Respuesta
El problema a resolver es salvar la barrera del idioma en el proceso de búsqueda, lo que nos va a llevar al estudio de la recuperación de información multilingüe, realizar la consulta en un idioma origen y como resultado de la misma, obtener documentos distribuidos en varias colecciones de idiomas diferentes. Si sólo tenemos un idioma origen y un idioma destino, la búsqueda será bilingüe. Es importante el concepto de recuperación translingüe interactiva cuando el sistema proporcione asistencia para que un usuario formule sus consultas, identifique información relevante y sea capaz de refinar sus necesidades de búsqueda sobre información escrita en idiomas que desconoce, como se puede apreciar en [1], donde se habla de sugerir al usuario mediante interfaces interactivas. Esta búsqueda, vamos a dividirla en
Aspectos monolingües
Stemming
Es una de las técnicas que han resultado ser de mayor ayuda en la recuperación de la información , consiste en la obtención de la raíz de las palabras, de forma que el proceso de indexación se lleve a cabo sobre ellas en lugar de sobre las palabras originales. Si dos palabras tienen la misma raíz , pueden representar el mismo concepto y se pueden detectar las distintas formas morfológicas Un ejemplo de stemmer lo tenemos en la siguiente dirección web, obtenida a partir del artículo de Ostenero, Gonzalo y Verdejo:
Ejemplo de uso de un stemmer.
Si en el cuadro de texto introducimos la palabra "Wonderful" el stemmer nos dará la palabra "Wonder" . Si añadimos la palabra "excitement", tendremos una reducción a excit, como vemos en la siguiente captura de imagen: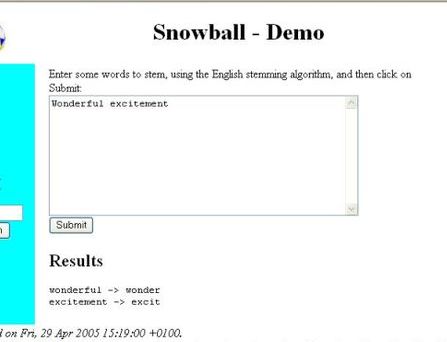
Otras alternativas a este algoritmo que Porter presentó en el 2001 serían los algoritmos SPLIT y STON de los que se puede consultar en [4] una buena introducción. La diferencia principal entre estos algoritmos y el anterior estriba en el enfoque probabilístico de estos últimos, ya que por ejemplo SPLIT detecta los sufijos y prefijos que forman las palabras y selecciona como raíz de la misma la más probable. En cambio el primero se basa en un conjunto sencillo de reglas que truncan las palabras hasta obtener una raíz común. Una explicación de los algoritmos de stemming se encuentra en [5]
Segmentación de compuestos
La idea que subyace a la segmentación de palabras en idiomas aglutinativos como el holandés es que la descomposición de estas palabras en lemas individuales produce una significativa mejora en las búsquedas de este tipo de idiomas al considerar cada elemento de la palabra compuesta como un término. También aquí, como alternativa a los métodos lingüisticos se recurre a métodos estadísticos. Se ha probado a realizar búsquedas sobre hexagramas y tetragramas, cuyos resultados se combinan con una búsqueda de palabras sin procesamiento adicional. El resultado es el mejor sobre idiomas aglutinativos en el CLEF 2000. En [3] se tiene un buen ejemplo de este método.
Segmentación de palabras
Los idiomas chino, japonés y coreano no marcan de manera explícita en el texto los límites de las palabras. Por ello es necesario identificar las palabras individuales para mejorar el proceso de búsqueda. A la hora de indexar los textos escritos en estos idiomas existen dos aproximaciones principales:
- Indexación basada en texto segmentado que incluye la indexación de palabras y/o de sintagmas
- Indexación de caracteres basada en n-gramas. Fundamentalmente bigramas, ya que en japonés, chino y coreano, la longitud media de las palabras es de dos caracteres al ser idiomas silábicos
Pese a lo anterior no hay un consenso claro sobre cuál es la mejor aproximación (n-gramas o palabras) es mejor para la indexación en este tipo de idomas. En muchos casos lo mejor es realizar una combinación de ambas
Enfoques basados en la traducción de la consulta
Siempre será menos costoso computacionalmente la traducción de la consulta que la de todos los documentos, ya que la consulta es sensiblemente más pequeña, sin embargo nos enfrentamos a tres problemas principales cuando tratamos de traducir la consulta:
- Saber cómo un término escrito en un idioma puede ser escrito en otro idioma
- Decidir cuáles de las posibles traducciones de cada término son las adecuadas en cada contexto
- Saber cómo pesar la importancia de las diferentes traducciones que se consideran adecuadas
Diccionarios
El uso directo de los diccionarios no resuelve el problema de encontrar traducciones a los términos, debido a las siguientes razones:- La terminología específica de un determinado dominio del conocimiento no suele estar contemplado en los diccionarios de uso común
- No contemplan todas las posibles variantes morfológicas de una palabra. Este problema puede ser mitigado mediante el uso del stemming tal y como se explica en [6]
- Hay nombres propios o de localizaciones que no van a estar contempladas en el diccionario. Esto tiene que ver con el "reconocimiento de entidades"
- La polisemia de las palabras dificulta latraducción y no se cuenta con métodos automáticos que puedan resolveral satisfactoriamente
- Traducción errónea detérminos multipalabra, por ejemplo el típico refrán español "De perdidos al río", su traducción literal sería "From lost to the river", cosa que un angloparlante no entendería Se intenta mejorar la efectividad de las traducciones utilizando diccionarios de traducción de expresión multipalabra, tanto en [Ballesteros and Croft, 1997] como en [1].
(Pirkola,1998) estudió los efectos de diferentes factores, llegando a la conclusión de que las consultas realizadas con lenguaje natural tenían una mayor precisión que auqellas realizadas con únicamente las palabras y sintagmas más relevantes de la consulta. Tras combinar dos diccionarios, uno específico de medicina y salud y otro general, se dió cuenta de que la mejor traducción se obtenía al combinar estos diccionarios. La estructuración de la consulta-De acuerdo con los operadores proporcionados por el motor de búsqueda Inquery- resultó ser el factor que más incrementaba la precisión de las búsquedas.
Se han intentado utilizar idiomas pivote para realizar la traducción cuando no se dispone de un diccionario directo, pero los resultados provocan una mayor pérdida de eficiencia que la utilización de un diccionario directo. Sin embargo, como método de desambiguación se puede utilizar el seleccionar sólo aquellas traducciones que pueden volver a ser traducidas al término de partida. Esta es mejor estrategia que usar Corpora Paralelo.
Utilización de corpora
El corpora paralelo hace referencia a varias colecciones de documentos escritos en varios idiomas.
Hay diferentes tecnicas de uso de corpora paralelo, desde Traducción Mediante Ejemplo/EBMT a LSI pasando por PRF y GSVM, todas ellas con sus ventajas e inconvenientes:
- EBMT: Se parte de un corpus que contiene información acerca de la traducción de los sintagmas y frases contenidos en él. La principal desventaja es la necesidad de disponer de corpora paralelo alineado a nivel de sintagmas
- PRF: Consiste en asumir que los documentos que ocupan los primeros lugares del ranking devuelto por el sistema son relevantes para la consulta. Esta técnica no es siempre efectiva
- GVSM: Modelo de espacio vectorial: Los documentos son vectores y la similitud entre ellos se mide mediante los ángulos que forman éstos. La generalización del método requiere corpora paralelo alineado a nivel de documentos
- LSI: Es una extensión del método anterior:Mientras que en el VSM se utilizan palabras como base ortogonal del espacio ortogonal, en el latent semantic index se utiliza la combinación lineal de las dimensiones originales que posea mayor significado. Una explicación de LSI puede encntrarse en [11](Junto con otras explicaciones sobre recuperación de información)
En el artículo "Translingual Information retrieval: Learning from bilingual corpora", de Yang et al., se dice que el rendimiento del LSI es comparable al de los otros métodos basados en corpus. En este artículo se habla también del mejor rendimiento que se obtendría si en vez de consultas se tradujesen los documentos, pero es poco práctico debido al extenso tamaño de las coleccionesde documentos. De los tres enfoques utilizados en este artículo el peor resultó ser el usar un corpus que pasase de término a frase Los otros dos enfoques fueron una traducción basada en diccionario y otra una traducción de términos basada en corpus. El estudio comparativo llevado a cabo en el artículo previamente citado indica que los métodos basados en corpora clararamente superan a los métodos basados en diccionarios de propósito general aunque los resultados se aproximan cuando se auemntan los diccionarios con glosarios desarrollados para sistemas de Traducción Automática. Son interesantes las preguntas con las que acaba el citado artículo, por ejemplo: ¿Pueden estos métodos ser extendidos a corpora comparable(Documentos sobre el mismo tema en distintos lenguajes, en vez de traducciones exactas? Y otra es ¿Se puede producir automaticamente un corpora paralelo para parte de una colección? La última pregunta a la que prestaremos atención es a la que hace referencia al interfaz del usuario: ¿Cómo debe ser?
Una alternativa al uso de corpora paralelo econsiste en utilizar la propia colección de documentos como corpus de referencia, llevándose a cabo la desambigüación de sintagmas, formados por secuencias de nombres y parejas nombre-adjetivo, mediante corpora paralelo, alineado a nivel de documentos o mediante coocurrenica estadística. En el artículo Resolving Ambiguity for cross-language retrieval, Ballesteros y Croft se decantan por el método de coocurrencia.
Otra posibilidad son los programas comerciales de traducción automática, sin embargo la utilización conjunta de corpus y diccionarios obtuvieron mejores resultados. Sin embargo, en consultas basadas en frases dan mejor resultado, pero la creación de estos traductores es costosa por lo que sólo existen para los pares de idiomas más demandados del mercado.
Tesauros: Están formados por la colección de terminos o palabras clave que se utilizan para realizar la indexación de los documentos(ya sea esta manual o automática)así como las relaciones semántica que las unen. Debido a que es necesario disponer de corpus paralelo para poder hacer uno multilingüe los tesauros no son moneda común. Un ejemplo de tesauro multilingüe sería el metatesauro de UMLSEl problema de la fusión. Dado que cuando se obtiene un resultado de una búsqueda no se tiene una única lista de documentos ordenados por relevancia, sino que se dispone de varias de ellas. El problema de mezclar estas listas en una única se conoce con el nombre de fusión de listas de documentos y aún no ha sido resuleto por completo, como enfoque podríamos decir: Si se traduce la consulta y se hace una búsqueda monolingüe ¿Cómo efectuar la fusión de las listas separadas en cada idioma? O bien normalizamos las listas por separado o utilizamos un algoritmo riund-robin, pero los problemas de esta aproximaciones son que tanto la normalización como el round-robin sólo tienen en cuenta la colección a la que pertenece el documento, sin tener en cuenta las otras. Hay una estrategia, presentada en [Martínez-Santiago] que tiene en cuenta el peso relativo de cada término de la consulta para realizar una reindexación de los documentos formando una nueva colección multilingüe.
Otros enfoques
Traducción de documentos
Aquí volveríamos a hace hincapié en lo anteriormente dicho respecto a que la traducción de documentos sería deseable aunque no sea practicable, aunque se echan de menos estrategias intermedias entre traducción palabra por palabra-demasiado imprecisa- y la traducción automática-Demasiado costosa-
Traducción bidireccional
Se pueden traducir tanto la consulta como los documentos y comprobar que este sistema híbrido tendrá mejores resultados que traducir sólo una de las dos posibilidades.
Indexación conceptual
Otra posibilidad consiste en realizar la traducción tanto de las consultas como de los documentos a un vocabulario de indexación conceptual independiente del idioma, esto tiene varias ventajas como que se evita el problema de la fusión , es más escalable, utiliza desambiguación automática, pero las técnicas no han alcanzado todavía la madurez suficiente para un enfoque tan ambicioso. Por otro lado es difícil encontrar el nivel de representación conceptual adecuado para la tarea. Como ejemplo está el proyecto ITEM[1] que usa el índice interlingua de EuroWordNet
Interactividad en la Recuperación de información Multilingüe
En general no se han considerado la interactividad con el usuario como pieza fundamental del diseño, por ello la investigación en este campo está en sus comienzos. Ha sido a partir del iCLEF que se ha proporcionado una infraestructura y una metodología específicas para la realización de experimentos interactivos de recuperación translingüe de información. En el iCLEF 2002, en concreto se trataba de proporcionar un marco de referencia común para realizar experimentos comparando dos sistemas de recuperación de información translingüe que permitan a un usuario que desconoce el idioma de los documentos realizar una expansión interactiva de la consulta, una selección interactiva de documentos(al igual que el año anterior) o ambas opciones a la vez. En [López-Ostenero et al, 2002a] se aprovecha el uso de sintagmas nominales extraidos con el Website Term Browser y se mejora no sólo en la búsqueda sino también de cara a los usuarios, los cuales se manifiestan en contra de tener que seleccionar interactivamente los términos de traducción
Recapitulación
Los experimentos demuestran que la recuperación translingüe es perfectamente realizable y con un nivel de eficiencia cercano a una búsqueda monolingüe
Sin embargo, aún quedan diversos problemas:
- Dominio: La mayoría de las técnicas empleadas han sido probadas sólo sobre noticias de periódico(en las colecciones TREC, CLEF y NTCIR) y no se sabe si serán efectivas fuera de él
- Eficiencia: El coste computacional que supone una traducción adecuada de las consultas puede resultar excesivo para un entorno real de búsqueda, aparte que la calidad de las traducciones aún no es óptima
- Unificación:Normalmente se presentan dos clases de separaciones:
- Traducción y búsqueda: Los procesos de traducción y búsqueda se realizan, normalmente, por separado. De esta forma la incertidumbre de las traducciones no influye en el proceso de búsqueda
- Diferentes idiomas: cuando se realiza una búsqueda multilingüe, el problema de fusionar los resultados de cada una de las búsqueda monolingües en una única lista ordenada aún no ha sido resuelto
- Interacción: Los usuarios reales de los sistemas de búsqueda están interesados en la información contenida en los documentos, no en la lista ordenada que proporcionan los sistemas
Referencias bibliográficas y enlaces
- ITEM: Un motor de búsqueda multilingüe basado en indexación semántica
- Metodos de optimizacion de la extraccion de lexico bilingüe a partir de corpus paralelos
- Algoritmo de decodificación de traducción automática estocástica basada en N-gramas
- Modelos probabilísticos para la producción automática de stemmers
- What is Stemming?
- Lematización
- Base de datos de WordNet
- El motor de traducción automática SYSTRAN
- Las bases de datos bilingües de STRAND
- Enlace a PTMiner
- Presentación que explica el uso de LSI
- HTML & XHTML the Definitive Guide, de Chuck Musciano y Bill Kennedy, editorial O'Reillly
- Enlace al diccionario SMART
- Enlace a Website Term Browser
- Enlace a proyecto Mulinex