Faster and bigger search engines are not necessarily easier to use
By
Ding Choo Ming
Lecturer
Fakulti Teknologi & Sains Maklumat
Universiti Kebangsaan Malaysia
Abstract
There are some 300 search engines, the so-called search
tools used to retrieve the haphazardly organized information on the Internet.
Supported by many features, ranging from simple to complex, they enable
us to conduct basic and advanced searches. Over the years, they have grown
bigger in terms of their databases and more powerful in terms of speed,
thus capable of performing wonders if properly harnessed. But, it is a
misconception to assume that their size and speed can produce better search
results. Searching the WWW entails more than just typing the keywords and
waiting for the search engines to list the relevant URLs and hyperlinks,
which when clicked upon, display the related sites or documents. With the
deluge of information residing in over 320 million Web sites on the Internet,
a search for some specific and obscure information can be time-consuming
and frustrating. This is mainly due to the different indexing techniques
and value-added evaluation processes adopted by the different search engines,
Nevertheless, practice, experience, common sense, expertise and search
techniques too are crucial in any search. All these factors determine the
quality of the search results. It is thus, beneficial to study the unique
features, strengths and weaknesses of a few popular and recommended search
engines, regardless of their size and speed, before using them to conduct
searches.
Introduction
1.1 A search engine is not only an automated search tool used to find our way in the ever changing galaxy of information, but also a Web site that can be initiated to uncover a myriad of sites in the fabulous cyberspace. Built upon Hyper Text Transfer Protocol (HTTP), it instantaneously and constantly scans and examines Web sites, attempting to match the keyword(s) supplied by the users, and displaying the search results sorted according to their relevance. The two most striking features about these 300 or so search engines currently available are their impressive speed and size. AltaVista, for example, claims to have indexed some 50 million Web sites and more than 3 million articles from 17,000 Usenet groups. Cunningham (1996:53) notes that it is currently used by 30 million people every day. Similarly, WebCrawler is said to have 50,000 documents added or updated, distributed over 9,000 different servers and answers more than 6,000 queries daily. Such statistics are growing daily too with the other search engines. It cannot be denied that the size and speed of search engines play a role in luring people to the Internet or WWW - used interchangeably in this paper - to get information fast. Although the Internet contains only a fraction of all the information and knowledge in the world, more information is readily available today through the Internet which is basically a network of networks. Search engines are becoming progressively faster as all the scanning and matching are hyperlinked. Each of these hyperlinks activates a unique Internet address to prompt another computer to get new information or even more hyperlinks (Pevar 1996:16). By merely pointing and clicking, these self-instructional search engines display a clickable lists of hyperlinks, which may appear in different colors, leading to seemingly relevant documents or appropriate sites, URLs and others within seconds or minutes. Ostensibly, search engines make searching on the Internet simple and without the need for assistance. This means enormous saving of precious time. But, can search engines retrieve the relevant documents at all times? Does searching the WWW only entail typing a keyword to indicate our interest and then clicking the search button? This may be so with a simple search using Yahoo and Aliweb, but not those involving in-depth indexing and advanced searching where skill and competence are required. Again the total number of hits is not necessarily a valid measure of performance. It is the number that matches our interest that counts.
1.2 The Internet is a haphazardly organized information bazaar where we can find something on almost any topic, including more search engines, but not necessarily the relevant documents for every query. This is partly due to the hundreds of completely new Web sites that appear on the Internet daily, in addition to thousands of new Web sites to the existing ones (MacLeod,1997), and partly due to the search engines all of which provide the basic means of searching. Basically there are five ways of searching for information on the Internet, including browsing with a directory or sifting the information via a search engine. However, searching the Internet can be an exhaustive experience for those lacking the right search techniques, experience, and common sense, and failing to select the right search engines. Search engines are not designed to help users like novices who have only a passing knowledge of the Internet and often lack the search skill. The exponential growth in the number of Internet users, the number of documents published, the number of times these documents are accessed, as noted by Furner (1997:3), are the result of such a variety of inter-related factors as the universality of applications of Uniform Resource Locator (URL), the speed documents can be produced in Hyper Text Markup Language (HTML) format, the simplicity of the retrieval process supported by Hyper Text Transfer Protocol (HTTP) and easy use of the Web browsers, including the Netscape Navigator
Features and Options
2.1 All search engines offer a set of seemingly user-friendly search options in specifying searches and constructing queries as well as unique features in defining and redefining searches interactively. They are judged by the size of their databases, contents, types of searches, search tips, sorting options, result set presentation, update frequency, speed of search response, the relevancy of items, and the overall ease of use. The size of the databases may determine the number of hits which can be delivered. But, it is the quality of the indexing that forms the major factor in determining the degree of relevancy of items retrieved. Searching becomes complicated not only because of the nature in the organization of data in the different search engines, but also because of their ever growing size. Although the sophistication of search engines is important, the size of the database is also a factor to be considered. Lycos, for example, offers limited search capabilities and does not support phrase searching, but it is often successful where others fail, because it indexes the largest number of Web pages (Webster & Paul 1996). Nevertheless, we cannot assume that the bigger the databases, the better the chances of retrieving documents that directly relate to our search topic. Peggy and others (1996) state that NlightN and Yahoo are not powerful enough to handle queries effectively despite their significant databases, whereas Harvest and Magellan are powerful even though their databases are not comprehensive. In other words, figures quoted should not be interpreted at their face value. They give only an indication of the problems users encounter in searching what are available and new on the Web. AltaVista , for example, claims to scan and index every word in the millions of web pages and Usenet groups daily. This implies that its contents change daily and is able to respond to any query, though some hits may appear to be odd matches. Open Text and WebCrawler index the full text of documents. Yahoo is said to employ people to index and assign descriptions to web sites. Lycos indexes title headings and the most significant 100 words, with the rest of the text buried. Infoseek claims never to index a URL twice, thus implying that there are no duplicate entries. Lycos maintains that it can search for sites that contain any or all of our search terms. Infoseek and Open Text support proximity searches, meaning allowing us to search for terms that are adjacent or near to one another. The power behind the Open Text is that it indexes not only every word of a page, but also offers three types of searching: simple search, weighted search and power search. Weighted search in the Open Text allows us to assign a number the higher the number the greater the importance - to indicate the importance given to the terms. To most users, AltaVista is a superstar, because firstly, it attempts to track down every web page on the Internet; secondly, it indexes every word on each page, and thirdly, it provides a lot of tools to help users in defining, thus narrowing the search (Hancock:1996:75).To this list, must be added DejaNews which boasts of its capability of searching thousands of ongoing Usenet groups discussions worldwide, with millions of comments on almost everything, and allowing us to contact participants by e-mail for more information.
2.2 It is apparent that different search engines generate different
results. This could be due to the possibility of sites being submitted
to certain engines only, or sites that are too recent to be picked up by
robots, worms or spiders. Consequently, the same key words submitted to
different search engines produce different results (Webster & Paul
1996). Thus, Finch (1996:82) rightly notes that for one particular search,
a certain engine may give the best result. For another search, the best
result may come from a different engine. His advice, therefore, is to
conduct many searches using several different search engines to find as
many as possible on a topic. As no one search engine can satisfy all our
information needs at any one time, some effort should be devoted to examine,
compare and evaluate them in order to understand their strengths and weaknesses.
It is necessary and important to equip ourselves with tips and news about
the latest developments in search techniques published by the search engines
themselves or in journals such as Online, IFLA Journal,
Journal
of Information Science, Reference Librarian and VINE.
The diagram below provides some of the features peculiar to the following
search engines:
| Service
|
Cove-rage | Full Text | Bool-ean | Adj | Nest
() |
Field
Search |
Media | Rank | Dupl
Detect |
Trun cate |
|
Case Sens | B-Ward
|
| AltaVista www.altavista.com | 30M URLs & Use-net |
|
|
|
|
|
|
|
|
|
|||
| HotBot
www.hotbot.com |
54M URLs & Use-net |
|
|
|
|
|
|
|
|
|
|||
| Ultraseek
www.infoseek.com |
50M URLs
Use-net, more |
|
|
|
|
|
|
|
|
|
|||
| Lycos
www.lycos.com |
66M URLs
FTP, Goph-er |
|
|
|
|
|
|||||||
| Opentext
www.opentext.com |
1.5M URLs
& Use-net |
|
|
|
|
|
|
|
|
Gillian Westera ([email protected]) has also provided a list comparing user interface capabilities of seven search engines, including AltaVista and WebCrawler. Nevertheless, we cannot assume that information on the features and capabilities of search engines is a panacea for our search problems. Today, all search engines are fast with user-friendly features, which when properly harnessed can yield good results. Hence, the crux of a search problem is knowing the strengths and weaknesses of search engines, besides updating ourselves on the latest developments in search techniques which can be accomplished through constant use.
2.3 One reason why search engines are said to be user-friendly is that they support keyword and Boolean logic searching. They are now popular approaches in information searching following the emergence of online information systems. Keyword searches are linked to free-text searches which imply that any word or words in any order, as natural to use as possible, can be accepted as uniquely defining a particular concept. We cannot, however, assume that searching only involves typing the keywords while term matching and combination are handled by the search engines. For a search to be effective, it must contain a reasonable number of words necessary for matching. A specific search query, including the use of distinctive words would produce an Exact Match result, and not Any of the words match which retrieves widely irrelevant documents. It is generally assumed that documents having the same search terms are related subject wise. Such a relationship is done by a matching or comparison function, based on the statistical analysis of the frequency of the occurrence of search terms (Furner,1997:10). But not all the search engines treat keywords, including phrases, in the same manner. Some engines search and match the whole phrase; some search and match individual words in the phrase, while others search and match part of the whole phrase. When using Infoseek, we have to (i) use commas to separate phrases (which should be encased in quotes), (ii) hyphenate words that need to be next to one another, (iii) place a minus sign ( - ) before a word to indicate non-searching, (iv) use a plus sign ( + ) before a word to indicate that it must occur in the results returned, (v) capitalize all proper names and be sure to include commas between them, (vi) use brackets [ ] and the Proximity (or NEAR) operator to find words that appear within 100 or more, or near to one another, and (vii) treat pairs of capitalized words as a single phrase. All these commands will affect matching and enhance relevance. With Excite, we can place a plus ( + ) or minus ( - ) sign before a word, instead of AND and NOT. For example McCartney+Starr-Lemon is equivalent to MacCartney AND Starr AND NOT Lemon. In addition to combining words, we can also exercise control over words by using truncation and proximity. The former can be right-hand-truncation, left-hand-truncation or internal or infix truncation. An asterisk * (see example in 2.6) which is sometimes called a wild card character is meant to represent letter(s) before, after or within the truncated words.
2.4 There are many other ways of refining a search. It includes clicking on Improve Your Result in Open Text, or Customize Your search in Lycos. The latter allows us to (i) match terms which we are unsure of their correct spelling, (ii) change Loose Match to Strict Match to cut down on titles that are not too useful, thus fewer relevant hits, and (iii) get detailed information by selecting Detailed Result from Display Option menu. These options are given in the HELP pages of the respective engines. No two search engines are created equal and as such the do not offer the same search options. While giving a comprehensive overview of the search systems on the Internet, Martin Courtois and others (On-line November-December 1995) state that even search engines that offer advanced search techniques, provide search instructions that are either difficult to locate or to comprehend. However, the good news is that more features are simplified and they should enhance accuracy and precision. Meanwhile, it is also important for us to be able to select the appropriate search tools and search techniques, to evaluate them critically and to use them efficiently and effectively. This set of know-how is part and parcel of information literacy. Many of us however, fail to realize its full value. Given the myriad array of information on the Internet and constrained by limited time and patience, we normally settle for the engines that seem to consistently serve our needs.
2.5 The success of a search may also be influenced by the way the search
results are ranked and displayed. When listing the results, most search
engines begin with the seemingly most relevant documents. Thus, documents
further down the list are supposedly less relevant. The matching and ranking
of documents are normally based on criteria like (i) the occurrence of
the words in the texts, (ii) the frequency of occurrence of the words,
(iii) the fulfillment of search options like All of the Words,
Any of the Words, All the Words in the Phrase and Any Word
in the Phrase. Yet we cannot maintain that the highest ranked document
is the most desired document as search engines employ different methods
in ranking search results. Bates (1997:52) agrees that relevancy ranking
in search engines is always a problem, because it is based on the matching
of keywords. Some only look at the title, author, URL and codes; while
others examine the abstracts, keywords (subject representation), contents
of the pages, and construct an index based on actual words within the sites.
Keyword(s) in the title(s) may not necessarily reflect the contents of
the documents, but because of their occurrence in the titles, they receive
a higher ranking than the others. Infoseek ranks hits according to the
frequency of occurrence of search terms in the database, while Lycos ranks
them based on the number of terms found on the page, their proximity to
one another and their position on the page. These are some of the common
ranking algorithms search engines adopt to retrieve and rank relevant documents.
On clicking Sort by Site in Excite, we can group the returned
pages by location. It provides a quick way of finding sites that are related
to the topics selected. Ali (1993) studies the validity subject
relationship between the articles based on co-occurrence of the same keywords
by analyzing 100 entries from Science Citation Index and Social Science
Citation Index using the purposive sampling method. The documents retrieved
upon clicking Any of these Words button are widely irrelevant.
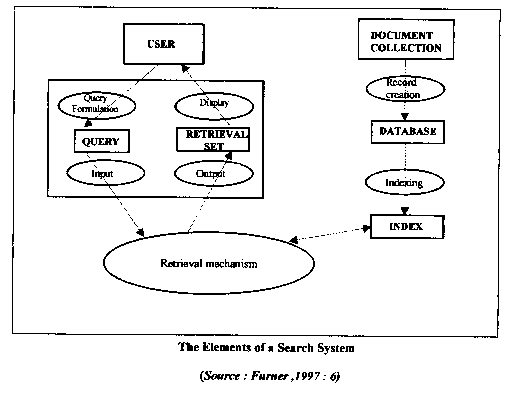
Some of the mechanisms used in information retrieval are shown in the following
figure:
|
|
|
| family AND planning | Both family and planning |
| family OR planning | Either family or planning |
| family AND NOT planning | family and not planing |
| family planning | The phrase family planning |
In a Proximity search, words are considered as a phrase, instead of
as independent keywords. But, proximity searches in WebCrawler requires
a number. For example, Raja Ali Haji NEAR/25Syed Sheikh al-Hadi retrieves
the two items, if available, within 25 words of each other. It is advisable
not to use Lycos for proximity searches as it has trouble handling terms
that start with numbers. However, to achieve greater recall, we can expand
the search with the aid of a thesaurus or Wild Card, through Word Stemming,
Truncation or String Searching. Yahoo supports Boolean and string searching,
while WebCompass includes a thesaurus to assist users in rephrasing the
original search. Below are examples of Wild Card searches:
|
|
|
| Omni* | Omnivoruous, omnipotent, omnipresent, omnificient |
| *cide | Suicide, fraticide, sororicide, matricide, mariticide, genocide, fungicide, insecticide, herbicide |
| ?age | Bandage, average, leverage, savage, agelese |
| 888-??? | All seven digits with the 888 as prefix |
| Pr?m* | Premature, pre-mediate, prim, prime, primate, promise, promotion |
As mentioned earlier, a good search engine provides sophisticated search options that not only enable us to refine our searches, but also to perform complex searches to yield higher precision. Upon reflection, they are merely automating basic Boolean search operations by rewriting, rephrasing and expanding our query. This subject relationship/ proximity technique, as Furner (1997:5) explains, supported by hypertext systems, allows the representation of inter-document relationships by links, which can be easily activated. The Power Search in Open Text allows us to indicate where we want the words to be searched: Anywhere, Summary, Title, or URL. Lycos too has modified Boolean searching with the ability to combine two out of three or more search terms, synonyms or concepts.
2.7 Despite the increasing availability of features and options, emphasizing on easy-to-use or do-it-yourself services, Internet searching is becoming more bewildering. Basically, there are five ways of searching the Internet, namely, surfing, keyword searching, thesaurus-aided searching, concept based or Boolean logic searching and browsing. Among them, surfing and browsing may be the more typical search methods among novices for various reasons. Firstly, most of them do not understand how search engines process keyword searches; secondly, they do not read or understand search instructions (Hildreth, 1997:61); thirdly, they have difficulties in understanding and applying Boolean logic and thus, fourthly they cannot formulate well-expressed, precisely-targeted on-line keyword Boolean queries (Hildreth 1997:52-53). Keyword and Boolean logic are deceptively too easy to use, hence causing many misunderstandings and misinterpretations about the Internet as an information superhighway. Regardless of the size of the databases, and the sophistication of the indexing techniques, a search engine is only as good as the query submitted to it. Our goal in searching the Web is to get specific information, or the relevant document in a subject area or everything on a specific subject. Effective retrieval is associated with specialized conceptual and procedural knowledge of the operating system of the search engine and its database structure. This is because, like other online searches, the Internet search is a complex, multistage, interactive and dynamic activity that is more of a process than an event (Hildreth: 1997:52). Surfing, as Webster & Paul (1996) note, is unstructured and serendipitous browsing. Starting with a particular Web page, we follow whatever links there are from page to page. making guesses along the way and hoping to get the desired information sooner or later. We stumble along and may get lost in cyberspace (Hancock, 1996). Anagnostelis etc (1997:21) assert Following the links alone can lead the user down numerous blind alleys and dead ends as sites move, resources turn out to be of little interest or relevance, or may contain large graphics which take so long a time to download that the user loses interest. Most users sacrifice search effectiveness for ease of use. Though Internet searching has resulted in dramatic and far-reaching changes to information searching, we have to remember that search engines can only solve part of the information retrieval problem. They have reasoning ability, and have an index that can be searched for documents on a specific topic, but that capability is less than that of a human. With the array of information on the Internet, a search for a specific information can be time-consuming and frustrating. A search for information on information science, may end up with numerous hits on information and science. Coy and others (1996) have summarized the opinions of millions of network users dissatisfied with the World Wide Wait as good stuff is hard to find. Such dissatisfaction is also shared by J. Pitkow and C. Kehoe (http://www.cc.gatech.edu/gvu/user_surveys).
Information Skill and Information Literacy
3.1 Given the present figure of some 320 million Web pages (Zoraini 1998), the current organization of their contents and the speed with which new information is added, searching for information on the Internet can be mind-numbing unless we are information literate, competent in information searching, always keeping abreast of the latest developments and complying with the idiosyncracies of search engines. Listed below are just some of the common problems encountered by users:
3.3 The importance of information literacy in information retrieval (be it manual, automated, on-line or the Internet) calls for the need to be an information literate. Ford (1995:99) and Doyle (1992) define information literate as one who is capable of efficiently and effectively locating and using information for problem-solving and decision-making. To accomplish that, we must have the ability, among many others, to formulate questions, identify potential resources, develop search strategies and evaluate the relevance of the information retrieved. An information literate is simply an effective information searcher who has the ability not only to decide whether a word can be searched alone or should be combined with other words to retrieve specific information, but also to refine searches that yield irrelevant results by applying new skills and working with powerful search tools. The ability to search, identify and retrieve information from the Internet is directly linked to the skill in manipulating words (Hovde, 1996). Word manipulation is part of language capability, which is also a part of information literacy. Today, with the greatly increased speed of the search engines, the growing size of databases and the complexity in the definition of searches, a higher level of information literacy is needed to conduct advanced searches. Below are some tips which may be useful in enhancing search performance:
2. Learning from mistakes can be important as they may lead us to places or techniques we have not thought of before..
4. A good command of the English language is a guarantee of a big vocabulary for distinctive words, synonyms or term variations (eg adolescents for teenagers; female for women; results for outcome) which can improve matching
5. To this list, must be added the 7 donts from Bates (1996), namely (a) dont be too proud to read and understand the manual, (b) dont rush into a search before thinking about the search goals, (c) dont do a comprehensive search when what you need is a few good items, (d) dont fail to think creatively about what sources would best cover the subject, (e) dont use the same old sources for every search, (f) dont try one formulation for every search, (g) dont be ignorant of the search engines tricks and tools.
6. Refer also to the tips, given by Nims and Rich (1998:157) as quoted below:
Tips for successful Web searching
| Search Engine | AND, OR, NOT - (+/-) | Truncation | Phrase Searching | Upper/LowerCase | URL Searching |
| AltaVista
www.altavista. digital.com |
+/-
and, or, and not |
|
|
upper case
retrieves exact match |
yes
(ex. u:image) |
| Excite
www.excite.com |
+/-
AND, OR, AND NOT (must be in caps) |
|
|
matches capital letters |
|
| HotBot
www.hotbot.com
|
+/-
and, or, not |
|
|
insensitive
(except for "interesting cases") |
|
| Lycos
www.lycos.com |
+/-
and, or, not |
|
|
insensitive |
|
| Magellan
www.mckinley. com
|
+/-
AND, OR, AND NOT (must be in caps) |
|
|
matches capital letters |
|
| Yahoo!
www.yahoo.com
|
+/-
and, or, not |
|
|
upper case
retrieves exact match |
yes
(ex. u:image) |
4.1 The so-called information age is characterized by the deluge of information and the greatly improved access to it. But, the question is whether more relevant information on various topics can be effectively retrieved following the emergence of the Internet, WWW and hundreds of search engines. The sheer volume and the myriad array of information on the Internet make searching for the right information at the right time progressively more difficult. As the size of databases grow, we need to traverse increasingly more links to search the required documents scattered in the hypertext system. In performing this, our skill, experience and competence are important to ensure that we do not drift further away from the desired paths and links. The characteristics of heterogeneity, inconsistency, multiplicity and size of the search engines also pose increasing problems in retrieving the required information. Unfortunately, bigger databases are no guarantee of more relevant documents, despite the fact that the size of databases determine the number of hits that can be delivered. On the other hand, the organization of data in the ever growing databases of the various search engines more often than not baffle us. Though most search engines claim to have access to an enormous number of sites and accessed by innumerable users, none can be said to be the best or can be relied upon to satisfy every query.
4.2 As all search engines have their strengths and weaknesses, the quality of search results vary greatly among them. Although they attempt to compete with one another, there is, so far, no one engine that can be considered the ultimate one-stop search tool that can satisfy every query as they complement one another. They may be fast and easy to use, hence a time-saver, provided we are familiar with their features, weaknesses and capabilities. As the Internet is still a relatively new on-line information resource, it is a place of great experiment and excitement and search engines, despite their shortcomings, are becoming increasingly indispensable information retrieval tools. It is therefore necessary for us to be discriminating and select our favourite search engines as Finch (1996:84) and Bates (1997:49) advise. Meanwhile, it is essential that we keep abreast of new and improved search techniques to upgrade our information literacy which brings with it the confidence of our ability to search for information more effectively. And, as new technologies are being developed, we will become more sophisticated information seekers (Cullen, 1997; Gordon, 1997 & Hildreth, 1977) hence keeping the information fatigue syndrome at bay.
References:
Ali, S. Nazim. Subject relationship between articles determined by
co-occurrence of keywords in
citing and cited titles. Journal of
Information Science 19 (1993):225-232
Anagnostelis, Betsy etc. Think critically about information on the Web. VINE 104 (1997): 21-28
Bates, Mary Ellen. The seven deadly sins of online searching. Online
User (Nov 1996)
(http://www.onlineinc.com/oluster/pempress)
Bates, Mary Ellen. The Internet: part of a professional searchers
toolkit. Online (Jan-Feb 1997):
47-52
Candy, Phil. The problem of currency: information literacy in the context
of Australia as a learning
society. The Australian Library Journal
(Nov 1993): 278-299
Coy, P; Hof, R. D & Judge, P. C. Has the net finally reached the
wall? Business Week (26
August 1996) also available at Http://businessweek.com/1996/35/b3490107.htm.
Culler, Clara. Filtering information from the Internet: the Borges
information filtering service project
in Dublin City University. VINE
104 (1997): 45-50
Cunningham, Jim. Getting the most from AltaVista. Behavioral
& Social Sciences Librarian.
15:1 (1996):53-53
Doyle, Christina A. Final report to the National Forum on Information
Literacy. (ERIC
Clearinghouse on Information Resources, 1992).
ED351033
Finch, Byron J. Finding P&IM resources on the Internet. Production
and Inventory
Management Journal 1996 (1):
82-85
Ford, Barbara J. Information literacy as a barrier. IFLA Journal 21 (1995): 99-102
Furner, Jonathan. IR on the Web: an overview. VINE 104 (1997): 3-13
George, Rigmor & Luke, Rosemary. The critical place of information
literacy in the trend towards
flexible delivery in higher education contexts.
AARL
(Sep 1996): 204-212
Gordon, Ed. Verity agent technology: automatic filtering, matching
and dissemination of
information. VINE 104 (1997):
40-44
Gregg, R. Looking ahead to 1998 on the net. Online (Jan-Feb 1998): 74-76
Hancock, Wayland Buddy. Lost in cyberspace? Search engines guide the
way. American Agent
& Broker (September 1996):
73-75
Hancock, Micheline. Subject searching behavior at the library catalogue
and the shelves:
implications for online interactive catalogues.
Journal
of Documentation 43:4 (Dec 1987):
303-321
Hildreth, Charles R. The use and understanding of keyword searching
in a university online
catalogue. Information Technology and
Libraries (June 1997): 52-62
Hock, Randolph E. Evaluating one web search engines capabilities.
Online
(Nov-Dec 1997):
24-32 (http://www.
Onlininc.com/onlinemag)
Karen, Hovde. Knowledge navigation and librarians: the word fray.
Bulletin
of the American
Society for Information Science
(Aug-Sep 1996): 8-10
Kimmel, Stacey. WWW search tools in reference services. Reference
Librarian. No 57
(1997): 5-20
MacLeod, Roddy. Tracking new Internet resources. VINE 104 (1997): 14-20
Mutch, A. Information literacy: an exploration. International
Journal of Information
Management 17:5 (1997): 377-386
Nims, Julia K. & Rich, Linda. How successful do users search the
Web? College & Research
Libraries News 59:3 (1998):155-158
Pevar, Marc D. Finding things on the Internet: search engines. Cost
Engineering 38:5 (May
1996)
Webster, Kathleen & Paul, Kathryn. Beyond surfing: tools and techniques
for searching the Web.
Information Technology (Jan
1996) (http://magi.com/-mmelik/ii96jan.html)
Zarn, Peggy et al. Advanced web searching. Online (May-Jun 1996): 15-18
Zoraini Wati Abas. Facts and figures from the Web. New Straits
Times Computimes (4 June
1998): 31
