo será, a partir de una muestra de datos (recogida según
una técnica concreta), la descripción de las características más importantes,
entendiendo como características, aquellas cantidades que nos proporcionen
información sobre el tema de interés del cual hacemos el estudio.
Tipos de variables:
variable: es la característica que estamos midiendo. Existen dos categorías
o tipo de variables:
o
Variable
cualitativa: es aquella que expresa un atributo o característica, ejemplo:
rubio, moreno, etc.
o
variable cuantitativa: es aquella
que podemos expresar numéricamente: edad, peso, nº. De hijos, etc. Esta a su
vez la podemos subdividir en:
Variable discreta, aquella que
entre dos valores próximos puede tomar a lo sumo un número finito de valores.
Ejemplos: el número de hijos de una familia, el de obreros de una fabrica, el
de alumnos de la universidad, etc.
Variable continúa la que puede
tomar los infinitos valores de un intervalo. En muchas ocasiones la diferencia
es más teórica que práctica, ya que los aparatos de medida dificultan que
puedan existir todos los valores del intervalo. Ejemplos, peso, estatura,
distancias, etc.
Clasificación de las
variables
Las
variables se pueden clasificar de tres formas:
·
Según su naturaleza (variables cualitativas, variables cuantitativas y variables cualicuantitativas)
· Según la función que cumplan en la hipótesis o en el
análisis del problema.
· Según su grado de complejidad
(simples y complejas).
2.- Distribución de
frecuencias: agrupamiento de datos en categorías, que muestran el número de
observaciones en cada categoría mutuamente excluyente.
Los
intervalos de clase usados en la distribución de frecuencias deben ser iguales.
Determine un intervalo de
clase sugerido con la fórmula:
i = (valor más alto - valor más bajo)/número de clases.
Use el intervalo de clase
calculado sugerido para construir la distribución de frecuencias. Nota: este es
un intervalo de clase sugerido; si el intervalo de clase calculado es 97, puede
ser mejor usar 100.
Cuente el número de valores en cada clase.
Ejemplo:
El Dr. Castro es el decano de la facultad de administración y
desea determinar cuánto estudian los alumnos en ella. Selecciona una muestra
aleatoria de 30 estudiantes y determina el número de horas por semana que
estudia cada uno: 15.0, 23.7, 19.7, 15.4, 18.3, 23.0, 14.2, 20.8, 13.5, 20.7,
17.4, 18.6, 12.9, 20.3, 13.7, 21.4, 18.3, 29.8, 17.1, 18.9, 10.3, 26.1, 15.7, 14.0,
17.8, 33.8, 23.2, 12.9, 27.1, 16.6.
Organice los datos en una distribución de frecuencias.
Considere las clases 8-12
y 13-17. Las marcas de clase son 10 y 15. El intervalo de clase es 5 (13 - 8).
|
Horas
de estudio |
Frecuencia,
f |
|
8-12 |
1 |
|
13-17 |
12 |
|
18-22 |
10 |
|
23-27 |
5 |
|
28-32 |
1 |
|
33-37 |
1 |
3.-
Distribución de frecuencias agrupadas:
En estadística existe una relación con cantidades, números
agrupados o no, los cuales poseen entre sí características similares. Existen
investigaciones relacionadas con los precios de los productos de la dieta
diaria, la estatura y el peso de un grupo de individuos, los salarios de los
empleados, los grados de temperatura del medio ambiente, las calificaciones de
los estudiantes, etc., que pueden adquirir diferentes valores gracias a una
unidad apropiada, que recibe el nombre de variable. La representación numérica
de las variables se denomina dato estadístico.
La distribución de frecuencia es una disposición tabular de datos
estadísticos, ordenados ascendente o descendentemente, con la frecuencia (fi)
de cada dato. Las distribuciones de frecuencias pueden ser para datos no
agrupados y para datos agrupados o de intervalos de clase.
Los pasos para la construcción de una distribución de frecuencias son
mejor explicados con un ejemplo.
Ejemplo: Los
siguientes datos son el número de meses de duración de una muestra de 40
baterías para coche.
|
22 |
41 |
35 |
45 |
32 |
37 |
30 |
26 |
|
34 |
16 |
31 |
33 |
38 |
31 |
47 |
37 |
|
25 |
43 |
34 |
36 |
29 |
33 |
39 |
31 |
|
33 |
31 |
37 |
44 |
32 |
41 |
19 |
34 |
|
47 |
38 |
32 |
26 |
39 |
30 |
42 |
35 |
4.- Medidas de posición nos facilitan
información sobre la serie de datos que estamos analizando. Estas medidas
permiten conocer diversas características de esta serie de datos.
Las medidas de posición son de dos tipos:
A) medidas de posición
central o "medidas de tendencia
central”: informan sobre los valores medios de la serie de datos.
B) medidas de posición no
centrales: informan de como se distribuye el resto de los valores de la
serie.
Las principales medidas de
posición central son las siguientes:
1.- la media, es la medida
más popular. Es el valor medio ponderado de la serie de datos.
![]()
•
es decir, tenemos una muestra de n
observaciones: x1, x2,…,xn.
![]()
 Su
media muestral es:
de forma compacta:
Su
media muestral es:
de forma compacta:
 la media de la muestra de seis
observaciones:
la media de la muestra de seis
observaciones:
7, 3, 9, -2, 4, 6 esta dada por:
Cuando
muchas observaciones toman el mismo valor, estas se pueden resumir en una tabla de frecuencias. Supongamos que el número de
Ejemplo:
Número de hijos en una muestra de 16 empleados:
|
|
|
|
Num. De
empleados 3 4
7 2 |
|
|
|
|
|
|
|
|
|
|
Se pueden calcular
diversos tipos de media, las más utilizadas
A) media aritmética: se calcula
multiplicando cada valor por el número de veces que se repite. La suma de todos
estos productos se divide por el total de datos de la muestra:
|
Xm = |
(x1
* n1) + (x2 * n2) + (x3 * n3) + ....+ (xn-1 * nn-1) + (xn * nn) |
|
--------------------------------------------------------------------------------------- |
|
|
N |
B) media geométrica: se eleva cada
valor al número de veces que se ha repetido. Se multiplican todos estos
resultados y al producto final se le calcula la raíz "n" (siendo
"n" el total de datos de la muestra). ![]()
2.- mediana (m) es el “valor central” de un histograma. Es el valor de la
serie de datos que se sitúa justamente en el centro de la muestra. Para hallar la mediana de una distribución debemos: 1. Ordenar las observaciones en orden ascendente. 2.
Si el número de observaciones n
es impar, m es la observación
central de la lista ordenada. M se
halla contando (n+1)/2 observaciones
desde el comienzo de la lista. 3. Si el número de observaciones n es par, m es la media de las dos observaciones centrales de la lista
ordenada.
|
Ejemplo: los salarios de 7empleados fueron los siguientes (en 1000): 28, 60, 26, 32, 30, 26, 29. ¿Cuál es la
mediana? nro. De observaciones es impar. Primero,
ordenar los salarios. Luego, localizar el valor en el medio 26,26,28,29,30,32,60 |
Supongamos que se agrega al grupo el salario de un
empleado más (31,000). ¿Cuál es la mediana?
nro. De observaciones es par. Primero, ordenar los
salarios. Luego, localizar el valor en el medio hay dos valores en el
medio 26,26,28,29.5,30,31,32,60 |
 3.- moda: es el valor que ocurre
con mayor frecuencia en la muestra (observación).
3.- moda: es el valor que ocurre
con mayor frecuencia en la muestra (observación).

Media, mediana y moda: si una distribución es simétrica, la media, mediana y modo
coinciden 
|
Si una distribución no es simétrica,
las tres medidas difieren |
|||
|
|
Asimetría hacia la Derecha (asimetría positiva) |
|
Asimetría hacia la Izquierda (asimetría negativa) |


5.- Medidas de posición
no central: serie de valores que dividen la
muestra en tramos iguales:
- Cuartiles: hay 3 cuartiles que
dividen a una distribución en 4 partes iguales: 1º., 2º y 3º. Cuartel,
ordenada de forma creciente o decreciente, en los que cada uno de ellos
concentra el 25% de los resultados.
- Deciles: hay 9 deciles que
la dividen en 10 partes iguales: (1º. Al 9º. Decil)., ordenada de forma
creciente o decreciente, en los que cada uno de ellos concentra el 10% de
los resultados.
- Percentiles: hay 99 percentiles
que dividen a una serie en 100 partes iguales: (1º. Al 99 percentil),
ordenada de forma creciente o decreciente, en cien tramos iguales, en los
que cada uno de ellos concentra el 1% de los resultados.
6.- Medidas de dispersión o variabilidad: estudia la distribución de los
valores de la serie, analizando si estos se encuentran más o menos
concentrados, o más o menos dispersos.
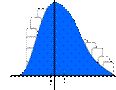
|
Ejemplo de dos conjuntos de datos con igual media |
|||
|
|
Datos con
baja dispersión |
|
Datos con
alta dispersión |

Medidas de
dispersión más utilizadas:
1.- rango: es calcular el recorrido de la distribución empírica, es
decir, la diferencia entre las observaciones máxima y mínima.
![]() 2.- varianza: mide la
distancia existente entre los valores de la serie y la media.
2.- varianza: mide la
distancia existente entre los valores de la serie y la media.
![]() De forma compacta:
De forma compacta:
3.- Desviación típica o
distribuciones normales: se calcula como raíz cuadrada de la varianza. La curva de densidad de una distribución
normal se describe por su media m y su desviación
estándars.
Propiedades de la desviación estándar: a)
s mide la dispersión respecto a la
media, b) s = 0 solo ocurre cuando no hay dispersión: todas las observaciones
toman el mismo valor. De lo contrario s >
0. c) cuanto más dispersión hay
entre las observaciones, mayor es s. d)
s, al igual que la media, se
encuentra fuertemente influenciado por las observaciones extremas
4.- Coeficiente de
variación de Pearson: se calcula como cociente entre la desviación típica y la media.
7.- Medidas de forma: grado de concentración.
Las medidas de forma permiten comprobar si
una distribución de frecuencia tiene características especiales como simetría,
asimetría, nivel de concentración de datos y nivel de apuntamiento que la
clasifiquen en un tipo particular de distribución. Son necesarias para
determinar el comportamiento de los datos y así, poder adaptar herramientas
para el análisis probabilístico. Las medidas de forma son instrumentos que
analizan la mayor o menor concentración o equidad en una distribución. Estas
medidas son de gran interés en distribuciones donde ni la media ni la varianza
son significativas.
Las medidas de forma permiten conocer que forma tiene la curva
que representa la serie de datos de la muestra. En concreto, podemos estudiar
las siguientes características de la curva:
A) concentración:
mide si los valores de la variable están más o menos uniformemente repartidos a
lo largo de la muestra.
B) asimetría:
mide si la curva tiene una forma simétrica, es decir, si respecto al centro de
la misma o centro de simetría los segmentos de curva que quedan a derecha e
izquierda son similares.
C) curtosis:
mide si los valores de la distribución están más o menos concentrados alrededor
de los valores medios de la muestra.
Concentración.
Para medir el nivel de concentración de
una distribución de frecuencia se pueden utilizar distintos indicadores, entre
ellos los más utilizados son el índice
de gini y la curva de lorentz.
A continuación se presenta la formula del
índice de gini:
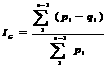
Siendo ![]()
![]()
De manera más detallada, explicamos el
cálculo de la formula del índice de gini:
|
Ig = |
(pi - qi) |
|
---------------------------- |
|
|
pi |
|
|
(i toma valores entre 1 y n-1) |
|
En donde pi mide el porcentaje de
individuos de la muestra que presentan un valor igual o inferior al de xi.
|
Pi = |
N1 + n2 + n3 + ... + ni |
|
|
---------------------------- |
X 100 |
|
|
N |
|
Mientras que qi se calcula aplicando la
siguiente fórmula:
|
Qi = |
(x1*n1) + (x2*n2) + ... + (xi*ni) |
|
|
----------------------------------------------------- |
X 100 |
|
|
(x1*n1) + (x2*n2) + ... + (xn*nn) |
|
El indice
gini (ig) puede tomar valores entre 0 y 1:
Ig = 0: concentración
mínima, la muestra está uniformemente repartida a lo largo de todo su rango.
Ig = 1: concentración
máxima, un sólo valor de la muestra
acumula el 100% de los resultados.
Ejemplo: Procedemos
a calcular el índice gini de una serie de datos con los sueldos de los
empleados de una empresa
|
Sueldos |
Empleados
(frecuencias absolutas) |
Frecuencias
relativas |
||
|
(millones) |
Simple |
Acumulada |
Simple |
Acumulada |
|
3,5 |
10 |
10 |
25,0% |
25,0% |
|
4,5 |
12 |
22 |
30,0% |
55,0% |
|
6,0 |
8 |
30 |
20,0% |
75,0% |
|
8,0 |
5 |
35 |
12,5% |
87,5% |
|
10,0 |
3 |
38 |
7,5% |
95,0% |
|
15,0 |
1 |
39 |
2,5% |
97,5% |
|
20,0 |
1 |
40 |
2,5% |
100,0% |
Calculamos los valores que necesitamos
para aplicar la fórmula del índice de gini:
|
Xi |
Ni |
ni |
Pi |
Xi * ni |
xi * ni |
Qi |
Pi - qi
|
|
3,5 |
10 |
10 |
25,0 |
35,0 |
35,0 |
13,6 |
10,83 |
|
4,5 |
12 |
22 |
55,0 |
54,0 |
89,0 |
34,6 |
18,97 |
|
6,0 |
8 |
30 |
75,0 |
48,0 |
147,0 |
57,2 |
19,53 |
|
8,0 |
5 |
35 |
87,5 |
40,0 |
187,0 |
72,8 |
15,84 |
|
10,0 |
3 |
38 |
95,0 |
30,0 |
217,0 |
84,4 |
11,19 |
|
15,0 |
1 |
39 |
97,5 |
15,0 |
232,0 |
90,3 |
7,62 |
|
25,0 |
1 |
40 |
100,0 |
25,0 |
257,0 |
100,0 |
0 |
|
|
|
|
|
|
|
|
|
|
pi (entre 1 y n-1) = |
435,0 |
|
(pi - qi) (entre 1 y n-1 ) = |
83,99 |
|||
|
por lo tanto: Ig = 83,99 / 435,0 = 0,19 |
|
||||||
Un índice gini
de 0,19 indica que la muestra está bastante uniformemente
repartida, es decir, su nivel de concentración no es excesivamente alto.
Otro
ejemplo: En una empresa existen cuatro categorías profesionales
y cada una tiene unos niveles de ingresos mensuales diferentes. La distribución
de frecuencias que expresa los niveles de ingresos y el número de personas en
cada categoría es la siguiente:
|
Ingresos |
100.000 |
200.000 |
300.000 |
400.000 |
|
Nº personas |
25 |
10 |
4 |
1 |
Obtener
el índice de gini y comentar el resultado. Obtener la curva de lorentz.
|
Xi |
Ni |
Xini |
Ni |
Ui |
Pi= |
Qi= |
|
100.000 |
25 |
2.500.000 |
25 |
2.500.000 |
62,50 |
40,98 |
|
200.000 |
10 |
2.000.000 |
35 |
4.500.000 |
87,50 |
73,77 |
|
300.000 |
4 |
1.200.000 |
39 |
5.700.000 |
97,50 |
93,44 |
|
400.000 |
1 |
400.000 |
40 |
6.100.000 |
100 |
100 |
|
|
N =40 |
|
|
|
|
|
![]()
Al tomar un valor próximo a cero podemos
decir que existe una
buena distribución de la renta.

La Curva de Lorentz quedaría de la siguiente manera
8.- Medidas de
forma: coeficiente de asimetría.
Las medidas de la asimetría, al igual que
la curtosis, van a ser medidas de la forma de la distribución, es frecuente que
los valores de una distribución tiendan a ser similares a ambos lados de las
medidas de centralización. La simetría es importante para saber si los valores
de la variable se concentran en una determinada zona del recorrido de la
variable.
Hemos comentado que el concepto de
asimetría se refiere a si la curva que forman los valores de la serie presenta
la misma forma a izquierda y derecha de un valor central (media aritmética)
Para medir el nivel de asimetría se
utiliza el llamado coeficiente de
asimetría de fisher, que se define con la siguiente formula:

Los resultados pueden ser los siguientes:
G1
= 0 distribución
simétrica; existe la misma concentración de valores a la derecha y a la
izquierda de la media
G1
> 0 distribución asimétrica
positiva; existe mayor concentración de valores a la derecha de la media que a
su izquierda
G1
< 0 distribución
asimétrica negativa; existe mayor concentración de valores a la izquierda de la
media que a su derecha
Curvas
|
As<0 |
As=0 |
As>0 |
|
Asimetría negativa a la izquierda
|
Simétrica
|
Asimetría positiva a la derecha. |



Ejemplo: Procedemos
a calcular el coeficiente de asimetría de Fisher de la serie de datos referidos
a la estatura de un grupo de alumnos.
|
Variable |
Frecuencias absolutas |
Frecuencias relativas |
||
|
(valor) |
Simple |
Acumulada |
Simple |
Acumulada |
|
1,20 |
1 |
1 |
3,3% |
3,3% |
|
1,21 |
4 |
5 |
13,3% |
16,6% |
|
1,22 |
4 |
9 |
13,3% |
30,0% |
|
1,23 |
2 |
11 |
6,6% |
36,6% |
|
1,24 |
1 |
12 |
3,3% |
40,0% |
|
1,25 |
2 |
14 |
6,6% |
46,6% |
|
1,26 |
3 |
17 |
10,0% |
56,6% |
|
1,27 |
3 |
20 |
10,0% |
66,6% |
|
1,28 |
4 |
24 |
13,3% |
80,0% |
|
1,29 |
3 |
27 |
10,0% |
90,0% |
|
1,30 |
3 |
30 |
10,0% |
100,0% |
Recordemos que la media de esta muestra es
1,253
|
((xi
- x)^3)*ni |
((xi
- x)^2)*ni |
|
0,000110 |
0,030467 |
|
|
(1/30) * 0,000110 |
|
|
G1 = |
------------------------------------------------- |
= -0,1586 |
|
|
(1/30)
* (0,030467)^(3/2) |
|
Luego:
Por lo tanto el coeficiente de Fisher de simetría de esta muestra es -0,1586, lo
que quiere decir que presenta una distribución asimétrica negativa, se concentran más valores a la izquierda de
la media que a su derecha.
Entre otros métodos para medir la
asimetría encontramos:
- Comparando
la media y la moda.
- Comparando
los valores de la variable con la media.
Si la diferencia ![]() es positiva,
diremos que hay asimetría positiva o a la derecha, en el caso de que sea
negativa diremos que hay asimetría negativa o a la izquierda.
es positiva,
diremos que hay asimetría positiva o a la derecha, en el caso de que sea
negativa diremos que hay asimetría negativa o a la izquierda.
No obstante, esta medida es poco operativa
al no ser una medida relativa, ya que está influida por la unidad en que se
mida la variable, por lo que se define el coeficiente de asimetría como:

Esta medida es muy fácil de calcular, pero
menos precisa que el coeficiente de asimetría de pearson.
El coeficiente de asimetría de pearson, se
basa en la comparación con la media de todos los valores de la variable, así que
es una medida que se basará en las diferencias ![]() , si medimos
la media de esas desviaciones sería nulas, si las elevamos al cuadrado, serían siempre
positivas por lo que tampoco servirían, por lo tanto precisamos elevar esas
diferencias al cubo.
, si medimos
la media de esas desviaciones sería nulas, si las elevamos al cuadrado, serían siempre
positivas por lo que tampoco servirían, por lo tanto precisamos elevar esas
diferencias al cubo.
 Para
evitar el problema de la unidad, y hacer que sea una medida escalar y por lo
tanto relativa, dividimos por el cubo de su desviación típica. Con lo que
resulta la siguiente expresión:
Para
evitar el problema de la unidad, y hacer que sea una medida escalar y por lo
tanto relativa, dividimos por el cubo de su desviación típica. Con lo que
resulta la siguiente expresión:
9.- Medidas de forma: coeficiente de curtosis.
El coeficiente
de curtosis analiza el grado de concentración que presentan los valores
alrededor de la zona central de la distribución. La curtosis es una medida del
apuntamiento, que nos indicará si la distribución es muy apuntada o poco
apuntada.
Se definen 3 tipos de distribuciones según
su grado de curtosis:
·
Distribución mesocúrtica: presenta
un grado de concentración medio alrededor de los valores centrales de la variable,
el mismo que presenta una distribución normal.
·
Distribución leptocúrtica: presenta
un elevado grado de concentración alrededor de los valores centrales de la
variable.
·
Distribución platicúrtica: presenta
un reducido grado de concentración alrededor de los valores  centrales
de la variable.
centrales
de la variable.
El coeficiente
de curtosis viene definido por la siguiente fórmula:
Los resultados pueden ser los siguientes:
G2
= 0 distribución mesocúrtica
G2
> 0 distribución leptocúrtica
G2
< 0 distribución platicúrtica
Curvas
|
Curtosis negativa |
Curtosis nula |
Curtosis positiva |
|
Platicúrtica
|
Mesocúrtica
|
Leptocúrtica
|

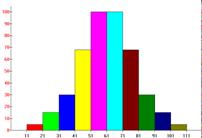
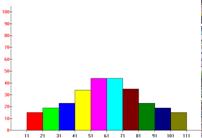
Ejemplo: Realizar
el cálculo del coeficiente de curtosis de la serie de datos referidos a la
estatura de un grupo de alumnos.
|
Variable |
Frecuencias absolutas |
Frecuencias relativas |
||
|
(valor) |
Simple |
Acumulada |
Simple |
Acumulada |
|
1,20 |
1 |
1 |
3,3% |
3,3% |
|
1,21 |
4 |
5 |
13,3% |
16,6% |
|
1,22 |
4 |
9 |
13,3% |
30,0% |
|
1,23 |
2 |
11 |
6,6% |
36,6% |
|
1,24 |
1 |
12 |
3,3% |
40,0% |
|
1,25 |
2 |
14 |
6,6% |
46,6% |
|
1,26 |
3 |
17 |
10,0% |
56,6% |
|
1,27 |
3 |
20 |
10,0% |
66,6% |
|
1,28 |
4 |
24 |
13,3% |
80,0% |
|
1,29 |
3 |
27 |
10,0% |
90,0% |
|
1,30 |
3 |
30 |
10,0% |
100,0% |
Recordemos que la media de esta muestra es
1,253
|
((xi
- xm)^4)*ni |
((xi
- xm)^2)*ni |
|
0,00004967 |
0,03046667 |
|
Luego: |
|
|
|
(1/30) * 0,00004967 |
|
|
|
G2 = |
------------------------------------------- |
- 3 |
= -1,39 |
|
|
((1/30) * (0,03046667))^2 |
|
|
Por lo tanto, el coeficiente de curtosis de esta muestra es -1,39, lo que
quiere decir que se trata de una distribución platicúrtica, es decir, con una
reducida concentración alrededor de los valores centrales de la distribución.
Ejemplo: Igualmente podemos observar, que el
coeficiente de curtosis nos mide el grado de apuntamiento de la distribución
utilizando la siguiente formula, donde podemos denotarlo por k y se
calcula según la siguiente expresión:

10.- Distribuciones Bidimensionales
Cuando
trabajamos en un estudio estadístico y observamos simultáneamente dos
caracteres en un mismo individuo obtenemos pares de resultados, por ejemplo, al
observar en una persona su edad y su peso. Los distintos valores de las
modalidades que pueden adoptar estos caracteres forman un conjunto de pares,
que representamos por (X, Y) y llamamos variable estadística
bidimensional.
Los
dos caracteres observados no tienen por qué ser de la misma clase, así nos
podemos encontrar con las siguientes situaciones:
|
Tipos |
variables ( X, Y ) |
Ejemplo |
|
Dos caracteres cualitativos |
Categórica / Categórica |
Sexo y color del pelo. |
|
Dos caracteres cuantitativos |
Discreta / Discreta |
Número de hermanos y número de hijos. |
|
Continua / Continua |
Perímetro craneal y perímetro torácico. |
|
|
Discreta / Continua |
Pulsaciones y temperatura. |
|
|
Uno cualitativo y otro cuantitativo |
Categórica / Discreta |
Sexo y número de libros leídos. |
|
Categórica / Continua |
Color del pelo y talla. |
Es
decir, ahora nuestra unidad de estudio es el par (X, Y) y dos pares están
repetidos cuando sus respectivos valores son iguales. Otro factor a tener en
cuenta es que el número de modalidades distintas que adopta el carácter X no
tiene por qué ser el mismo que el que adopta el carácter Y:
X
= { x1, x2, x3, ..., xs
} ; Y = { y1, y2,
y3, ..., yt }
Ordenación
de datos: Tablas
|
Parece que lo más lógico es ordenar
éstos pares de datos en una tabla de doble entrada, donde
tengan cabida los s valores de la variable X y
los t valores de la variable Y. Donde nij
es el número de veces que aparece repetido el par (xi,
yi) y que llamaremos frecuencia absoluta del
par (xi, yi). |
|
|
Una
tabla de doble entrada también se puede expresar como una tabla simple,
de forma que siempre es posible pasar de una a otra según convenga. Las
tablas simples reflejan el comportamiento de la variable estadística
bidimensional (X, Y) a partir de los valores individuales que toman cada una
de las variables estadísticas unidimensionales X e Y. |
|


11.- Distribuciones marginales.
Las
distribuciones unidimensionales del total de los individuos de la población,
respecto a cada una de las características reciben el nombre de distribuciones marginales.
Distribución
marginal de
|
Y |
Frec. absolutas marginales de Y |
|
y1 y2 . .yr |
n’1 n’2. . n’r |
Análogamente la distribución marginal de la X
Ejemplo. Obtener la
distribución marginal de la variable X.
|
X |
Frec.
absolutas marginal de X |
|
1 2 3 |
3 5 2 |
Si
en la tabla de correlación consideramos la primera columna y una columna
intermedia, la correspondiente a yj, se obtiene una distribución
unidimensional que llamaremos distribución
condicionada de la variable X por la modalidad yj de la
variable Y.
|
X |
Frec.
absolutas condicionadas por yj |
|
x1 x2 . . xk |
n1j n2j . . nkj |
|
|
|
|
|
|
|
|
|
Análogamente
se define la distribución condicionada
de la variable Y por la modalidad xi de la variable X.
Ejemplo. Obtener la tabla de la
distribución condicionada de la variable Y por la modalidad x2.
|
Y |
Frec.
absolutas condicionadas por x2 |
|
2 3 4 5 |
0 2 1 2 |
|
|
|
|
|
|
Conclusiones:
La Estadística es una disciplina que
utiliza recursos matemáticos para organizar y resumir una gran cantidad de datos
obtenidos de la realidad, e inferir conclusiones respecto de ellos.
Por ejemplo, la estadística
interviene cuando se quiere conocer el estado sanitario de un país, a través de
ciertos parámetros como la tasa de morbilidad o mortalidad de la población.
En este caso la
estadística describe la muestra en términos de datos organizados y resumidos, y
luego infiere conclusiones respecto de la población.
Aplicada a la investigación
científica, también infiere cuando provee los medios matemáticos para
establecer si una hipótesis debe o no ser rechazada.
La estadística puede
aplicarse a cualquier ámbito de la realidad, y por ello es utilizada en física,
química, biología, medicina, astronomía, psicología, sociología, lingüística, demografía,
etc.
Existen varias formas de
clasificar los estudios estadísticos:
1) Según la etapa.- Hay una estadística descriptiva y una
estadística inferencial. La primera etapa se ocupa de describir la muestra, y
la segunda etapa infiere conclusiones a partir de los datos que describen la
muestra (por ejemplo con respecto a la población).
2) Según el tiempo considerado.- Dentro de la estadística
descriptiva se distingue la estadística estática o estructural, que describe la
población en un momento dado (por ejemplo la tasa de nacimientos en determinado
censo), y la estadística dinámica o evolutiva, que describe como va cambiando
la población en el tiempo (por ejemplo el aumento anual en la tasa de
nacimientos).
3) Según la cantidad de variables estudiada.- Desde este punto
de vista hay una estadística univariada (estudia una sola variable, como por
ejemplo la inteligencia, en una muestra), una estadística bivariada (estudia cómo
están relacionadas dos variables, como por ejemplo inteligencia y alimentación),
y una estadística multivariada (que estudia tres o más variables, como por
ejemplo como están relacionados el sexo, la edad y la alimentación con la
inteligencia).
Las
Estadística, por otro lado, si no se sabe manejar con cautela puede generar
resultados falaces que podrían a su vez llevar a la toma de decisiones
erradas. Por consiguiente se recomienda un estudio pleno y científico de
la materia a fin de que quien utilice sus servicios pueda hacerlo de manera
objetiva y con resultados satisfactorios.
Hoy
en día es imposible pensar en instituciones que manejan ciertos volúmenes de
datos e informaciones y que no utilicen sus herramientas para verificación,
planeación y seguimiento de políticas, estudios de factibilidades, etc.
Infografías:
http://www3.uji.es./mateu/Tema1-D37.doc Definiciones
de estadística
http://www.aulafacil.com/cursoestadistica/lecc-4-est.htm Cursos en gratis línea. Lección 4ª. de estadística. Medidas de Posición Central
http://knuth.uca.es/repos/l_edyp/pdf/febrero06/ Estadística descriptiva y probabilidad. Teoría y problemas 3a Edición. Autores: I. Espejo Miranda, F. Fernández
Palacín, M. A. López Sánchez. Publicaciones Universidad de Málaga.
http://sitios.ingenieria-usac.edu.gt/estadistica/estadistica2/estadisticadescriptiva.html Estadística
descriptiva. Conceptos básicos
http://www.unavarra.es/estadistica/i.t.t.imagen/descriptiva.pdf
Estadística descriptiva. Definiciones
fundamentales.
http://www.tuveras.com/estadistica/estadistica02.htm
Medidas descriptivas.
http://www.eumed.net/libros/2007a/239/7.htm
Medidas de forma.
http://www.eumed.net/libros/2007a/239/7a.htm
Tipos de distribuciones de frecuencia.
http://www.eumed.net/libros/2007a/239/7c.htm
Coeficiente de asimetría.
http://www.eumed.net/cursecon/libreria/index.htm
Eeumed●net biblioteca virtual.
392 libros gratis. En este sitio web puede encontrar gratis y accesible libremente, el
texto completo de diccionarios, libros, cursos, revistas, vídeos y
presentaciones multimedia sobre economía, derecho y otras ciencias sociales. El
grupo eumed●net está reconocido oficialmente por
la junta de Andalucía (sej 309) y está localizado en la Facultad de Derecho de
la Universidad de Málaga, España
http://ponce.inter.edu/cremc/estadistica.htm Sitio web. Universidad Interamericana de
Puerto Rico Recinto de Ponce.
Rivera, luz m. Estadística. Última
edición: marzo 9, 2001
http://personal5.iddeo.es/ztt/Tem/t15_distribuciones_bidimensionales.htm
Distribuciones Bidimensionale
http://carmesimatematic.webcindario.com/bidimensionales.htm
Distribuciones marginales
http://www.monografias.com/trabajos19/la-estadistica/la-estadistica.shtml
Bibliografías:
BATANERO, Carmen.
Significado y comprensión de las medidas de posición central. Departamento de didáctica de la matemática,
universidad de granada. Uno, 2000, 25, 41-58
RUIZ M., David. Manual de Estadística. Universidad Pablo de Olavide. Isbn:
84-688-6153-7. 91 págs.
SANZ,
J.A. y otros (1996): Problemas
de estadística descriptiva empresarial. Ed. Ariel Economía.
SPIEGEL, Murray R.
Probabilidad y Estadística. México. McGraw Hill. 1996.