![]() Copyright , май 2000 г.
Copyright , май 2000 г.
|
|
ИНТЕЛЛЕКТУАЛЬНАЯ ПОИСКОВАЯ МАШИНА
КОНЦЕПТУАЛЬНЫЙ ПРОЕКТ
(ЧАСТЬ 2)
В.Н. Поляков
Факультет Информатики и Экономики
Московский Государственный Институт Стали и Сплавов (Технологический Университет)
Кафедра экспериментальной и прикладной лингвистики
Московский государственный лингвистический университет
http://geocities/SiliconValley/Campus/7926/Polyakov/Polyakov.htm
|
Содержание |
|
1.Введение |
1.Введение
Как было показано в первой части проекта, основными нерешенными проблемами современных поисковых машин являются
Во второй части проекта предложено краткое описание предлагаемых способов решения этих проблем и изложены базовые принципы организации интеллектуальной поисковой машины (ИПМ).
При разработке настоящего проекта исходим из соображения, что нет единственного универсального средства решения проблем релевантности и полноты и необходимо разумное комбинирование всех известных и доступных на сегодняшний момент средств.
Эти средства надо разделить на две тесно связанные категории. Первая - это механизмы разрешения многозначности и увеличения полноты поиска, предоставленные пользователю в процессе формулирования запросов. Вторая - это способы решения проблем релевантности и полноты на уровне индексирования массива текстов. Вторые являются необходимой предпосылкой для задействования первых и используются на этапе подготовки базы текстов и индексов к работе в составе ИПМ.
2.1.Диалоговые средства разрешения лексической многозначности
Как отмечалось в первой части проекта, наиболее целесообразным принципом организации диалога пользователя с ИПМ, представляется гибкий сценарий, объединяющий несколько механизмов поиска, которые предлагаются пользователю в зависимости от первоначально сформулированного запроса и которые тот может активизировать или нет по своему усмотрению. Такую диалоговую процедуру можно назвать интеллектуальный поиск
.В проекте предлагается три базовых механизма разрешения лексической многозначности, которые необходимо разумно комбинировать и каждым из которых пользователь может воспользоваться в процессе формулирования запросов:
= лексикографический;
= частотный;
= семантический.
Лексикографический механизм сводится к переформулированию запроса с использованием предлагаемого списка словосочетаний, включающих ключевые слова, первоначально введенные пользователем. Способы формирования базы таких словосочетаний и методы индексирования текстов по словосочетаниям описаны в разделах "Описание инструментального комплекса подготовки лингвистического обеспечения
", "Описание блока подготовки массивов данных и индексов".|
Пример: |
|
С помощью лексикографического механима для запроса по ключевому слову масло система предложит следующий список словосочетаний: растительное м. животное м. сливочное м. смазочные масла авиационное м. автотракторное м. арахисовое м. ацетоновое м. белое м. вазелиновое м. веретенное м. всесезонное м. и т.д. Разумеется, в список попадут только те словосочетания, которые встречаются в текстовой базе данных. |
Частотный механизм
сводится к переформулированию запроса с использованием предлагаемого списка частотных кластеров, включающих ключевые слова, первоначально введенные пользователем. Частотным кластером будем называть список слов, представляющих наболее часто встречающуюся комбинацию для текстов заданной тематики. Способы формирования базы частотных кластеров и методы индексирования текстов по частотным кластерам также описаны в разделах "Описание инструментального комплекса подготовки лингвистического обеспечения", "Описание блока подготовки массивов данных и индексов".|
Пример: |
|
С помощью частотного механима для запроса по ключевому слову масло система предложит следующий список кластеров: Масло, автомобили, моторы, техосмотр Масло, продукты, пища, еда, диета Масло, холст, пастель, графика, картина, галлерея, выставка и т.д. |
Семантический механизм
сводится к переформулированию запроса с использованием предлагаемого списка лексических значений для введенных ключевых слов. Лексическое значение выводится в виде слова, или словосочетания, описывающего категорию понятий, к которому относится значение. Описание способов формирования базы лексических значений и методов индексирования текстов по ним находится в разделах "Описание инструментального комплекса подготовки лингвистического обеспечения", "Описание блока подготовки массивов данных и индексов".|
Пример: |
|
С помощью семантического механима для запроса по ключевому слову масло система предложит следующий список лексических значений: Масло, как смазка Масло, как пищевой продукт Масло, как масляная краска Масло, как картина, написанная масляной краской |
2.2.Диалоговые средства разрешения коммуникативной многозначности
В проекте предусмотрено два механизма уточнения коммуникативных целей пользователя:
= частотный
= семантический
Частотный механизм сводится к предоставлению пользователю списка видов деятельности, связанных с введенными ключевыми словами (с/сочетаниями), выбор из которого позволит сузить объем выдаваемой информации. Способы формирования списка видов деятельности и методы индексирования текстов по ним описаны в разделах "Описание инструментального комплекса подготовки лингвистического обеспечения", "Описание блока подготовки массивов данных и индексов".
|
Пример: |
|
С помощью частотного механима для запроса по ключевому слову масло система предложит следующий список видов деятельности, сформированный с учетом выбора лексического значения смазка :Масло, торговля, бизнес Масло, производство Масло, сертификация Масло, техобслуживание автомобилей Масло, работа Масло, научные исследование Масло, учеба и т.д. |
Семантический механизм
сводится к предоставлению пользователю списка уточняющих вопросов, связанных с веденными ключевыми словами (с/сочетаниями), ограничивающих выбор. Способы формирования списка уточняющих вопросов и методы индексирования текстов по ним описаны в разделах "Описание инструментального комплекса подготовки лингвистического обеспечения", "Описание блока подготовки массивов данных и индексов".|
Пример: |
|
Семантический механизм для запроса по ключевому слову масло предложит пользователю следующий список уточняющих вопросов: Масло. Где купить? Масло. Где продать? Масло. Кто продает? Масло. Кто покупает? Масло. Сколько стоит? Масло. Где разместить рекламу? Масло. Кто производит? Масло. Как производить? Масло. Как упаковать? Масло. Как транспортировать? Масло. Как сертифицировать Масло. Где заменить в автомобиле? Масло. Как заменить в автомобиле? Масло. Где найти работу? Масло. Как исследовать? Масло. Как запатентовать? Масло. Где учиться? и т.д. |
2.3.Диалоговые средства увеличения полноты поиска
В проекте ИПМ предусмотрено пять механизмов повышения полноты поиска:
= когнитивная морфология;
= поиск по списку однокоренных слов;
= поиск по списку синонимов;
= поиск по онтологии;
= ассоциативный поиск.
Расширение запроса средствами когнитивной морфологии, применяется в случаях, когда ключевое слово, введенное пользователем, отсутствует в базе текстов. В этом случае пользователю предлагается четыре варианта выбора:
= похожее слово, полученное путем выявления потенциальных орфографических ошибок;
= лексическое значение, полученное путем анализа морфоструктуры;
= категориальное значение, полученное путем анализа имен собственных;
= похожее слово, полученное путем транскрибирования с английского на русский (или наоборот).
Поиск по списку однокоренных слов осуществляется по заранее подготовленному списку. Пользователю предлагается список, включающий однокоренные слова с ключевым словом. Способы формирования списка однокоренных слов и методы индексирования текстов по ним описаны в разделах "Описание инструментального комплекса подготовки лингвистического обеспечения", "Описание блока подготовки массивов данных и индексов".
|
Пример: |
|
Механизм поиска по списку однокоренных слов для запроса по ключевому слову масло предложит пользователю следующий список маслобак маслобензостойкость маслобойка и т.д. |
Поиск по списку синонимов
осуществляется по заранее подготовленному списку. Пользователю предлагается список, включающий синонимы для ключевого слова. Способы формирования списка синонимов и методы индексирования текстов по ним описаны в разделах "Описание инструментального комплекса подготовки лингвистического обеспечения", "Описание блока подготовки массивов данных и индексов".Поиск по онтологии сводится к предоставлению пользователю списка слов, находящихся в тесной семантической связи с введенными ключевыми словоми. Способы формирования онтологий и методы индексирования текстов по ним описаны в разделах "Описание инструментального комплекса подготовки лингвистического обеспечения",
"Описание блока подготовки массивов данных и индексов".|
Пример: |
|
Механизм поиска по онтологиям для запроса по ключевому слову масло предложит пользователю следующий список расширения поиска: Масло-> смазка Масло-> горючий продукт Масло-> жидкость Масло-> предмет купли-продажи Масло-> объект исследования Масло-> расходный материал в автомобилях Масло-> продукт питания Масло-> кулинарный продукт и т.д. |
Необходимо отметить, что поиск по онтологии не означает замену поиска по одним ключевым словам поиском по другим словам. При поиске по онтологии задействуются семантические связи, скрытые в словосочетаниях. Напротив, ассоциативный поиск предполагает переход по онтологическим связям к другим, семантически близким категориальным словам и, далее, использование этих слов в качестве запроса. Таким образом ассоциативный поиск можно рассматривать как рекурсивный (т.е. циклический) поиск с использованием всех возможностей разрешения многозначности, описанных ранее.
Кроме того, средства разрешения многозначности, описанные ранее, могут одновременно выступать и как средства расширения полноты поиска, если предусмотреть множественный выбор из предлагаемых списков и выбор сразу всех значений.
Описанные механизмы расширения полноты поиска надо рассматривать как своего рода крайнюю меру, которая применяется в следующих случаях:
2.4.Настройка на индивидуальный профиль пользователя
Одним из средств повышения интеллектуального уровня ПМ и уровня комфортности работы пользователя с ней является настройка на индивидуальный профиль пользователя. В системе должны быть предусмотрены средства регистрации пользователей и механизмы установки по умолчанию значений из списков в соответствии с опциями настройки. Предусматриваются три опции, регламентирующие порядок установки значения по умолчанию:
2.5.Фильтрация и группирование информации
Интеллектуальные средства фильтрация и группирования информации можно рассматривать как один из механизмов устранения информационного шума. ИПМ должна иметь средства выявления дублирующих друг друга записей в БД и их фильтрации, т.е. в выходном списке должна быть только одна запись. Другим способом борьы с шумом является группирование близких по теме страниц с одного сайта в одном блоке
.2.6.Вывод информации в файл
Считаю, что целесообразно рассмотреть возможность вывода информации в файл (с ограничением максимального количества записей) и загрузки его на компьютер пользователя в режиме download. Это может оказаться привлекательным для категории пользователей с низким трафиком или пользователей, которые работают в режиме экономии.
2.7.Структура программного обеспечения
ИПМ включает следующие семь программных компонентов:- интерфейсный блок
- поисковый блок- блок формирования рабочих массивов базы данных - блок инструментальных средств настройки и сопровождения лингвистического обеспечения
- блок сбора и анализа статистики
- блок диспетчера запросов
- блок диагностики сбоев
Взаимодействие блоков ИПМ представлено на рис 1.
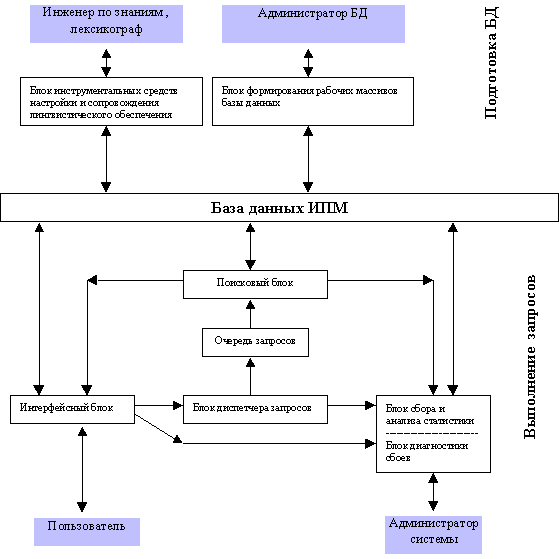
Рис.1 Схема взаимодействия программных блоков ИПМ
3.Описание интерфейсного блока
И
нтерфейсный блок предназначен для:Сценарием поиска предусмотрены следующие формы экранов (Рис 2-5):
Первый шаг сценария (Рис.2.) активизируется после ввода пользователем ключевого слова (нескольких слов, словосочетаний) и предназначен для разрешения лексической многозначности.
Второй шаг сценария (Рис.3.) активизируется после выбора пользователем на первом шаге одного или нескольких из предложенных словосочетаний, кластеров, значений и предназначен для разрешения коммуникативной многозначности.
Третий шаг сценария (Рис.4.) активизируется сразу или после шагов 2,3, если в результате запроса пользователя не будет обнаружено ничего или список сайтов будет небольшим (n <= 10).
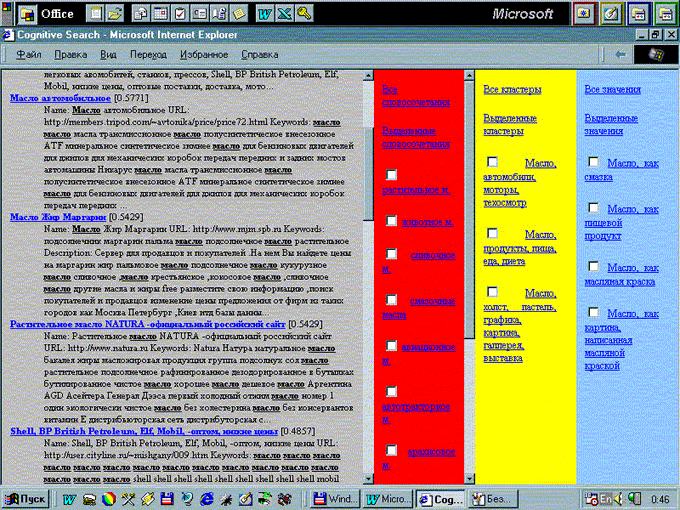
Рис 2.Шаг 1 сценария : разрешение лексической многозначности
(включает 4 фрейма: 1- список первоначально обнаруженных узлов; 2 - список словосочетаний; 3 - список частотных кластеров; 4 - список значений)
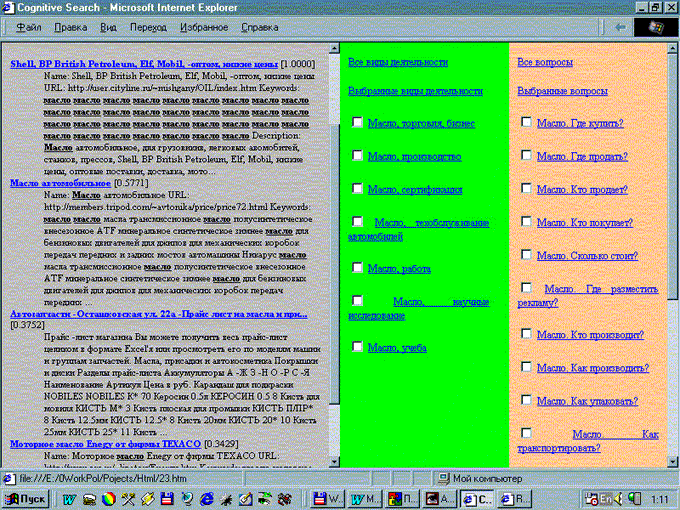
Рис 3.Шаг 2 сценария : разрешение коммуникативной многозначности
(включает 3 фрейма: 1- уточненный список первоначально обнаруженных узлов; 2 - список видов деятельности; 3 - список вопросов)
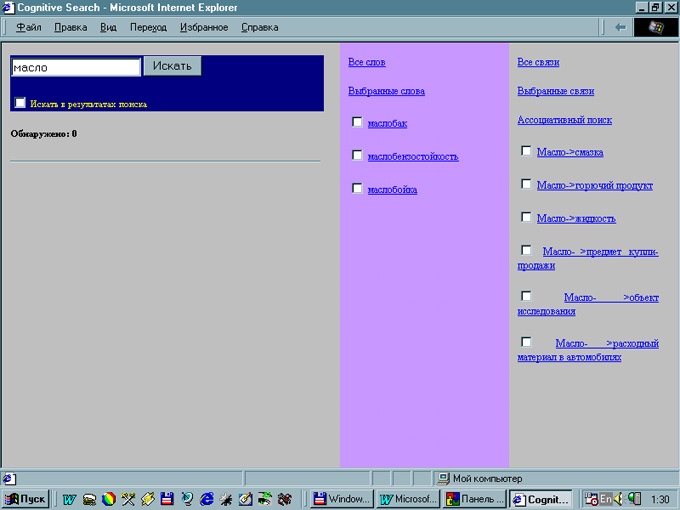
Рис 4.Шаг 3 сценария : раcсширение полноты поиска
(включает 3 фрейма: 1- уточненный список первоначально обнаруженных узлов; 2 - список словообразований; 3 - список связанных категорий/понятий)
4.Заключение
Во второй части концептуального проекта рассмотрены следующие вопросы: общие технические решения, средства повышения интеллектуального уровня ПМ, диалоговые средства разрешения лексической и коммуникативной многозначности, диалоговые средства расширения полноты поиска, структура программного обеспечения, общий подход к организации интерфейса ИПМ. Третья часть включает более подробное описание блоков, описание механизмов формирования лингвистического обеспечения и БД, описание экспертной системы для организации поиска в соответствии с грамматическими и семантическими признаками введенных слов, описание методов расчета численных критериев релевантности.